对抗网络和BERT结合的电商平台评论短文本情感分类
2022-03-18潘梦强黄先开张青川
潘梦强,黎 巎,董 微,黄先开,张青川
(1.北京工商大学 电商与物流学院,北京 100048;2.北京工商大学 国际经管学院,北京 100048)
0 引 言
在互联网飞速发展的大背景下,电商平台迅速成长,直播带货等新兴商品销售手段如雨后春笋般涌现。商品琳琅满目,鱼龙混杂,消费者难以短时间内判断商品质量。以次充好、以假乱真的案例时有发生,平台也面临着监管难的问题。消费者购物时,往往会参考已有的评论来辅助自己决策,同时也会根据自己的使用体验对商品进行评价,大多数购物平台也会建立奖励机制来鼓励购买者对商品进行评价,这就使根据评论来进行商品质量监测成为可能。
情感分析是从用户意见中分析其观点、情感等信息的过程[1],在商品推荐[2-3]、销量预测[4]、舆情治理[5]等方面均有广泛应用。情感分析也是一项领域敏感度高的技术[6],针对一个领域训练好的模型在应用于其他领域时,效果却可能不尽人意。例如,“温度高”在形容热水袋时往往表达的是正向情感,但是在形容手机时,却是负向的。达到较好效果需要针对特定领域进行训练,然而又会面临着优质标签数据不足的情况。在这样的背景下,迁移学习等跨领域的方法应运而生[7-8],但是本质上还是对于特定领域知识的重新训练模型,难以应对类似于舆情监测、商品质量监测等涉及领域广、实时性要求高的场景。因此,跨领域对商品进行普适性评论情感分析显得十分重要。
1 相关研究
在基于机器学习的情感分类上,文献[9]尝试了多种机器学习方法进行情感分类任务。实验发现,朴素贝叶斯(naive bayes, NB)、支持向量机(support vector machines, SVM)等方法能取得较好的效果。文献[10]利用Boosting方法,将SVM集成起来作为新的情感分类器。实验表明,使用集成SVM分类效果会好于单一SVM分类器。文献[11]利用改进的NB进行电商平台评论情感分析,文献[12]通过最大熵方法进行情感分类。虽然传统机器学习方法一直在改进,但是随着数据量的暴涨,新鲜词汇不断涌现,传统方法需要一直保持训练以维持模型性能,因此越来越难以适应当今时代。
