基于RGB-D图像的移动端点云分割方法研究
2022-03-23余方洁
余方洁,王 斌
(1.中国科学院长春光学精密机械与物理研究所, 长春 130033; 2.中国科学院大学, 北京 100049)
点云是一种重要的三维数据结构,它是具有相同空间参考的一组物体表面特征点集合。点云数据语义分割作为三维场景理解的关键性技术,在无人驾驶、数字城市、高精地图、VR、AR等领域得到了广泛的应用。传统的点云分割流程包括前期数据采集与桌面端后期处理2个阶段,其中常用的采集设备有激光雷达、TOF相机等,它们通常价格昂贵且有安装结构要求,此外这种前后端分离的工作模式在实时性方面也表现较差。本文通过对深度图获取原理及点云分割方法的研究,提出了一种仅凭借智能手机等轻量级移动端设备就可以实现三维数据采集和准实时语义分割的技术方案,旨在进行前后端的无缝集成。
语义分割是计算机视觉的基本研究任务之一,是将输入数据映射到现实世界中事物的可解释类别的技术。近年来,随着大数据的出现与计算机硬件性能的大幅提升,基于深度学习的点云分割方法已经成为当前的主流。根据对三维点云数据处理方式的不同,又可分为间接语义分割法和直接语义分割法。间接语义分割法主要借鉴了以往二维图像分割的经验,通过将点云数据转换为多视图或体素网格,很大程度上利用二维的网络模型间接达到分割的目的。在多视图的方法中,Su等[1]提出了MVCNN(multi-view convolutional neural network),将三维目标投影为多个不同视角下的二维图像,对每个视图进行特征提取并经过特征聚合得到最终的分割结果;Feng等[2]在MVCNN的基础上提出了GVCNN(group-view convolutional neural network),对不同视图提取的特征进行分组,提高了网络性能;Zeng等[3]基于FCN(fully convolutional networks)[4]并结合HHA投影技术实现了对RGB-D数据的语义分割;Wu等[5]借鉴SqueezeNet[6]的设计思路提出了SqueezeSeg网络,使用球面投影的方法将三维点云转换为二维图像输入到SqueezeSeg中进行分割。不同于多视图方法对数据进行降维的操作,体素化方法致力于构建三维语义分割网络,Maturana等[7]将卷积运算推广到三维空间,最早提出了基于体素数据的VoxNet模型;针对体素网格分辨率低的限制,Tchapmi等[8]提出了SegCloud网络;为了更加合理地利用点云数据的特点并减少计算量,Riegler等[9]基于八叉树结构提出了OctNet,Klokov等[10]基于Kd-tree结构提出了Kd-Net。