数据产权市场主体的认知调查与矫正*
2022-03-21文禹衡贺亚峰
文禹衡,贺亚峰
0 引言
数据在我国已被视为生产要素,地方立法曾尝试数据确权,如何可持续地大规模激活并释放数据要素的经济价值成为时代命题。然而“数据权”“数据权利”等概念在该问题上的解释力“捉襟见肘”,此时“产权”概念在数字经济市场重新得到重视,于是“数据产权”概念重新回归人们的视野[1]152。
在国内,现有研究成果主要从所有权视角分析,如吴江认为数据产权是指数据的拥有权、使用权、收益权、让渡权等权利[2],汤琪认为数据的产权问题包括数据的所有权、使用权、收益权等问题[3],陈一认为大数据产权转让可分为所有权、使用权、收益权3种交易模式[4],姬蕾蕾认为数据产权集中于所有权并重点关注对数据的占有、使用、收益和处分的权利配置[5]。也有从知识产权视角展开分析,如陈俊华认为衍生数据无法归入现有知识产权客体范畴,需构建包含标记权、存储权、使用权等具体权利的新型知识产权[6]。还有从确权路径展开分析,如司晓认为数据产权不同于传统产权,不宜采取绝对权利的路径[7]。值得注意的是,尽管既有研究成果将所有权的权能——使用权、收益权与所有权并列而言,但也呈现出一种朴素的数据产权观念,其所指“所有权”应是指所有权的权能——占有权。
在国外,现有研究成果很少直接论述数据产权。Schwartz提出以个人数据产权化模型来平衡所有权和使用权以便充分保障隐私信息[8]。Frieden认为应赋予数据创建者个人数据保护的权利[9]。Hoeren等指出数据所有权正在被广泛讨论,必须从法律上界定数据本身、数据所能包含的信息和数据载体之间的关系[10]。Boerding等认为欧洲物权法为建立数据所有权的理论概念提供了框架,进而构建数据所有权概念维度,提出分配所有权的潜在标准,并分析积极的访问和消极的限制权利[11]。Schneider认为生成数据的组织者有权对其生成的数据进行私有化,且可以选择保留数据或将其出售[12]。
我国正处于产业数字化、数字产业化的关键期,《中共中央 国务院关于构建更加完善的要素市场化配置体制机制的意见》提出加快培育数据要素市场,研究根据数据性质完善产权性质。尽管既有研究成果对数据产权展开了不同层面的讨论,但不管是数据产权的支持者还是否定者,都未通过实证方法呈现数字市场主体的数据产权观念到底如何。可能的原因在于:潜在样本中并未出现“数据产权”字眼,因而无法找到样本展开实证研究。然而,市场实践并不介意使用什么概念术语来描述数据产权,而是在于如何务实地描述业务场景所欲实现的目标。“数据产权体系是否形成,并不以法律文本中是否出现‘数据产权’字眼为标志”[1]346,同样,数字市场主体的数据产权观念形成也不以相关文件中是否出现“数据产权”字眼为标志。毕竟在私法上创设产权的路径之一是“要至少有一种法定权利为基础,则可以形成某种产权”[1]117。由此,研究数字市场主体的数据产权观念,可以从样本文件中描述与数据相关的某种权利的实质内涵语句展开。在研究方法选择上,扎根理论方法适合规模大、碎片化样本的定量和定性分析,已成熟运用于政府数据开放利用[13]、公共图书馆健康信息服务[14]、移动图书馆服务质量评价[15]等领域。鉴于此,本文采用扎根理论方法检视我国数字市场主体的数据产权观念并提出矫正建议。
1 研究设计
1.1 样本选取
