基于YOLOv4的暴力行为实时检测算法
2022-03-25闫保中刘忠强
闫保中,刘忠强
哈尔滨工程大学 智能科学与工程学院, 黑龙江 哈尔滨 150001
随着“平安城市”等建设项目的推进,我国安防行业得到了快速发展,视频监控系统未来将向智能化方向迈进。但是目前大部分的监控系统仍采用传统的依赖人工监视的方式,不仅效率较低,而且容易对异常行为发生漏检,可能会造成严重的后果[1]。因此,研究一种能够自动检测出监控视频中异常行为的算法,对于加强城市安全具有重要意义。
对于监控视频异常行为检测问题,国内外学者提出了多种算法,按发展阶段可分为基于传统机器学习的算法和基于深度学习的算法两类。传统算法采用手工提取特征的方式,根据对异常判断准则的不同可分为能量法、聚类法、重构法和推断法[2]。传统算法需要手工设计特征,往往针对特定的任务,因而设计出的模型泛化能力较差。而基于深度学习的算法能够自动学习特征,目前主要采用行为识别模型对异常行为进行检测,主流的网络结构包括双流卷积网络(twostream convolutional network)[3]、3D 卷积网络 (3D convolutional network, C3D)[4]、 卷 积 神 经 网 络(convolutional neural networks, CNN)与 长 短 时 记忆 (long short-term memory, LSTM)网络结合的网络[5]等。这些算法计算量很大,难以实现实时检测,无法满足监控系统的实际需求。
针对上述问题,本文采用YOLOv4[6]作为基础模型,并从检测的精度和速度两方面改进原网络,用于对监控视频中暴力行为的实时检测。当检测出暴力行为时,及时报警通知相关人员处理,能够有效避免恶性事件的发生,保障人民群众的生命安全。
1 算法概述
本文算法用于对公共场所中发生的暴力行为的检测,仅检测监控视频中的暴力行为,忽略正常行为。选取真实的监控视频,根据对暴力行为的定义截取视频帧并进行标注,建立暴力行为数据集。对YOLOv4的网络结构和后处理方法进行改进,将自建数据集经过数据增强等预处理后,用于训练改进后的模型,并在测试集上验证训练后模型的检测效果,从准确性和实时性两方面做出评价。本文的暴力行为检测方案如图1所示。
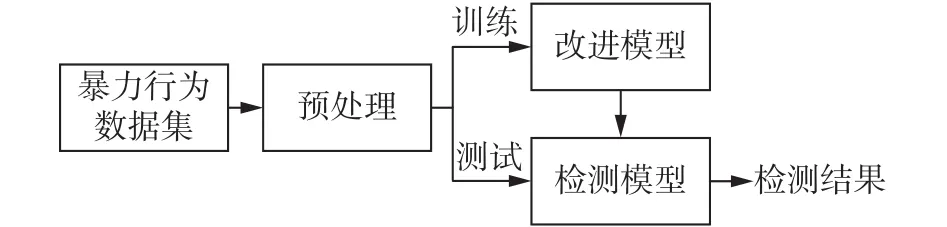
图1 暴力行为检测方案
2 暴力行为数据集
2.1 暴力行为定义
异常行为的判定与场景相关,一些正常行为在特定场景下会被归为异常,比如在行车道上跑步被认为是异常行为。本文将异常行为限定为暴力行为,具有明显的行为特征,且不受场景的限制。暴力行为包括打架、虐待等肢体冲突,主要表现为2人或多人之间的挥拳、踢腿以及擒抱等超出正常接触范围的动作,在任何公共场所中检测到此类行为即判定为暴力行为。
2.2 数据集的建立
本文在UCF-Crime[7]和RWF-2000[8]异常行为数据集的基础上建立暴力行为数据集。其中UCF-Crime由1 900个监控视频组成,包括真实场景中的13种危害公共安全的异常事件。而RWF-2000由真实监控视频中的2 000个 片段组成,每个片断时长5 s,分为有暴力行为和无暴力行为2种。
本文在上述2个数据集中筛选出包含暴力行为的较清晰的视频,利用OpenCV对视频进行帧处理,每隔5帧截取1帧图像。然后再进一步筛选出包含暴力行为关键特征的图像,共获得5 000多张暴力行为样本。利用LabelImg标注工具对样本中的暴力行为进行标注,获得相应的标签文件。数据集中的部分样本如图2所示。

