基于文本知识库的肝损伤药物不良反应大数据智能识别研究
2022-03-18葛斐林郭玉明柏兆方王伽伯肖小河
葛斐林, 郭玉明, 牛 明, 赵 旭, 柏兆方, 王伽伯, 肖小河
1 中国人民解放军总医院第五医学中心 肝病医学部研究所/全军中医药研究所, 北京 100039;2 北京中医药大学 中药学院, 北京 100029
近年来,国务院先后发布了《“健康中国2030”规划纲要》及《“十三五”国家药品安全规划》等医药卫生相关文件,药物安全性已经越来越成为国家层面关注的重点[1-2]。随着药物不良反应(adverse drug reactions,ADR)的报道逐年增多以及公众健康意识的提高,药物的安全性问题也越来越受到公众广泛关注[3-5]。
由于ADR事件发生率较低, 有限的病例数据难以为药物安全性评价提供更多的证据。医疗大数据时代的到来,为药物警戒与风险防控带来了极大的发展机遇[6-7]。然而,目前药物警戒领域对于ADR大数据的处理还处于探索阶段。以ADR自发上报数据为例,数以百万计的数据信息一方面提供了极为丰富的风险信号;另一方面,由于数据本身规范性、完整性较差,给数据识别与评价造成了障碍。可见,ADR大数据的信息资源尤为重要,而数据信息的高效识别和精准分析则是安全性评价的关键。肝损伤相关ADR为临床常见的药物不良反应之一, 严重者可致急性肝衰竭甚至死亡,其已成为药物研发失败、增加警示和撤市的重要原因, 受到医药界、制药业、管理部门及公众的高度重视[3,7]。因此,本研究以肝损伤相关ADR为例,尝试从药品不良反应监测系统(ADR-SRS)数据库入手,在人工临床再评价基础上建立肝损伤相关ADR风险识别规则,实现基于肝损伤相关ADR文本知识库的大数据智能识别评价,以期为ADR大数据的智能识别提供方法参考,促进药品安全性评价与防控的积极推进。