在点云直接语义分割方法中,Qi等[11]在CVPR2017上开创性的提出了PointNet网络,它不需要对输入数据做任何变换,可以直接通过端到端训练的方式实现点云分割,为三维场景理解指明了新的发展方向;由于对空间邻域信息感知较少,Qi等[12]又提出了PointNet的改进版本PointNet++,通过对数据进行采样、分组的方式提取局部特征,并使用MSG(multi-scale grouping)、MRG(multi-resolution grouping)等策略自适应处理密度不均匀的点云数据。
深度图可以等效为三维密集点云,针对移动端深度图像获取的任务,谷歌的Valentin等[13]提出了depth-from-motion算法,它可以从运动中恢复深度信息;商汤科技的Yang等[14]基于多视图关键帧的深度估计方法,提出了一个手机端实时单目三维重建系统Mobile3Drecon。移动端设备由于资源和算力等受限, 因此在对深度学习模型进行部署时,通常需要经过网络压缩处理,减少其参数量与运算量。在此方面,研究者们也提出了许多模型压缩方法,如紧凑网络、参数剪枝、低秩分解、知识蒸馏等。
同时,许多轻量化网络也被证明具有相当好的效果,已经在移动端设备上进行了成功的应用,如SqueezeNet[6]、MobileNet[15]、ShuffleNet[16]、Xception[17]等。
本文利用移动端设备轻量、便捷的优势,对安卓平台的点云分割方法进行研究,主要贡献如下:
1) 提出了一种仅使用移动端设备进行三维数据采集与处理的一体化解决方案,包括了深度图像获取、点云转换、模型压缩、移动端部署与加速整个处理流程,改变了以往前后端分离的应用模式。
2) 对点云语义分割网络PointNet进行轻量化设计,使参数量减少为原来的1/5,同时在测试集上的平均分割精度达到了73%,在启用GPU加速后,对单幅场景点云数据的推断速度约为0.7 s。
系统整体架构如图1所示。

图1 系统整体架构
1 三维点云分割方法
1.1 点云特点
1) 无序性
点云是点数据的集合,这意味着其中的数据是没有顺序的,因此对于按照不同排列输入的同一集合的数据,点云处理模型应该对于这种变化具有不变性。
2) 稀疏性
点云的本质是对空间中物体形状的低分辨率重采样,而且由于采集过程中存在的目标遮挡等情况,其获得的几何信息是片面、不完整的。
3) 密度不均匀性
不同方式获取的点云数据,其点间距、密集程度等往往相差很大,即使同一批次采集的点云数据,也经常存在密集和稀疏的区域。
1.2 点云分割方法
随着深度学习技术的不断成熟,其在点云语义分割领域也得到了越来越多的应用,取得了比传统方法更优的效果。根据点云数据处理方式的不同,基于深度学习的点云语义分割方法可分为间接语义分割法和直接语义分割法[18]。
