基于Flink的工业大数据平台研究与应用
2022-03-22赵润发娄渊胜
赵润发,娄渊胜+,叶 枫,石 宏
(1.河海大学 计算机与信息学院,江苏 南京 211100; 2.南京广厦软件有限公司 工业大数据开发部,江苏 南京 210000)
0 引 言
针对工业大数据平台的研究[1-4],文献[5]采用Dubbo与NoSQL构建了工业领域大数据平台,为工业领域不断增长的数据提供了解决办法。文献[6]提出了一个面向工业的数据处理系统,其以Spark为框架,选取MySQL和HDFS为存储介质,实现了工业数据的快速分析。文献[7]将物联网与大数据相结合,构建了一个工厂能耗分析平台,实现了能耗数据的查询以及数据的分析。
目前工业大数据平台已得到广泛研究,但工业大数据平台技术架构不同,差异性较大,再者对于很多工业大数据平台而言,其数据处理效率较低,预警时间较长。针对上述问题,本文研究了一种基于Flink的工业大数据平台,主要贡献如下:
(1)采用Kafka和Flink进行集成,对数据进行传输和处理,并将处理过的数据按照类型存储至数据池中;
(2)利用Flink对工业大数据进行预处理,提高平台运行的准确性;
(3)采用多种大数据技术,实现工业大数据平台的数据查询以及预警功能,且相对于典型大数据平台而言,速度更快、效率更高。
1 关键技术介绍
1.1 Apache Flink
Apache Flink是一个分布式处理框架,可在无边界和有边界数据流上进行计算[8]。Flink不仅能运行在YARN、Mesos等资源管理框架上,而且能在单独集群中运行,适用于具有不可靠数据源、海量数据处理等场景。此平台采用Flink的最主要原因是:工业大数据类型杂,既包括流数据,又包括批数据,而Flink两者都可以处理。它适用的主要场景是流数据方面的,而批数据是“特殊的流数据”,所有任务都可以当成流来处理[8],并且数据处理延迟性较低。其架构[8]如图1所示。
对于流数据应用来说,Flink提供DataStream API。对于批数据处理应用来说,提供DataSet API。它支持Java和Scala语言,同时支持Kafka的输入数据和ElasticSearch、MySQL、InfluxDB多种数据库。Flink同时具有高度灵活的窗口操作,包括time、count等窗口操作,如:每隔多久发送数据至客户端、每次发送数据的个数等,十分适用于工业场景。

图1 Flink架构
1.2 Kafka
Kafka是一个基于Zookeeper的分布式消息系统,它具有高吞吐、低延迟、可靠性好、容错能力强的良好特性[9]。低延迟体现在Kafka每秒能够处理巨量信息且延迟很低,只有几毫秒,适用于工业生产过程中海量数据的处理;高吞吐率体现在即使应用在廉价的商用机器上,Kafka也能进行每秒100 K消息的传输。Kafka也较为可靠,传输的数据可以在本地磁盘持久保存,同时数据会自动进行备份,数据丢失后仍可找到数据。Kafka容错性较好,集群中节点是允许失败的(如副本数量为n,则n-1个节点是允许失败的)[9]。此平台选用Kafka消息队列能够更好地解耦,也增强了平台的扩展性,即使企业数据发生改变,不需要改变代码和调节参数就可以轻松实现用户要求。同时也保证了数据传送的顺序性和安全性。