图2 数据集样本示例
2.3 数据增强
为了扩充样本的数量,提升模型的泛化能力和鲁棒性,本文对样本进行了数据增强。为了保证暴力行为关键动作的完整性,没有采用随机裁剪的方法,仅对单个样本进行了水平翻转、改变亮度和旋转操作。经过数据增强的图像如图3所示。

图3 单样本数据增强
此外,本文采用了YOLOv4中的Mosaic数据增强方法,将4张图片拼接为1张,扩充了检测目标的背景,并且同时对4个不同的图片做批标准化 (batch normalization, BN)计算,可以减小 batch size的大小。经过Mosaic增强的图像如图4所示。

图4 Mosaic 数据增强
3 改进的 YOLOv4 网络
3.1 YOLOv4 网络结构概述
YOLOv4的网络结构可分为主干网络、特征融合网络和检测头3个部分。其中主干网络在原来的基础上加入CSPNet[9]结构,形成了CSPDarknet53网络,用于提取特征。而特征融合部分采用空间金字塔池化层(spatial pyramid pooling, SPP)和 路 径 聚 合 网 络 (path aggregation network, PANet)相结合的结构,将不同层级的特征进行融合,能够获得较强的语义信息和空间信息。融合后的3种尺度的特征图分别经过检测头,输出检测结果。
3.2 Focus 层的设计
对于输入图像一般需要先经过下采样来实现降维,从而降低计算量。常用的下采样方法包括最大池化和步长为2的卷积两种,但他们在下采样的过程中都难以避免信息丢失的问题,影响检测效果。
本文在YOLOv4的输入端和主干网络之间加入了1个Focus层,采用间隔采样的方式对原特征图进行切片,将高分辨率的特征图拆分为多个低分辨率的特征图,如图5所示。将拆分的特征图进行拼接,相当于将输入通道扩充了4倍。将平面上的信息转换到通道维度,再通过卷积操作提取特征,能很大程度减少信息损失,从而提取到更充分的特征。

图5 Focus 层示意
3.3 DO-Conv 卷积
DO-Conv(depthwise over parameterized convolutional)是一种新提出的能够替代传统卷积的卷积方式,在普通的卷积层中加入depthwise操作,构成1个过参数化的卷积层,能够加速网络的训练过程,并且在不增加网络推理计算量的前提下提高网络性能[10]。图6为传统卷积与DO-Conv卷积的卷积过程。传统的卷积过程如图6(a)所示,图中Cin和Cout分别代表输入特征图和输出特征图的通道数,M和N代表特征的空间维度。对给定的输入特征图,采用滑动窗口的方式,将卷积核作用到特征图的窗口区域中。图中*代表标准卷积操作,输出特征可以表示为O=W∗P,其中W为卷积核,P为输入特征。图6(b)为DO-Conv的卷积过程,首先对2个卷积核DT和W进行depthwise操作,得到新的卷积核W′=DT◦W,其中 ◦代表depthwise操作。然后将卷积核W′与输入特征P经过传统卷积得到最终的输出特征O=W′∗P。

