基于B-CNN算法的汽车数据集细粒度图像分类分析
2022-03-23韩成春崔庆玉
韩成春,崔庆玉
(1.徐州工程学院电气与控制工程学院,江苏 徐州 221018;2.徐州工程学院外国语学院,江苏 徐州 221018)
0 引言
细粒度图像分类技术的进步,使其在工业应用中发挥了越来越重要的作用。目前,细粒度图像分类技术已经成为图像分析的重要部分。细粒度分类对于当前人们的生产与生活过程也具有主要的现实意义[1-3]。相同种类的各个亚种间存在局部差异,各子类取决于差异部分。以汽车不同位置的车灯数据集为例,该数据集在细粒度分类的过程中存在某些特定图像难以准确标注的问题[4-7]。对于计算机视觉领域而言,相比于手工制作特性,采用细粒度分类方法能够获得更优的综合性能。
卷积神经网络(convolutional neural network,CNN)是实现深度学习的基础,能够实现对数据固有属性的挖掘,通过学习深度卷积特征来实现准确分类的功能[8]。Simonyan[9]被广泛应用于大规模计算机视觉分析领域,包括目标分辨、目标追踪、图像检测、精确定位、影像归类、人体姿势判断等。Szegedy[10]利用堆叠3×3卷积核以及2×2池化层的方式,获得更高的网络结构,构筑得到深度为16~19层的CNN。通过持续加深网络结构的方式,可实现模型综合性能的提升。文献[11]所述的传统CNN方法是利用新增卷积层与池化层方式实现的,会引起信息损耗的问题。根据经典CNN模型进行图像网络大规模视觉识别挑战(imageNet large scale visual recognition challenge,ILSVRC)比赛获得的结果可知,分类误差率从16.2%减小至5%,已经超过人工分类的性能。
1 本文算法
1.1 双线性卷积神经网络模型及原理
双线性卷积神经网络(bilinear convolutional neural network,B-CNN)首先利用2个卷积神经网络从图像中提取得到特征参数,并构建相应的深度卷积特征;然后利用双线性层完成外积操作,针对各通道构建了相应的特征图关系;最后通过池化层跟恒定长度神经元相连形成输出[12]。
通过加和池化的方法获得各位置特征组成的矩阵,将矩阵表示为向量x,实施元素级带符号正则化处理y以及归一化z,根据融合特征进行细粒度分类。以下为具体计算式:
(1)
式中:fA和fB分别为第一路和第二路卷积神经网络的特征提取函数;p为池化层;c为分类层;I为图像信号矩阵;l为对应区域;b(l,I,fA,fB)为双线性函数;ζ(I)为池化函数;x为矩阵张成向量;y为方根正则化操作;z为归一化操作。
对于双线性池化层反向传播过程,利用链式法则计算得到梯度,如下所示:
(2)
式中:L为损失函数。
利用空间金字塔池化层进行二阶特征处理时,可以消除剪切特征图操作并降低计算量。以下为协方差池化计算式:
(3)
式中:H为提取得到的特征图像素;μ为凭据误差。
网络A与网络B既可以属于对称网络,又可以属于非对称网络。依次选择深度网络M-net与D-net进行测试。以上2个网络属于VGG深度网络对应的2类结构。
采用ImageNet数据集预训练获得M-net与D-net权重系数,依次从M-net与D-net中提取获得卷积层加载参数并完成初始化,利用测试数据集完成网络微调。通过对比法可知:深层网络相比浅层网络更优;双线性相比单路网络更优;非对称相比对称网络更优。
1.2 改进的双线性卷积神经网络
两路卷积神经网络同时运行时,可以获得重复的相近特征。利用卷积神经网络可获得更多特征。而在特征融合之前,应对特征图实施裁剪,从而便于完成外积操作。随着模型参数的增加以及复杂度的提高,需要满足更大的显存需求。本文应用归一化处理,通过减少批次数的方式降低误差值受到的影响。
随着数据维度的提高,计算量也明显增加。因此,进行特征选择时,需要确定由最多有效信息构成的最小特征子集。由于图像包含了多个维度,而图形处理器(graphic processing unit,GPU)显存存在一个上限,各批次只对少量数据进行训练,设定的批量数也较小。进行批归一化(batch normalization,BN)处理时,对于较小的批量数会引起较高错误率。训练时,以批量数据作为BN均值与方差的计算数据,通过直接调用的方式进行测试。组归一化(group normalization,GN)可以实现上述情况的优化。BN与GN误差率对比结果由图1所示。由图1可知,当批量数减小后,BN误差率发生了明显增大。