在深度学习方面,文献[13]与文献[14]分别提出了Word2Vec模型和Glove模型来对文本中的字词进行表征,解决了传统的独特编码维度灾难问题。但这些方法都是对于字词的静态表示,一个词对应一个词向量,对于一词多义现象并不友好,在中文文本序列中尤其如此。例如,“苹果”既可以表示一种水果,也可以表示一种电子产品。词在不同语境下有不同含义,为了应对这一现象,ELMO模型[15]提供了较好解决方案,与静态表征不同的是,该模型对于同一个词可以根据不同语境训练出不同的词向量。在此基础上,文献[16]基于Transformer提出了表征能力更强的BERT模型。在得到词的向量化表示之后,学者往往在通过神经网络来进一步提取文本序列的特征,然后输入到情感分类器中进行分类。文献[17]通过改变池化策略来提升卷积神经网络(convolutional neural networks,CNN)的特征提取能力,文献[18]将注意力机制加入CNN中,提升了情感分类性能。但是这些方法往往只适用于固定领域,当应用于新领域时,需要重新训练,而新领域的优质人工标注数据较少,难以支撑海量模型参数,所以往往效果不佳。文献[19]提出域对抗(domain adversarial neural network, DANN)方法,并且在图文跨领域分类任务上取得了较好结果。虽然域对抗方法解决了新领域人工标注数据不足的情况,但是每当一个新领域出现时都得重新训练模型,在如今商品类型极其丰富的情况下,此方法亦难以应对。
基于此,本文提出一种基于对抗网络和BERT的情感分类模型,从领域相关特征与无关特征两个角度对文本特征进行提取,将提取的两种特征进行融合之后,传入情感分类器进行情感分类。在模型训练时,利用对抗网络对领域无关特征加以约束,情感分类器可以据此达到较好的分类效果,而领域鉴别器难以判别来自哪个领域。针对传统最大池化卷积神经网络在提取文本序列特征时效果较差的情况,提出平面金字塔池化(panel pyramid pooling, PPP)改进策略,同时以自注意力机制增强卷积神经网络对文本序列特征的提取能力。模型特点在于:训练模型时,使用情感和领域双标签数据;模型训练完成后,则与其他传统情感分类模型一样,只需输入文本序列,无需输入所属领域等额外信息。
2 模型设计