1.2.1间接语义分割法
间接语义分割法需要将点云数据转换为其他的表示方式,通过这种数据结构的转变间接实现点云数据语义分割,根据转换类型的不同,分为二维多视图法和三维体素化法两类。
二维多视图法的基本思路是对点云数据进行投影,得到多个视图的二维图像,再对这些二维图像使用经典的语义分割模型如FCN[4]、U-Net[19]、Segnet[20]、DeepLab[21]等进行处理。多视图法很好地克服了点云数据的非结构化特性,通过卷积神经网络提取各个视图的特征,并将多个特征的信息整合为更高级的语义特征,得到最终的分割结果。但是多视图的方法在简化点云数据处理的同时,也丢失了原始数据中包含的大量关键空间信息,影响了点云分割的精度。
体素(Voxel)是二维空间中像素概念的推广,体素化的本质是将无序、非结构的点云数据规则化,这解决了点云数据的特征学习问题,但点云的稀疏性导致了体素网格数据冗余多、占用空间大、分割效率低。此外体素化方法相比二维图像增加了一个维度,计算过程中的资源开销更大,这也一定程度上限制了体素网格的分辨率。总的来说,体素化方法在现阶段实用性相对较低。
1.2.2直接语义分割法
为了充分利用点云数据本身的特性并降低计算复杂度,人们开始研究直接对原始点云数据进行处理的网络模型,其中具有开创性和代表性的是Qi等[12]提出的PointNet网络。
PointNet网络设计时充分考虑了点云的无序性、旋转和平移不变性、空间相关性,并经过严格的推理证明提出了2个定理:一是证明了PointNet网络能够拟合任意的连续集合函数,二是其网络结构对于有噪声和数据缺失的点云同样具有鲁棒性。对于点云无序性,PointNet使用对称函数来提取点云数据的特征;为了保证旋转和平移不变性,PointNet网络通过训练一个小型网络T-Net得到转换矩阵,并用来对输入的点云数据进行空间变换;为了有效利用点云之间的空间关系,PointNet网络使用跳跃连接(skip connection)的方式将浅层特征与高层特征相结合。
虽然PointNet网络在点云分割方法中取得了突破性的进展,但由于对各个点的操作过于独立,以及未考虑点云的密度不一致性,因此仍有很大的改进和提升空间。后来研究者们在PointNet网络的基础上又提出了一系列的优化算法,这些方法主要有基于邻域学习的方法、基于图卷积神经网络的方法、基于注意力机制的方法、基于循环神经网络的方法等。
2 深度图获取与转换
2.1 常用获取方法
深度图(Depth map)是一种特殊的二维灰度图像,它的每个像素值反映的是场景中各个物点距离传感器的实际距离,是物体可见表面几何形状的写真。深度图像通常是与彩色RGB图像经过配准的,被合称为RGB-D图像,它们的像素点之间具有一一对应的关系。