1 材料与方法
1.1 数据来源 本研究采用的文本数据来自2012年1月1日—2016年12月31日,ADR-SRS中标记为“药物性肝损伤”“药源性肝损伤”“肝功能异常”“肝细胞损害”“肝损害”“肝炎”“肝酶升高”“肝衰竭”“肝毒性作用”“肝功能损害”“黄疸”“肝硬化”“肝区不适”“药物性肝病”等肝损伤相关的ADR数据。
1.2 文本数据的清洗与归一化处理 通过剔除重复上报数据及其他无关数据后,共得到肝脏相关ADR数据55 388例。抽取ADR名称、临床症状、临床指标、药物信息等关键字段,将关键字段的“非标准表述”映射到“标准表述”,提出关键字段的语义层级划分,根据《药物性肝损伤诊治指南》[3]以及《中药药源性肝损伤临床评价技术指导原则》[8],为ADR名称、临床症状、临床指标、药物信息进行包含同义、对义的语义层级构建,建立同义、对义词库。
1.3 数据析取与人工再评价 随机抽取5%共计4152份肝损伤相关ADR病例报告,由2名5年资以上的肝病专科临床医生分别进行临床再评价,参考WHO-UMC不良反应因果关系评价标准[9]以及《药物性肝损伤诊治指南》[3],将肝损伤相关ADR再激发病例定义为“确定病例”,将ADR名称与肝损伤无关及明显非损肝药物的病例定义为“否定病例”,其他病例为“疑似病例”。
1.4 智能识别规则的确定 依据人工再评价结果,分别提取不同分组中ADR风险信号识别的关键要素信息,对提取到的ADR名称、临床症状、临床指标与肝损伤相关ADR因果评估进行相关性分析,确定方法建立所需要的关键指标;通过2倍中位数及ROC曲线分析,进行关键指标、评分标准及阈值的确定,确定智能识别基本规则。