本文提出基于对抗网络与BERT的电商平台短文本情感分析模型,见图1。模型分为输入层、信息提取层、分类输出层,包括BERT模型、CNN-PPP网络、自注意力机制、BiLSTM网络等。模型训练时,样本不仅包含情感标签,还包含领域标签,以领域标签作为信息增强的手段。模型训练分为5步:①将经过分词等预处理操作后的文本输入到BERT模型中,形成词向量作为初始词表征并且作为后续特征提取层的输入;②将BERT生成的词向量传入到BiLSTM模型中提取文本序列的上下文特征信息;③与②类似,将BERT模型的输出(即BERT生成的词向量)作为CNN-PPP的输入,传入到CNN-PPP模型中,进行局部语义的特征提取,并且将CNN-PPP模型的输出加以自注意力机制,提取更深层次的语言信息;④将③的输出(即经过自注意力机制后的输出)经过一层梯度反转层(gradient reversal layer, GRL)之后作为输入传入由全连接网络组成的领域鉴别器中,判别来自哪个领域,并且力图使领域鉴别器无法鉴别文本序列属于哪个领域;⑤将②与③的输出进行特征融合(即进行拼接),然后传入情感分类器中进行情感分类,力图使情感分类器能准确分类文本序列的情感倾向。
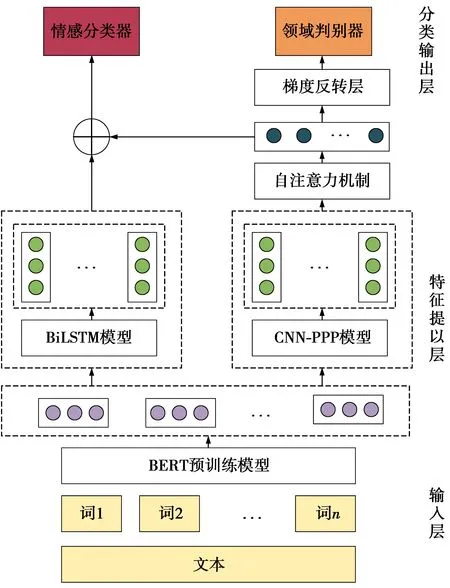
图1 基于对抗网络和BERT的情感分类模型Fig.1 Sentiment classification model based on adversarial network and BERT
2.1 BERT
BERT模型结构如图2所示。图2中,Trm表示Transformer单元,BERT模型由多个Transformer层组成,通过“masked language model”和“next sentence prediction”两个无监督子任务来训练。在特征嵌入方面,相较于Word2Vec、Glove等模型,BERT有着更强的词表征能力。
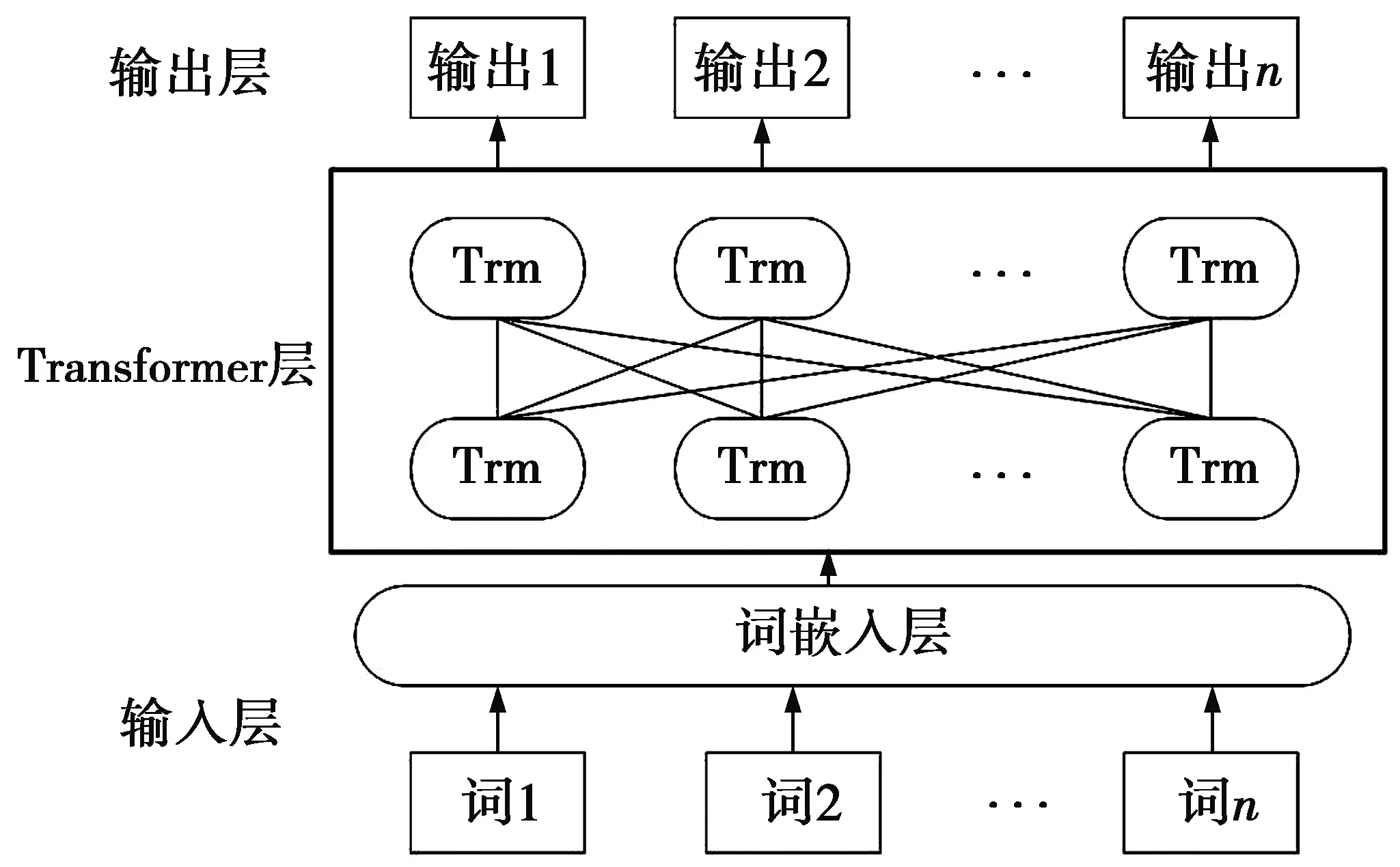
图2 BERT模型结构Fig.2 Structure of BERT model
2.2 BiLSTM
LSTM是对传统循环神经网络(recurrent neural network, RNN)的改进,在一定程度上克服了RNN的梯度弥散与长期依赖问题。LSTM的信息传播方式为
it=σ(Wi·[ht-1,Xt])+bi
(1)
ft=σ(Wf·[ht-1,Xt])+bf
(2)
ot=σ(Wo·[ht-1,Xt])+bo
(3)
(4)
(5)
ht=ot·tanh(Ct)