深度图的获取有多种方法,根据传感器工作原理的不同,分为主动式和被动式两类。主动式方法主要有激光雷达成像法、结构光法、TOF相机、莫尔条纹法、坐标测量机法等,它们的共同特点是在获取深度信息时需要激光等光源主动向物体发射信号并解析回波,这类方法也是目前在实用中被研究最深入、使用最广泛的一类;此外还有被动式的单目、双目、多目立体视觉的方法,这些都是基于多视图几何原理的通过对图像的理解来恢复三维结构,其相对主动式的方法而言成本更低也更加便捷,因此近年来也受到了越来越多的关注。
2.2 depth-from-motion算法
本文通过对深度图获取方法的研究,探索了在移动端设备上创建深度图的解决方案,结果表明depth-from-motion算法具有可行性,其实质是属于单目深度估计算法的一种,可以从运动中恢复深度信息。
depth-from-motion算法由谷歌的Valentin等[13]研究者于2018年提出,是一种专门针对智能手机设备获取深度图任务设计的算法,使得在大多数智能手机上仅通过标准的彩色摄像头就可以在单核CPU上创建30 Hz频率的密集、低延迟的深度图。
如图2所示,展示了depth-from-motion算法的基本处理流程。算法的第一步是从过去的图像帧中选择适合与当前帧进行立体匹配的关键帧,接着使用关键帧和当前帧之间的相对6 DoF(自由度)位姿进行极性图像校正,再根据视差就可以得到估计的稀疏深度图。将稀疏深度图送到快速双边求解器(fast bilateral solver)中进行求解,生成与之相应的双边深度网格(bilateralgrid of depth),双边深度网格可以根据需要转换为经过时空平滑的密集深度图。为了保证生成的深度图与RGB图像对齐,在生成双边深度网格后,还需要使用最新的图像帧对其进行切片,再经过后期渲染就能得到密集的平滑深度图。
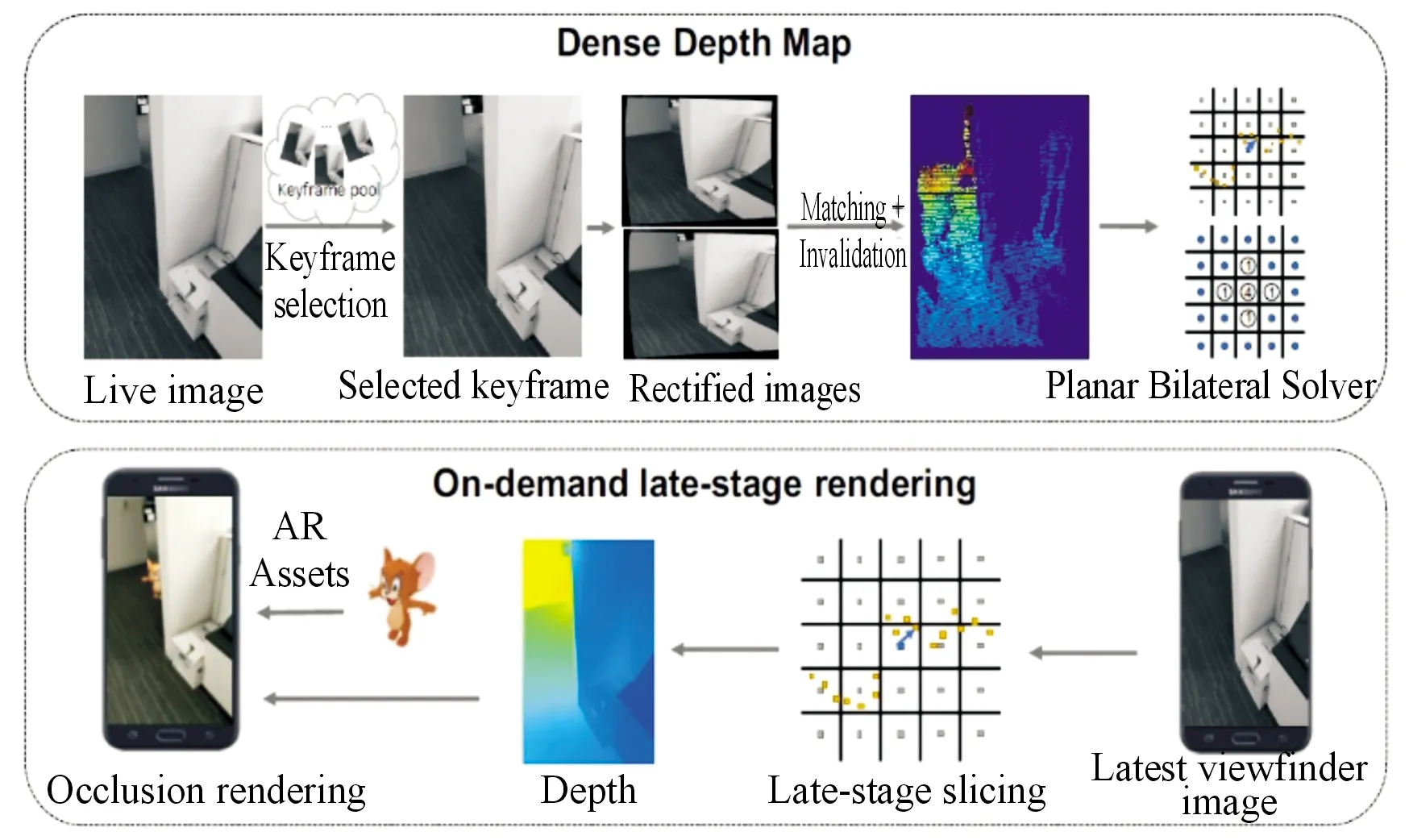
图2 depth-from-motion算法流程
谷歌现已开源了集成有depth-from-motion算法的增强现实开发平台ARCore,并支持iPhone、iPad、华为、三星、小米等制造商的多个型号的设备。本文使用Android Studio 4.0开发环境,并借助ARCore SDK进行了华为nova3智能手机设备上的深度图获取实验,图3中展示了谷歌给出的官方效果图(a)与自己创建的深度图(b)对比:

图3 深度图获取实验
2.3 相机模型