1.3 Grafana
Grafana是一个可靠性较好的可视化和度量分析工具。它具有灵活和快捷的客户端图表,有多种可视化指标和面板插件,官方库里有图表、折线图、文本文档等丰富的仪表盘插件;它支持多种数据库如:MySQL、InfluxDB、Prometheus、OpenTSDB、Elasticsearch和KairosDB等等;Grafana可通过直观的可视化方式进行预警并发送通知,当获得的数据大于用户设定的阈值时通知Slack、DingDing、Email等;并且数据源不同,但仍可以使用在同一图表中,数据源的来源可以根据每个查询决定,也可以自定义数据源;Grafana同时具有丰富的注释图,注释图表能显示不同数据源的丰富事件,当鼠标停留在图表时,会以全面的标记来显示出元数据。
1.4 InfluxDB
InfluxDB是一个用于处理海量数据写入与数据查询的时间序列数据库,应用于有大量时间戳数据的场景下,例如DevOps(过程、方法、系统)监控,物联网工业数据实时分析等。它是分布式扩展的,不依赖外部任何条件。它还可以对ETL进行后台处理并实时监控预警。它有类似SQL的查询语言,可轻松方便查询到需要的数据。不仅如此,InfluxDB连续查询自动计算聚合数据,大大提高了频繁查询的效率。本平台中的数据量较大,时间戳数据较多,因此InfluxDB是工业大数据存储的绝佳选择。
2 工业大数据平台框架设计
本平台旨在实现一个能满足对工业大数据进行存储、集成、分析的平台,能够为企业多种业务提高指导和决策支持。其架构如图2所示,其主要分为5个部分,包括:数据源模块、消息队列模块、数据存储模块、数据处理模块、可视化模块。
2.1 数据源模块
此平台的数据源主要分为两种,一种是静态系统数据,第二种是实时流数据。数据源获取的方式主要如下:
(1)静态系统数据一般是由公司专门人员去收集,如设备生产日期、企业名称、设备编号等,这些数据以特定的形式整理形成一个Excel表格,能够直接使用;
(2)大多数的企业获取数据的方式都是通过各种传感器,传感器获取到的设备的状态、运行时间等实时数据,然后将这些数据发送给此平台的处理系统;
(3)企业的很多数据会分布在不同地区的不同公司,所以这时候它们通常会以日志的形式存在,而Flume是一个很好的日志收集工具[10]。这个工具能够将这些日志文件识别出来,并整理收集在一起,并发往此工业大数据平台;
(4)工业生产中会产生很多业务静态数据,但它们的格式可能不是我们所需要的,此时可以使用Sqoop数据源转换工具,将它们转换为我们所需要的格式,然后再将这些数据发送给工业大数据平台。