(6)
(1)—(3)式中:it、ft、ot分别表示输入门、遗忘门、输出门;σ为激活函数;W和b分别表示权重矩阵及偏置项;ht-1表示t-1时刻的输出;Xt表示t时刻的输入。
LSTM相比RNN已有较大改进,但是单向传播特性使其在进行文本情感分类任务,尤其是文本序列较长时,会出现序列后面词比前面词重要的问题。在情感分类时,实际突出情感的词可能出现在文本任何位置,而非一定在文本最后。BiLSTM由前向LSTM以及后向LSTM组成,信息在两个隐层之间双向流动,可以在提取上下文信息的同时提取到更多语言信息。图3为BiLSTM模型的结构图。
2.3 CNN-PPP
在图像目标检测等视觉领域,采用空间金字塔池化(spatial syramid pooling,SPP)的CNN大放异彩,特殊池化结构使其能提取到图像的更多信息。而文本情感分类任务不同于文本分类任务,它有着更为复杂的情感表达方式,同时对商品可能有多个角度的评价,且各方面的情感倾向略有差异,直接使用全局最大池化可能会陷入一叶障目的困境。与传统CNN采用全局最大池化不同,CNN-PPP采用的是平面金字塔池化。

图3 BiLSTM模型结构Fig.3 Structure of BiLSTM
卷积层:使用若干个大小固定的滤波器对上一层的输出矩阵进行卷积操作。在文本序列中,卷积核会沿着序列方向进行滑动,第i个卷积核对特征矩阵进行卷积之后,得到新的特征ci,j为
ci,j=f(wi·xj:j+h-1+b)
(7)
(7)式中:f为非线性的变化函数,通常为RELU;b为偏置项;h是卷积核口窗口的大小。第i个卷积核沿序列滑动之后得到新特征序列ci。
ci={ci,1,ci,2,…,ci,n-h+1}
(8)
池化层:进行卷积操作之后,可以进一步提取原始特征。为了充分提取信息,通常会使用多个卷积核进行卷积操作,这样就会得到大量特征向量。如果直接传入分类层进行分类任务,会使模型因参数过大而难以训练,且易出现过拟合现象,所以往往会在卷积层之后加上池化层来减少参数。常见的CNN模型结构如图4所示。经过全局最大池化操作后所得特征di可表示为
di=max(ci,1,ci,2,…,ci,n-h+1)
(9)