2021年6月20日至7月15日,本研究以中国互联网协会2020年发布的中国互联网综合实力百强企业为范围,选择连续8年入围互联网企业百强的21家企业主要业务与品牌的“隐私政策”“服务协议”“法律声明”等文本作为样本,检索出现“数据”字词的内容,并联系上下文语义,获取相关内容作为扎根理论的具体分析对象。如此确定样本,主要基于5个方面的考虑:(1)选择互联网企业,因为其是最主要的数字市场参与主体,能够代表数字市场主体;(2)选择“用户协议”“隐私政策”等文本,因为其往往是企业和用户之间的契约,除违反法律的无效条款以外,具有约束双方的效力,其中对“数据”的相关约定至少能反映企业的意图;(3)选择“百强”,因为能进入百强企业一方面是综合实力的体现;另一方面其应担负起相应的社会责任,因而具有一定的代表性;(4)时间限定为连续8年,因为如果企业能够自互联网百强企业排名开始,保持每年进入百强名单,说明其具有相当强的稳定性;(5)选择中国互联网协会发布的排名,因为其具有权威性——中国互联网协会成立于2001年5月25日,由国内从事互联网行业的网络运营商、服务提供商、设备制造商、系统集成商、科研和教育机构等70多家互联网从业者发起成立,是由中国互联网行业及与互联网相关的企事业单位自愿结成的全国性非营利性社会组织,现有会员1,000多个[16]。
取样步骤分为三步:
第一步,将2013-2020年的各年度“中国互联网企业100强”汇总排序,筛选出连续出现8次的企业名称,由此确定连续8年入围互联网百强的21家企业(以下简称“样本企业”)。需要注意的是,部分企业名称在8年间的排行榜上发生变动,如“腾讯公司”变更为“深圳市腾讯计算机系统有限公司”,但仍视为同一个企业;应避免名称含有同类主题词的企业并不是同一个企业,如“深圳市腾讯计算机系统有限公司”与“腾讯音乐娱乐集团”都含有“腾讯”,在整理检索结果时应注意区分。
第二步,如果样本企业有多个主要业务与品牌,仅选择2020年排名榜单中列明的第一个“主要业务与品牌”(以下简称“样本业务与品牌”)。如果在首个样本业务与品牌中一个样本文件都没有,则选择2020年排名榜单中列明的第二个“主要业务与品牌”,以此类推,直到找到样本文件。如果最终无法找到样本文件,则剔除该样本企业。
第三步,在样本业务与品牌的官网或品牌的应用中找出“隐私政策”“服务协议”“法律声明”等可能涉及“数据”的文件(以下简称“样本文件”),如果存在多个样本文件则都找齐。随后,对找齐的文件进行初步检索阅读,剔除不包含“数据”相关内容的文件,如《淘宝网儿童个人信息保护规则及监护人须知》未涉及“数据”,不纳入样本文件。
如表1所示,共获取46个样本文件,累计出现“数据”频次为641次,涉及隐私政策、服务协议、注册协议、许可协议、个人信息保护政策、法律声明、知识产权声明等不同的文件类型。
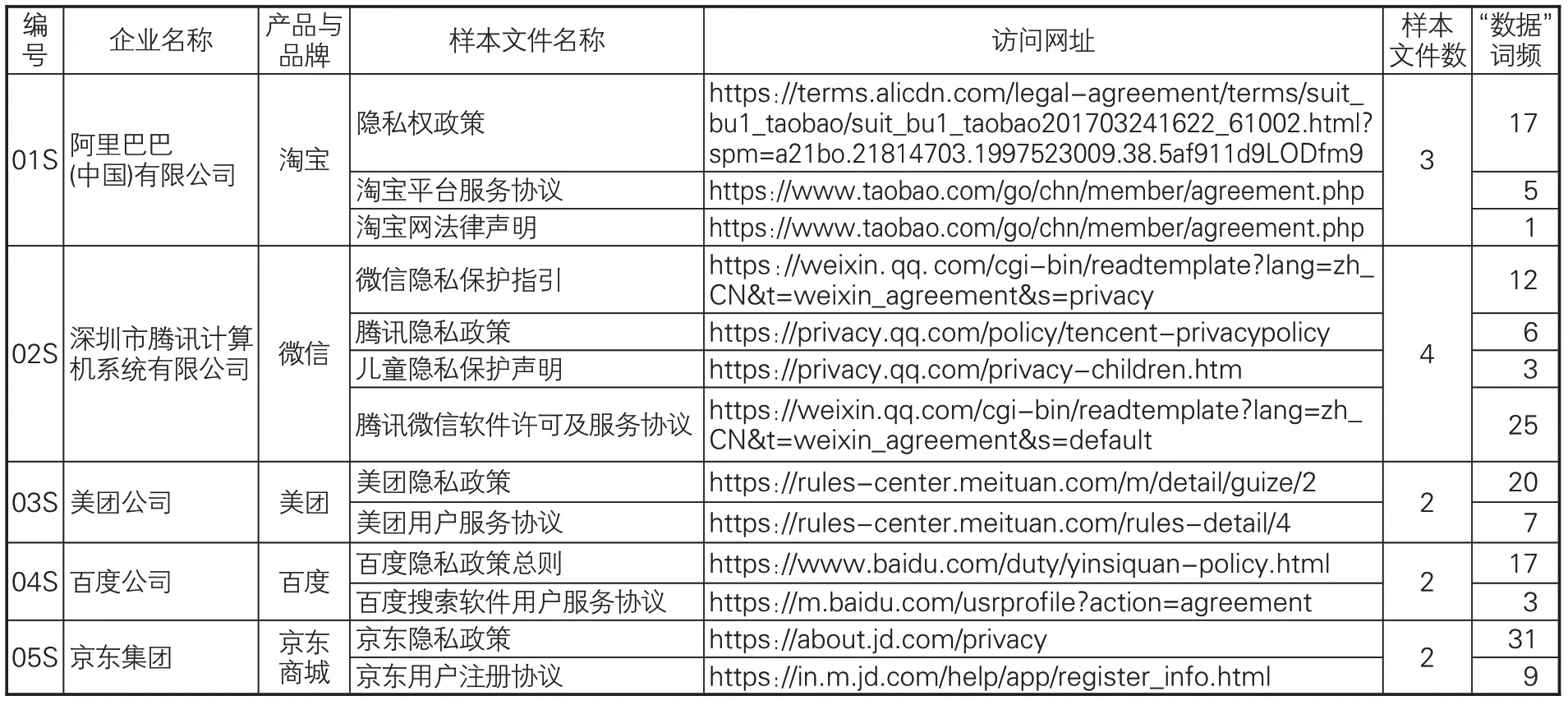
表1 作为样本的21家互联网百强企业
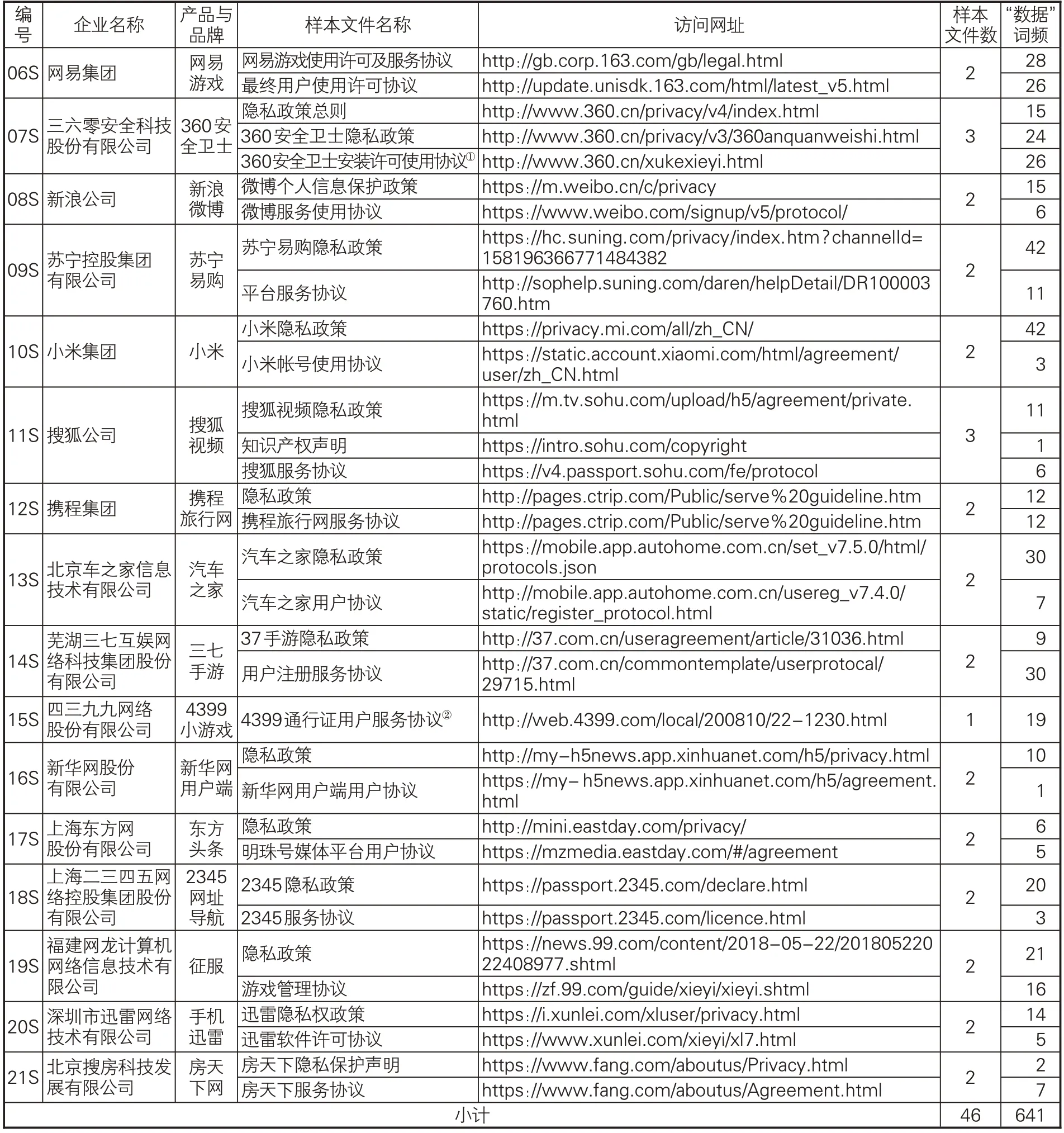
(续表1)
1.2 数据处理