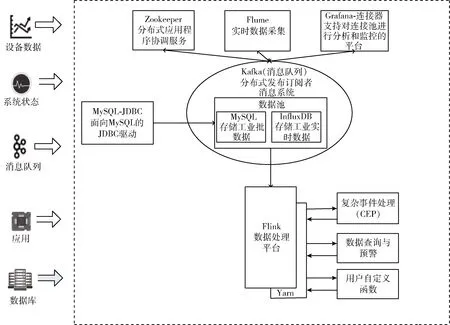
图2 体系架构
2.2 消息队列模块
消息队列主要指数据在传输过程中保存数据的一个容器。工业大数据类型多,数据量大,面对此场景使用消息队列是一个极佳的选择,因为消息队列能够极大地降低系统响应时间、提高系统稳定性,同时保证数据传输的顺序性和安全性,最重要的是实现数据的异步化,并起到解耦的作用。
此模块选用Kafka作为消息队列系统,利用Flink将数据源模块中的实时数据和批数据都暂存至消息队列中。Flink作为生产者,会源源不断地生产出消息,然后发送给消息队列Kafka中,而Kafka就成为了消费者,它会不断地从Flink中获取到消息,从而对这些数据进行进一步处理。
2.3 数据处理模块
本模块主要采用Flink来处理实时大数据和离线批数据。根据数据类型,将此模块又分为实时数据处理模块和批数据处理模块。Flink能够同时支持批处理与流处理任务,它包含两种预先定义的函数:DataStream API和DataSet API。DataStream API 包括reduce、aggregations、filter等方法。DataSet API包括distinct、Hash-Partition、window等方法。
批数据处理模块中,此平台会利用aggregations中的sum()、min()、max()方法对批数据进行统计,求出工业数据的最大值、最小值、总和等,并在前端显示出来。
流数据处理模块主要是对数据进行预处理。在工业大数据的实际生产过程中,由于人工失误或者数据采集设备因生产环境恶劣会导致收集到的数据不准确,这些数据如果直接存入到数据库中不仅会降低大数据平台查询数据的准确性,而且会大大降低平台的运行效率。此模块主要利用Flink来去除实际业务处理中的无效数据、重复数据以及缺失率较高的数据,其预处理的流程如图3所示。
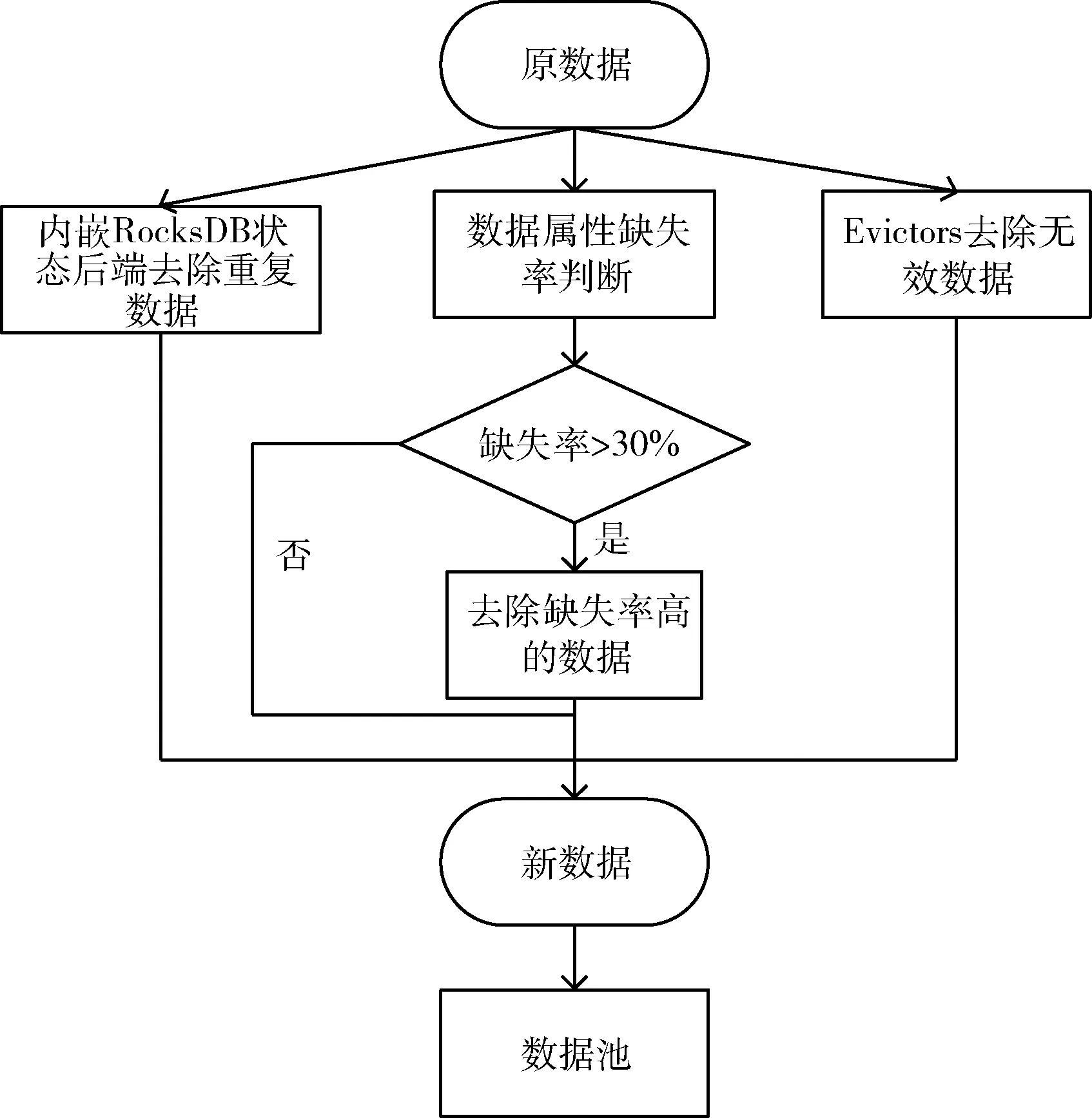
图3 预处理流程
数据预处理方法具体步骤如下:
(1)首先利用Flink从Kafka中获取到数据,然后通过Flink自带的RocksDB状态后端去重方式对工业大数据进行去重。我们需要开启RocksDB状态后端并对其参数进行配置,如数据过期的时间、是否过期的数据能再次被访问等,接着注册Flink定时器。我们也可以利用Flink的TTL机制,打开RocksDB状态后端的TTL compaction filter,这样能在后台实现重复数据的自动删除。在处理重复数据时,如果数据的key(如事件ID)对应的状态不存在,说明此数据没有出现过,可以更新状态并且输出数据。反之,说明此数据已经出现过,RocksDB就会将其自动删除。同时我们可利用Flink SQL提供的distinct去重方法来统计重复数据的明细结果;
