基于轻量化卷积神经网络的疲劳驾驶检测
2022-03-23林富生周鼎贺
程 泽,林富生,靳 朝,周鼎贺
(1.武汉纺织大学 机械工程与自动化学院, 武汉 430200;2.湖北省数字化纺织装备重点实验室, 武汉 430200;3.三维纺织湖北省工程研究中心, 武汉 430200)
近年来,由于疲劳驾驶造成的交通事故屡见不鲜。频发的交通事故给国家和个人的生命财产安全带来了严重的损失。及时检测出驾驶员的疲劳驾驶状态并做出预警已成为降低此类安全事故的有效方法之一。
疲劳驾驶状态检测技术大致可分为基于传统特征检测模式和基于深度学习检测模式2种[1-5]。朱名流等[6]通过传统HOG特征进行人脸识别并使用人脸特征点模型进行人眼和嘴部的定位,根据人眼与嘴部的张开与闭合,最后根据PERCLOS值判断疲劳驾驶状态。该方法不依赖深层网络,可大幅度提升检测速度,但在检测精度上与深度学习网络还是有一定差距。徐莲等[7]通过多任务级联卷积神经网络对眼部状态进行识别,最后根据PERCLOS判定疲劳驾驶状态。该方法虽然使用了深度学习网络去对特征进行分类处理,但是由于多任务级联导致网络参数过多,虽提高了检测精度但检测实时性略显不稳定。王旭彬等[8]使用目标检测框架Yolo-V3对驾驶员面部定位并对其人脸特征点提取与分析,评价驾驶员状态。该方法虽然利用了深度学习网络,但该网络只作用于人脸位置检测,并没有作用于人脸特征提取,导致最终的检测结果仍旧与传统特征检测方法相当,在检测精度与实时性的平衡性上仍需加强。基于传统特征的检测模式多以特征提取与浅层网络训练模型的方式进行,该模式虽然检测速度较快,但是检测精度不稳定。基于深度学习的检测模式多以深层网络作为特征的训练网络,由于网络层数多、参数多,导致检测速度下降。由于疲劳驾驶检测对实时性要求极高,使用传统的深度学习网络进行疲劳驾驶检测缺乏实用性。
