一种基于PBI指标支配的多目标优化算法
2022-03-21南宁师范大学计算机与信息工程学院郭华
南宁师范大学计算机与信息工程学院 郭华
利用支配和指标度量结合的方式提出一种新的支配关系,通过该支配关系构造出新的多目标优化算法MOEA-PBI,该算法对多目标优化问题进行有效优化,从而得出一组可供选择的折中解。新算法与其他三种代表性的多目标进化算法一同在3,5和8目标的DTLZ基准测试问题上进行测试,结果表明MOEA-PBI算法具有较为优秀的收敛性和多样性。因此得出结论,MOEA-PBI算法是一种可以选择的多目标进化算法。
现实中存在着很多需要同时优化多个目标的优化问题,这类问题统称为多目标优化问题(Multiobjective Optimization Problems,MOPs),MOPs的解方案通常并非单个解,而是一组折中解。为解决这些MOP问题,研究者们提出了一些有效的多目标进化算法(Multi-objective Evolutionary Algorithms,MOEAs)。目前常见的MOEAs主要分为三大类:(1)基于分解的多目标进化算法,张青富等人在2007年提出的MOEA/D算法开创了分解策略应用于解决MOP问题的先河,该算法通过在目标空间生成均匀分布的权重向量来引导解个体的收敛。(2)基于支配关系的多目标进化算法,Deb等人提出的NSGA-II算法在NSGA算法的基础上增加了快速非支配排序策略,使得基于Pareto的NSGA-II算法在解决MOP问题时不仅具有良好的收敛性和分布性,而且大大降低了时间复杂度。(3)基于指标的多目标进化算法,Bader等人基于超体积(Hypervolume,HV)指标提出HypE算法,通过HV指标将不可直接进行比较的解个体向量,转化为可以直接比较大小的标量,从而进行个体筛选和优化。
但随着优化问题的目标个数增多,传统的MOEAs已经不能很好地解决四个及以上的高维多目标优化问题(Many-objective Optimization Problems,MaOPs),本文通过将基于支配的方法与基于指标的方法结合,利用支配关系的收敛性优势和指标方法的多样性优势,从而解决高维多目标优化问题。
1 预备知识
1.1 MOP问题的基本概念
一般而言,最小化问题可表示如下:
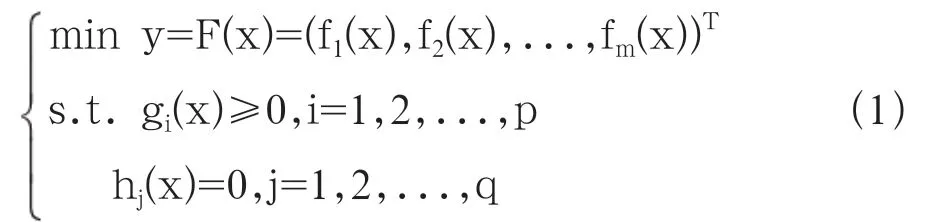
其中,x=(x,x,...x)∈X⊂R是n维决策向量,X为n维决策空间;y=(y,y,...y)∈Y⊂R为m维的目标空间;目标函数F(x)定义了由决策空间X向目标。空间Y映射的函数,g(x)定义了p个不等式约束,h(x)定义了q个等式约束。约束函数g(x)和h(x)共同确定了决策向量x的可行域。一般当目标数m≥4时,式(1)中的MOP问题又被称为MaOP问题。下面是MOP问题中一个重要的概念。
