基于YOLOv3改进的轻量化人脸检测方法
2022-03-22史梦安蔡慧敏陆振宇
史梦安,蔡慧敏,陆振宇
(1.苏州大学应用技术学院 工学院,江苏 苏州 215325;2.南京信息工程大学 人工智能学院, 江苏 南京 210044;3.南京信息工程大学 江苏省大气环境与装备技术协同创新中心,江苏 南京 210044)
0 引 言
如今的人脸检测技术大致可分为两类:人工设计特征的传统方法和特征自动提取的深度学习方法。人工设计一般从人脸的肤色、结构、纹理、轮廓等特征入手。Mollah等[1]将Harr-like特征与肤色特征相结合,降低了人脸样本假阳性的概率。Zheng等[2]先后选取肤色特征与纹理特征,使用局部二进制模型进一步减少误检率。Sudhaker团队[3]使用Gabor滤波器进行人脸的检测,通过滤波生成不同角度和方向的人脸图像通过匹配算法与数据库中的人脸轮廓进行比对。人工设计特征的检测算法,由于特征表达能力有限,容易受外界环境变化的影响,所以在复杂场景下检测性能难有提升。
基于深度学习的人脸检测算法大致分为两类:以Faster R-CNN[4]为代表的两步法(Two-Stage):这类方法首先提取候选区域,再基于候选区域做二次修正,特点是速度较慢,但精度很高;以SSD[5]为代表的一步法(One-Stage):这类方法通过直接对预设在图像上的边界框做修正来获得检测结果,特点是速度与精度相均衡。
目前人脸检测技术的难点是如何在有限的资源上完成实时检测并兼顾准确性,究其原因是现在通用的目标检测模型往往本身复杂度高,神经网络模型参数多,计算量大,而它们的简化版本(tiny)虽然速度有所提高,但是检测精度却大打折扣,不能满足现实生活中的需要。
为解决上述不足,本文认为关键点是轻量化模型设计,并增加一系列的trick提高网络的检测精度,提出了以YOLOv3[6]为基础的一种基于MobileNet[7-9]中深度可分卷积替换传统卷积的轻量化模型,主要贡献可总结为:
(1)针对人脸检测不能满足实时性的问题,采用MobileNet中的深度可分卷积轻量化YOLOv3模型,降低计算量,加快检测速度。
(2)针对人脸检测因人脸尺寸不一容易出现漏检的情况,增加了SPP结构,尺度不变的同时可提取不同尺寸的空间特征信息,提升模型的鲁棒性。
(3)针对人脸检测易受环境影响召回率不高的问题,基于YOLOv3中的FPN[10]结构,增加Self-attention[11]机制,加强不同尺度预测特征层上语义信息与位置信息的融合,提高检测精度,降低环境对人脸检测的影响。
1 相关理论基础
1.1 MobileNet网络
MobileNet是google团队于2017年发表的专门针对移动端或者小型设备开发的轻量级CNN网络,提出了深度可分卷积这一结构。相比传统的卷积神经网络,在略微降低准确率的前提下大幅减少了模型参数与运算量,与同样是通过堆叠卷积层构建的VGG16网络相比准确率仅降低了0.9个百分点但是模型参数只有VGG大小的1/32。
深度可分卷积(depthwise separable convolution)的定义请参见文献[7]。图1中的depthwise convolution就是深度卷积,在深度卷积中,每一个卷积核的深度都为1,也就是说每一个卷积都只对应输入特征矩阵中的一个通道,也只提取一个通道的特征,所以得到的输出特征矩阵的深度等于输入特征矩阵的深度。逐点卷积则对应图1中的pointwise convolution,其实逐点卷积就是卷积核大小为1的普通卷积,它对深度卷积计算出来的结果进行1×1的卷积运算,并将得到的特征图再串联起来,维持特征的完整性。标准的卷积运算是一步中就包含了深度计算和合并计算,然后直接将输入变成一个新的尺寸的输出。深度可分卷积是将这个一步的操作分成了两层,一层做深度计算,一层做合并计算。这种分解的方式极大地减少了计算量和模型的大小。深度卷积和逐点卷积如图1所示。

图1 深度可分卷积
1.2 YOLOv3网络
2018年Redmon发布的YOLOv3(you olny look once)可谓是前两代YOLO[12,13]的集大成者,在原有YOLO算法的基础上修改主干特征提取网络,改变对边界框的预测方式并引入一些新的结构来增加mAP,使其成为当时最受欢迎的one-stage目标检测网络之一。
YOLOv3的主干特征提取网络较之于YOLOv2[13]的Darknet-19,采用重新训练的Darknet-53,Top-1达到了77.2个百分点,对比原来的Darknet-19有非常明显的提升。和Darknet-19一样,Darknet-53中有53个卷积层,所以称为Darknet-53。具体网络结构如图2所示。