数据和信息是两个完全不同的概念,二者之间的关系具体表现为:数据是信息的载体,而信息是数据的映射[1]88-89。在我国立法实践中,《网络安全法》第37条将“个人信息”和“重要数据”进行并列表述,《数据安全法》第三条第一款将“数据”界定为“任何以电子或其他方式对信息的记录”,说明立法层面就“数据不同于信息”达成了共识。有鉴于此,在筛选样本时并不考虑“信息”相关问题,而只研究“数据”相关问题。在企业的系列文件中,有专门的“用户协议”或“隐私政策”,但并没有就“数据”相关问题作出专门规定。关于“数据”的规定分散在企业的“隐私政策”“用户协议”或“法律声明”等文件之中,故筛选样本文件需根据是否出现“数据”来判断,通过人工筛选共摘录324个与“数据”相关的样本资料。因某些语段中“数据”字眼不只一次出现,因此与“数据”相关的样本资料数量(324个)小于表1中“数据”总词频(641个)。
正因为样本文件内容繁多,且与数据相关内容占比较小,因此在编码前需要对样本资料进行数据清洗。有的样本资料虽然出现“数据”字眼,却与“数据产权”没有关联性。例如,“您可点击此处查看淘宝平台数据共享情况说明”,因此要剔除此类样本资料,不予以编号。逐一检索样本文件中的“数据”,定位到相应语句,再通过人工判断摘录与“数据产权”相关语句形成样本库,作为运用扎根理论方法的原始资料。需要注意的是,原始资料摘录不仅仅只是摘录包含“数据”字眼的语句,根据情况还需要将能够帮助理解“数据”内容的上下文一同摘录(以下简称“原始语段”)。
清洗完样本资料后需要对原始资料进行定位编号,编号规则为“样本企业号+样本文件号+原始语段号+主题词号”。
样本企业号的区位码为第1-3位,取自表1的01S到21S连续编号,分别代表不同样本企业,如“01S”表示表1中的第一个样本企业“阿里巴巴(中国)有限公司”。
样本文件号的区位码为第4-6位:第6位表示同一样本企业中出现的不同样本文件的类型,从“A”开始连续编号;第4-5位表示在同一样本企业中同一类型样本文件出现的次数,从“01”连续编号。如果在第一个样本企业出现了3个不同类型的样本文件,则按其被检索到的顺序,编号为“A”“B”“C”,其中“A”代表与隐私相关的文件(可表述为隐私权政策、隐私保护指引等),“B”代表与服务协议相关的文件(可表述为用户注册协议、用户服务协议、使用许可协议等),“C”代表与法律声明相关的文件(可表述为法律声明等),如“01S01A”“01S01B”“01S01C”;如果在第二个样本企业出现的两个样本文件落入前述三个类型之中,则继续沿用“A”“B”“C”的编号,如“02S01A”“02S01B”;如果在后面的样本企业出现的样本文件超出了这三个类型,则继续编号为“D”,例如在第八个样本企业中出现“个人信息保护政策”,则编号“08S01D”,“D”就代表与个人信息保护相关的文件,以此类推。如果同一样本企业的同一类型样本文件仅出现一次,则都是编号为“01”,如“01A”“01B”;如果同一样本企业的同一类型样本文件出现多次,则在“01”之后继续编号,如“01A”“02A”“03A”或“01B”“02B”“03B”,以此类推。
原始语段号的区位码为第7-8位,从“01”开始连续编号,按照样本文件中出现“数据”的语段顺序编号(如“01S01A01”“01S01A02”),每一样本文件的原始语段号重新开始连续编号(如“01S02A01”“01S02A02”,再如“1S01B01”“1S01B02”)。