全局最大池化可以在降维的同时筛选出与任务关联度最高的特征,常应用于图像领域。由于文本的特殊性,使用全局最大池化难以捕捉句子的语法结构,且句子可能对商品进行多方面的描述,只选取一个特征难免会以偏概全。RNN虽然可以学习文本上下文信息,但是也难以捕捉句子结构特征。受SPP的启发,本文提出一种适用于一维卷积的PPP池化方式,其结构见图5。在某个卷积得到新特征序列ci之后,将其分为k段,分别对其中的每一段进行全局最大池化操作,得到k个特征记为di;k。将k取不同的值,如k1,k2,k3,由此可以得到(k1+k2+k3)个特征,再将三者进行拼接作为PPP池化的输出,以此来捕获文本序列的句子结构特征。第i个卷积核在通过PPP池化之后有
ci={ci;1,ci;2,…,ci;k}
(10)
di;k={max(ci;1),max(ci;2),…,max(ci;k)}
(11)
di={di;k1,di;k2,di;k3}
(12)
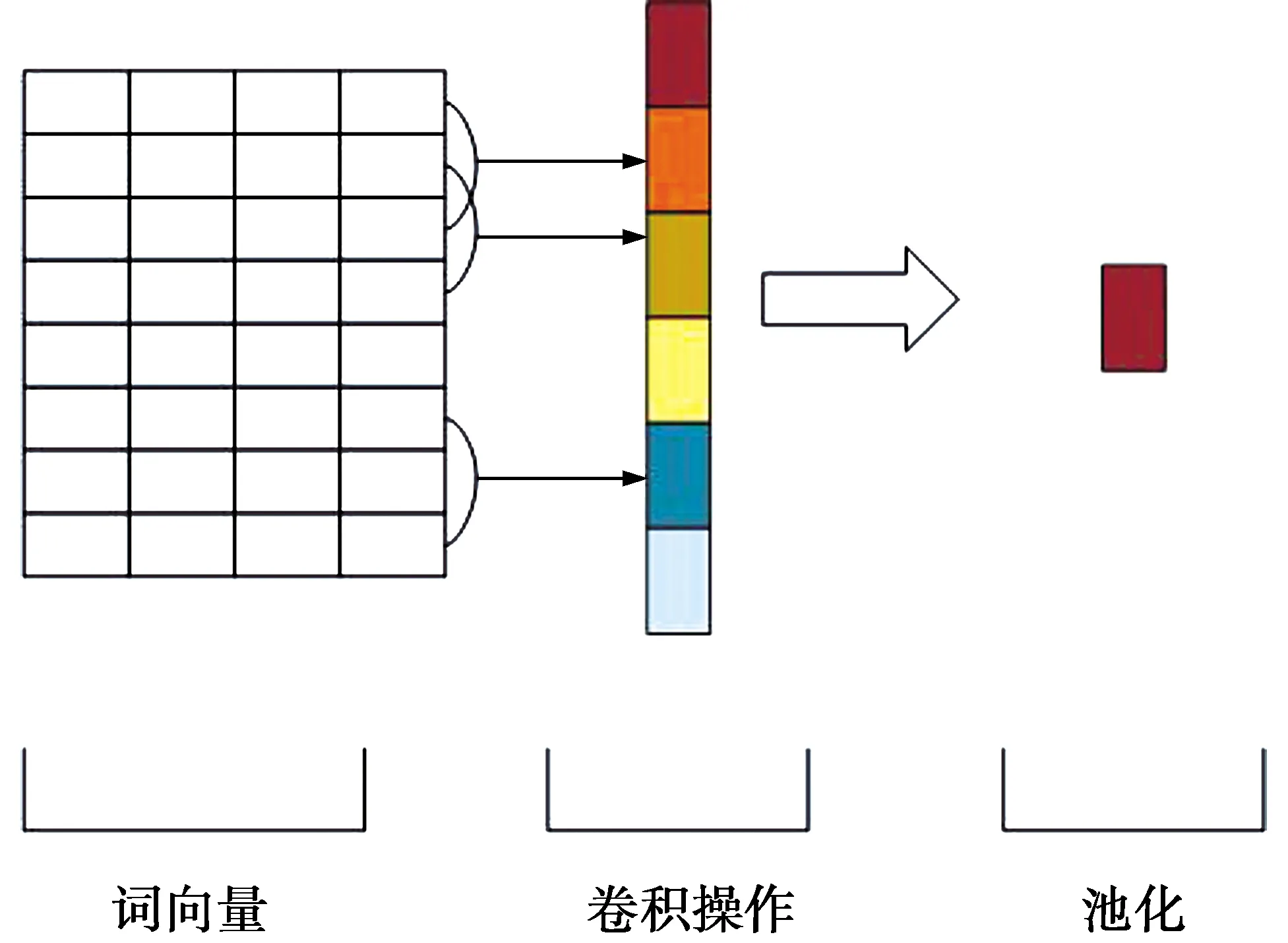
图4 CNN模型结构Fig.4 Structure of CNN
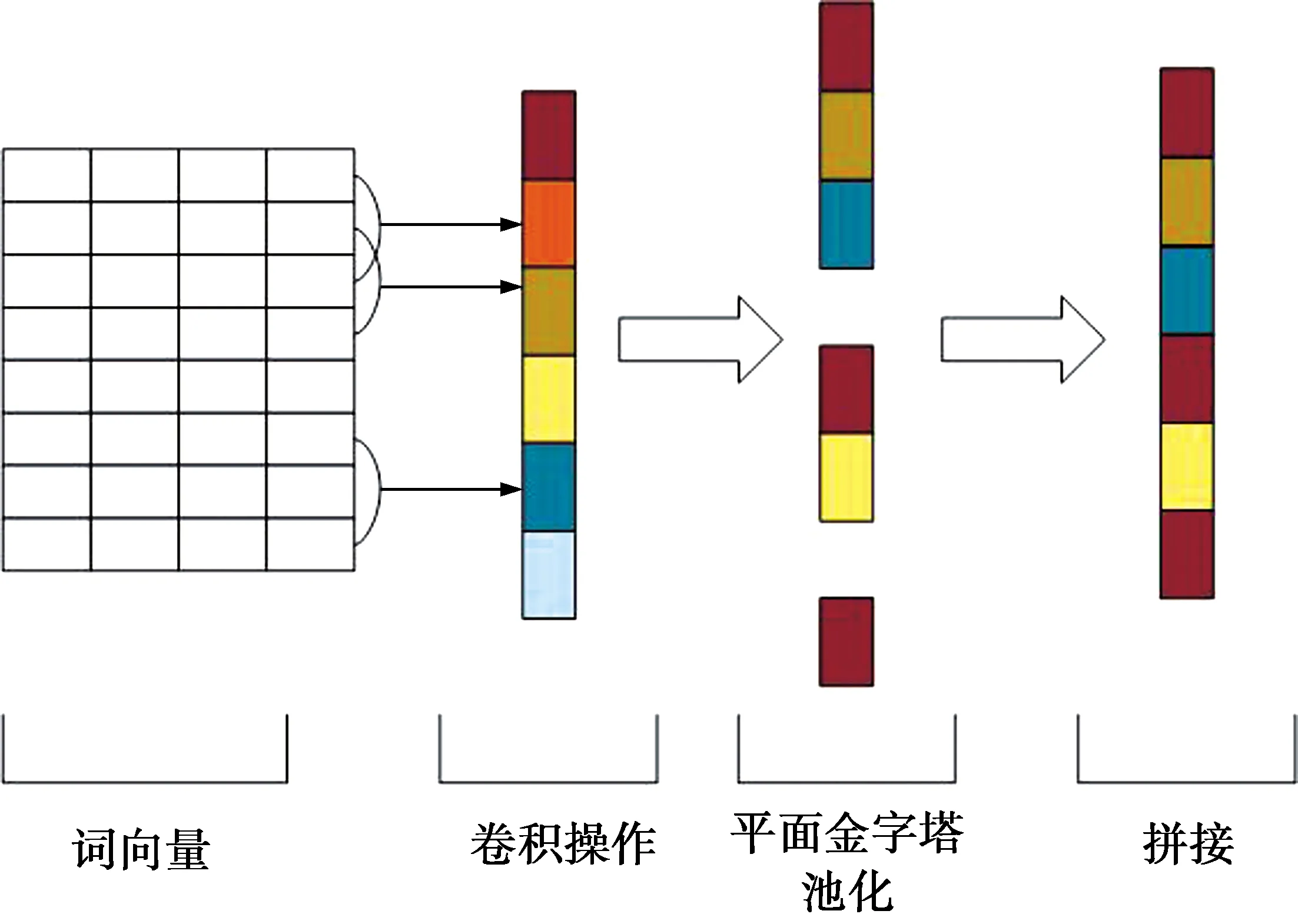
图5 CNN-PPP模型结构Fig.5 Structure of CNN-PPP
2.4 梯度反转层
加入对抗网络的目的是混淆领域特征,使领域鉴别器无法鉴别上一步提取到的特征来自哪个领域,即使得CNN-PPP网络提取的序列特征与其领域无关。假设CNN-PPP经过自注意力机制层之后得到特征Vc,然后传入领域鉴别器中,Vc在前向传播经过梯度反转层时保持不变,在反向传播时,将梯度变为原来的-λ倍。前向与反向传播的公式为
Rl(X)=X
(13)
(14)
(13)—(14)式中,Rl为梯度反转层的函数,参数λ可动态变化。特征Vc最终将传入到领域鉴别器中进行分类。
(15)
本文以交叉熵损失函数作为领域鉴别器的损失函数,记为Ldom,以二分类为例,表达式为
(16)
(16)式中:yd为实际标签;x为单独样本;n为样本量。
情感分类器的损失函数和领域鉴别器的损失函数相同,也为交叉熵损失函数,记为Lsen,与情感分类器目的不同,领域鉴别器的目的是约束提取的特征与领域关联度低,即难以通过提取的特征来判断所属领域,这一点主要由梯度反转层保证,而情感分类器的目的是根据提取的特征准确判断情感极性。本模型实际有两个输出,但在最终训练完成后只关注情感分类器的输出。在训练整个模型时,将两个损失以一定权重进行加和,最终本文模型的损失函数为