针对以上问题,本文对深层网络进行轻量化改进,使得改进后的网络能够在尽可能少牺牲检测精度的前提下大幅度提升检测速率与实时性,同时有效提升驾驶员疲劳检测的实用性与可靠性。
1 目标检测网络Yolo-V4轻量化改进
1.1 Yolo-V4网络结构
目标检测网络Yolo-V4结构[9]如图1所示。其整个网络结构可以分为3个部分:首先是主干特征提取网络(backbone)模块,对应图上的CSPDarknet53,用来获得3个初步的有效特征层;其次是加强特征提取网络模块,对应图上的SPP和PANet,用来对3个初步的有效特征层进行特征融合,提取出更好的特征;最后是预测网络模块,对应图上的3个尺度输出,用来获得预测结果。图中左下部分为各个组件的结构。
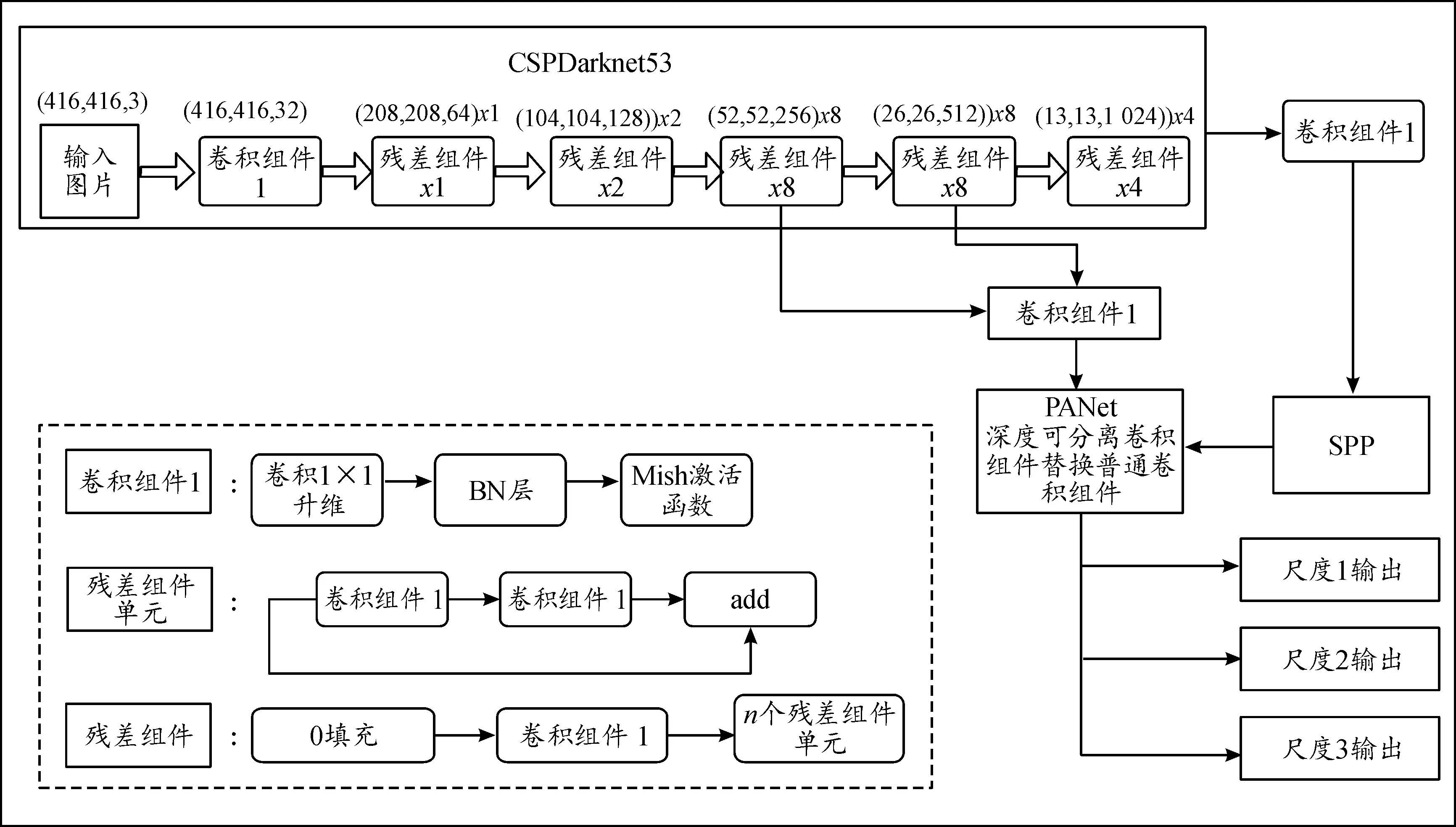
图1 Yolo-V4结构框图
1.2 EMLite-Yolo-V4网络结构设计
由于Yolo-V4的网络参数量较大,导致在模型训练时耗时较长,所得模型占用内存空间较大,在处理一些简单的目标检测任务时检测速度会受到一定影响。所以针对轻量化与检测精度2个因素设计了一种EMLite-Yolo-V4超轻量级目标检测网络结构,如图2所示。该网络结构对Yolo-V4网络中3个部分进行了改进。
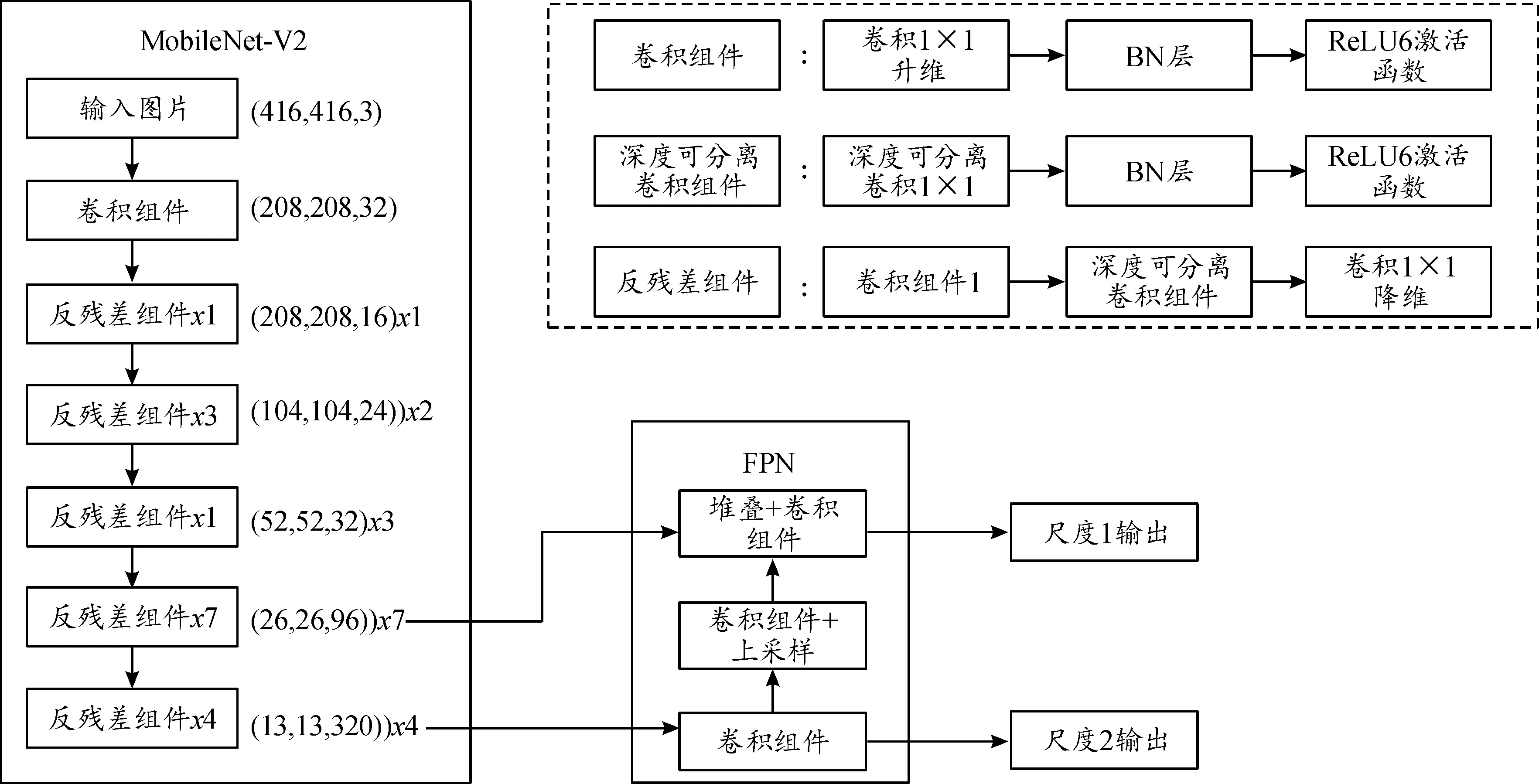
图2 EMLite-Yolo-V4结构图
1.2.1主干特征提取网络改进
首先,由于Yolo-V4的主干特征提取网络CSPDarknek53的参数量较大,导致在模型训练时耗时较长,所得模型占用内存空间较大,在处理一些简单的目标检测任务时检测速度会受到一定影响。所以使用MobileNet-V2替换CSPDarknek53[10]。其中MobileNet-V2是一种轻量级主干特征提取网络,其网络结构如表1所示。其中Input为输入维度,Operator为操作组件,t为瓶颈层内部升维的倍数,c为特征的维度,n为该瓶颈层重复的次数,s为瓶颈层第一个卷积的步幅。Operator中的bottleneck表示线性瓶颈层,Conv2d表示二维卷积操作,Avgpool表示平均池化操作。