主题词号的区位码为第9-11位,从“001”开始非连续编号,按照原始语段中“数据”在样本文件中出现的词频序号编号,“非连续编号”是相对于样本文件中出现“数据”的总词频数而言。比如,“01S01A01001”表示阿里巴巴(中国)有限公司的隐私权政策中第一条关于“数据”的原始语段第一次出现“数据”的位置,“01S01A02004”表示阿里巴巴(中国)有限公司的隐私权政策中第二条关于“数据”的原始语段第四次出现“数据”的位置。这种非连续编号的优点在于可以快速定位到样本文件中的原始语段。
2 研究过程
2.1 开放性编码
第一步,运用内容分析法逐一解构原始资料,对每一个原始资料的内容进行分析,并按照前述编号规则编号(便于追溯原始数据),如表2第二列“原始资料编号”,分析46份样本文件的样本资料共获得与“数据产权”相关的原始资料编号165个。由于开放性编码的资料丰富,限于篇幅,仅以第一个样本企业的全部原始资料示例编码过程(见表2)。
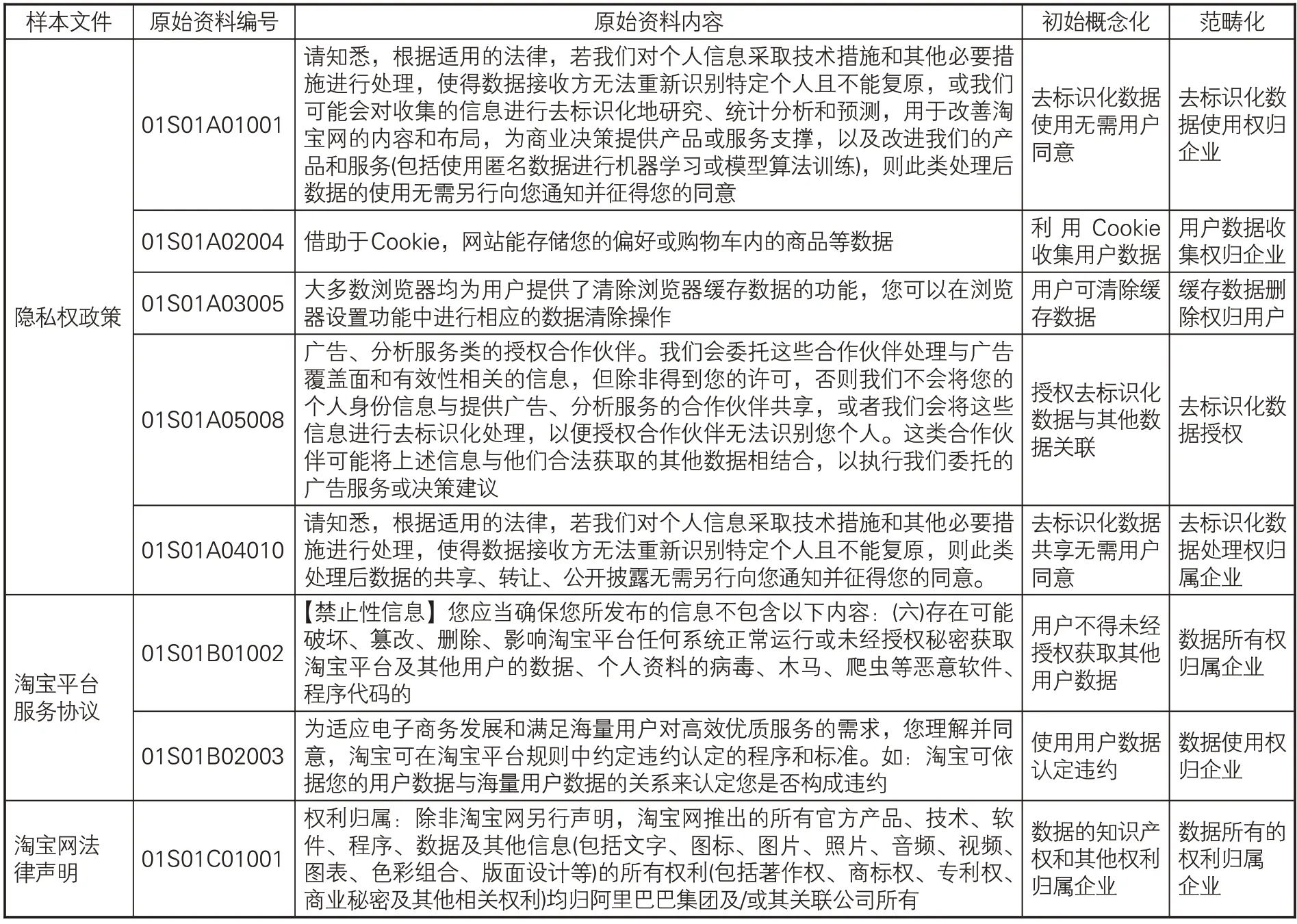
表2 阿里巴巴(中国)有限公司原始资料开放性编码示例
第二步,运用扎根理论对原始资料进行开放性编码,在对每一特定内容概念化时,不拘泥于每一个条文只归纳一个概念,并在此基础上范畴化。在编码过程中注意处理初始概念与范畴的关系,如“数据的知识产权和其他权利归属企业”初始概念标签,在范畴化时仅编码为“数据所有的权利归属企业”,不再单独计量“数据的知识产权”,因为原始资料的“所有的权利”(并非“所有权”)除列举的知识产权外,还包括其他未列举权利,仅计量“数据的知识产权”有失偏颇。在开放性编码过程中再次去除无实质内容的部分,完成137个编号对应内容的开放性编码后,得到137个初始概念,合并重复内容后获得98个初始概念,最终获得44个范畴(见表3)。在初始概念基础上可解读出数据产权的内容,在范畴的基础上可解读出数据产权的“客体”观念。
其他研究成果运用扎根理论方法不同,基于研究“权利”的特殊性,开放性编码时需注重两方面的处理。其一,对原始资料的初始概念化并不追求绝对的简洁表述,而是尽可能用简短文字表述原意,为后续论述权能内容和功能服务。例如,表3中的a1、a12分别体现数据使用权的“优化服务”和“维护交易安全”的内容和功能指向。其二,范畴化在追求简洁表述的同时应确保包括“客体”“权能”“主体”三要素,因为这3个要素构成权利的基本内容。例如,表3中a1-a12的客体都是“数据”,权能都是“使用权”,主体都是“企业”,因此范畴化得到“A1数据使用权归企业”;a13-a19和a1-a12的权能、主体都一样,但不能范畴化为“数据使用权”或“数据使用权归企业”,而是要区分不同的客体——用户数据,因此范畴化得到“A2用户数据使用权归企业”。如此保留基本要素便于后续结论分析,而A1和A2的进一步归纳整理则是主轴编码的工作。

表3 原始资料开放性编码汇总
2.2 主轴性编码
就研究数字市场主体的数据产权观念而言,由于权利基本要素的特殊性,范畴化编码时包括客体、权能和主体,因而在进行主轴编码时要注意区分副范畴和主范畴,即范畴、副范畴和主范畴分别相当于三级指标、二级指标和一级指标。其一,比较开放性编码中获取的44个范畴,将“客体”统一整理为“数据”,整理得到19个副范畴(见表4),在副范畴的基础上可解读出数据产权的“主体”观念。其二,比较主轴编码中获得的19个副范畴,将“主体”统一去掉,整理得到获得14个主范畴(见表5),在主范畴的基础上可以解读出数据产权的“权能”观念。