Ltotal=Lsen+βLdom
(17)
(17)式中,β作为模型的超参数,用于调节两个损失函数的比重,实现Ltotal的最小化。
3 实验与结果分析
3.1 实验数据
本文采用的实验数据为公开数据集online_shopping_10_cats。数据集中包含书籍、水果、计算机等十个种类总计近6万条的电商评论数据。情感标签分为两类,标签1为积极情感,标签0为消极情感。为了验证模型性能,从原始数据集中抽取情感标签为1的水果、衣服数据各五千条,情感标签为0的水果、衣服各五千条,共计2万条数据作为数据集一,数据集一代表领域差别较大的样本。类似地,将商品类型为平板、计算机的数据各1 996条,共计7 984条评论作为数据集二,数据集二代表领域差别较小的样本。水果、衣服属于体验型商品,平板、计算机则属于搜索型商品,这样设计数据不仅可以在子数据集内做对比,也方便在子数据集间做对比。
3.2 实验环境
本文所用编程语言为python,深度学习框架为tensorflow,CPU为Intel Xeon Silver 4210,GPU为NVIDIA GeForce RTX 2080ti,内存为64G。
3.3 实验参数设置
本文设置文本序列最大长度为100,即一条评论文本最多包含100个字,超过100个字则进行截断,少于100字的在向量化之后用零向量进行填充。数据集一与数据集二分词后所包含词的个数分布见表1,可以看到,在100时进行截断可以保留绝大部分的评论数据。LSTM中隐藏层单元数为128,卷积层激活函数为RELU,PPP分段数为1段、3段、6段。2个分类器均由2层全连接层组成,第1层神经元个数为128,第2层神经元个数视分类类别数而定,在本文中为2。优化器为Adam,学习率为0.001,batch_size为128。为了在一定程度上抑制过拟合问题,分别在分类器前加入值为0.5的dropout机制。最大训练轮数为60,并随机选取80%的实验数据作为训练集,20%的数据作为测试集。

表1 字个数的分布Tab.1 distribution of word number /个
3.4 对比实验与评估指标
基线模型如下。
①SVM[20]:支持向量机模型。
②CNN[21]:以全局最大池化为池化方式的卷积神经网络,后面连接与本文模型相同的全连接层分类器。