1.2 基于惩罚的边界相交法PBI的概念
PBI方法来源于MOEA/D算法的效用函数。在MOEA/D算法中,PBI作为一个可选择的函数,在度量解个体的优劣上体现出了它的优越性。PBI方法由可以度量个体收敛性和个体分布性的两个指标构成,它们分别是d距离和d距离。d距离代表的是个体在权重向量上的投影到原点的距离,所以d距离可以直观地表现出个体的收敛性。d距离代表的是个体到权重向量的垂直距离。而权重向量在初始设置中,是一组从原点出发、均匀分布的向量,所以个体越靠近权重向量,个体分布也就越均匀。即d距离可以直观地刻画出个体的分布性。具体地,PBI方法采用式(2)的方式计算,PBI值总体越小,则表示个体的收敛性和分布性越好,即个体越优秀。其中变量θ的作用是均衡种群的收敛性和分布性,当种群收敛过快而分布性较差时,就需要将θ值放大来强调收敛性,反之亦然。
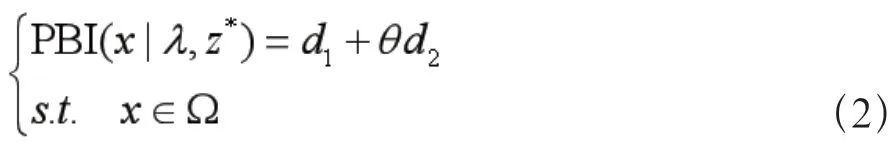
求解MOP需预先在目标空间生成一组均匀分布的权重向量,权重向量从原点出发,沿着各自的方向延伸并与可达目标空间的最左下边界(即规范化的PF)相交。通常,如果权值向量的数目设置合理,那么在PBI方法的引导下,可以产生一组较为优秀的解个体。图1为PBI方法在双目标优化问题上的形象描述。其中,F(x)为目标空间的任意一点,λ为一个权重向量,则d表示F(x)的投影点y与原点之间的距离,d表示F(x)与权重向量λ之间的垂直距离。
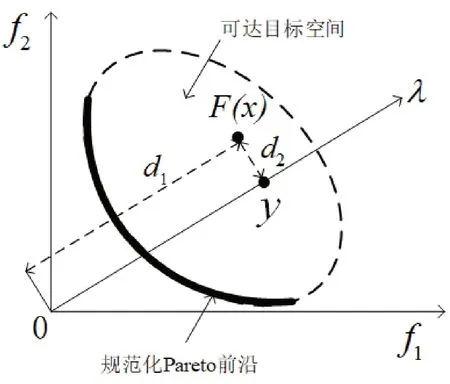
图1 PBI示意图Fig.1 Schematic diagram of PBI
2 MOEA-PBI算法
受MOMBI算法的启发,通过计算个体基于惩罚的边界相交法(Penalty-based Boundary Intersection,PBI)的值来度量解的优劣性。每一个个体对于任意一个权重向量都有唯一的PBI值,在支配关系中应用该值平衡收敛性和分布性,则能对种群个体进行一个合理的支配分层。算法的具体步骤:(1)首先生成具有N个个体的初始种群,同时在目标空间生成与个体数目相同的N个均匀分布的权重向量;(2)在每一代中,计算每个个体到每个权重向量的PBI值;(3)在同一个权重向量下,根据PBI值大小对每个个体进行升序排序,并赋予个体序号值;(4)循环步骤(3),对全部N个权重向量进行上述操作;(5)对于任意个体而言,它将具有N个针对不同权重向量的序号值,存储其中最小的序号值作为该个体在全部个体中所处的非支配层数,非支配层数越小,则表示个体越优秀,也就越容易进入下一代进化中。至此,不同个体所在非支配层之间的支配关系构建完成。