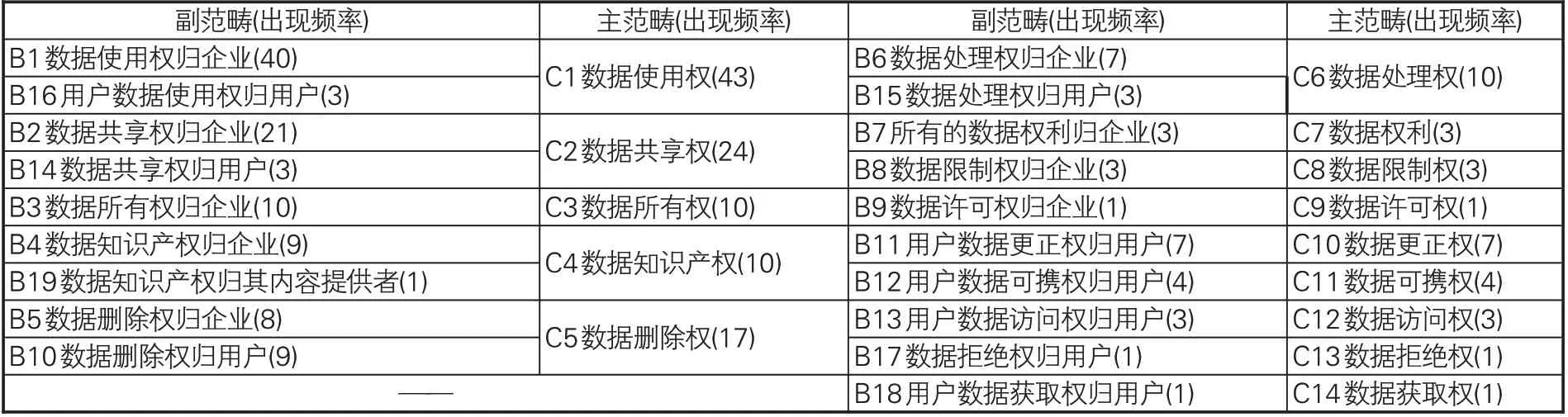
表5 主范畴与对应副范畴
3 研究结论
以互联网企业为代表的数字市场主体所形成的数据产权观念尽管没有像学术研究那样直接使用“数据删除权”“数据可携权”等严谨的表达方式,但通过扎根理论方法分析,在遵循原始资料原意的基础上按照学术表达建构,可呈现比较清晰的数据产权的权能、客体和主体格局。
3.1 数据产权的权能配置
如表5的C1-C14所示,在企业的数据产权观念中,数据之上可以设定数据使用权、数据共享权、数据删除权、数据所有权、数据知识产权、数据处理权、数据更正权、数据可携权、数据访问权、数据权利、数据限制权、数据拒绝权、数据获取权、数据许可权。如表6所示,除“数据权利”属于数据所有的权利的概括性称谓外,共有13项具体的权能类型。其中,排名前三的是数据使用权、数据共享权、数据删除权(简称为“数据产权权能整体排名”),占比分别为31.39%、17.52%、12.41%,数据使用权分别是数据共享权、数据删除权的1.8倍和2.5倍;数据所有权、数据知识产权和数据处理权的占比(7.3%)虽并列第四名,但均未超过10%。可见,对企业和用户而言,在数字市场实践中,数据使用权是最重要的,其次分别是数据共享权和数据删除权,这三项权能能够满足数字市场参与主体使用、共享和删除数据的需求,故后续的进一步分析仅围绕这三项权能展开。

表6 数据产权的权能类型、数量与占比
结合表3的a1-a25,可知各权能的内容和功能指向。以“数据使用权”为例示范归纳过程:对于企业而言,使用权主要是为了实施优化服务(a1/a2/a6/a8/a9/a17/a18)、认定用户行为(a3/a4/a7/a10/a19/a25)、商业利用(a5/a16/a21)、维护交易安全(a12)、数据统计(a14/a23)、用户画像(a15)、控制用户使用行为(a11)等利用(a13/a20/a22/a24)行为;对于用户而言,使用权仅能实现控制其他主体(a93/a95)使用其个人数据,以及自己使用(a94)其个人数据的自由。同样,对企业而言,共享权主要是为了实现服务功能、交易安全、特定业务等目的,而有权决定数据披露事宜、控制数据与第三方共享、便于企业内部共享数据,以及要求数据共享接受方遵守数据保护规定;对用户而言,共享权主要是为了实现其位置数据的分享自由。对于企业而言,删除权主要是为了确保其有权限在用户终止服务、注销账户等场景下删除数据,进而减轻数据安全保护的负担;对用户而言,删除权赋予其要求企业删除其个人数据或自行删除其Cookie数据的能力。综上,对企业而言,使用权是其数字化经营的必要生成要素,共享权是其建立数字化业务往来的基础,删除权是其维护经营业务安全的必要措施;对于用户而言,使用权可确保自己能用、控制他人使用其个人数据,共享权可确保数据共享自由,删除权可实现删除个人数据自由。
3.2 数据产权的客体类型