表1 MobileNet-V2网络结构
MobileNet-V2的核心是利用深度可分离卷积块(图3)代替普通卷积块[11-12]大幅度减少参数量,其中深度可分离卷积过程如图4所示。
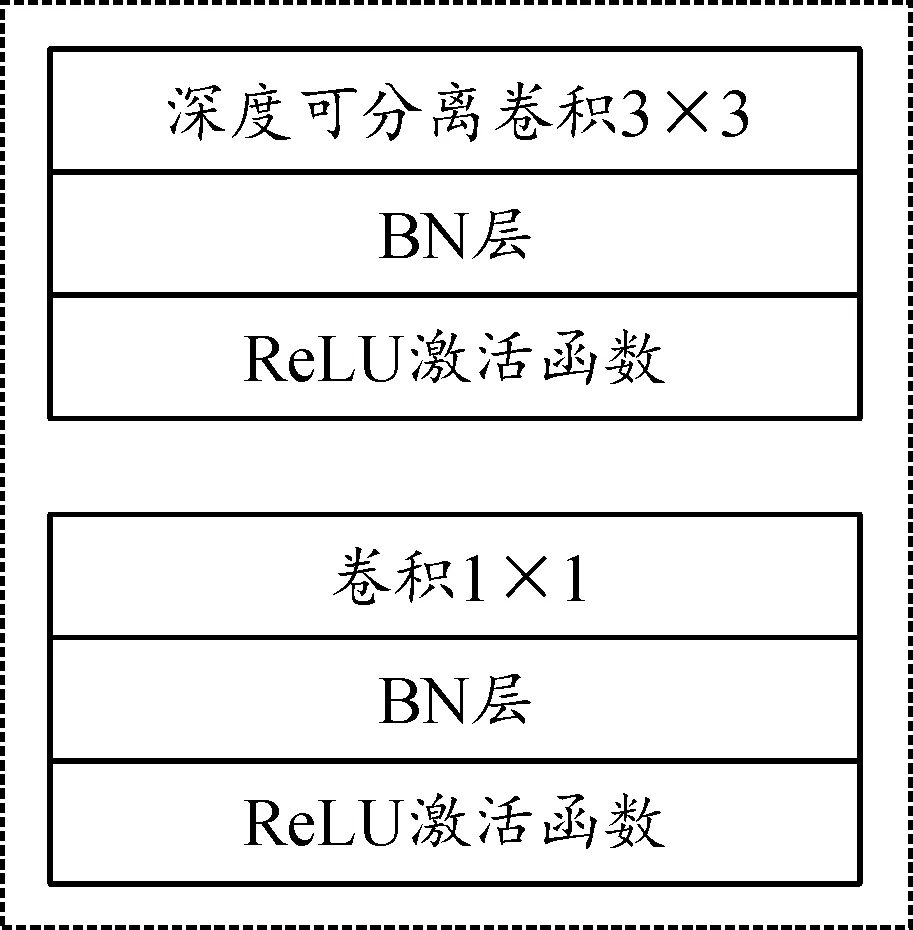
图3 深度可分离卷积结构图
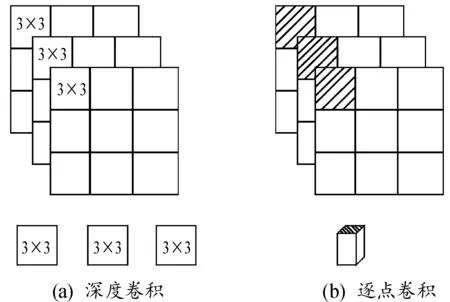
图4 深度可分离卷积过程图
其中,普通卷积计算过程如图5所示。假设输入图片维度为(din,din,C),其中C为图片的通道数,(din,din)为图片的大小,假设卷积核大小为(dk,dk,C),共有N个,执行普通卷积计算后输出大小为(dout,dout,N)。普通卷积总计算量S1为:
(1)
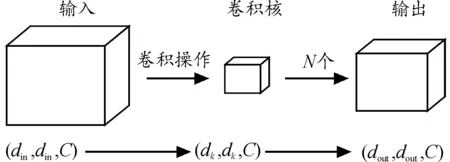
图5 普通卷积计算过程
深度可分离卷积计算过程分为2步,如图6所示。第1步为深度卷积,输入图片仍为(din,din,C),在深度卷积操作中卷积一次应用于单个通道,因此卷积核大小为(dk,dk,1),共有C个,则输出图片大小为(dout,dout,C);第2步为逐点卷积,输入图片为深度卷积的输出(dout,dout,C),在深度卷积操作中卷积一次应用于单个通道,因此卷积核大小为(1,1,C),共有N个,则输出图片大小为(dout,dout,C)。深度可分离卷积的总计算量S2为:
(2)

图6 深度可分离卷积计算过程
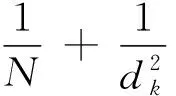
1.2.2加强特征提取网络改进