1.5 智能识别规则的交叉验证 本研究中共有3组数据需要进行交叉验证,即“疑似病例”-“否定病例”,“确定病例”-“疑似病例”,“确定病例”-“否定病例”,以检验智能识别规则的识别稳定性。比如“疑似病例”-“否定病例”的十折内部交叉验证,即分别将“疑似病例”与“否定病例”分成10份,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得出相应的正确率(或差错率),10次结果正确率(或差错率)的平均值作为对算法精度的估计。
2 结果
2.1 同义、对义语义词库的建立 通过对肝损伤相关ADR关键字段的规范化处理,将ADR名称,生化指标,临床症状的同义、对义表述进行归一化处理。例如不良反应名称中的“肝功能异常”的同义表述包括肝功异常、肝功能受损、肝功能损害、肝功异常加重、肝功能变化、肝功能失调,对义表述包括转氨酶升高、转氨酶异常、肝酶升高、肝酶异常、转移酶高、转氨酶升高;生化指标中的“ALT”的同义表述包括GPT、丙氨酸氨基转移酶、谷丙转氨酶、谷氨酸-丙酮酸转氨酶、丙氨酸氨基转移酶、转氨酶。
2.2 关键字段的热图分析 将析取后的关键字段进行肝损伤相关ADR的热图分析发现,ADR名称、生化指标、临床症状在“确定病例”“疑似病例”“否定病例”分组中的区分度较好,因此将ADR名称、生化指标、临床症状确定为肝损伤相关ADR智能识别关键要素(图1~3)。
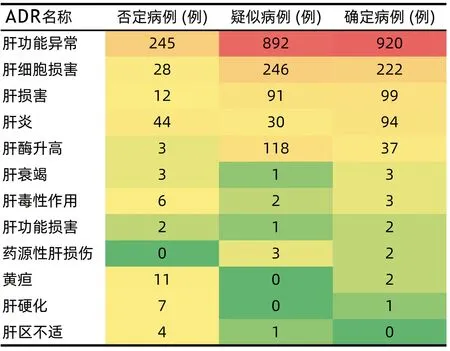
图1 “确定病例”“疑似病例”“否定病例”的ADR名称热图分析
2.3 关键指标的确定及打分标准 通过2倍中位数确定关键指标并评分,即ADR名称、临床症状、生化指标中大于2倍中位数的数据,K=K疑似+K确定,3项数据具备2项指标的病例计3分,只有1项指标计2分,无指标计1分,即K疑似∩K确定=3分、K-K疑似∩K确定=2分、其他=1分。