图6 传统卷积与 DO-Conv 对比
本文将YOLOv4主干网络中的标准卷积层替换为DO-Conv。网络经过训练后得到 DT和 W ,在推理时先计算 W′并保存,然后与输入特征做传统卷积,与相同设置的传统卷积相比计算量相近,能够在不降低推理速度的情况下提升网络的性能。
3.4 Matrix NMS 后处理
YOLO系列算法会在1个目标上生成多个预测框,所以不能将网络的输出直接作为预测结果,还需要经过非极大值抑制(non-maximum suppression, NMS)处理,筛选出最优的预测框,消除冗余的部分。
YOLOv4中采用的是 DIoU NMS 算法[11],将边框的中心点纳入考量,与标准的NMS算法相比,对冗余预测框的消除更为准确,并且对存在遮挡问题的目标检测效果更好。但是DIoU NMS算法仍采用的串行处理方式,需要多次计算IoU值,且计算方式更为复杂,会降低运算效率。为了提升后处理的效率,本文采用Matrix NMS算法[12]代替DIoU NMS,使用并行运算的方式,一次性完成全部计算。
对于冗余的预测框,Matrix NMS会利用重叠度来降低其他预测的得分,而不是像标准NMS那样直接将其消除,其中得分是重叠度的单调递减函数f(iou)。预测框Bj的衰减因子主要受2个因素影响,首先是每个预测的Bi对Bj的惩罚(penalty),其中Bi的得分si大于Bj的得分sj;其次是Bi被抑制的概率。Bi对Bj的惩罚可以通过f(ioui,j)计算,而Bi被抑制的概率计算较为复杂,但是此概率与IoU正相关,可以用与Bi的IoU最大的预测来近似此概率,得到公式为

式中si和sk分别为相应预测框的置信度得分。从而可以得到Bj的衰减因子,即

然后可对Bj的得分进行更新:
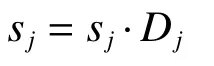
Dj的计算公式中包含2个递减函数,其中分子是线性的,计算方法为