Yolo-V4的加强特征提取网络PANet、SPP中的卷积结构比较复杂,也导致了整个网络参数量的增加。因此,EMLite-Yolo-V4中将 PANet、SPP替换为一种轻量级的特征金字塔FPN-tiny,如图7所示。FPN-tiny利用多尺度手段有效提升了小目标的检测效果,同时由于FPN-tiny获得了更加鲁棒的高层语义特征,使得模型学习过程更为高效,进而提升模型准确率,以弥补整体网络参数减少而带来的精度损失。
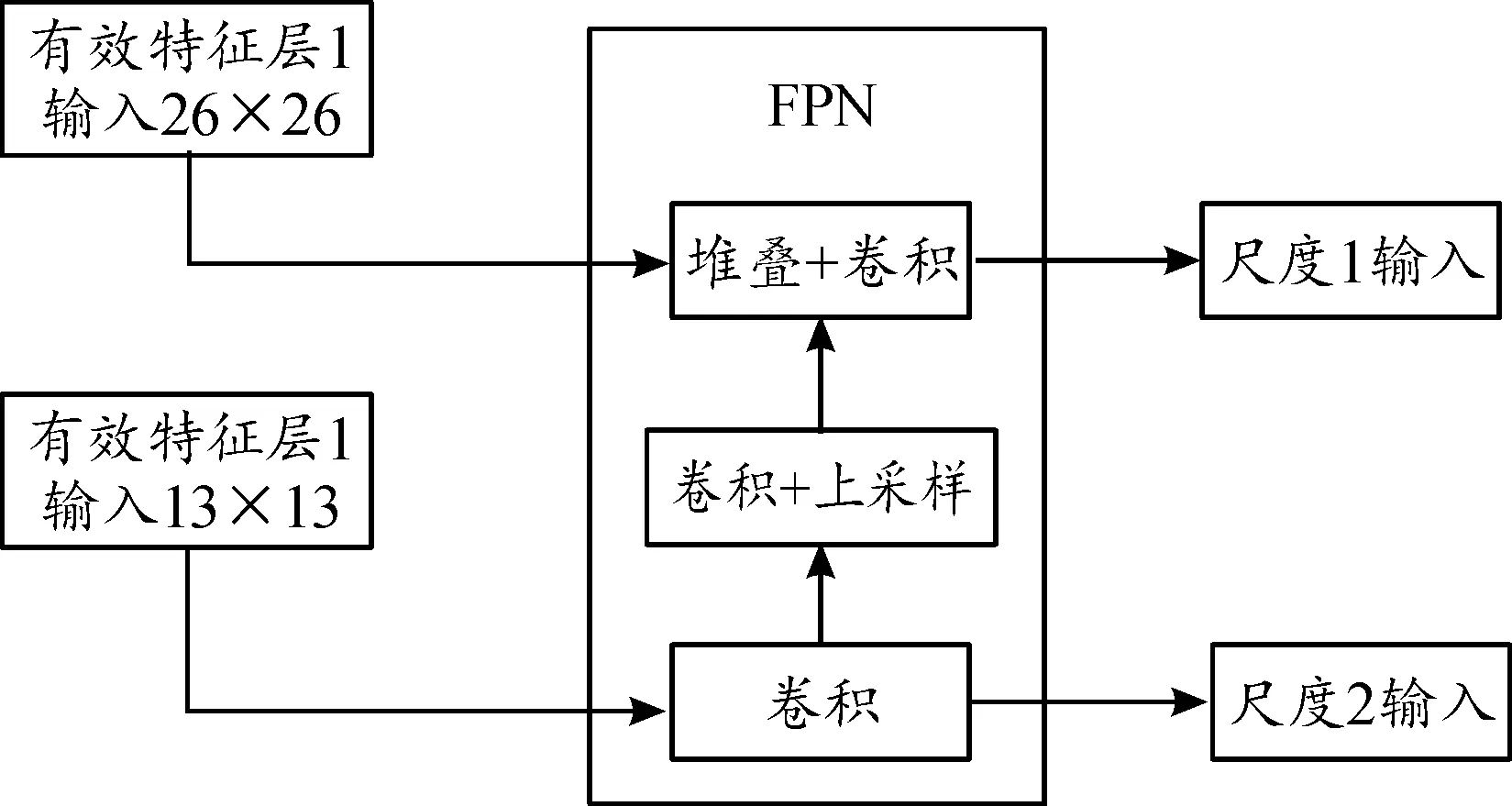
图7 FPN-tiny结构
1.2.3柔性非极大值抑制(Soft-NMS)与卷积通道参数alpha改进
针对本文数量较少且目标大小中等的检测目标时,由于先验框数量固定为3个尺度共类聚9个中心点,导致需要比较的预测框数量较多,此时若进行柔性非极大值抑制,每个预测框需要计算得分与重合度2个指标。由于待检测目标大小适中,检测背景较为简单,且在检测过程中被检测目标为无相对位移的目标,不会出现被检测目标重合问题,这样导致计算预测框重合度就为冗余操作,检测精度并没有提升,反而使得检测速度变慢。所以EMLite-Yolo-V4网络结构中将柔性非极大值抑制剔除计算预测框重合度的因素,在不丢失检测精度的同时提高检测速度。如表2所示,对同一帧图像进行眼嘴特征检测,分别使用改进前后的柔性非极大值抑制进行实验,结果表明,改进后的非极大值抑制在单帧检测时间上可减少将近一半,使得EMLite-Yolo-V4网络的检测速率进一步加快。

表2 柔性非极大值抑制改进对比结果
为了继续缩减网络参数量,通过修改卷积通道alpha系数,将默认值1改为0.5,使得主干提取网络与加强特征提取网络中卷积通道数减少,使得EMLite-Yolo-V4网络的参数量只有9 MB。
2 模型训练与分析
2.1 数据集