通过打分,临床症状中,纳差、发热、皮肤瘙痒等为3分;肝掌、肝区不适为2分;上腹部胀痛、尿黄、柏油样便等为1分。生化指标中,AST、ALT、GGT等为3分;AKP、PTs为2分;ChE、PTA、Alb等为1分。ADR名称中,肝功能异常、肝细胞损害为3分;肝酶升高、转氨酶升高为2分;肝损害、肝损伤、肝炎等为1分。
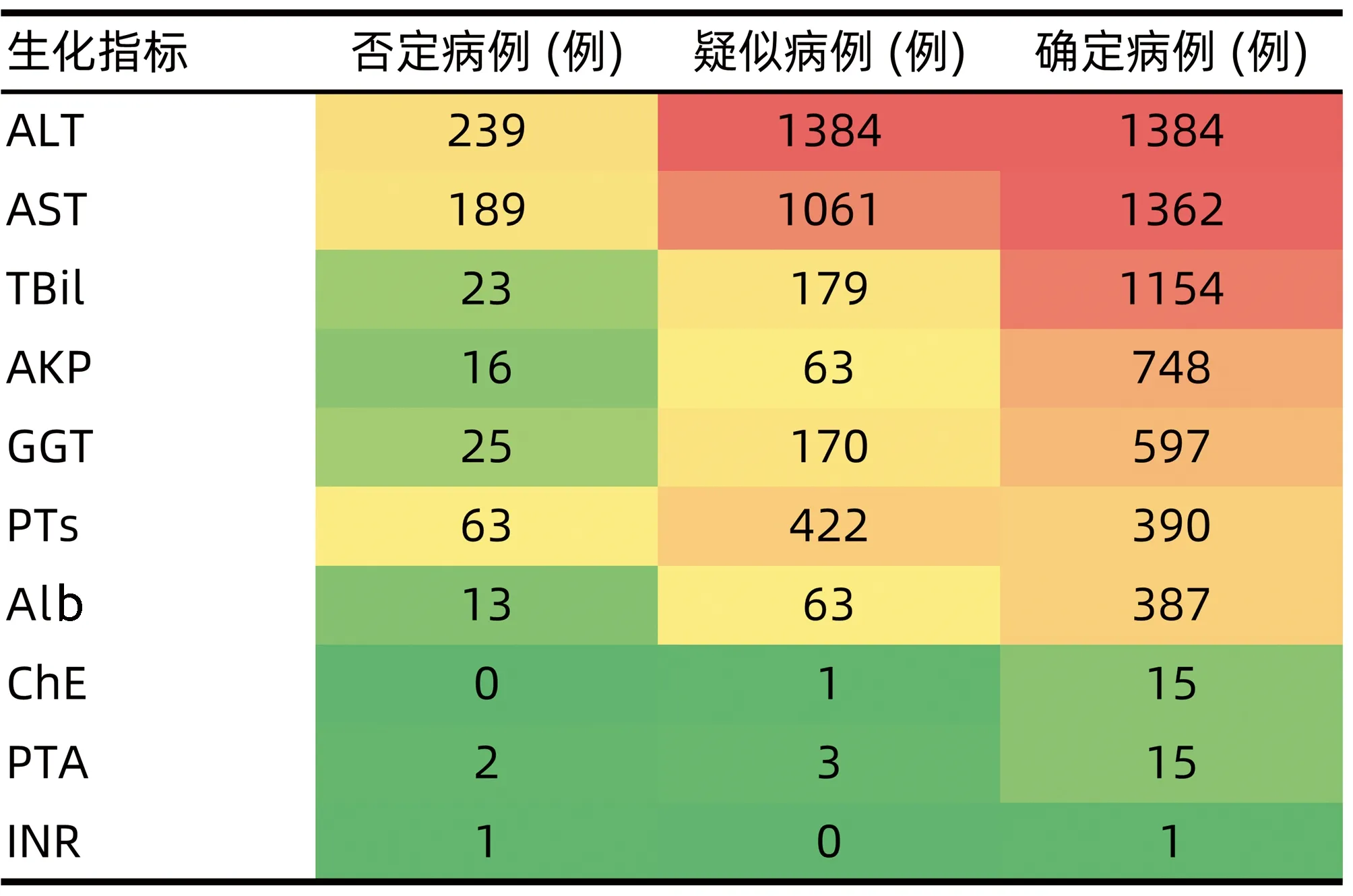
图2 “确定病例”“疑似病例”“否定病例”的生化指标热图分析
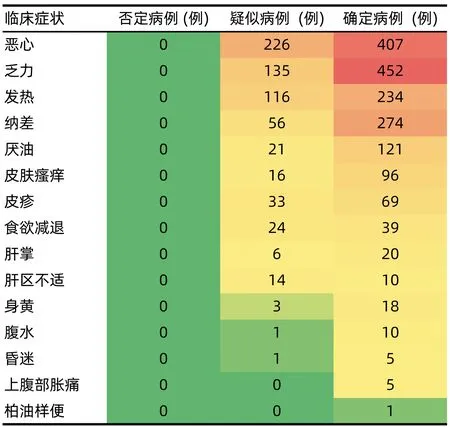
图3 “确定病例”“疑似病例”“否定病例”的临床症状热图分析
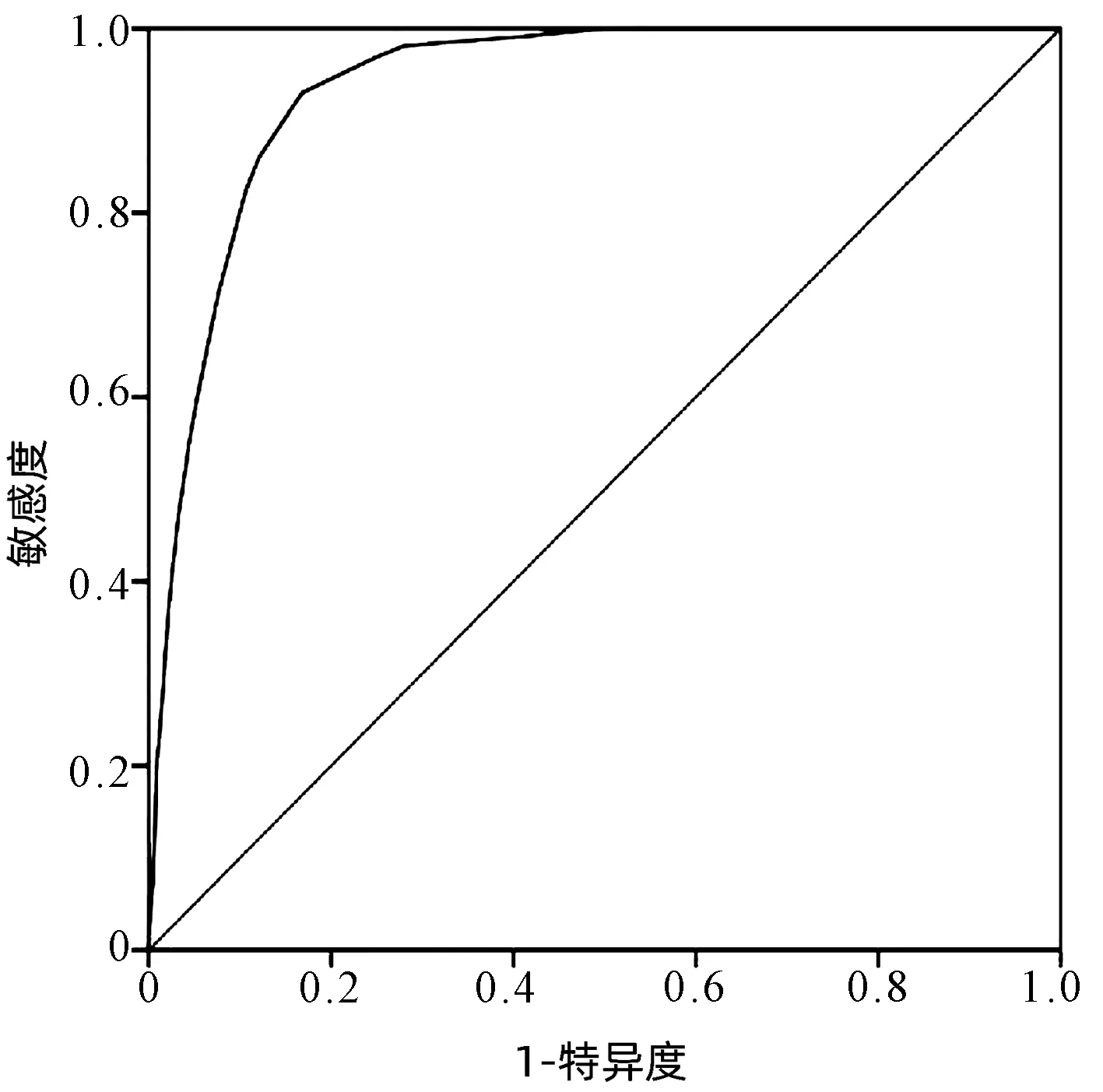
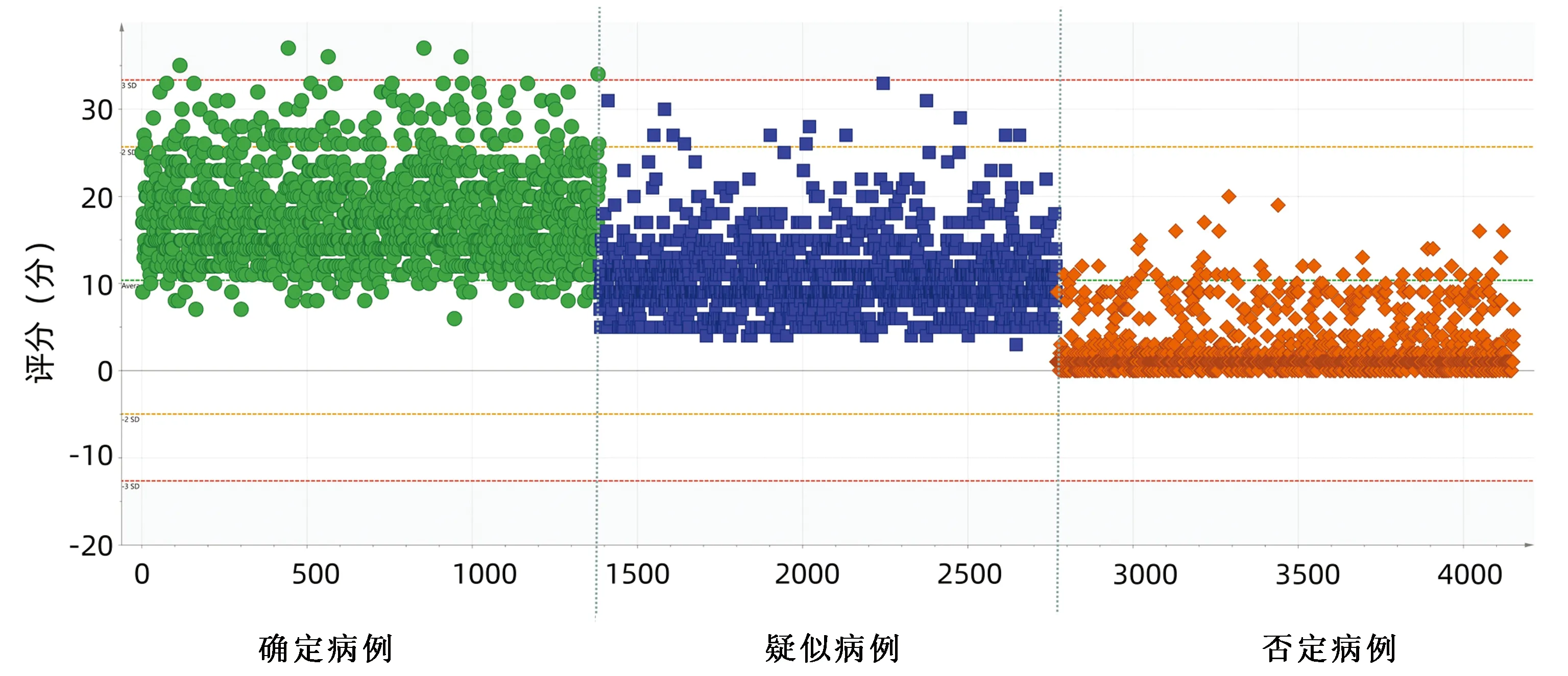
依据上述关键指标打分标准,确定肝损伤相关ADR评价识别公式为:总分(M)=症状分数+指标分数+不良反应名称分数。M≤5分:否定肝损伤,5分 2.4 评分阈值的确定 通过ROC曲线对肝损伤相关ADR的评价打分进行阈值分析,发现“否定病例”与“疑似病例”“确定病例”在M=5分区分度最好(AUC=0.97),敏感度为99.57%,特异度为84.61%,“确定病例”与“疑似病例”“否定病例”在M=12分区分度最好(AUC=0.938),敏感度为87.93%,特异度为85.98%(图4、5)。 