在企业的数据产权观念中,没有严谨地区分个人数据或非个人数据,而是根据需要使用“数据”和“匿名数据”“用户数据”等概念。在表4的A1-A44的基础上提炼出18种客体类型,涉及数据、用户数据、去标识化数据、游戏数据、用户位置数据、账户数据、非个人身份数据、服务器数据、个人数据、任务效果数据、违法数据、儿童数据、服务数据、异常游戏数据、匿名儿童数据、去标识化儿童数据、匿名化数据、脱敏数据。其中,匿名儿童数据、匿名化数据、去标识化儿童数据、脱敏数据与去标识化数据的最终形态都是无法识别到特定主体,故在计量分析时合称为去标识化数据。但是,由于客体的限制条件关系到客体范围的大小,因此在处理数据时保留限制条件,例如“游戏数据”和“异常游戏数据”分别计为两个客体,因为“异常游戏数据”比“游戏数据”的范围更小。
如表7所示,数据产权的客体类型共14种,从数量来看,占比排名前三的客体类型为“数据”“用户数据”“去标识化数据”,占比排名第四的“游戏数据”不及占比排名第三的“去标识化数据”的四分之一,故仅就数据、用户数据和去标识化数据进一步展开分析。“用户数据”就是学理上的“个人数据”,“去标识化数据”实际上就是学理上的“非个人数据”,而个人数据和非个人数据可统称为“数据”,即“数据”可能为个人数据或非个人数据。因此,在表7中“个人数据”“用户数据”占比之和为19.71%,“非个人身份数据”“去标识化数据”占比之和为16.79%,故数据、个人数据、非个人数据的占比分别为48.91%、19.71%和16.79%,占整个数据客体类型85.41%。综上,在绝大部分数字市场主体的观念中,数据产权的客体主要是个人数据和非个人数据,根据具体业务场景会自行规定其他类型。应当注意:自行规定其他客体类型可能遵循“个人数据”与“非个人数据”的分类,如“用户位置数据”“儿童数据”等属于个人数据范畴;也可能不会明确区分个人数据和非个人数据,如任务效果数据、违法数据。

表7 数据产权的客体类型、数量与占比
在表4的A1-A43的基础上,按照是否可识别到特定自然人的划分标准,将用户数据、户数据、儿童数据、用户位置数据合称为“个数据”,将去标识化儿童数据、匿名儿童数据脱敏数据、非个人身份数据、匿名化数据、去识化数据合称为“非个人数据”,异常游戏据、游戏数据、任务效果数据、违法数据、服器数据、服务数据、违法数据等未明显区分“人”和“非个人”的合称为“数据”。从客体度分析可知:许可权仅设定在非个人数据上,问权、更正权、获取权、拒绝权和可携权仅设在个人数据上,知识产权(含“版权”)、限制和“数据权利”仅设定在数据上;删除权设定个人数据和数据上,所有权设定在非个人数据数据上,处理权、共享权、使用权设定在个人以账人、标数务个角访定权在和数据、非个人数据和数据上。
3.3 数据产权的归属主体
在表5的B1-B19基础上,归纳数据产权的主体主要涉及企业、用户和内容提供者三类,出现频次分别为102、34、1,分别占比74.45%、24.82%、0.73%。由于“内容提供者”概念着意于“内容提供”,在实践中主要是指用户,但也可能是企业,而且占比仅0.73%,故不纳入进一步讨论范围,也不会影响研究结论。企业和用户各有9项权利,其中给企业和用户均配置了使用权、共享权、删除权、处理权,单独给企业配置所有权、知识产权、限制权、许可权和“数据权利”,单独给用户配置更正权、可携权、访问权、拒绝权和获取权。
