融合BERT 与LDA 的在线课程评论关键词提取方法
2022-03-25尼格拉木买斯木江艾孜尔古丽玉素甫
尼格拉木·买斯木江,艾孜尔古丽·玉素甫,2
(1.新疆师范大学 计算机科学技术学院,新疆 乌鲁木齐 830054;2.新疆师范大学 计算机科学技术学院 国家语言资源监测与研究少数民族语言中心,北京 100814)
0 引 言
随着信息技术的迅猛发展,“互联网+教育”得到了市场的青睐和追捧,但当前的慕课平台还有一些不足,如存在教学视频延迟、教学资源不完整等问题。由于数据量太大,使得手工统计和分析难以实施,所以迫切需要一种方法能够从大量的信息源中快速有效地提取出真正需要的信息,并充分展示分析结果。因此,需要对在线课程评论关键词进行提取。
关键字提取使人们能够以简洁的方式表示文本文档。文档的关键词在文本自动索引等任务及相关应用场景中有相应表现。目前,关键字提取主要基于最频繁度量的关键字提取、词频反转文本频率的关键字提取等方法。随着关键词提取技术的提高,一些学者优化算法,利用节点信息进行关键词处理,如通过TextRank 调整边的转移权值以取得较好的效果。Abilhoa W D 通过隐含的Diricre 分布主题模型构建主题特征LDA 的奖励函数计算词,构建关键词抽取模型。Nagarajan R 等通过将句法特征结合到词的表示中来获得比N-Gram 更高的准确性。Abdelhaq H 等通过LDA 和TextRank 算法联合提取关键词。顾益军等为了提高学习算法的有效性及秉持对基于统计关键词提取方法的评价,对基本的学习算法和常用的Set 算法进行了比较。郭庆用文本分类问题思路解决了文本主题词挖掘问题,提取关键词用了支持向量机(SVM)。Khalil M 认为在提取关键词时要考虑句子的影响程度。基于以上方法,可以进一步提高关键词处理的效率。
随着人工智能技术的发展,关键词提取得到越来越多的重视,洪成杰通过BERT 和TextRank 处理关键词。王亚坤利用融合算法提取关键词。韦强申通过PageRank 和神经短语嵌入算法对关键词进行提取和排序。薛清福等构建词向量并与主题挖掘技术TextRank 相结合,增添了文本语义与TextRank 的相关性。肖倩等提出一种新的词向量聚类和TextRank 方法,利用BERT 词之间的相似度关系,提高了关键词处理效率。李德新等优化了关键词提取,但仍存在准确性不高的问题。
基于上述研究,本文提出了一种融合BERT(Bidirectional Encoder Representations from Transformer)和模型LDA 隐含狄利克雷分布(Latent Dirichlet Allocation)的在线课程评论关键词提取方法。该方法可以根据语义信息的影响,浓缩在线课程的特点评论信息和关键词的覆盖率和差异。利用训练后的BERT 模型获得候选词的词向量;再利用LDA 主题模型得到候选关键词差异的影响程度以及在主题与文本候选关键词间的语义相关性;最后在主题与语义关联性及TextRank算法基础上对实验所选出来的关键词进行排序。通过本文提出的方法可以完善慕课平台的建设与改进,同时也有助于提供更好的用户体验。
1 一种融合BERT 与LDA-TextRank 的在线课程评论关键词提取方法
近几年在线课程的发展,使用户和平台管理者能够从繁杂的用户评论中获取更多有价值的信息。在选择和改进过程中得以实现是目前在线课程评论的研究热点。本文提出一种基于BERT LDA-TextRank 的关键词提取方法。第一步获取候选关键词,在候选关键词之前对爬取的课程评语进行预处理,再通过BERT 模型训练得到慕课网在线评语的词向量;然后利用LDA 主题模型得到候选关键词的主题分布;最后结合TextRank 算法计算出各主题的关系词,并生成候选关键词进行主题挖掘。
1.1 词向量构建模块
一些学者采用分布式方法对词进行处理,该方法有相关性更强的优点,能更好地反映词与词之间的紧密关系。Mikolov 等人提出了一种词表示模型,通过分布式方法突出词语的相关性。本文则通过谷歌开源工具包BERT 模型训练慕课平台语料库上的词表示模型。为了得到待测文本候选关键词,本文首先对在线课程评论进行预处理并选取评论主题的特点;再基于针对网络课程的候选关键词,在现有的数据集上进行文本表示,在得到BERT 模型训练好的词向量之后,进一步得到文本评论向量。
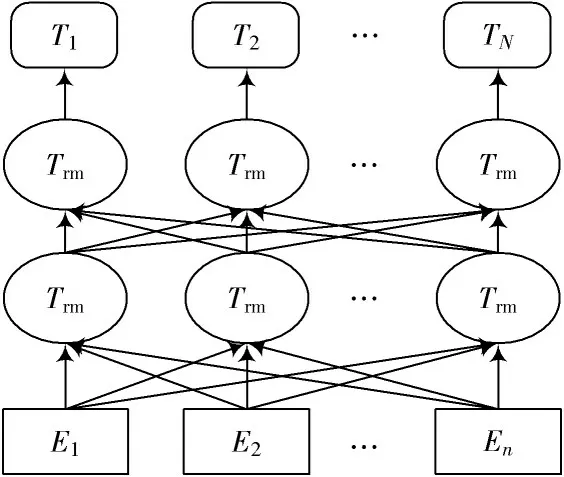
图1 BERT 模型图