YawDD(a yawning detetion dataset)为公开的疲劳驾驶打哈欠数据集[13]。ZJU(Zhejiang University dataset)为浙江大学公开的人脸眨眼视频数据集[14]。融合2个数据集构成一个包含具有睁眼、闭眼、张嘴、闭嘴4种特征的完整数据集。该数据集包含2组具有不同面部特征驾驶员的视频数据,且视频均是在真实和变化的驾驶状态光线条件下拍摄的。该数据集包括来自不同肤色的、戴或不戴眼镜的男女驾驶员的面部信息,根据本实验要求标注了睁眼、闭眼、张嘴、闭嘴4种特征。为了满足实验需求,在保证训练与验证结果一致性的前提下,对数据集进行了部分裁剪,裁剪后的新数据集包含4个眼嘴特征,共有5 544张驾驶员面部图像。表3给出了数据集按8∶1∶1的比例划分后的训练、验证和测试集。

表3 YawDD-ZJU数据集划分情况 张
2.2 融合离线数据增强与Mosaic数据增强
为了提高模型的泛化能力与鲁棒性,本文使用了2种数据增强方式,分别为离线数据增强和Mosaic数据增强。
离线数据增强包括数据翻转、数据旋转、数据缩放、数据剪裁、数据移位、增加高斯噪声和颜色增强7个方法。由于本文训练数据为人脸眼嘴特征,其中数据缩放、数据剪裁和数据移位会破坏特征的完整性。故只使用数据翻转、数据旋转、增加高斯噪声和颜色增强4种方法来增强数据集。如图8所示为4种数据增强方法的效果。

图8 离线数据增强方法
Mosaic数据增强直接对4张图片进行随机拼接,将拼接后的新图片传入训练网络中进行特征提取。使用Mosaic数据增强可以大大丰富检测目标的背景,进而提升检测精度。Mosaic数据增强方法如图9所示。

图9 Mosaic数据增强方法
2.3 模型训练结果对比
实验以主频2.30 GHz、内存16 G的Intel(r)Core(TM)i5-8300H处理器和Nvidia GeForce GTX 1060 GPU(6G显存)为实验平台,采用Tensorflow/Keras平台建立神经网络模型,并选择Tensorflow框架作为Keras平台的后端。