图4 “否定病例”与“疑似病例”“确定病例”肝损伤相关ADR诊断的ROC曲线 2.5 智能识别规则评分的分布及交叉验证结果 采用内部交叉验证的方法对智能识别规则评分效能进行评价,结果显示:“疑似病例”-“否定病例”的交叉验证结果为(R2X,R2Y,Q2)=(1,0.239,0.239),“确定病例”-“疑似病例”的交叉验证结果为(R2X,R2Y,Q2)=(1,0.054,0.054),“确定病例”-“否定病例”的交叉验证结果为(R2X,R2Y,Q2)=(1,0.334,0.334)。通过3组病例智能识别规则评分分布 (图6),“确定病例”与“否定病例”,“疑似病例”与“否定病例”的区分较好,“肯定病例”“疑似病例”与三者的区分性较差。 图5 “确定病例”与“否定病例”“疑似病例”肝损伤相关ADR诊断的ROC曲线 图6 基于智能识别规则的“肯定病例”“疑似病例”“否定病例”的评分分布 本研究通过对肝损伤相关ADR大数据的规范化处理、相关性分析、关键指标的确定及打分标准、评分阈值的确定,建立了一种基于文本知识库的肝损伤相关ADR大数据智能识别新方法。交叉验证结果显示“疑似病例”-“否定病例”,“确定病例”-“否定病例”的区分效果较好,“确定病例”-“疑似病例”的区分效果较差。表明该方法识对于肝损伤相关ADR的“是”与“否”区别度较好,结果稳定可靠,具有实际运用的价值,可应用于肝损伤相关ADR大数据风险信号筛选与识别研究。 本研究以“文本数据的收集→文本数据的清洗与归一化处理→指标的相关性分析→关键指标的确定→关键指标的打分标准→评分阈值的确定→评分方法的交叉验证”为基本研究思路,是基于ADR大数据探索建立的肝损伤相关ADR识别新方法。从未经规范化处理的大量ADR数据中高效筛选出肝损伤相关ADR数据,为肝损伤相关ADR风险信号挖掘及相关药物安全性评价提供了可靠的数据源。