1.2 主题差异性挖掘模块
关键词不仅需包含网络课程评论的主要框架,而且要有主题差异和文本覆盖。如果考虑不周,则提取的关键词有效率会下降,因此,关键词不仅重要,而且具有差异度和覆盖度。
为了表征关键词之间的差异和覆盖范围,本文重点关注了候选关键词重要属性,利用LDA 主题模型分析候选关键词主题差异的关系。
LDA 主题模型认为一个文档由几个主题组成,同时每个主题由几个单词组成,分别代表个文档的个特征词及其主题。主题模型是一种识别和聚类文档中潜在主题的算法,可用于识别文本中隐含的主题信息。现流行的主题概率模型是隐含狄利克雷分布,即LDA,简称基于向量模型。这个模型是一个基于生产的概率模型,其中包含文件、话题和文字。该模型运用先验分布解决了主题挖掘任务中向量过度拟合问题。LDA 概率模型基于贝叶斯算法,具体计算过程如图2所示。
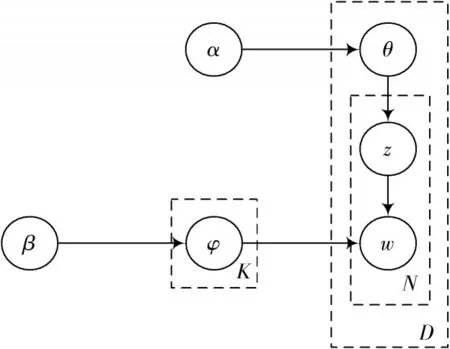
图2 LDA 概率模型
图2 中LDA 的各实验变量参考释义如表1 所示。

表1 主题模型中各参数含义
从主题模型生成单词的LDA 过程如下:
1)根据先验实验概率从多个备选文档中选择一个文档;
2)从Dirichlet 分布中抽样,并且生成主题分布;
3)主题多项式分布样本的底部单词,生成主题的文档z;
4)与主题对应的单词分布由Dirichlet 分布生成;
5)生成词w从词的多项式分布采样中得到;
6)参数计算可以采用Gibbs 算法,即:


1.3 基于TextRank 的主题摘要生成模块
关键词能体现文本的基本信息,随着人工智能的发展,各种技术和理论被应用到关键词处理中。BERT 在这些技术中脱颖而出。
基于TextRank 的主题摘要生成是指主要评论中的某个评论语句和其他相似度较高的评论,如有两个句子s,s,t表示评语候选关键词,相似度公式如下:

式中,若两个给定句子相似度高于给定的值,在该模型中被认定为这两个句子具有语义相关性并且会将s,s连接起来,作为候选评论语句的重要语句根据相关权重计算抽取出重要度高的个句子,得到主题摘要。
1.4 BERT-LDA 模型整体框架
本文以BERT 的模型为基础,构建LDA-Text Rank课程评价的主题提取模型。与传统主题模型的输入语料库相比,该模型使用BERT 语言模型减少了输入语料库,大大提高了模型提取的效率,使主题提取的分布更好。BERT-LDA-TextRank 模型操作过程为:对爬取的课程评语进行预处理,预处理语料库用输入到BERT 模型获得减少维度的词向量表示;再通过LDA 模型对数据进行主题挖掘,挖掘热门话题和相应的主题关键字;最后运用TextRank 算法提取各关键评论语句的主题摘要。本文方法在更深的层面上提取隐含的主题中包含情感信息的课程评价。
2 实 验
2.1 数据预处理和参数设置
本文以最大的IT 网络学习平台慕课(MOOC)网作为数据来源,通过开源爬取框架Scrapy 爬取了前100 门热门课程评论信息共51 977 条数据记录。同时采用结巴分词系统对数据进行了去重、过滤、去停用词等文本预处理。图3 为在线评论主题挖掘算法流程。实验中数据集按3∶1 的比例分割,并使用BERT+LDA+TextRank 模型,参数设置如表2、表3 所示。