训练时,采用冻结训练法和早停法(early stopping)加快训练速度。初始学习率设置为0.000 1,学习率衰减设置为0.000 01。输入数据维度为416*416,训练总世代数(Epoch)设置为100,冻结世代数设置为50,一次训练所选取的样本数(Batch size)设置为8。训练过程中的损失曲线与精度曲线如图10、11所示。
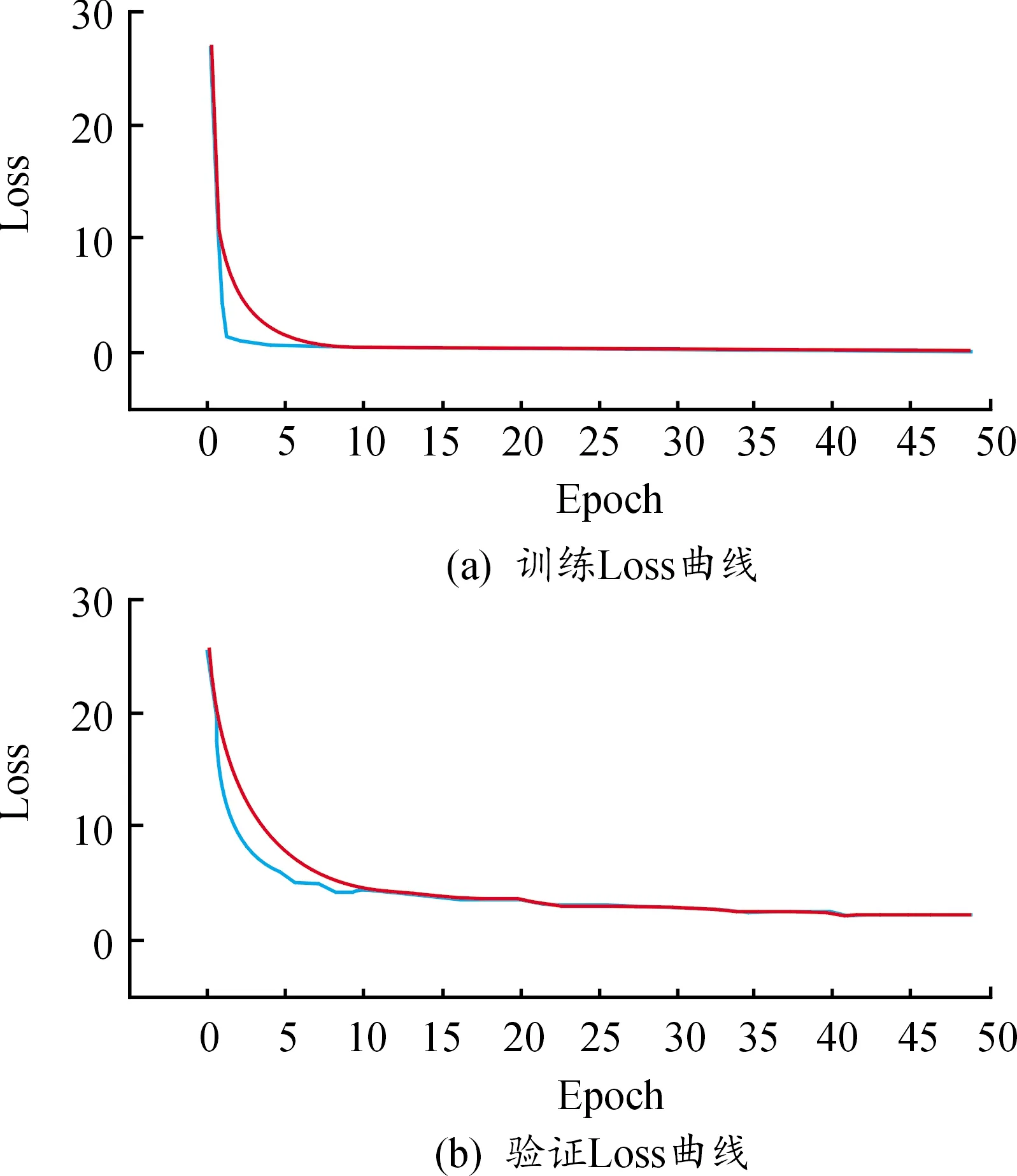
图10 损失曲线

图11 精度曲线
表4为4种眼嘴特征在EMLite-Yolo-V4模型下的性能数据,由表中数据可以得出模型对于4种眼嘴特征具有较高精度与检出率,平均分类精度达到97.39%,平均mAP为80.02%。

表4 4种眼嘴特征的模型性能数据
由表5数据可得,模型针对本文改进方法均较前阶段mAP值有一定提升,由于检测目标为驾驶员面部眼嘴特征,通过MobileNet-V2作为主干特征提取网络,融合FPN-tiny轻量级特征金字塔,在尽量不牺牲精度的情况下大幅度提升检测速度,使得EMLite-Yolo-V4模型检测效果显著提升,从而验证了本文改进方案的有效性。
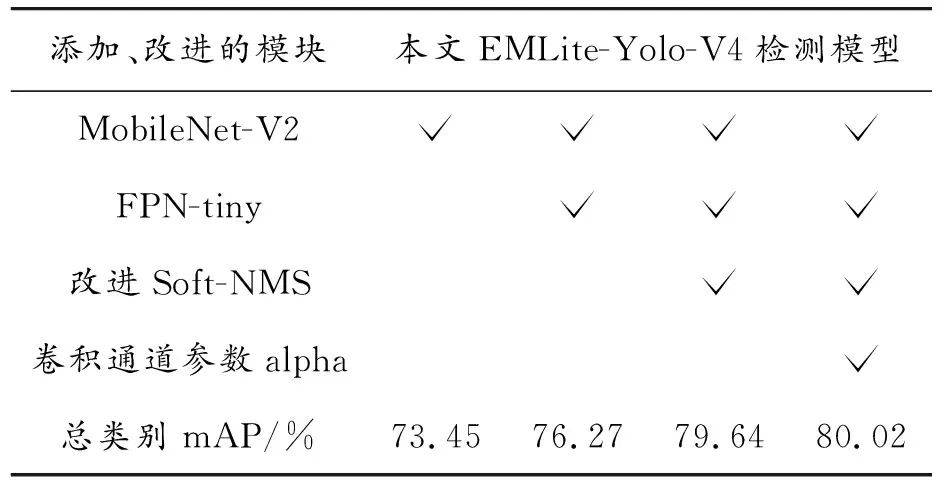
表5 EMLite-Yolo-V4分模块对比结果
对比其他Yolo-V4的改进方案,将本文EMLite-Yolo-V4与Yolo-V4和基于文献[15-17]网络训练好的模型做评价测试,该测试包含检测模型的预测时间、模型大小和模型平均分类精度。如表6所示,EMLite-Yolo-V4网络在预测时间、模型大小、mAP值上均优于文献[15-17]网络。EMLite-Yolo-V4网络的精度略小于Yolo-V4网络,但在预测时间与模型大小上均优于Yolo-V4。

表6 5种网络结构训练结果对比