该方法的建立不仅很大程度上节省了识别评价大样本ADR初筛的人力和时间,而且可以提高大样本识别的准确度。 目前药物警戒领域对于ADR大数据的处理仍处于探索阶段,相关研究较少,还没有形成一个相对完整的规范化流程。比如,有相关研究运用聚类分析、神经网络等方法对ADR大数据进行了智能识别评价,为ADR大数据的高效识别和精准分析提供了可参考方案[10-13]。然而其仍存在缺乏与人工临床再评价结合、数据规范化处理等问题,有一定局限性。而本研究在数据规范化处理的基础上,以人工临床再评价与智能识别相结合,尝试构建了一个ADR大数据智能识别的方法以及可参考的规范化流程。 本研究也存在局限性,由于ADR部分数据缺失,在使用该方法智能识别的过程中可能存在偏倚,有待增加大样本外部验证,进而完善该方法。同时,创建结构化、规范化医疗大数据平台,实现数据整合与共享将为ADR风险防控与药物警戒带来更有力的契机。基于目前医疗大数据存在的问题,研究团队前期已经创建了多源数据融合与共享共创于一体的药源性肝损伤主动监测与评价大数据平台[14],以期为实现全民共享共治的药物安全性评价与风险防控提供有力的数据平台和研究模式。结合本研究尝试建立的医疗大数据智能识别方法,从而为医疗大数据的进一步评价及处理提供便利,以期将医疗大数据的挑战转化为机遇,从而为医疗卫生的大健康做出更大的贡献。 利益冲突声明:本研究不存在研究者、伦理委员会成员、受试者监护人以及与公开研究成果有关的利益冲突,特此声明。 作者贡献声明:葛斐林负责分析数据,撰写文章;牛明、赵旭、柏兆方负责整理数据;肖小河负责论文的修改;郭玉明、王伽伯负责拟定论文思路,指导撰写文章并最后定稿。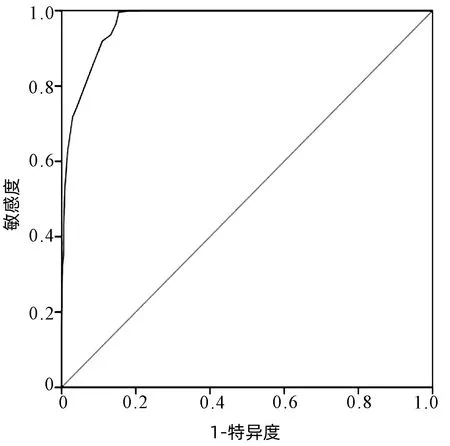
3 讨论