(2)然后对实际生产过程中的无效数据进行删除。这里利用FlinkDataStream API的Evictor()方法对WindowFunction前后的数据进行处理。Evictor()方法包括Count-Evictor、DeltaEvictor和TimeEvictor以及自定义的Evictor。CountEvictor是在窗口中设置保持的数据数量,如:evictor(CountEvictor.of(10000)),意思是窗口中最大的数据量为10 000,若大于10 000条,则剔除。在实际生产过程中也会产生很多已过时的无效数据,其不仅会影响平台数据查询的正确性,而且会增加平台的资源消耗,进而影响执行效率,而Flink 自带的TimeEvictor方法能将最新时间的数据筛选出来,去除过时的数据。其主要将当前窗口中最新元素的时间减去时间间隔,然后将小于该结果的数据全部剔除。DeltaEvictor方法通过定义DeltaFunction和指定threshold(阈值),计算出窗口间数据的Delt大小,如果超过了阈值则将当前数据元素删除,这样可以去除那些因为机器故障或者外部原因产生的差别较大的无效数据。同时也可以根据用户的需求自定义Evictor方法来去除那些无效数据;
(3)利用步骤(1)中distinct去重方式的Distinct-Accumulator 与CountAccumulator方法统计单条数据value值的数量,DistinctAccumulator()内部包含一个map结构,key包含的是一条数据的属性值,而value则是属性值出现的次数。若缺少的value值过多(大于50%),直接删除缺失数据的记录。反之认定数据为有效数据;
(4)原数据经过预处理后得到新数据,将这些数据存储至数据池中。
通过一系列的数据预处理,可以有效防止脏数据影响平台的正常运行。
2.4 数据存储模块
工业大数据异构性较强,数据类型较为复杂,这些数据通常以不同形式存储在不同的数据库或者数据管理系统中,所以管理起来较为麻烦,因此企业急需一个平台对数据进行统一管理。而此平台的数据源主要分为两类,一类是实时数据,另一类是工业批数据,为了方便管理使用,此平台建立一个数据池来存储数据。实时数据存放至InfluxDB数据库中,设备状态、设备离线事件、设备事件等信息,静态系统数据存放至MySQL数据库中,如:企业设备、企业名称、地址等信息。
数据存储的过程如下:首先平台先判断获取到的数据的类型,若是工业批数据会利用SQL-query去取出数据连接的URL、用户名和密码,然后加载SQL-JDBC去连接实例,并执行查询;若是工业实时数据会先加载NoSQL-query,然后读取NoSQL连接类,读取InfluxDB数据库自带配置文件,从而连接实例,并执行查询。
2.5 可视化分析模块
无论是联机事务处理(OLTP),还是联机分析处理(OLAP),都是为了用户更好地更直观地获取到处理到的数据结果,因此考虑一个与用户交互性好的前端工具是十分必要的。