结合表8和表6分析可知,在企业的权利类型中,除了“数据权利”属于数据所有的权利的概括性称谓以外,共有8项具体权利可以作为产权的基础,其中数据使用权、数据共享权和数据所有权占比排名前三(简称“企业数据产权独立排名”)。企业数据产权独立排名的第三位是“数据所有权”,取代了数据产权权能整体排名的第三位“数据删除权”。由此说明,除使用和共享数据外,企业仍然企图实现对数据的独占和排他,这从占比排第四位的“数据知识产权”可以得到印证,因为知识产权就有很强的“合法垄断”性。同样,在用户的权利类型中,共有9项具体权能可以作为产权的基础,其中数据删除权、数据更正权和数据可携权占比排名前三(简称“用户数据产权独立排名”)。用户数据产权独立排名的第一位“数据删除权”和第二位“数据更正权”,分别取代了数据产权权能整体排名的第一位“数据使用权”和第二位“数据共享权”。由此说明,企业并不重视用户的数据使用权和数据共享权,而是重视用户的数据删除权、数据更正权和数据可携权,不过这不是企业的“仁慈”,而是因为业务合规和商业策略的需要。综合而言,企业作为数字市场主体的强势方,在其所主导指定的隐私政策、服务协议、个人信息保护政策等文件中,虽然企业的数据产权仍然占绝对主导地位,但没有完全排除用户的数据产权,具有一定的数据合规意识。

表8 数据产权谱系及其权能数量与占比
在表4的A1-A43的基础上,从主体角度分析可知,“个人数据”之上被设定9项具体权利,用户仅单独享有获取权、拒绝权、可携权、删除权、访问权、更正权,企业和用户都享有各自的处理权、共享权和使用权;“非个人数据”之上被设定5项具体权利,处理权、共享权、使用权、所有权、许可权全部由企业享有;“数据”之上被设定12项具体权利和1项概括性权利(数据权利),企业享有版权、共享权、删除权、使用权、所有权、知识产权、处理权、共享权、删除权、所有权、限制权和“数据权利”,仅企业和用户同时享有各自的处理权,用户的该“处理权”实际上是“用户可抛弃其游戏数据”。可见,在数据之上设定的13项具体数据权利类型中,几乎只在个人数据上给用户配置权利,但企业可以就个人数据和非个人数据享有权利。
4 研究展望
当前我国数字市场主体已经形成主体、客体和权能三要素具备的数据产权观念,在主体方面基本已形成“企业-用户”的格局,因而主要从权能和客体两方面展开矫正。
4.1 数据产权的权能观念矫正
在企业设定的13项具体的权利类型中,除根据业务实际需要设定“数据共享权”外,其余权利类型均可在既有权利观念中找到“原型”。在《通用数据保护条例》各项数据权利观念影响下设定数据删除权、数据更正权、数据可携权、数据访问权、数据限制权、数据拒绝权,在“可携权”的“获取”权能观念影响下设定数据获取权;在既有的所有权、知识产权、许可权的权利观念影响下设定数据所有权、数据知识产权、数据许可权;在所有权的使用、处理的权能观念下设定数据使用权、数据处理权。从实质意义来看,许可数据关联(a71授权去标识化数据与其他数据关联)的前提是对数据享有占有的权利,故可归入“数据所有权”范畴。由此,可将数字市场主体的数据产权观念简化为数据所有权、数据知识产权、数据共享权,以及数据删除权、数据更正权、数据可携权、数据访问权、数据限制权、数据拒绝权。