③CNN-PPP:池化方式为本文提出的平面金字塔池化,其他与CNN相同。
④BiGRU[22]:双向门控循环单元,后接的情感分类器与CNN相同。
⑤BiLSTM[23]:双向长短期记忆神经网络,后接的情感分类器与CNN相同。
⑥本文模型无对抗:为了验证本文对抗网络的有效性,在此模型中移除本文模型的梯度反转层与领域鉴别器,其他参数同本文模型。
本文采用准确率(Accuracy)、F1值、召回率(Recall)作为评价指标,具体公式如下。
(18)
(19)
(20)
(21)
3.5 结果分析
采用数据集一进行仿真得表2。由表2可以看出:在领域差别较大的混合数据中,使用PPP池化的CNN,相较于使用全局最大池化的CNN,在Accuracy、Recall和F1值上面均有一定优势;与BiGRU模型相比,在这3个指标上相近。说明采用平面金字塔池化的方式能在一定程度上捕获句子的语法结构特征。在所有模型中,本文模型在3个指标上都最优,准确率达到了95.25%,比CNN、BiGRU、BiLSTM模型分别提高了2.48%、1.42%、1.35%;相较于不使用对抗网络的本文模型,准确率提高了0.9%。采用数据集二进行仿真得表3。从表3可以看出,在领域差别较小的数据中,本文提出的模型在3个指标数上依旧高于其他模型,准确率达到了93.61%,比CNN、BiGRU、BiLSTM分别提高了1.75%、1.5%、0.94%;与剔除对抗部分的模型相比,准确率提升了0.4%。说明即使在领域较为相近的数据中,使用对抗网络的本文模型依旧能保持较好的准确率。在Recall方面,使用对抗网络的模型要高于无对抗网络的模型,这一点在领域差别较大的数据集一上更为明显,比无对抗的模型提高了2.1%。
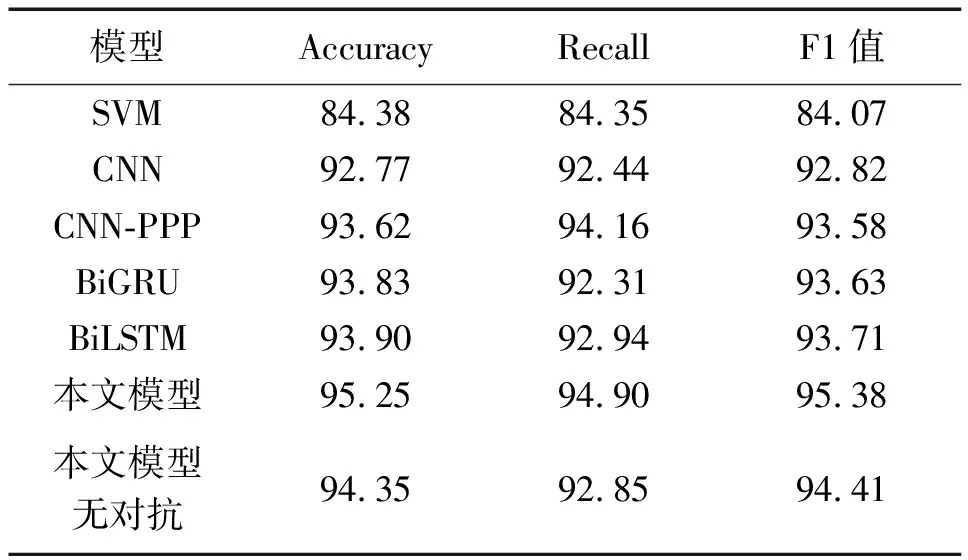
表2 数据集一实验结果Tab.2 experimental result of data set 1 %
综合而言,本文提出的模型在多领域情感分类任务中有较好的性能,且在领域差别较大的数据集中表现要好于领域差别小的数据集,说明加入对抗网络,可以提升在多领域情况下的情感分类性能。同时,本文提出的CNN-PPP模型在两个数据集上的表现均好于普通CNN,且接近于复杂度更高的BiGRU模型。

表3 数据集二实验结果Tab.3 experimental result of data set 2 %