深度图像中包含有被摄场景的三维空间信息,通过对相机成像模型的研究,可以从深度图中解算出每个像素点所对应的三维坐标,生成点云数据。深度图到点云的转换利用的是多视图几何的原理,其实质是图像坐标系到相机坐标系的变换,如图4所示。

图4 相机模型
转换过程中需要已知相机的内标定参数cx、cy、f,其中cx、cy表示的是相机成像时光心在像素平面坐标系下的坐标,f是相机焦距。另外记焦距f与单个像素在x、y方向实际距离dx、dy的比值为fx、fy,由此可以得到相机的内参数矩阵:
(1)
记像素平面坐标系中像素点的坐标为u、v,相机坐标系中空间点的坐标为X、Y、Z,如图4所示,根据相似三角形原理可知:
(2)
式(2)实际上已经给出了像素平面坐标与相机空间坐标的转换公式,为了表示方便,将其写为矩阵的形式:
(3)
式(3)给出的变换就是我们需要的转换公式,它表示了从深度图像上读取像素坐标u、v以及深度值Z,利用相机内参数矩阵,就可以解算出对应的三维空间坐标X、Y、Z。
3 深度学习模型压缩算法
深度学习在计算机视觉、自然语言处理等领域取得显著效果的同时,模型的结构也变得越来越复杂。对于移动设备来说,其内存空间有限、运算能力有限、续航时间短、散热条件不利,这都将导致深度学习模型在移动端设备上进行实际部署时,将会遇到很大的限制。因此使用一定的方法对模型进行精简,使之更加轻量且具有相当的准确率是非常必要的,对于深度学习模型的移动端部署具有重要的意义。
目前主要的模型压缩方法有紧凑网络、参数剪枝、参数量化、知识蒸馏等,根据压缩策略的不同又可分为压缩结构与压缩参数两类[22]。两类模型压缩方法的技术描述如表1所示。

表1 深度学习模型压缩算法
在对深度学习模型进行压缩的实践过程中,出现了几种具有代表性的轻量级网络,它们在减少网络参数量的同时保持了网络的性能,使移动终端、嵌入式设备运行神经网络模型成为可能,对其后的轻量级网络设计具有重要的启发与借鉴意义,表2对几种经典的轻量级网络进行了对比总结。
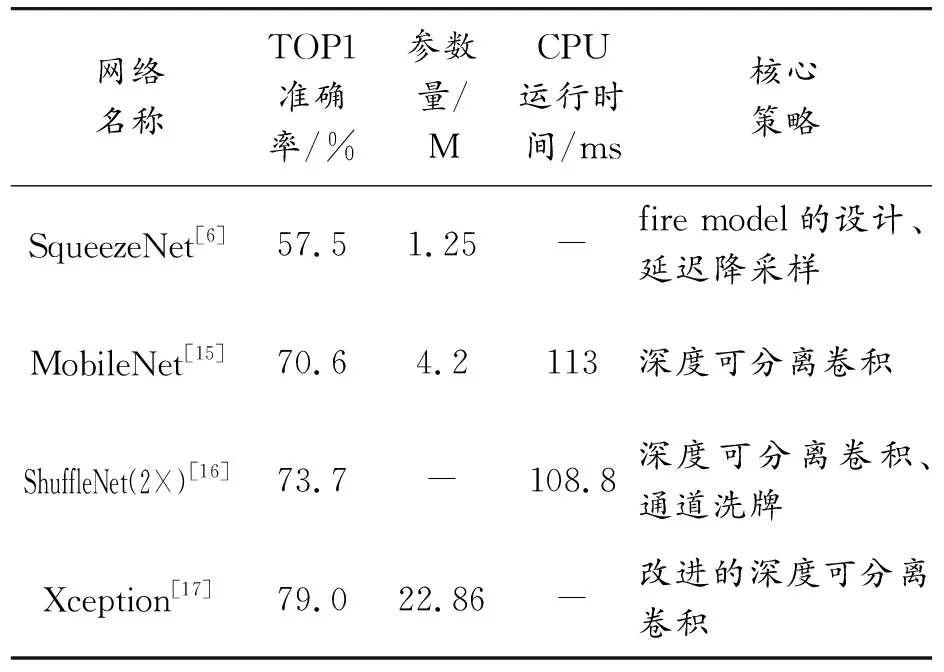
表2 几种轻量级网络对比
4 实验及结果分析
4.1 数据集获取与处理
目前随着深度卷积神经网络在三维点云分割中的广泛应用,许多研究机构推出了一系列公开且可靠的三维数据集,如S3DIS、Semantic3D、SUNRGB-D、KITTI、Apollo等。在综合考虑使用场景与数据集规模后,本文选择SUN RGB-D数据集进行模型训练与测试。
SUN RGB-D是普林斯顿大学Vision & Robotics 实验室开发的用于室内场景理解的数据集,该数据集共包含10 335张经过密集标注的RGB-D图像,分别由Intel RealSense、Asus Xtion、Kinect v1、Kinect v2 4种不同的3D传感器采集图像和深度信息,共有146 617个2D多边形和58 657个3D边界框,包含了场景分类、语义分割、物体检测、物体朝向预测、房间布局预测等标注[23]。