本平台采用开源的Grafana作为可视化分析工具,它不仅支持多种数据库,如IoTDB、MySQL、InfluxDB等,还支持多种数据的展示方式,如折线图、图表等,以更直观的形式显示出数据,用户按照各自需求可快速获取到数据且不需要关心后台的具体运行过程。同时可以对工业设备进行预警,它通过Slack、DingDing、Email等方式通知企业数据已达到阙值,从而实现设备数据的准确预警。
2.6 集成过程
首先,数据源模块可采用Flume收集工业生产过程中产生的日志,或直接从传感器中获取到数据,并由专门人员将这些数据整理为Excel格式。其次,利用Flink将整理好的数据发送至Kafka消息队列中,保证数据传输的安全性和顺序性。然后利用Flink获取到暂存至Kafka中的数据并对其进行预处理,去除重复数据、缺失率较高的数据、无效数据等,处理好后将其存储至不同的数据库中,批数据存储至MySQL中,流数据存储至InfluxDB中。而Flink贯穿整个运行过程,对于MySQL中的数据可采用DataSet API,InfluxDB中的数据采用DataStream API。可视化分析模块使用Grafana组件,实现不同类型数据的增删改查,同时也可以对企业数据进行监测,若大于预定的值可通过邮件的形式进行预警。
3 实验与分析
3.1 实验环境和数据集
此平台集群的硬件环境包含3台物理机,一个为主节点,其余两个为子节点,其域名分别为Master、Slave1、Slave2,3台机器均使用8 G内存以及1 T的硬盘,使用的操作系统为Centos6.4 64位。Flink集群选择1.9.3版本。Flink的master进程 jobManager放在Slave1中。修改好的配置文件放置在其它节点,并在Slave2的Flink_HOME/conf/slaves目录下添加 Master、Slave1、Slvae2,这样可以通过主节点免密登录启动其它的副节点启动。Kafka应注意与Zookeeper 版本之间的兼容性,所以此平台选择了Kafka 2.2.0和Zookeeper3.4.10。前端工具Grafana选择版本Grafana-6.7.2,此平台选用的数据库为MySQL-5.5和InfluxDB-1.7.3。
本文的实验数据来自经过数据脱敏后的3000家企业基本信息,10 000余台设备连续3个月的运行数据,脱敏简要过程如下:利用Java代码定义数据脱敏的工具类,涉及到具体公司名时,用*替代。同时企业id、设备id、事件id值重新编号,从而保护数据的安全性。本实验的采用的数据主要分为两种类型,一种是“企业名单”、“企业设备信息”、“测点名称”等批数据,此类数据量为87 000条,描述的是3000家企业的一些基本信息,如公司名、所处地区等;另一种是“设备实时事件统计”、“设备状态时长统计”等实时数据,此类数据量较大为1 250 000条,描述的是设备的实时状态信息,如在某个时间段企业的状态等。批数据以“企业名单”为例,包括5个字段值:企业id、客户名称、地址名称、省市区、公司名,部分数据见表1。(注:表中只展示了部分数据集中的某个表,并不是全部数据)。