图3 在线评论主题挖掘算法流程
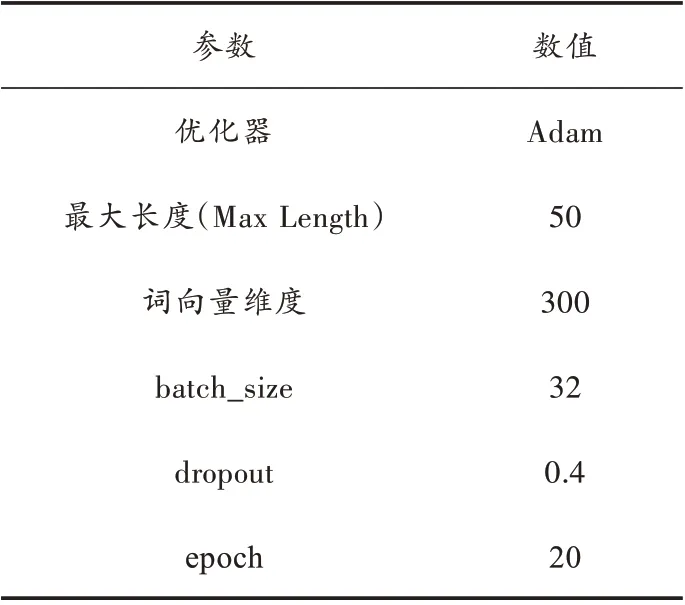
表2 Bert 模型参数设置

表3 LDA 模型参数设置
2.2 实验评价指标与实验环境
为了验证本文模型的性能,在本实验效果评价上使用了困惑度(Perplexity)对比实验。困惑度是用来度量概率分布的重合程度和预测样本的指标,也可以用来表示两个概率分布或概率模型,在主题模型中低困惑度的概率分布预测样本能力更高。困惑度计算公式如下所示:

式中()指的是每个单词的出现频率。根据式(3)可求得相应文档中不同主题出现的概率。
实验环境为X86 平台,Intel CPU,内存16 GB,硬盘100 GB,GPU-v100,操作系统为Windows 10,Pycharm 2017。使用基于TensorFlow 的深度学习库Keras 进行测试。
2.3 实验结果与分析
为了对提出模型性能进行测试,开展了两组对比实验。第一个实验在对主题提取效果进行验证的基础上测试了各模型性能,同时验证不同主题数下模型的性能,并为实验选择最有效的主题数。第二个实验是验证不同数量的Gibbs 迭代次数对模型的影响。第三个实验基于TextRank 的主题词分布研究。
2.3.1 基于慕课在线课程评语主题提取效果对比
本文选择了慕课网中最热门的50 门课程。根据大量文献将参数设置为0.2,将设置为0.1,两个参数都为超参数。下一步将初始Gibbs 样本的迭代次数初始值设置为300。因为BERT-LDA-TextRank 模板的第一层为文本表示模型,第二层为主题挖掘层,所以模板的参数也是超级参数,以人为设置为主。通过调整主体数量来调整主题提取影响度,因此值分别为2,4,6,8,10,12,14 在各主题数基础下确定实验最佳性能,对比实验如下:
1)LDA:此模型是Ml构建的原始LDA 主题模型,直接使用LDA 主题模型进行主题提取实验。
2)CBOW-LDA:该模型类似于BERT-LDA 模型,通过CBOW 算法对文本进行降维,最后将降维后的实验语料集输入LDA 主题模型进行主题抽取实验。
3)LDA-TextRank:模型第一次使用LDA-TextRank算法将降维语料库输入LDA 主题模型主题提取实验,最后用TextRank 算法挖掘各主题。
4)BERT-LDA-TextRank:为本文提出的模型。实验模型是使用BERT 训练在线课程评语的候选评语并生成评论向量,然后将语料集输入LDA 主题模型,最后与实验3)类似,用TextRank 算法计算主题分布。
这四个模型的混淆度随着主题的增加而明显。通常,降维模型的LDA 模型混乱程度都不优于本文提出的BERT-LDA-TextRank 方法,其中单纯的LDA 模型主题提取能力最差;本文模型混乱程度最低,对比CBOW-LDA,添加文本表示模型对文本向量化,训练语料有了很明显的提高。
对比CBOW-LDA,添加BERT 主题模型的混乱效果优于添加CBOW-LDA,因为BERT 模型考虑上下文语义信息和词序关系,以及在训练和文本中的单词出现的次数,因此CBOW 提取的特征不如BERT。本文还进行了LDA-TextRank 和BERT-LDA-TextRank 对比实验。在本文的数据集上BERT-LDA-TextRank 模型略优于LDA-TextRank 模型。通过实验不难发现,当主题数=6 时,被试的困惑程度最低,所以主题模型中的主题数为6。