而分母是高斯,计算公式为

Matrix NMS的所有计算均可以单阶段完成,不需要进行递归。首先选取按照置信度得分排列的topN个预测结果,计算一个N×N的IoU矩阵,在此矩阵上就可得到重叠度最高的各个IoU值;然后计算所有置信度分数较高的预测的衰减因子,并通过列最小值法在它们中进行选择;最后可根据衰减因子来更新置信度得分。在使用Matrix NMS时,只需要设置筛选的阈值,然后选择top-k得分的预测框作为最终的预测结果。由于采用并行运算,Matrix NMS大幅提高了运算效率,在保证检测精度的同时提高了检测速度。
此外,为了进一步减少网络的计算量,提高检测速度,本文在主干网络中采用LeakyReLU激活函数[13]代替YOLOv4中计算较复杂的Mish函数[14]。改进后的网络结构如图7所示。
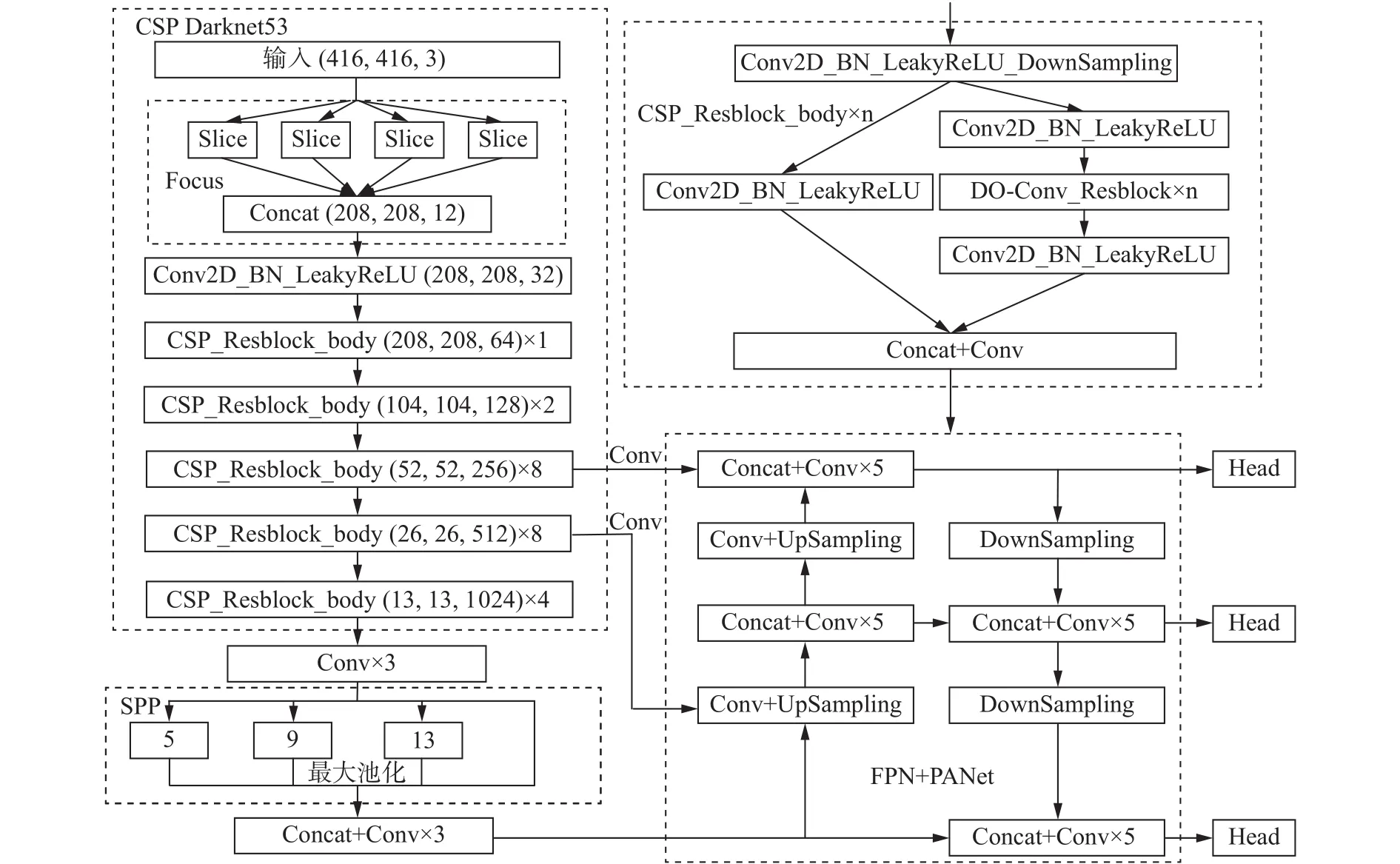
图7 改进的 YOLOv4 结构
4 实验结果分析
4.1 实验环境及参数设置
本文实验在Windows10操作系统下进行,CPU 为 Intel Core i7-9700K,内存为 32 GB,GPU为 NVIDIA RTX 2 070 SUPER。在 PyCharm 中预装的环境包括 python 3.8、pytorch 1.81、cuda 10.2、opencv 4.5.2 等。
将数据集按照4∶1划分训练集和测试集,利用k-means聚类的方法重新确定适合自建数据集的9种anchor大小。训练中设置batch size为8,初始学习率为10-4,优化器采用Adam,共训练100个 epoch。
4.2 损失函数及其变化曲线
本文在自建数据集上分别训练了原始的YOLOv4模型和本文改进后的模型,得到未经平滑的损失函数loss曲线如图8所示。其中蓝色曲线代表原始模型的loss值,绿色曲线为改进模型的loss值。从2种曲线的对比可知,改进后的模型loss值下降得更快,且最终的loss值稳定在0.5左右,低于原始的模型。
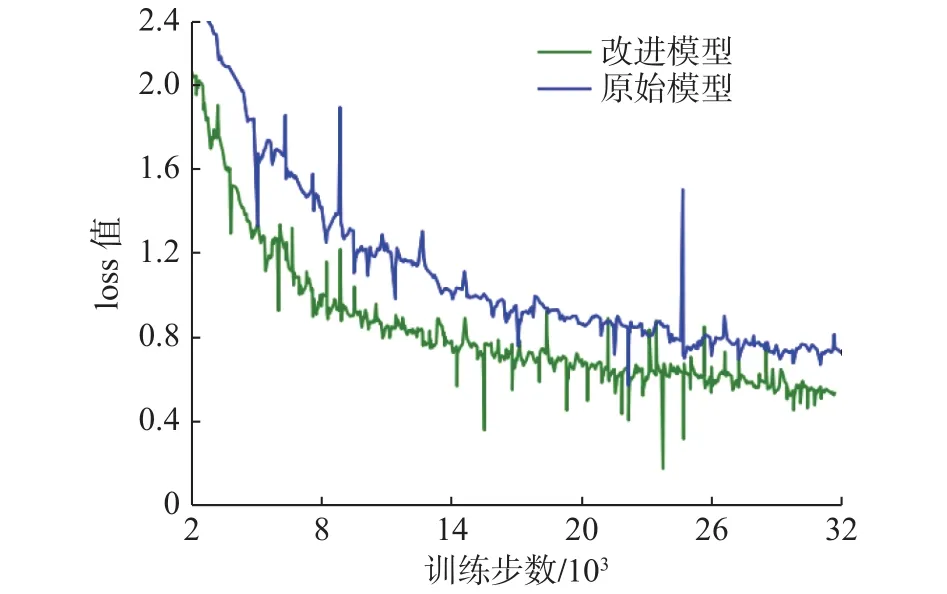
图8 2 种模型的 loss曲线比较
4.3 检测精度与速度对比
对于目标检测模型的精度,一般采用P–R曲线和 mAP(mean average precision)值来评价。如果随着召回率(R)的增长,精确率(P)能够保持平稳,则模型的分类性能较好。本文所训练的2种模型的P–R曲线如图9所示,可知2种模型的分类性能均较好,当R值达到0.9以上后,P值逐渐快速下降,且改进模型下降得相对更慢。