图2 YOLOv3网络结构
YOLOv3引入了FPN结构,会在3个预测特征层上进行预测,每个预测特征层上使用3种尺度的预测边界框。这3种尺度也是通过k-means聚类算法得到的,一共9组尺度。在YOLOv3中称这些预设的目标边界框作bounding box priors,与SSD中的anchor类似。每一个预测特征层上的一个网格会预测3种尺度,所以在每个预测特征层上会预测N×N×[3×(4+1+80)] (N是指特征矩阵的高和宽),也就是说一个bounding box priors需要预测85个参数(4个偏移参数,1个confidence,80个classes score(因为是在coco数据集上))。
2 网络模型
2.1 主干特征提取网络的替换
对于YOLOv3而言,其网络结构可以大致分为以下两个部分:①主干特征提取网络Darknet-53;②预测网络YOLO-head。第一部分的主干特征提取网络进行图像特征的初步提取,提取后可以获得3个初步的有效特征层,预测网络则根据第一步获取的有效特征层进行目标的预测。
MobileNet网络虽然用于图像分类任务,但它的主干网络(backbone)的作用也是初步的特征提取,可以使用MobileNet替换YOLOv3中的Darknet-53进行特征的提取。
基于上述想法,要想用MobileNetV1模型替换Darknet-53模型,只需将经过Darknet-53后得到的3个初步有效特征层替换成MobileNetV1中shape相同的特征层即可。如表1所示,输入图片的大小控制为320×320,第一次卷积为普通的卷积,其它卷积为DW卷积,DW的普遍使用提高了模型的计算速度,表中有3处加粗的Output分别为:40×40×256,20×20×512和10×10×1024,这3个 Output是为后面的特征金字塔(FPN)提供的input即替代3个有效特征层的特征层的shape值。

表1 MobilenetV1架构
2.2 增加空间金字塔池化
He等提出卷积神经网络是由卷积层和全连接层组成,卷积层对输入图像的大小并没有要求,但是第一个全连接层的输入必须是大小固定的特征向量。人脸图像由于图像者本身,具体拍摄情况等一系列原因不可能达到固定的大小,如果直接对图像进行拉伸、缩放、裁剪等操作必然要损失信息从而影响到检测的精度和算法的鲁棒性。SPP(空间金字塔池化)也正是He等提出来的解决办法。
考虑到与本文改进模型的适配性,参考SPP结构对其做出了改良,添加到第一个YOLO-head前的第5和第6层卷积之间。改良的SPP结构如图3所示。
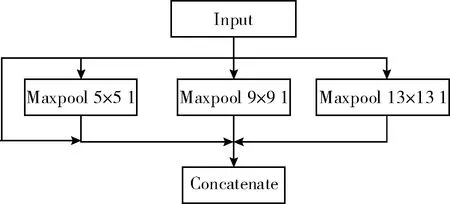
图3 改良的SPP结构
选取池化核大小分别为13×13、9×9、5×5的池化核。首先从输入直接接到输出,这是第一个分支;第二个分支是池化核为5的最大池化下采样;第三个是池化核大小为9的最大池化下采样;第四个分支是池化核大小为13的最大池化下采样。注意这里的步距都是1,意味着在池化之前会对特征矩阵进行padding填充,填充之后进行最大池化下采样之后所得到的特征层的高度和宽度是没有发生变化的。最后在深度上进行一个Concatenate拼接就完成了。通过改良的SPP结构实现了不同尺度的特征融合,并且使特征层的表达能力增强,有利于对不同尺寸的人脸图像进行检测。
2.3 Self-attention与FPN融合
由2.1节可知,改进的模型(以下简称改进的模型为SMYOLO)中FPN(特征金字塔)是基于MobileNetV1的第6层、第12层、第14层输出来实现的,图4为融合后的整体架构,第一行Conv1、DWConv12、DWConv14为MobileNetV1的架构。第二行以下模块属于FPN,图4中红色模块与黄色模块为Self-attention。黄色的Self-attention接收的是DWConv14输出的特征图(10×10×1024),红色右接收DWConv12与DWConv14上采样的特征图,红色左接收DWConv6与DWConv12上采样的特征图。

图4 SMYOLO框架
在介绍Self-attention与FPN融合前,首先介绍下Self-attention机制。Self-attention的流程如图5所示。