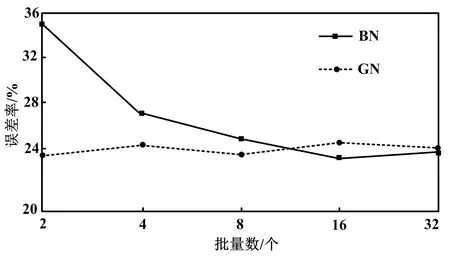
图1 BN与GN误差率对比结果Fig.1 BN VS.GN error rate comparison results
首先,采用B-CNN模型获得二个卷积神经网络特征X1与X2;然后,利用外积方式,处理得到二阶双线性特征;最后,把二层网络加深至四层网络,从而得到更多有用特征。这可以显著改善分类性能。
(4)
根据以上测试结果可知,其结果未获得优化。对其进行分析可知:虽然B-CNN模型是把2个一维特征转变为二维特征,提升了特征的丰富性,但采用本文设计的4层网络获得的特征还是属于二维特征,所以以这种方式分类并不能实现理想分类效果。
2 试验分析
2.1 数据集描述与试验设置
本文选择StanfordCars汽车数据集开展测试。其中,StanfordCars属于一种汽车数据库,总共含有各个年份、车型、制造商的车辆图像共16 186张,可分成196种子类,共8 145张训练集图像以及8 041张测试集图像。汽车类型是根据品牌、模型、年份的方式完成细粒度的分类过程。
①图像信息预处理和参数增强。进行图像分类时,需先对图像数据开展分析并完成预处理。以随机方式从原始图像内截取224×224的范围,根据中心化剪切方式接近。然后,在进行网络输入前,以随机方式完成图片的不同方向翻转。图片发生随机变形后,先对图片作小幅拉伸,再将其裁剪为同样的尺寸,最后将其输入网络中。
②下载ImageNet数据集并对VGG16[13]与ResNet50卷积神经网络权重参数进行预训练。将池化与全连接层去除后,只保留卷积层。以预训练获得的权重构成网络参数。
③构建模型。对2路VGG16网络融合进行分析。首先,通过缩放处理,控制各组图片为448×448×3,再利用VGG16将其转变为28×28×512,共包含512个通道,通道尺寸28×28。然后,复制一份输出结果,按照两两组合方式对输出通道相乘,再计算相乘结果的均值并开方,获得维数为512×512的向量。最后,在完成向量归一化之后,经一层全连接层输出200维向量,共包含200类结果,选择其中最高数值的一维组成最后一类。
④训练与优化。首先,合理选择学习率,进行迭代训练。然后,将模型起始的BN改写为GN,加入dropout层,在训练过程中随机屏蔽一部分全连接层的参数,并进行微调。
2.2 试验结果与分析
针对CUB-200和StanfordCars这2个数据库,分别以B-CNN目标识别算法与优化后的B-CNN完成数据集分类。判别性部件识别结果如图2所示。

图2 判别性部件识别结果Fig.2 Discriminative part identification results
进行网络训练时,合理控制学习率能够达到更快的训练速度。随着损失函数幅度降低至某一范围,可以利用降低学习率的方式来达到跳出局部最优解的效果,并由此获得全局最优解,从而有效防止死循环的问题。学习率寻找过程结果如图3所示。
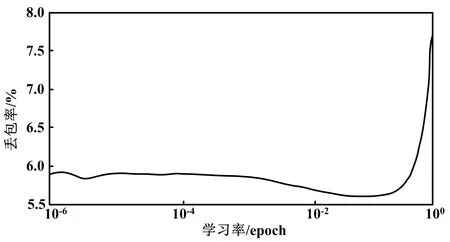
图3 学习率寻找过程结果Fig.3 Learning rate search process results
表1为准确率比较结果。
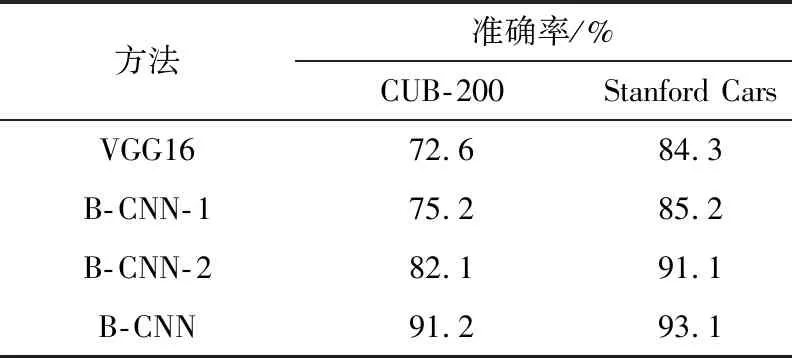
表1 准确率比较结果Tab.1 Accuracy comparison results
B-CNN-1与 B-CNN-2输入图像尺寸分别为(224,224)、(448,448)。从表1纵向层面进行分析可知,B-CNN相对单路神经网络发生了增大,当输入(224,224)的图像时,以汽车数据集进行测试时,准确率提升了16%。输入图像发生了少量裁剪,在(448,448)尺寸下,汽车数据集发生显存溢出。以B-CNN测试汽车数据集的准确率为91.2%,经过提升处理准确率达到了93.1%。
3 结论
本文对双线性卷积神经网络进行阐述,首先应用了GN、dropout方法,调整可训练参数,然后在汽车数据集上试验,最后比较了经典卷积神经网络和双线性卷积神经网络。对比结果显示,双线性卷积神经网络对于一些细粒度图像分类任务适用,能提升分类准确率。