针对本文的语义分割任务,使用SUN RGB-D数据集的子集NYUdata作为实验数据。NYUdata是由Kinect v1的RGB摄像机和深度摄像机同步拍摄的室内场景的视频连续帧中提取出来的,包含了1 449组具有像素级标注的彩色和深度图像对,每张图像的宽度为561像素、高度为427像素。
由式(3)可知,在确定了相机的内参数后,即可将二维像素坐标转换为三维空间坐标。查找资料可知,Kinect相机的固有内参数如下:
fx= 525.0,fy= 525.0
cx= 319.5,cy= 239.5
另外,Kinect在保存像素值时进行了比例缩放,比例因子factor为5 000,因此实际的Z坐标等于读取的深度值除以5 000。由于深度图像与彩色图像的对应关系,可以结合XYZ空间坐标与RGB颜色信息,得到每一组图像对所对应的RGB点云数据,其在三维处理软件MeshLab中的可视化效果如图5(c)所示:
原始数据中的标签类别为894类,为便于模型训练与结果可视化,可以利用元数据中.mat格式的类别映射文件将标签类别转换为40类或13类,这里选择将894类映射到13类。RGB图像(a)与映射后的标签图像(b)如图6所示:

图5 点云转换结果

图6 标签类别映射
4.2 模型压缩
4.2.1改进策略
为了使PointNet点云分割网络能够以较快速度、较高精度运行在移动端设备上,本文结合紧凑网络和参数剪枝2种模型压缩方法对PointNet进行改进。
紧凑网络当前比较成熟的做法是卷积核级别的重新设计,通常是用多个小的卷积核替代大的卷积核。本文借鉴MobileNet[15]等轻量级网络的设计思路,将PointNet中的全连接层替换为深度可分离卷积(depth-wise separable convolution),在有效减少模型参数量的同时保持了推理的精度。深度可分离卷积的实质是分组卷积(Group Convolution)和1×1卷积的结合,最大程度上实现了通道间的解耦。此外还使用减少网络宽度、深度的方式对PointNet进行了结构化的通道剪枝和层间剪枝。改进后的PointNet网络结构及参数设置如图7所示。

图7 改进的PointNet网络
4.2.2网络结构分析