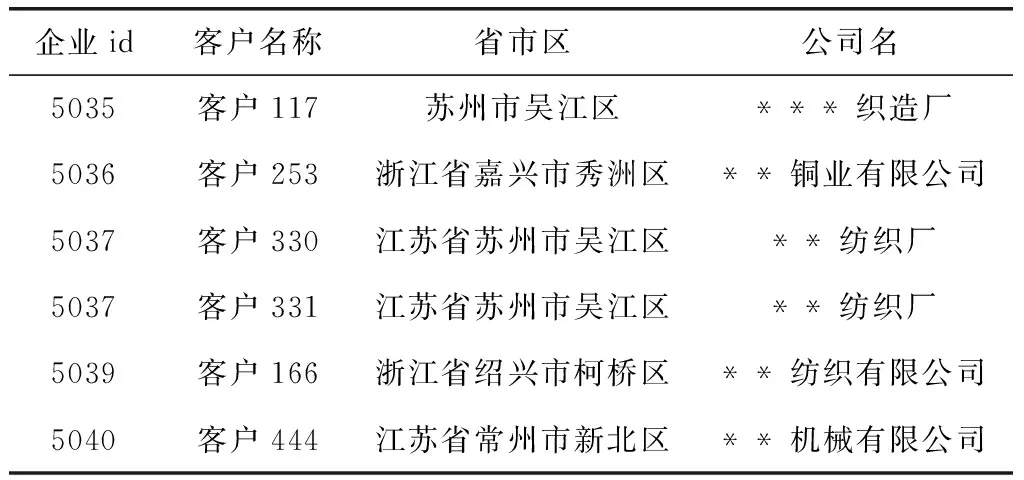
表1 企业名单
实时数据以“设备实时事件”数据为例,包括4个字段值:事件id、发生时间、设备id、事件,部分数据见表2。
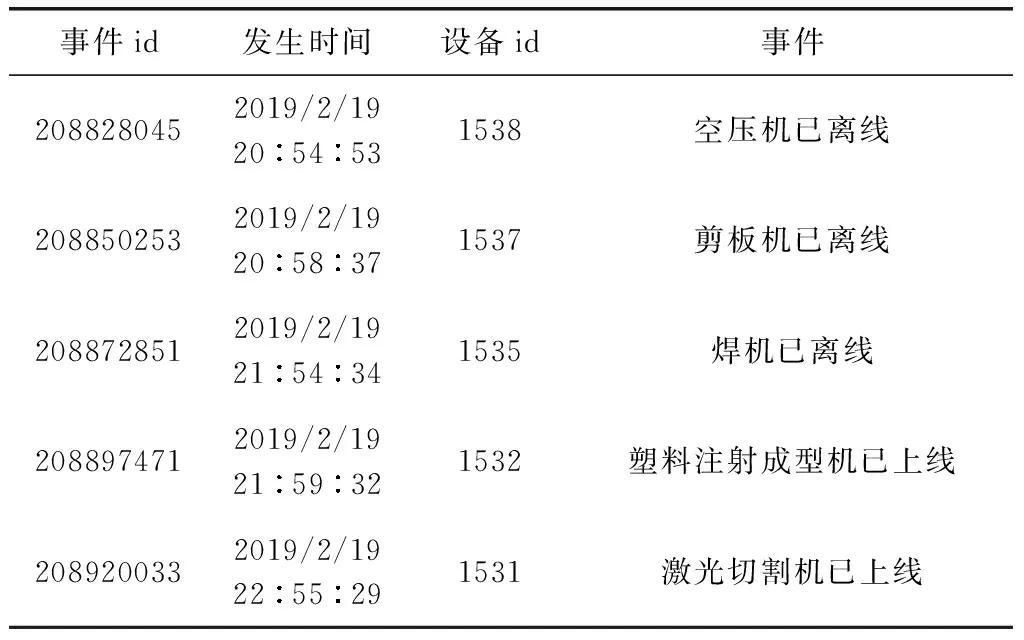
表2 设备实时事件
3.2 平台实现
为了验证基于Flink的大数据平台的有效性,对此平台的各个模块进行了测试。
系统实现具体过程如下:首先将数据源中的批数据和实时数据导入到Kafka消息队列中。批数据的数据量较小,导入时间较短,耗时3 min 10 s成功将“企业名单”的信息发送至Kafka中。而“设备实时事件统计”实时数据量较大,耗时较长,耗时17 min成功将实时数据导入到Kafka中。然后利用Flink读取Kafka数据并进行预处理后写入到MySQL与InfluxDB中,预处理后的重复数据筛选结果见表3(以实时数据“设备实时事件”为例)。

表3 重复数据筛选结果
无效数据筛选结果见表4。
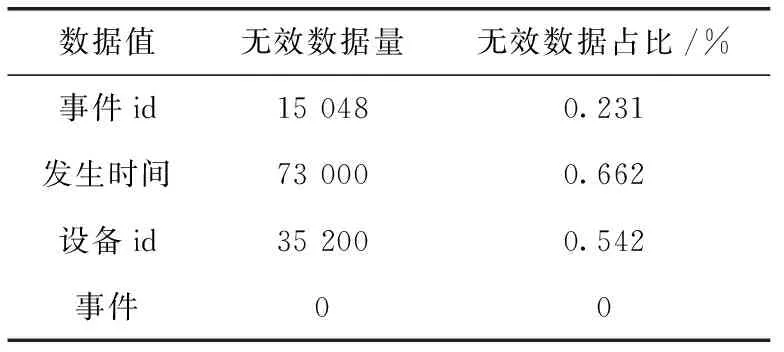
表4 无效数据筛选结果
空数据筛选结果见表5。
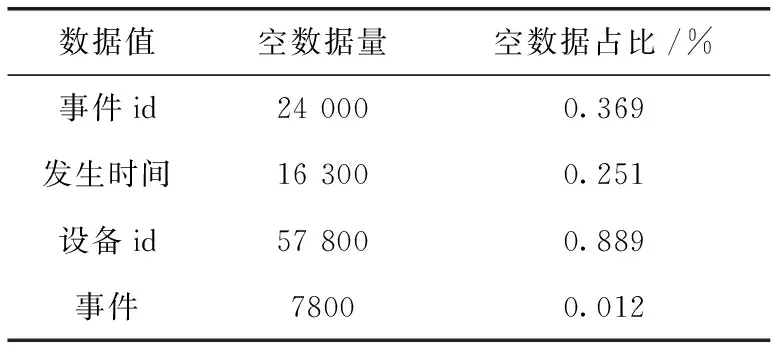
表5 空数据筛选结果
数据筛选后,开发人员可利用Navicat和InfluxDBStudio可视化工具查看数据,用户显示界面如图4所示。
图4 用户界面
用户在浏览器中输入localhost:3000进入此平台,首先填写数据库的用户名以及密码,创建用户需要的数据库,其次选择数据库显示的仪表形式,有折线图、表格、文本等形式。例如:用户想查询MySQL数据库中的某个特定条件的批数据并以表格的形式输出,用户可在系统界面选择Table并输入:SELECT * FROM ′company_list′ WHERE 区=′天宁区′,便只查询天宁区的公司名单,其实现效果如图5所示。
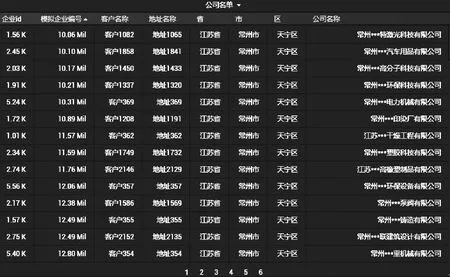
图5 公司名称
同理,也可以实现实时数据的查询,能快速地查询到各个设备的实时状态和对应的发生时间,如图6所示。

图6 设备实时状态表
同时系统界面也提供edit的方式,用户只需要选择操作的数据库和限定条件,也可轻松查询到数据。不仅如此,用户也可以利用此平台筛选出自己所需要的数据,如查询到相同设备号id的机器、同一时间内机器的上线数量、统计一段时间内出故障机器的数量、显示预警的极值和结束时间等。