需要矫正的是在数据上形成的“所有权”和“知识产权”观念,这两类权利的共性在于“排他”。《中华人民共和国民法典总则编》的起草过程能洞见在立法上已经否定在数据上设定这两类权利的可能性。《中华人民共和国民法总则(草案)》简称《民法总则(草案)》一次审议稿就将“数据信息”安放在知识产权客体条款(第108条第2款)之中,直接否定“数据所有权”的可能性,而是在知识产权范畴寻找嵌入空间,毕竟数据和知识产权客体具有某种外观上的相似之处——无形性、非损耗性和可复制性。然而,《民法总则(草案)》二次审议稿直接在知识产权客体条款(第120条第2款)中删去“数据信息”,取而代之的是以第124条的“法律对数据、网络虚拟财产的保护有规定的,依照其规定”预置立法空间,可见立法层面已经意识到符合相应构成要件的数据可以援引版权和商业秘密等加以保护,不符合相应构成要件的数据纳入到知识产权客体范畴也“无能为力”。此后《民法总则(草案)》二次审议稿的第128条和颁布的《民法总则》(现被《民法典》的“第一编 总则”取代)的第127条都保留前述第124条的表达。综上,从“数据信息”到“数据”的矫正,从否定将“数据”纳入所有权,到企图在知识产权范畴寻找空间,再到为数据保护预置立法空间,无不说明在数据上设定所有权和知识产权的不可能性。
企业应当在现有的法律框架下,在数据之上设定相关权利时使用规范的权利概念,这些概念可以来自于域外法律实践,也可以是企业根据业务场景需要而拟定,尤其要注意不宜与现有的权利实质相悖。否则将会导致数据难以获得法律保护,而且容易强化“数据确权困境”观念,不利于为今后立法形成数据确权的观念基础。
此外,还要跳出“非此即彼”式排他、独占的权利逻辑,而是基于数据具有使用非损耗性和非独占性的自然属性[1]92,针对不同的主体需求设定不同的产权权能——以“控制”为核心为用户设定数据控制权,以“经营”为核心为企业设定数据经营权,以这两类权能作为数据的产权基础。为了实现用户和企业之间数据产权的权利能力平衡,可围绕“控制”为用户设定数据的拒绝权、可携权和删除权,可围绕“经营”为企业设定数据的相对性占有权、生产性使用权、经营活动自主权和增量财产收益权[1]173-276。
4.2 数据产权的客体观念矫正
以是否可以识别到特定自然人为划分标准,可以将数据分为个人数据和非个人数据,那么在统计意义上“未区分个人和非个人的数据”则可视为“数据”。在表7的基础上按此标准归纳整理可知,个人数据占比42.50%、非个人数据占比28.75%、数据占比58.39%。然而,在“数据”之上仅设定一项“用户可抛弃其游戏数据”,由于“未区分个人和非个人的数据”实际上可以识别到特定主体,意味着企业在个人数据上为自己设定的权利占比71.53%。从这个意义上而言,在没有法律明确规定的情况下,企业藉由其强势地位,几乎将个人数据视为己有。
企业通过隐私政策、服务协议等文件为自己设定数据产权时,应该进一步区分个人数据和非个人数据,在此基础上方可进一步根据业务场景设定具体的数据类型。企业可在非个人数据上为自己设定权利,但应承认用户在其个人数据上享有权利,这并不是绝对地否定企业在个人数据上享有的权利,其前提是经过用户同意——法理基础在于“权利让渡”或“权利转让”。如此,有利于促进不同主体就数据产权达成最小共识。
注释
①360安全卫士安装许可使用协议访问地址内包含360公司旗下多个产品的许可使用协议,“数据”出现次数仅截取于360安全卫士的安装许可使用协议中。
②《4399通行证用户服务协议》由《4399通行证服务条款》《网络游戏用户隐私权保护和个人信息利用政策》《4399游戏平台服务条款》《用户守则》四部分组成。