图5 Self-attention[11]
f(x),g(x) 和h(x) 都是普通的1×1卷积,差别只在于输出通道大小不同也就是每个权重的规格是不一样的,规格见式(1)。将f(x) 的输出转置,并和g(x) 的输出相乘,再经过Softmax归一化得到一个Attention map。将得到的Attention map和h(x) 逐像素点相乘,就能得到自适应注意力的feature maps
(1)
图5中输入的feature map(x)就是经过隐藏层后得到的特征图,对应图4中3个Self-attention接收的特征图,对于x来说它的维度是C×N,C表示通道数,N表示图片的宽度×高度,换句话来说就是这个feature map中一共有多少个像素点。f(x)、g(x)、h(x) 的计算公式见式(2)
f(x)=Wf·xg(x)=Wg·xh(x)=Wh·x
(2)

(3)
式中:βj,i代表生成第j个Attention map矩阵区域时,模型对第i个位置的关注程度。
如何将Self-attention与FPN融合来降低环境对人脸检测的干扰。第一部分是Self-attention机制一,如图6所示,对应图4中SMYOLO框架黄色的Self-attention机制。将MobilenetV1的DWConv14输出特征图(10×10×1024)作为Self-attention机制一的输入,然后通过Self-attention输出特征图(10×10×256)。

图6 Self-attention机制一
第二部分是Self-attention机制二,如图7所示,Self-attention机制二的输入是两部分,第一部分是MobileNetV1中DWConv12的输出特征图(20×20×512),第二部分是Self-attention机制一模块的输出特征图(10×10×256)。将特征图(10×10×512)进行f(x) 和g(x) 的计算,并计算出Attention map,如图7绿色部分。
Attention map是采用DWConv12输出的特征图计算出来的,相对于DWConv11输出的特征图语义信息强,本文用Attention map来聚焦人脸的特征,Attention集中在人脸,减小环境对人脸的影响。为了使Attention map发挥作用,将DWConv11的特征图与经过h(x) 处理后的特征图进行融合(*)(对应像素相加)。如图7的黄色部分
(4)
式(4)是计算Attention map层的输出,得到Self-attention feature maps的计算公式。其中,o代表最终的输出,维度是C×N即C×N大小的一个自适应注意力的矩阵。h(xi)+X是上文中的步骤*。v(xi) 表示一个1×1大小的矩阵,维度是C×C。

图7 Self-attention机制二(模块一)
图8是Self-attention机制二的第二模块,原理与第一模块一样,不同的是输入不同,模块二的输入分为两个部分,第一部分是Self-attention第一模块的输出特性图(20×20×128),第二部分是MobileNetv1的DWConv5的输出特征图(40×40×256)。

图8 Self-attention机制二(模块二)
2.4 DIoU损失函数
YOLOv3在计算置信度损失时使用的是IoU[14]损失函数,IoU表示预测目标边界框和真实目标边界框之间的重合程度,计算公式见式(5)
(5)
式中:A为预测边界框的面积,B为真实边界框的面积,IoU(A,B)表示A与B的交并比,即A与B面积的交集和A与B面积的并集的比值。可以发现IoU能够很好反应预测边界框和目标边界框的重合程度,但是当二者相交时损失直接就变成0,这是我们不想看到的结果。为了避免在改进的模型中计算置信度损失时出现这种无法优化的情况,本文采用DIoU[15]作为边界框回归损失函数,公式见式(6)
(6)
式中:b是指预测目标边界框的中心坐标,bgt是指真实目标边界框的中心坐标,ρ代表两个中心之间的欧氏距离的平方,即图9中d的平方,c是指预测边界框和真实边界框的最小外接矩形的对角线的长度。由此可见DIoU损失对预测边界框和真实边界框之间的归一化距离进行了建模,如图9所示,在考率重合度的同时还考虑到两者之间的中心距离和尺度,可以更快更稳定地进行回归。因为考虑到了中心距离,即使在预测边界框和真实边界框不重合的情况下也能为回归移动提供方向,这样就避免了IoU为0时训练发散,回归收敛慢的问题。

图9 DIoU计算参数
同时DIoU损失能够直接最小化两个边界框之间的距离,因此收敛速度也更快,且对边界框的尺度具有不变性,使预测边界框回归真实边界框时定位更加准确。
从表2可知,DIoU在mAP上优于IoU,因此选择DIoU作为边界框回归损失函数对模型的检测性能是有很大提升的。

表2 IoU与DIoU损失函数对比
3 实验与结果分析
3.1 实验数据
本文用于模型训练的人脸图片来自大型人脸公开数据集WIDER FACE,由香港中文大学资讯工程学系多媒体实验室制作,包含32 203张图像共40多万张人脸,涵盖不同尺度、光照、表情、遮挡等不同类型的人脸数据,大部分数据环境复杂,人脸和小人脸众多,是训练和检验人脸检测模型较为官方有效的数据集之一。本文在一开始训练模型时还采用了LFW人脸数据集,LFW人脸数据集图像尺寸固定,大部分图像中只包含一张人脸且人脸特征十分明显,相对于WIDER FACE而言识别简单,用于一开始初步训练模型非常合适。图10为LFW和WIDER FACE数据集中的示例图片。