传统的多目标进化算法在保持种群多样性方面,一般采用拥挤距离的度量,该方法存在一定缺陷,即在高维空间中欧氏距离的度量不再适用。个体的拥挤距离存在不能准确度量个体拥挤度的问题,在种群迭代的时候,该问题会导致分布性差的个体反而被保留,进而导致种群多样性较差。如公式(3)所示,本文采用PBI指标值度量个体多样性适应度,即利用公式(2)计算最后一层非支配层中个体对于各个权重向量的PBI指标值(一般θ取值为5),选择最小的PBI值作为该个体的多样性适应度。P表示个体i的多样性适应度,PBIj∈{1,...,N}表示个体i与每一个权重向量j都进行PBI计算,最终保留最小值。图2以MOEA-PBI算法的第t代为例说明算法的运行机制。
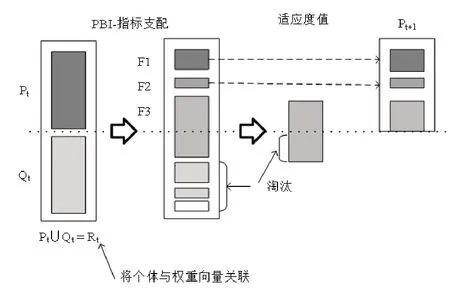
图2 MOEA-PBI算法运行机制Fig.2 Operating mechanism of MOEA-PBI

3 实验与分析
一般针对MOP问题的MOEAs大多利用Das等提出的方法产生权重向量,但对于MaOPs问题来说,其目标数通常≥4,如果仍然使用该策略,则会使得产生的种群数目过于庞大。为此,本文利用双层参考向量生成方法。
为验证MOEA-PBI的算法性能,本文将其与三种经典的多目标算法进行实验对比,分别是RPDNSGA-II、NSGA-II、MOEA/D。四种算法一同在3-、5-和8-目标的DTLZ系列测试问题集上进行实验,通过IGD性能指标以检验算法的收敛性和多样性。实验中对各目标数的种群规模分别设为92、212和156,评估次数为50000。表1列出了四种算法在DTLZ系列测试问题上获得的IGD均值和方差。表内各行最佳的结果加粗表示。其中MOEA-PBI、MOEA/D、RPD-NSGA-II、NSGA-II算法在这些测试实例上获得最佳IGD均值的个数分别为9、3、2、1。另外,从表1的检验结果来看,MOEA-PBI相对于MOEA/D、RPD-NSGA-II、NSGA-II的净胜得分(得“-”数目减去得“+”的数目)分别为5,11,11。综上,MOEA-PBI算法在求解DTLZ系列问题时具有显著较优的性能。
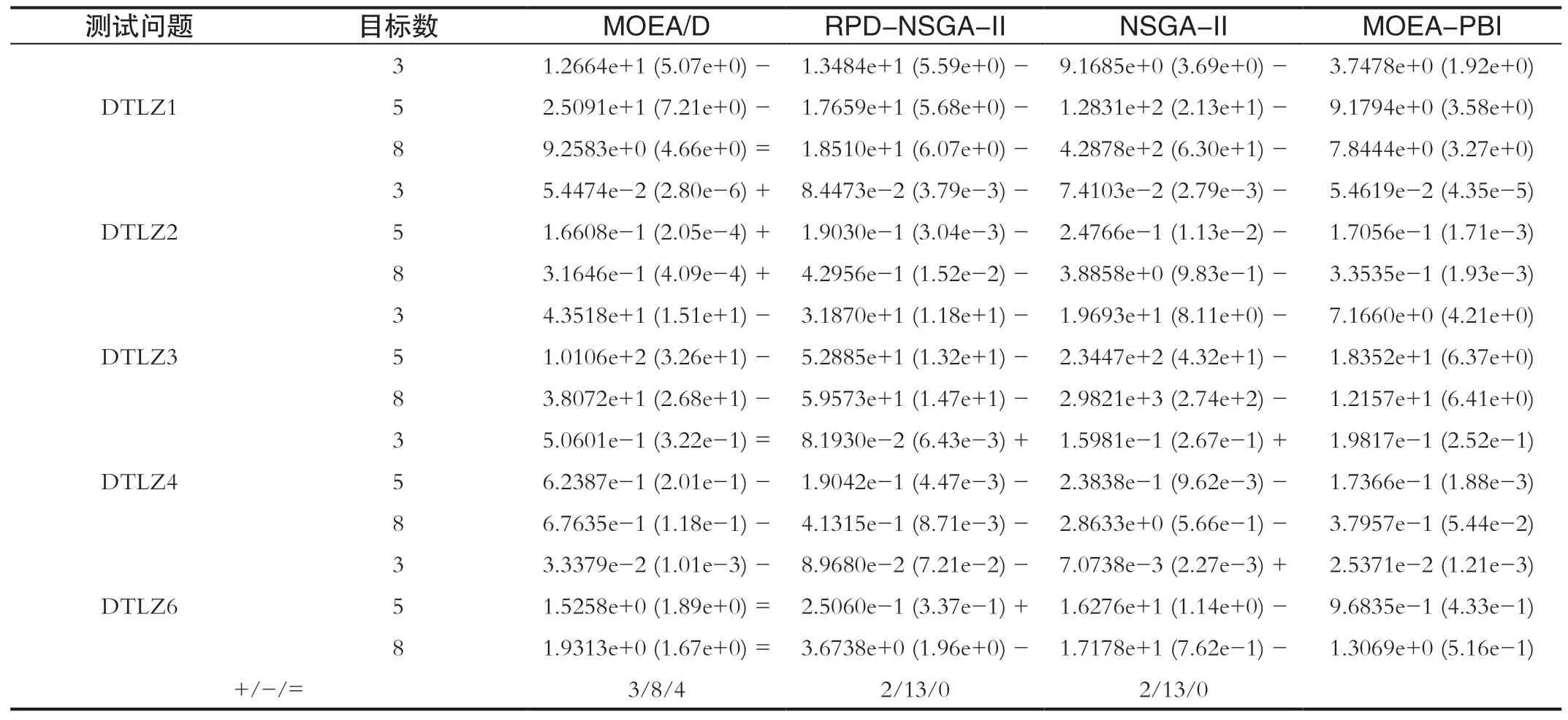
表1 四种算法在DTLZ系列问题上获得IGD值Tab.1 The IGD values of the 4 algorithms on the DTLZ test function
4 结论
未来将面临更多有关高维多目标问题的挑战,研究者们应当提出更高效的算法来解决这些问题。本文通过支配与指标相结合的原则,利用支配策略偏向强调收敛性,指标策略偏向强调多样性的特征,共同促进解个体向真实Pareto前沿收敛。实验结果表明,MOEA-PBI在面对高维多目标问题时,总体具有较好的性能。在解决日后的MaOPs时,MOEA-PBI也不失为一种较优的选择。
