基于Python的招聘数据爬取与分析
2022-03-19丁文浩朱齐亮
◆丁文浩 朱齐亮
基于Python的招聘数据爬取与分析
◆丁文浩1朱齐亮2 通讯作者
(1.华北水利水电大学信息工程学院 河南 450000;2.华北水利水电大学建筑学院 河南 450000)
本文利用网络爬虫爬取招聘数据并对其进行数据清洗,通过pyecharts绘制图形,对诸如薪资水平、工作经验、热点城市、学历要求、员工福利等数据进行可视化分析。直观反映互联网招聘的真实情况,可为相关专业人才的职业发展提供判断信息。
网络爬虫;数据预处理;pyecharts;可视化
随着网络信息技术的蓬勃发展,网络招聘这一早年流行于欧美国家的新型招聘方式也已在国内广泛使用[1],人才招聘方式也逐渐从传统的平面广告招聘向网络招聘转变。近年来,网络招聘数据量呈现爆炸式增长,有效提取并利用招聘数据也已成为了数据分析与挖掘领域的研究热点[2]。本文使用Python语言编码爬取了前程无忧网站发布的数据算法工程师、大数据开发工程师等7个大数据相关的6279条招聘数据,利用Python提供的第三方库pyecharts着重对城市、学历、工作经验、工作行业等因素进行绘图分析。
1 数据采集
数据采集是数据分析的基础。没有数据,分析也就没有任何意义。常见的数据来源分为四类:开放数据源,爬虫抓取,日志采集和传感器[3]。本文采用爬虫抓取的方式实现数据采集。
爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本[4],目前大多数的爬虫使用后台脚本类语言编写,基于Python语言实现的最多。
1.1 爬虫算法设计
本文爬虫算法通过调用Request模块对相应URL发起请求,获得Response响应,在Response响应中包含页面的所有信息,解析出响应中的每条招聘信息的URL,再通过Request模块发出请求,爬取详细的招聘页面,并通过Xpath确定所需文本具体位置,对文本内容进行解析、抓取,最终数据会保存在指定的CSV文件中以备后续处理,算法整体流程如图1所示。
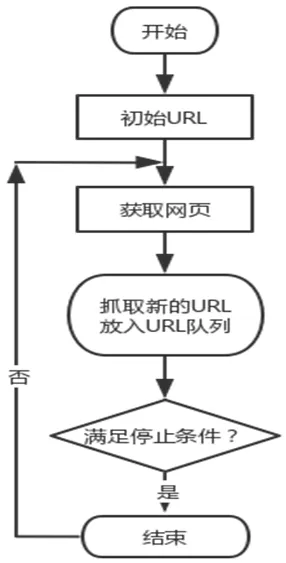
图1 算法流程图
1.2 爬虫算法实现
1.2 .1获取招聘信息URL
打开前程无忧网站,进入数据挖掘工程师招聘页面,按F12键进入开发者模式以进行页面分析。点开Network查看XHR,刷新页面,在Headers中查看参数信息的请求方式为GET方式,状态码为200,在Response中查看响应信息,从响应中可以找到页面中的所有信息,爬取各个招聘信息的URL。关键代码如下:
response = requests.get(URL,headers=headers)
t = response.text
bs = etree.HTML(t)
c = bs.xpath("//script[@type='text/javascript']")[2].text
op = eval(c[29:])['engine_search_result']
for i in range(0, len(op)):
a = [op[i]['job_href']]
list.append(a)
1.2 .2 招聘信息数据爬取