图4 模型结果对比图
2.3.2 Gibbs 迭代次数对模型影响研究
为了确定吉布斯抽样的最优迭代数,本文在保持其他参数不变的情况下,进行BERT-LDA-TextRank 迭代数混淆度实验,分别将吉布斯抽样迭代数设置为50,100,150,200,250,300,以观察其混淆度随迭代数的变化。设定迭代次数时,吉布斯认为迭代次数越高实验效果越好,但增加迭代次数也会影响计算机硬件配置,所以配置迭代次数时,应根据实际实验条件来设置参数。
通过图5 可知,Gibbs 迭代次数从0~250 的困惑度值差距较大,主题提取精度在迭代次数为250 时为最佳并保持不变。因此,在本模型中Gibbs 参数设置为250。

图5 迭代次数对实验结果影响图
2.3.3 基于TextRank 主题词分布研究
为了能更清楚地研究各主题评论内容,本研究利用第1.3 节所讲解的TextRank 算法生成主题摘要和关键词语,限于文章篇幅,表4 给出部分产品的主题摘要和关键词语。
从表4 中可以看出:第1 个主题与程序语言学习相关,用户在评论中都体现了一些主题信息,“C++”这个词语出现的概率较高;第2 个主题是基于机器学习的,因为“SVM”这个词出现的频率相对较高;第5 个主题是关于各种框架学习等。除此之外,从主题词分布中能够掌握用户的关注点,比如Java 课程中,机器学习主题主要关注一些模型,而用户关注框架和语法问题。同时,实验结果表明,用户对相关课程和平台管理者的建议以及主观情感态度也会表现在评语中,比如慕课用户对语言类科恒“Java”的授课老师、内容以及授课方式给出了比较客观的评价,对JS 课程的授课内容很满意,对第4 个主题的课程评价比较卡顿,对管理者提出了相应的改进方案。
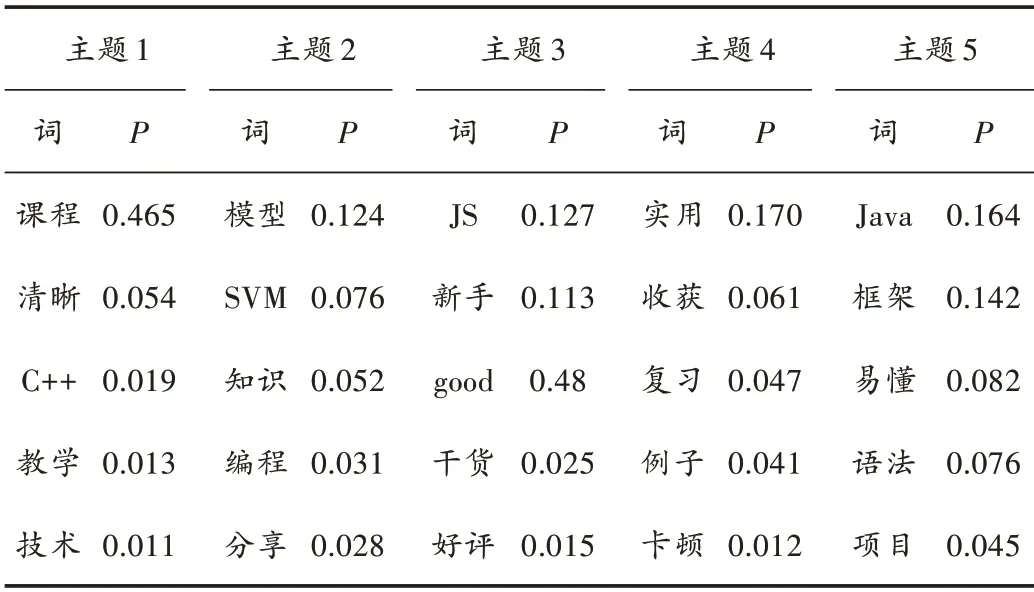
表4 主题词分布表
通过主题挖掘,能够从更深的层面上提取隐含的主题中包含情感信息、对学习者及有利于平台管理者的课程评价,有助于完善慕课平台的建设与改进,同时也有助于提供更好的用户体验。
3 结 语
本文提出一种结合BERT 和LDA-TextRank 差异的简单有效的关键词提取方法,该方法考虑了候选关键词的语义重要性、覆盖范围和差异。该方法通过LDA 主题模型、BERT 词表示模型提升候选关键词的差异敏感度,结合TextRank 算法生成了主题摘要和关键词语。实验结果表明,与现有的关键词提取方法相比,文中方法的困惑度有明显降低。下一步就是根据不同语料库信息高度集中的特点,整合外部知识信息,提高关键词提取的质量,扩充语料完善实验。