改进后的PointNet网络共有12层,整体可分为3个部分。第一部分是前5层Conv1~ Conv5,主要作用是逐级提取浅层特征,层名称后面的参数如1×1、1×9等表示的是卷积核尺寸,最后一个参数表示输出通道数,卷积层中的其他细节还包括高和宽2个方向上的滑动步长为[1,1],填充方式使用的是“valid”类型,激活函数为修正线性单元ReLU,这些参数设置对于其他部分的卷积操作也是一致的;第二部分是中间3层,主要作用是筛选全局特征和增加网络表达能力,该部分对于Conv5的输出先作一个最大池化,池化时的卷积核尺寸为n×1,相当于每个输出通道保留一个特征,共得到256个全局特征,接着经过2个替代了全连接层的可分离卷积操作对全局特征进行非线性变换,输出128个特征值;第三部分是最后4层,作用是对前两部分提取的浅层和全局特征进行跳跃连接并输出最终分割结果,得到每一个点属于13个类别中各个类别的概率。
4.3 模型训练
4.3.1评价指标
语义分割算法的性能评价标准主要分为以下几个方面:精确度、空间复杂度和执行时间。其中精确度的评价指标主要有总体精度(overall accuracy,OA)、平均精度(average accuracy,AA)、平均交并比(mean Intersection-over-Union,mIoU)、Kappa系数等。本文中使用OA和AA作为评价指标,其定义分别如下:
(4)
假设共有k+1个语义类别(包括一个背景类),pij表示本属于i类实际预测结果为j类的点云数量,则pii表示预测正确的点云数量。OA指标反映了每一个随机样本的语义分割结果与真实标注类型的总体概率一致性。
(5)
AA指标中pii、pij的定义与OA中相同,它是总体精度的一种简单提升,反映了每个类别预测准确率的平均值,即平均类别精度。
4.3.2训练过程
在Windows 10平台,编程环境选择PyCharm,显卡设备是NVIDIA-1080Ti,使用深度学习框架TensorFlow进行模型训练。网络超参数设置为批量数batch_size=24,初始学习率learning_rate=0.001,使用指数衰减法进行学习率调整,decay_step= 300 000、decay_rate=0.7,迭代次数max_epoch= 200。损失函数为softmax交叉熵,优化器选择Adam算法,训练集、验证集、测试集的比例分别为60%、20%、20%。训练集(train)、验证集(val)上的总体精度分别为0.77、0.74,验证集上的平均精度为0.69,训练过程如图8所示。
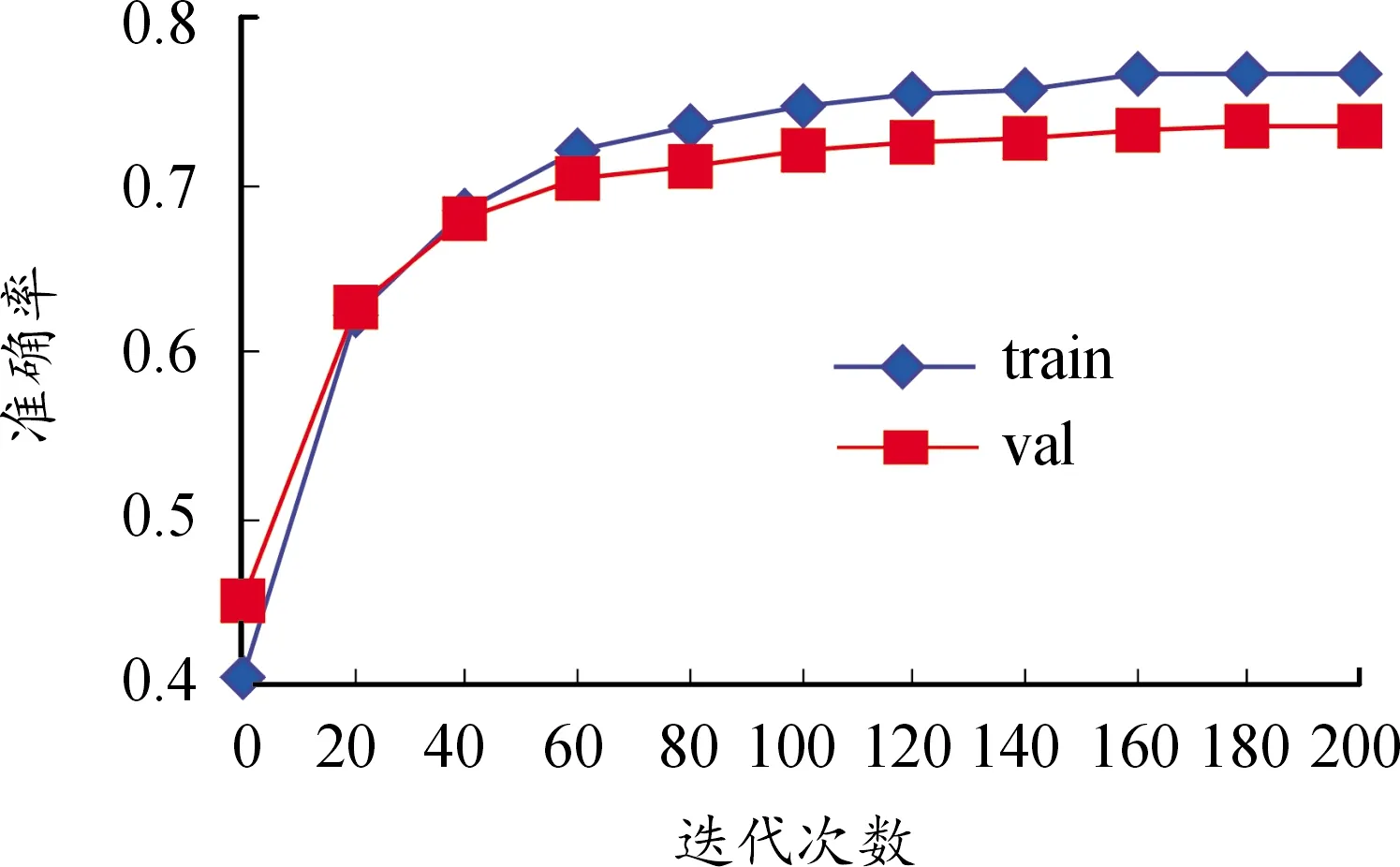
图8 模型训练过程
4.4 移动端部署与加速