图9 2 种模型的 P–R 曲线比较
在2种模型的训练过程中,从第10个epoch开始,每训练完1个eopch即对模型进行1次测试,得到2种模型的mAP变化曲线如图10所示,其中蓝色代表YOLOv4原模型,绿色为改进模型的曲线。由曲线可知改进模型的mAP值更高,即具有更高的检测精度。

图10 2 种模型的 mAP 变化曲线
模型训练结束后,分别在测试集上对2种模型进行测试,得到mAP值和推理速度的值如表1所示,其中推理速度的单位为帧每秒(frame per second,fps)。

表1 2 种模型的测试结果对比
测试结果说明本文的改进模型在检测精度和推理速度上均优于原模型,检测mAP值达到97.95%,推理速度为56.4 fps,超过实时检测要求的30 fps,能够实现对暴力行为的实时检测。
4.4 模型检测结果分析
利用训练好的2种模型分别在测试集上进行验证,部分检测结果如图11所示。模型在定位暴力行为的同时,在预测框的上方会标记分类结果及置信度。

图11 2 种模型的测试结果对比
2种模型均能对不同场景下的各种表现形式的暴力行为进行检测,但存在不同比例的误检问题。比较2种模型的检测结果,本文的改进模型对暴力行为的定位更为准确且分类的置信度更高。此外,相比YOLOv4模型,本文的模型检测发生误检的概率更低。
5 结论
本文针对监控视频中的暴力行为,研究了基于改进的YOLOv4的实时检测算法。
1) 为提升检测的准确性和实时性,对YOLOv4网络结构和后处理方法进行了改进和优化,改进后的模型在检测精度和速度上均优于原模型。
2) 自建暴力行为数据集,用于模型的训练和测试。实验结果表明,本文的算法能够准确定位视频帧中的暴力行为,并且具有良好的实时性,但是存在部分误检问题。
文本的算法还可用于对其他特定行为的检测,以满足特定场景的监控需求。