在招聘岗位信息的页面,根据数据采集所需的文本,获取文本信息的Xpath,通过Xpath解析抓取所需数据。具体代码如下:
job_name = html.xpath('//div[@class="cn"]/h1/text()')
company_name = html.xpath('//div[@class="cn"]/p[@class="cname"]/a[1]/text()')
salary = html.xpath('//div[@class="cn"]/strong/text()')
attribute_text = html.xpath('//div[@class="cn"]/p[@class="msg ltype"]/text()')
jobwolf = html.xpath('//div[@class="cn"]/div[@class="jtag"]/div[@class="t1"]//text()')
companytext1 = html.xpath('//div[@class="com_tag"]/p[1]/text()')
companytext2 = html.xpath('//div[@class="com_tag"]/p[2]/text()')
companytext3 = html.xpath('//div[@class="com_tag"]/p[3]/a[1]/text()')
keywork = html.xpath('//div[@class="mt10"]/p[2]/a/text()')
1.2 .3数据存储
Python内置了CSV文件操作函数,所以本文选择将数据写入CSV文件实现保存工作。具体代码如下:
with open("数据挖掘工程师.csv","a+") as f:
writer = csv.writer(f,dialect="excel")
csv_write = csv.writer(f)
csv_data = result
csv_write.writerow(csv_data)
f.close()
2 数据预处理
2.1 数据清洗
数据清洗即去除信息中的重复信息和错误信息,这些数据会影响后续的分析,数据清洗的过程对数据分析十分有必要。数据清洗主要包括以下步骤:(1)删除错误数据;(2)处理重复数据;(3)处理空值;(4)检测离群点,处理异常数据[3]。
2.1 .1数据去重和空值处理
所有数据要保证一一对应,在此前提下去除重复行(data.drop_duplicates(inplace=True))。
对于薪资中出现的空值,如果全部删除会降低数据分析的可靠性,找出缺失数据所处岗位,遍历岗位薪资数据,得到众数值填充进空值处。最后删除数据采集过程中产生的其他空值所在的行
(drop_index = data.loc[data.isnull().any(axis=1)].index
data=data.drop(labels=drop_index,axis=0))。
2.1 .2异常值处理
对于数据中可能出现的异常数据,使用上四分位法进行检测,并对区别于大多数正常数据的离群数据进行删除。部分代码如下:
(q_low=data['薪资'].quantile(q=0.25)
q_high=data['薪资'].quantile(q=0.75)
q_interval = q_high-q_low)