TensorFlow Lite是专为Android和iOS等移动平台设计的深度学习解决方案,提供了转换 TensorFlow 模型并在移动端、嵌入式和物联网(IoT)设备上运行 TensorFlow 模型所需的所有工具。整个模型转换过程分为2个阶段,首先是对保存的checkpoint模型文件进行持久化操作,将其中的变量值固定,冻结为pb格式;再使用TensorFlow Lite 转换器将pb文件转换生成最终的tflite文件。模型转换流程如图9所示。

图9 模型转换流程
模型部署的最后一步是使用tflite文件在安卓设备上进行推理。本文基于Android Studio 4.0搭建运行环境,使用Kotlin作为开发语言,在工程的build.gradle配置文件中添加tensorflow-lite相关依赖后就可以调用TFLite解释器运行输入数据并获得预测结果。
实测时使用的是华为nova 3 智能手机, CPU为海思麒麟 970,GPU为Mali G72 MP12,运行内存6 GB,存储空间128 GB,运行过程中发热情况一般,未启用GPU加速时推断一幅图像约需1.8 s。将配置文件中的相关依赖替换为GPU版本后即可实现运行加速,启用GPU代理后的推理速度约为0.7 s。
4.5 实验结果分析
如图10所示,展示了4个不同场景下的点云分割结果,每行代表一个场景。使用本文改进的PointNet网络对深度图转换的点云进行分割,取得了不错的效果,总体精度为73.3%,对于场景中的主要类别,均能得到较好的分割结果。PointNet网络与本文改进后的模型在参数量、精确度、推理速度方面的定量性能对比如表3中所示。

图10 点云分割结果

表3 实验结果对比
从模型压缩的角度看,参数量减少了约80%,总体精度仅降低了2.7%,网络轻量化的同时也保持了较高的分割精度,模型训练和推断的速度进一步加快,证明了本文提出的改进算法的有效性;另外,从移动端部署的情况来看,将checkpoint模型文件大小从13.4 MB减少到了2.9 MB,经过参数量化并转为移动端的tflite文件后仅有268 kB;在启用GPU加速后,模型在华为智能手机上能够以准实时级速度进行推断,可以满足一般的即时查看需求。
5 结论
通过对深度图获取原理及点云分割方法的研究,提出了一种仅凭借移动端设备实现三维数据采集和准实时语义分割的技术方案。利用谷歌AR Core SDK,可以在Android、iOS等设备上很方便地获取16位深度图像,在相机内参已知的情况下可以转换生成密集点云数据。考虑到移动端设备的性能受限情况,对PointNet网络进行改进,将模型参数量压缩为原来的1/5,再利用TensorFlow Lite将checkpoint模型转换为可以运行在安卓手机上的tflite模型。实验结果表明,在启用GPU加速的情况下,部署的模型能以较高的精度和速度进行点云分割,证明了本文方法的可行性。