为进一步验证在模型参数量降低后对检测精度的影响,针对卷积通道系数alpha值为1、0.75、0.5时3种情况,并进行对比实验。实验数据如表7所示。由表7可知,alpha值在1、0.75、0.5时,模型大小显著变化,由alpha为1时的149 MB减少到alpha为0.5时的9 MB。对比alpha为1与alpha为0.5时的模型平均分类精度可知,随着模型参数量大幅度减少,模型检测精度会受到一定影响,但该影响并不大,由表7中数据可知,alpha值从1减少为0.5,其平均分类精度分别减少了0.45%、0.05%,即模型在尽可能少牺牲检测精度的前提下大幅度提升检测速度。

表7 卷积通道系数alpha对比实验数据
为验证FPN-tiny对模型精度的提升,针对alpha为0.5时添加与未添加FPN-tiny模块进行对比实验。实验数据如表8所示。由表8中数据可知,在添加FPN-tiny模块后模型检测精度提升较多,且一定程度上可加快检测速度。验证了FPN-tiny具有提升模型识别精度的作用。
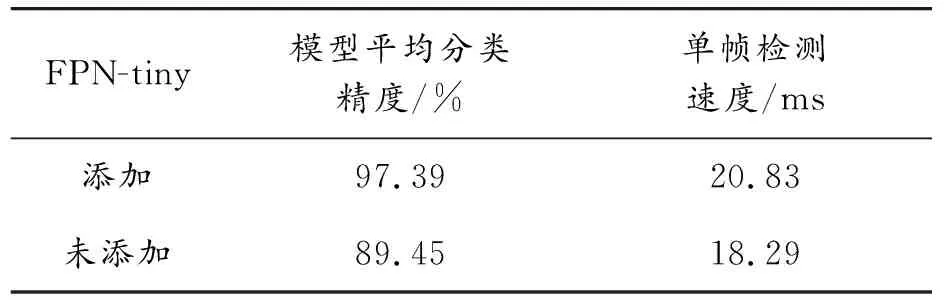
表8 FPN-tiny模块对比实验
3 模型部署
本文疲劳检测流程如图12所示,首先将实时采集到的驾驶员人脸图像输入至基于Haar特征的人脸检测分类器模块中[18]定位检测目标,然后将定位后的检测数据送至EMLite-Yolo-V4眼嘴特征检测模型进行疲劳特征提取与检测,最后将提取到的特征送入疲劳特征参数计算模块进行计算并输出最终的判定结果。
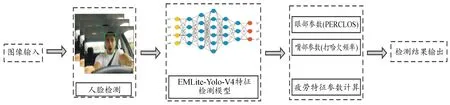
图12 疲劳驾驶检测流程图
其中疲劳特征参数计算模块功能是将驾驶员睁眼、闭眼、张嘴、闭嘴4种特征的检测结果记录并根据PERCLOS和单位分钟打哈欠阈值数计算出疲劳程度,依据疲劳程度分数得出最终的疲劳驾驶检测结果。其中疲劳程度分为3个等级,分别为正常驾驶状态(NDS)、轻微疲劳驾驶(LFDS) 、严重疲劳驾驶(EFDS)。分类依据如表9所示。