图10 LFW和WIDER FACE数据集中的示例
最终选取WIDER FACE和LFW数据集中15 494张图像进行模型的训练,训练集和验证集和测试集的比例按照7∶2∶1的比例在总图像中随机抽取,保证各类人脸图像的平衡。
3.2 实验环境及训练参数
实验训练所采用的设备为NVIDIA GeForce RTX 2080Ti,CPU i7 9700 K,内存16 GB,操作系统为Ubuntu 18.04 64位,编译环境/语言Pycharm2019.2/Python 3.7,使用Pytorch1.6框架进行深度学习,cuda版本10.1。
根据事先写入用于训练的.yaml超参数文件进行模型的训练,初始学习率0.001,衰减系数0.0005,最小批量32。
3.3 评价标准
本实验针对人脸检测效率、准确度两个方面,选取速度、召回率(Recall)、精度均值(average precision,AP)3个指标来评估各模型的人脸检测表现。
召回率(Recall)是所有真实目标中,模型预测正确的目标比例,公式为
(7)
平均精度(AP)是P-R曲线下面积,P-R曲线即Precision-Recall曲线,Precision为查准率,表示模型预测的所有目标中,预测正确的比例。求解Precision的公式为
(8)
其中,TP表示IoU>0.5时检测框的数量,同一个真实目标框只计算一次;FP表示IoU≤0.5的检测框或者是检测到同一个真实目标框的多余的检测框的数量;FN表示没有检测到的真实目标框的数量。
检测速度表示为每秒钟处理图像的数量,单位FPS。
3.4 实验结果与分析
考虑到本文提出的改进网络模型是用于人脸实时检测的,在减少参数和计算量的同时要保留较高的检测精度,故选择YOLOv3-tiny、YOLOv3、Faster R-CNN、SSD-Lite作为对比模型。所有算法均在WIDER FACE和LFW共同构建的数据集上进行测试,测试对比结果见表3。

表3 不同算法结果对比
由表3可知,像Faster R-CNN这一two stage的大型网络,在人脸检测任务中虽然检测速率低但是检测精度非常高,YOLOv3作为平衡速度和精度的one stage模型代表,在人脸检测任务中虽不落下风,但和本文改进的方法相比无论是精度还是速度都没有任何优势。剩下的两个轻量级网络,在检测速度方面依然无人能敌,但是削减了网络层数,模型整体结构简单检测效果方面达不到实际中的要求。本文的方法虽然检测精度略低于Faster R-CNN,但是速度是它的两倍多。与原方法相比在YOLOv3的基础上替换了主干特征提取网络,减少模型参数以及计算量更能满足实际应用中检测速度的需求,同时增加了SPP结构尺度不变的同时可提取不同尺寸的空间特征信息,提升模型的鲁棒性,检测速度低于两个轻量级网络也是因为在训练后期mAP上升的同时能检测出更多的人脸图像。综上所述,本文提出的方法更适合运用在人脸检测的任务当中。
为了更明显表示我们的方法更适合运用在人脸检测任务中,选取了测试中的一些图片进行检测效果的分析,从上到下依次是原图、YOLOv3-tiny的检测结果、YOLOv3的检测结果、本文的检测结果。
从图11看出,在小人脸众多的场景下YOLOv3-tiny漏检严重,且人脸置信度也是最低的,YOLOv3效果比YOLOv3-tiny较优,在右上方还是有3张人脸漏检的情况,人脸置信度也有相应的提升,本文的算法只有最后一张小人脸漏检,检测效果非常强劲,因此可见本文改进的方法更适合用于人脸检测任务当中。

图11 各种方法的效果对比
4 结束语
本文提出了一种改进YOLOv3的轻量化人脸检测方法。用MobileNetV1替代YOLOv3的主干特征提取网络Drrknet-53,引入深度可分卷积,大幅减少网络参数和计算量。增加了SPP结构,尺度不变的同时可提取不同尺寸图像的空间特征信息,实现不同尺度的特征融合,并且使特征层的表达能力增强。Self-attention机制与FPN结构的融合,减少环境对检测的干扰,使用DIoU损失函数加速模型收敛。实验结果表明,相较于原算法YOLOv3,在公开人脸数据集WIDER FACE上mAP提高了9.0个百分点,检测速度达到了61 FPS,满足人脸检测任务中的准确率和实时性。在今后的研究中,会从其它方面进一步优化我们的模型,使其速度更快精度更高,并且适应多种场景下的人脸检测任务。