2.2 数据规范化
2.2 .1拆分数据
采集到的数据中,在工作岗位所在地一栏有的包含区,有的则不包含,因此需要统一到城市(data['工作地点']=data['工作地点'].str.split('-').str[0])。
2.2 .1薪资优化
薪资一列出现了多种表达形式:1.2万-1.8万/月、15万-20万/年、30元/小时,其中30元每小时多为实习生招聘,对此类数据进行删除,其他的表达形式统一修改为以k为单位的月薪形式。为了方便分析,添加最高薪资、最低薪资、平均薪资列,并将原薪资列删除。
3 数据分析可视化
3.1 发达城市平均薪资和岗位平均薪资分析
首先对数据进行处理,提取热门城市,再对招聘信息进行分析,对热门城市的最低平均工资、最高平均工资,和平均工资进行分析展现,如图2所示。岗位平均薪资分析图显示各个岗位的平均薪资水平,如图3所示。
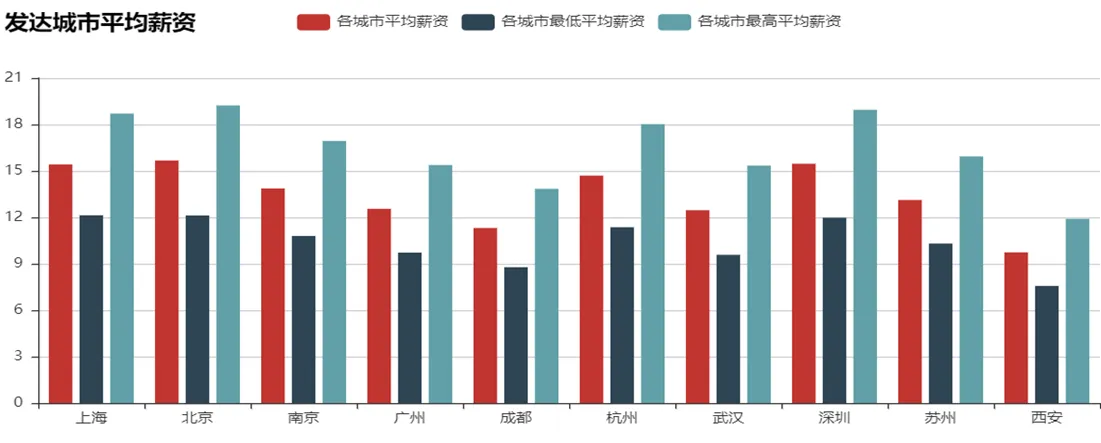
图2 发达城市平均薪资分析图

图3 岗位平均薪资分析图
3.2 工作经验分析
工作经验分析图对经验要求情况进行展示,如图4所示。不同工作经验薪资分析图对不同工作经验的薪资情况进行展示,如图5所示。
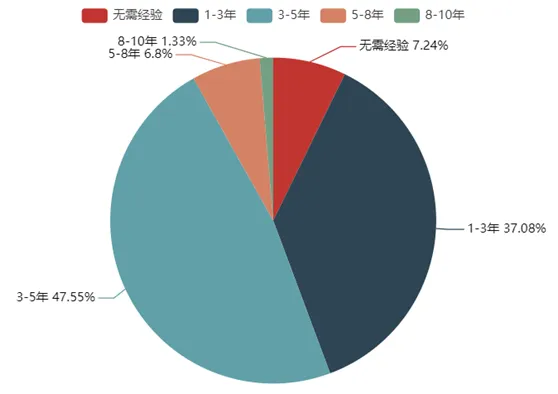
图4 学历平均薪资分析图

图5 不同工作经验薪资分析图
3.3 学历情况分析
学历占比图对企业招聘要求最低学历进行分析,如图6所示。学历平均薪资分析图对不同学历验的平均薪资情况进行展示,如图7所示。

图6 学历占比图

图7 学历平均薪资分析图
数据算法工程师、数据分析师和数据专员三个岗位对不同学历的招聘需求差别巨大,如图8所示。导致了三个岗位薪资待遇的差别,学历也由此成为了不同岗位之间的行业壁垒。
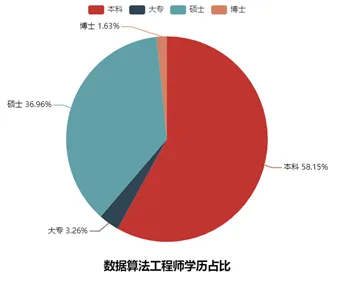
图8 不同岗位学历占比图
4 结束语
使用Python对前程无忧网站爬取招聘信息并进行可视化分析,这一工作整体分为三个模块。首先是用户根据对数据的需求改变爬虫程序的输入参数,获得不同职位的招聘信息。接下来是数据预处理阶段,数据预处理是数据分析的重要前提,预处理的效果直接决定数据分析的好坏。最后是数据分析模块,对需要进行分析的数据进行不同类型的可视化实现,将复杂的数据直观形象地展现出来。
本文数据分析的结果也可为网上求职者提供一定的帮助,求职者若从事数据类技术岗,数据算法、数据挖掘是非常不错的工作方向;若对数据分析类岗位感兴趣,则具备本科学历的求职者具有较大优势;有3-5年工作经验且有本科学历的技术人员比较容易找到大数据方向的工作;互联网行业对技术类人才需求较大,其中高学历人才尤其受欢迎。
[1]中国网络招聘市场发展研究报告[A]. 上海艾瑞市场咨询有限公司.艾瑞咨询系列研究报告(2021年第3期)[C].:上海艾瑞市场咨询有限公司,2021:48.
[2]张长华.大数据视域下网络招聘数据信息挖掘的研究[J].科学技术创新,2021(10):114-115.
[3]杨众.基于Python语言的招聘信息可视化分析[J].计算机与网络,2020,46(02):61-64.
[4]熊章军.基于互联网大数据的招聘数据智能分析平台研究[J].科学技术创新,2020(24):91-92.