表9 疲劳程度分类依据
为验证本文模型对3种疲劳驾驶状态的检测效果,随机抽取了3名实验人员进行检测实验。实验模拟真实驾驶环境,由实验人员正前方摄像头实时采集面部信息,并且实验人员按照要求分别模拟出3种疲劳驾驶状态。每位实验人员分别进行100次模拟实验,共进行300次模拟实验。实验数据如表10所示。由表10可知,3种疲劳驾驶状态的误检率较低,且平均分类准确率达到98.28%,证明3种疲劳驾驶状态分类精度较高;其漏检率较低,证明本模型实际检测更具稳定性与鲁棒性;模型检测速度较快,实时FPS可达到46帧/s,检测实时性较高。实验过程中实时监测情况如图13所示。
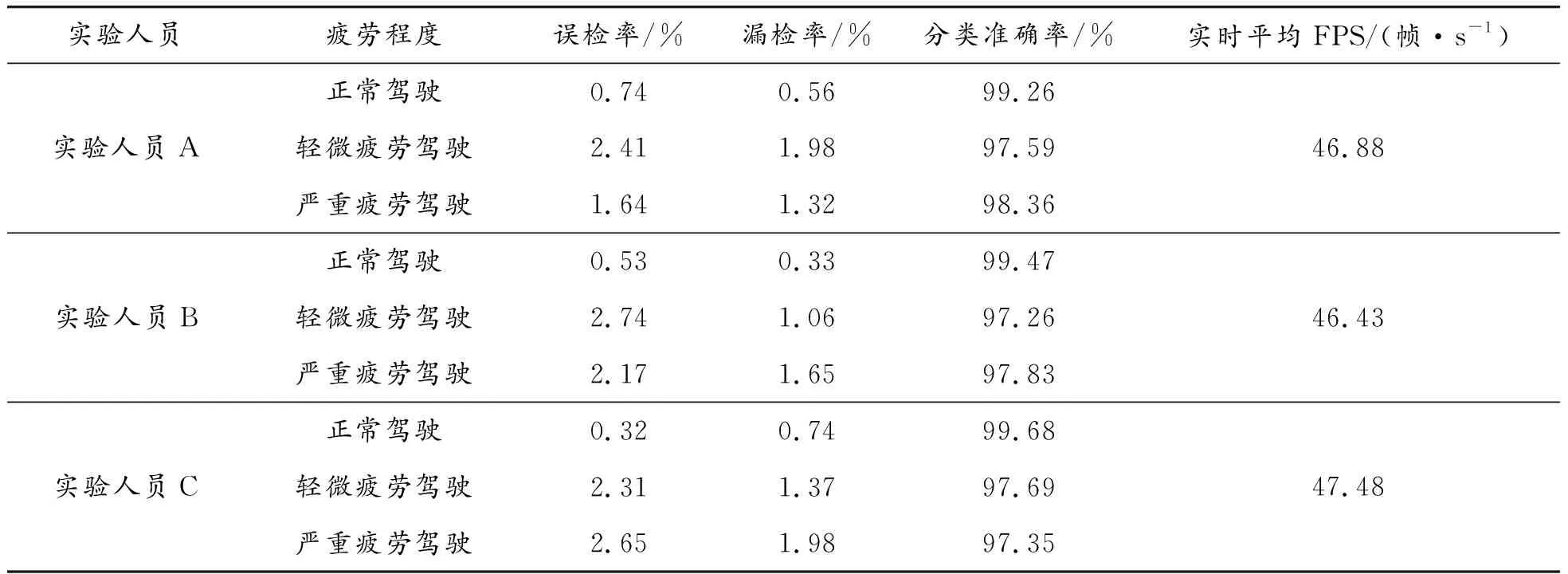
表10 疲劳程度实验数据
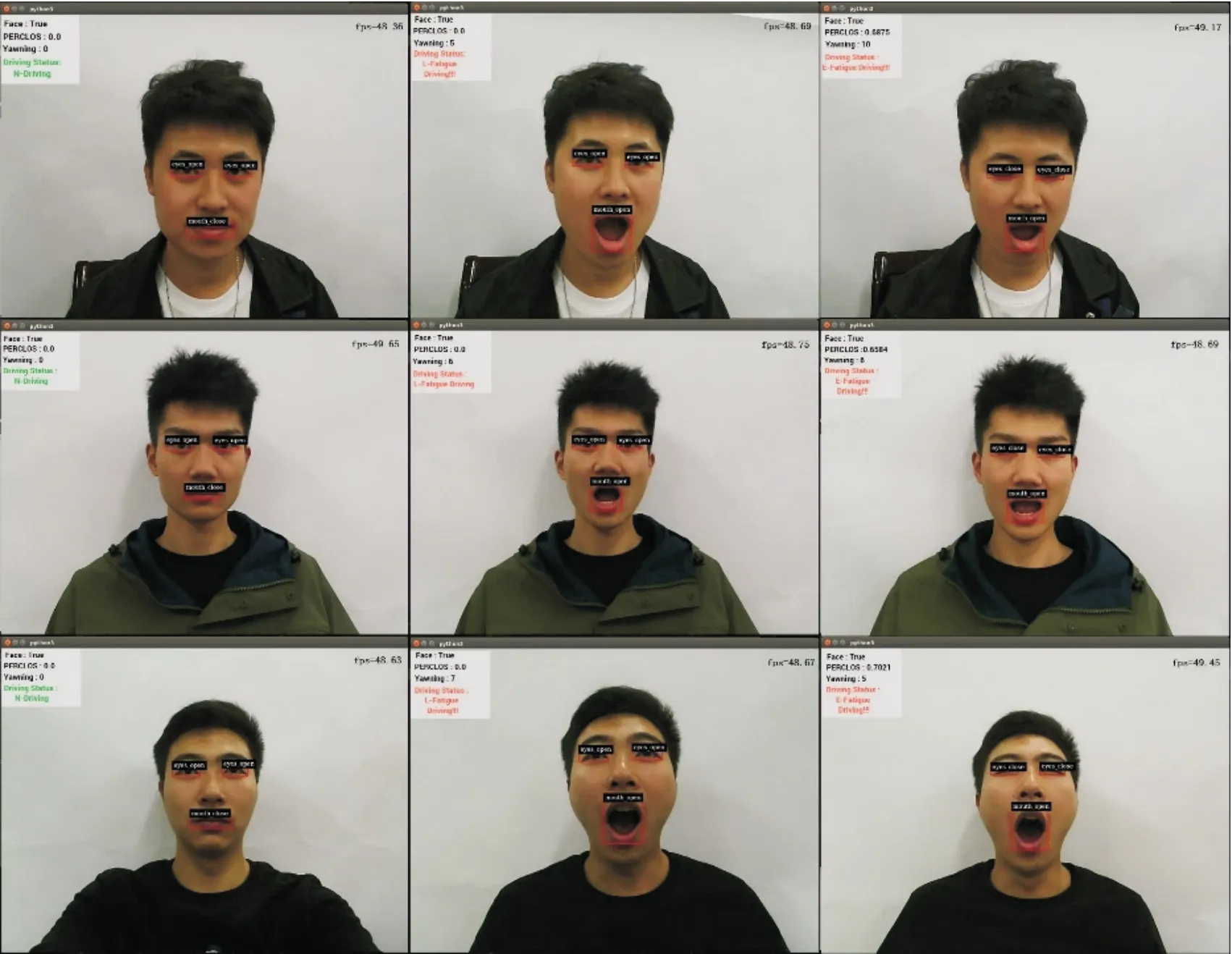
图13 疲劳程度实验实时监测图
4 结论
针对疲劳驾驶检测的准确性与实时性不平衡的问题,提出一种基于轻量化卷积神经网络EMLite-Yolo-V4的疲劳驾驶检测方法。通过使用轻量化卷积神经网络MobileNet-V2替换了Yolo-V4原有的主干提取网络,联合卷积通道参数alpha的缩小,使得整个EMLite-Yolo-V4网络的层数更少,检测速度更快。加入FPN-tiny轻量级特征金字塔模块过滤图像中的冗余信息,减少了EMLite-Yolo-V4在检测速度提升时带来的精度损失。同时,针对本文检测目标体积改进了Yolo-V4原有的Soft-NMS,在检测过程中无需再同时考虑目标框的得分与重合度,使得本文方法检测速度进一步提升。最后通过对比实验证实了本文网络模型的有效性,整体检测精度达到97.39%,mAP值达到80.02%,较当前主流目标检测网络模型具有更高的精度。本方法在光线条件较好时具有较为稳定的检测效果,在后续工作中会加入红外图像,检测光线条件较差时的疲劳状态。