Grafana可以无缝定义告警在数据中的位置,可视化的定义阈值,并可以通过钉钉、E-mail等平台获取告警通知。这里我们选用E-mail的形式来关注实时设备状态并获得告警通知。首先在启动Grafana前配置/etc/grafana/grafana.ini开启smtp服务,配置发送邮件的邮箱以及密码。配置好后,通过Grafana 的Alerting功能设置发送邮件的间隔时间,实现对设备数据的预警(此平台判断机器是否出现故障的方式有两种:①由于机器是24小时运作的,所以机器会一直呈现在线状态,若机器离线时间过长则会判定为出故障;②平台会每隔一定时间发送机器上下线的数量给用户,若下线的机器数量过多,则判定有机器出现故障),其告警如图7所示。
图7 告警

3.3 分析比较
在文献[11]中,作者介绍了当前较为典型的Clou-dera大数据平台,其以Hadoop技术架构为基础,具有稳定的、可扩展的企业级大数据管理平台,它提供了很多部署案例,能够方便管理企业生产过程中的多种数据,且具有强大的管理和监控工具。其中Cloudera Manager是开源的方便使用的一款产品,它提供Web用户界面使得企业进行数据管理时更加容易。而Shark[12]也是一个相对较新的开源工业大数据分析平台,它是Spark的一个组件,可安装在与Hadoop相同的集群上,是一个性能较好的分布式和容错内存分析系统,它具有数据联合分区,容错以及机器学习的能力,且完全兼容Hive和HiveQL,也能支持多种数据库数据的查询。
本平台采用了Flink框架来构建工业大数据平台。首先比较Flink平台和文献[11,12]二者平台基础框架的技术特点:Spark和Flink都是运行在YARN上的,但Flink的性能是优于Spark的,而Spark性能是大于Hadoop的,而且迭代的次数越多,Flink 的优势越明显。不仅如此Flink具有灵活的窗口,对于流数据处理起来更加方便,而工业生产下流数据偏多且较为复杂,因此Flink十分适用于工业场景。
其次,文献[11,12]对于工业领域中的不同类型的数据无明确的区分,只采用单一的数据库存储数据。而本平台中采用一个数据池来存储不同数据,批数据放入MySQL据库中,流数据放入InfluxDB数据库中,能够更好地区分开不同类型的工业大数据。再者,本平台利用Kafka进行数据暂时存储,更好地保证了数据传输的安全性以及平台的可扩展性。
Flink平台和Cloudera Manager大数据平台、Shark大数据平台的查询数据效率如图8所示,行表示数据集的数量(单位个数),列表示用户查询数据的响应时间(单位ms)。

图8 数据查询效率
从图8中我们可以看出:当数据集为5000条时,各个平台的执行效率是差不多的,基本能在几毫秒内响应出来。但当数据集数据变多时,Shark平台和Cloudera Manager平台数据查询时间明显上升,执行效率变低,而Flink平台在处理将近60 000条数据集时也能快速响应。
3个平台的吞吐量方面也进行了比较(吞吐量即单位时间内平台成功传送数据的数量),比较结果如图9所示,本次测试吞吐量的单位为:条/s。
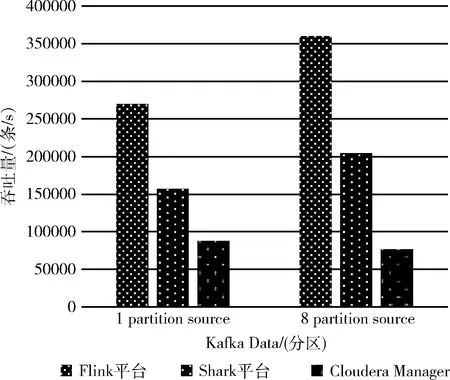
图9 吞吐量比较
从图9中可以看到,当Kafka Data的Partition为1 时,此平台的吞吐量是Cloudera Manager大数据平台的3.2倍,是Shark平台的将近1倍,而当Partition数为8时,此平台吞吐量为Shark平台的将近1倍,是Cloudera Manager大数据平台的4.6倍。总之Flink平台的吞吐量是远远高于其它两个平台的,而吞吐量又极大地反应了系统的负载能力。在工业大数据量大的情况下,Flink平台能够更好地运作。
当数据量变大时,延迟低也是一个企业需要考虑的地方,因此比较了3个平台的延迟性。延迟性即数据从进入系统到流出系统所用的时间,本次测试延迟的单位为:ms。其实验结果如图10所示。
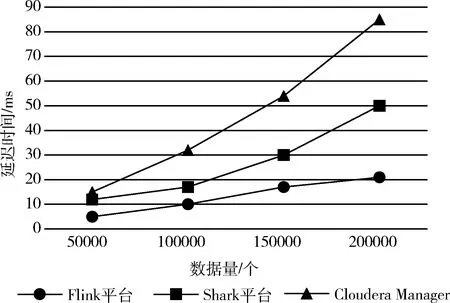
图10 延迟比较
从图10可以看到,Flink平台的延迟较低,即使面对200 000条的数据量,平台也只具有21 ms的延迟,而Shark平台的延迟几乎是Flink平台的2倍,而Cloudera Manager平台是Shark平台的两倍,因此Flink平台在延迟上也有较大的优势。
同时,在平台预警速度方面做了个对比:选用5000条实时数据在不同的平台上运行,比较不同平台进行预警并发送邮件至用户的时间。其实验结果如图11所示。
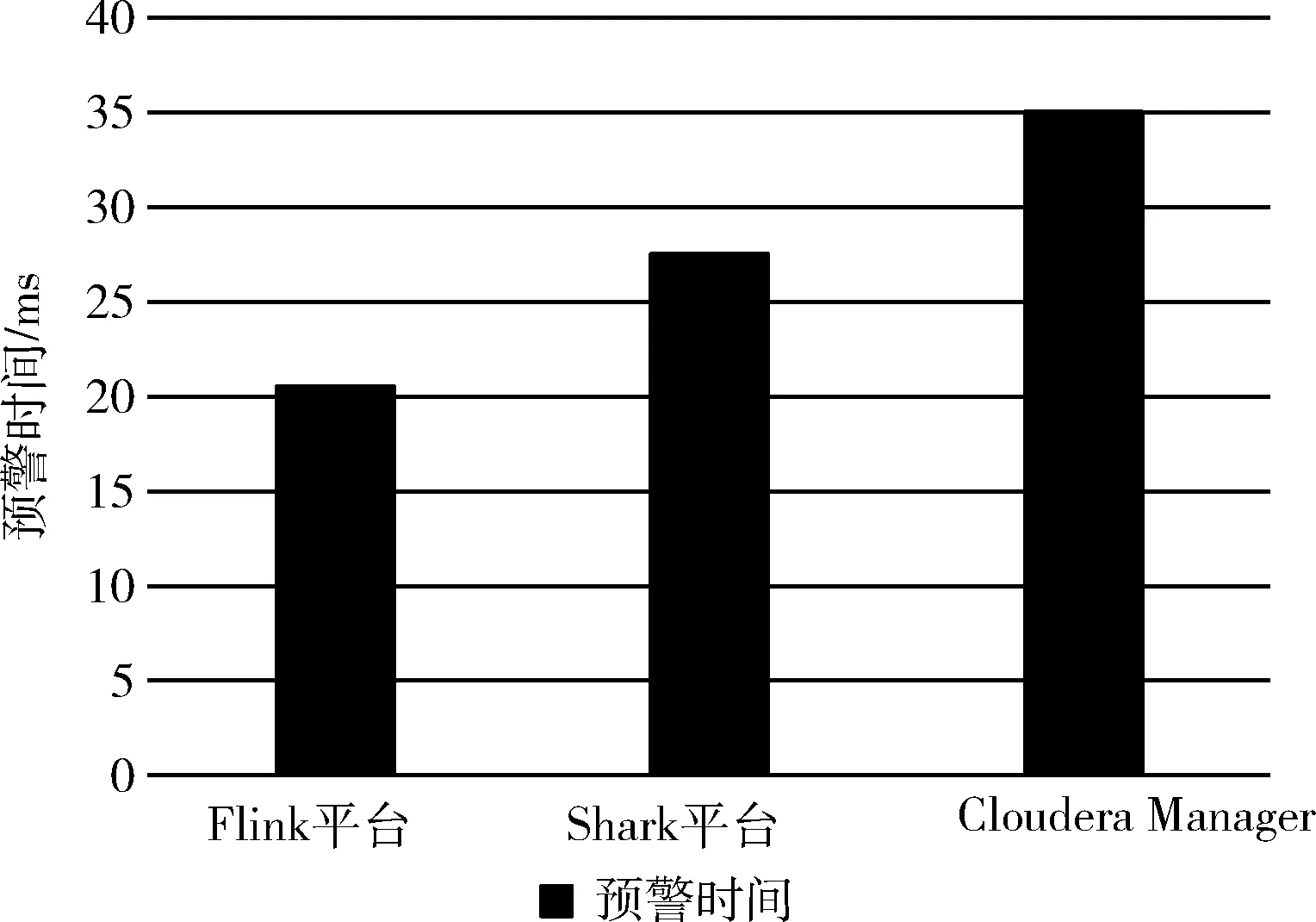
图11 预警时间比较
从图11中我们可以看出:5000条实时数据在此平台进行预警并发送邮件的速度是最快的,需要20 ms,而在Shark平台和Cloudera Manager大数据平台分别需要27 ms和35 ms,此工业大数据平台预警时间更短,能够最大地减少企业的损失。
4 结束语
针对工业大数据数据量大、异构性强、及时性强的特点,引入大数据技术,提出了Flink和Kafka集成的工业大数据平台,此平台通过集群环境能够高效地查询数据,并能进行设备数据的快速预警。与目前较为典型的两款开源大数据平台进行比较,实验结果表明,此平台在数据查询效率、吞吐量、延迟性以及预警速度方面都是优于其它两个典型的大数据平台的,能够满足预计的设计目标。不仅如此,此平台不仅适用于工业领域,而且适用于所有时间序列数据多的场景,因此基于Flink的工业大数据平台的研究是具有实际意义的。
在今后的工作中,还需完善此平台的其它功能,如云平台数据分析故障预测等。其次数据源部分的数据都是整理好的,而此平台中并未过多介绍如何获取数据源,因此今后还需多学习物联网的知识。在企业生产过程中,安全性是重中之重的,虽然在传输过程中使用消息队列保证数据传输的安全性,但其它模块产生的数据实际是不够安全的,所以如何保障保证数据处理的安全性[13],这也是本平台未来需要考虑的地方。