通过代表体验型商品的数据集一和代表搜索型商品的数据集二上实验数据的纵向对比,可以发现:即使领域跨度较大,体验型商品上各模型的总体准确率依旧要高于搜索型商品,这可能是由于产品属性的不同导致了在线评论特征的差异化。
3.6 模型参数分析
由上面的结果看出,本文模型在不同领域跨度的数据集上表现有所差异,总损失函数由情感分类器损失函数与领域鉴别器损失函数组成,二者各自占有一定比重,在模型中以超参数β来调节。图6和图7分别展现了不同β取值下情感分类器与领域鉴别器的准确率。从图6可以看出,在数据集一上,当β取值为0.01时,情感分类器的准确率最高,此时的情感分类器准确率高于95%;领域鉴别器准确率低于60%,基本无法鉴别特征来自哪个领域。此时CNN-PPP模型提取到的特征与领域关联度较低,达到了模型预想的结果。从图7可以看出,在β取值为0.01时,情感分类器准确率较高,但是此时领域鉴别器准确率在70%左右,高于数据集一上的60%。这可能是数据集二上平板和计算机两类商品领域很接近所致。而当β取值为0.001时,数据集一和数据集二上领域鉴别器的准确率都较高,情感分类器的准确率则较差,此时对抗网络对于多领域数据的优势难以发挥。
4 结束语
在物流与互联网大发展的今天,传统购物平台与视频平台的边界日益模糊,逐渐发展成你中有我,我中有你的态势。商品类型日益丰富,但是质量却参差不齐,时常出现“金玉其外,败絮其中”的现象,平台也往往缺乏有效的监管。从情感角度分析在线评论文本乃至弹幕文本,辅助进行质量监测,是一项具有实际意义的研究。
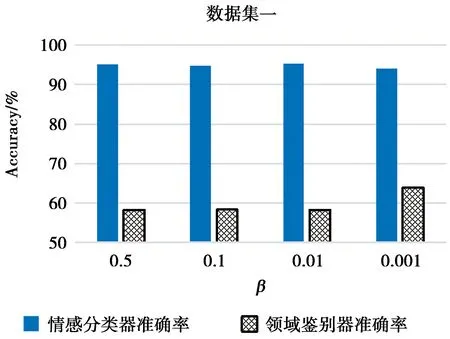
图6 数据集一分类器准确率Fig.6 Classifier accuracy of data set 1
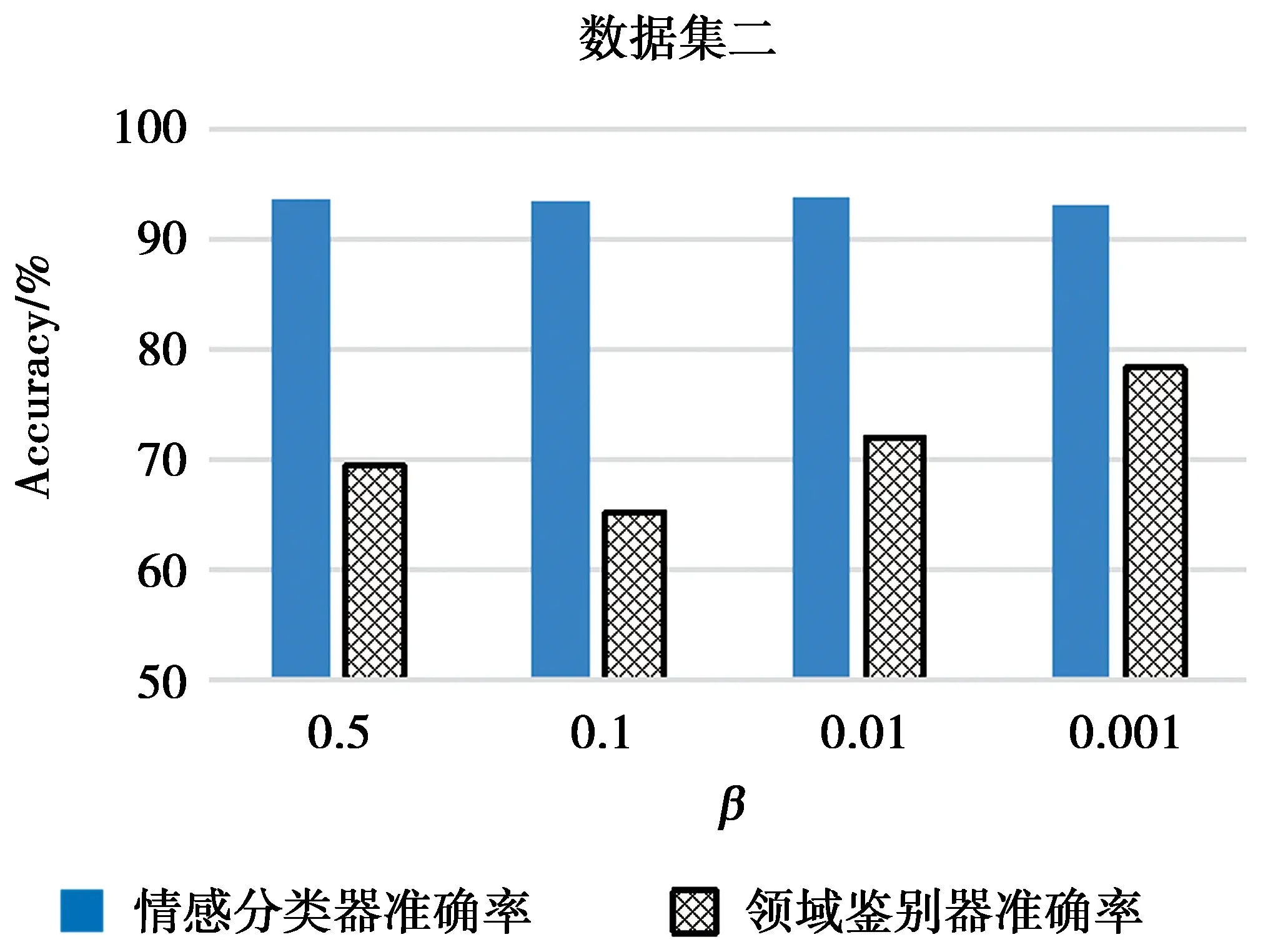
图7 数据集二分类器准确率Fig.7 Classifier accuracy of data set 2
情感分类任务领域性较强,传统情感模型在跨领域或者涉及多领域的情况下效果不佳,而迁移学习的方法本质上仍需根据新的标签数据对模型进行重新训练,难以应对直播电商等要求的实时质量监测任务。本文提出一种适用于多领域的情感分类模型,旨在提升多领域混合情况下文本情感分类准确率,应对诸如电商平台商品质量监测、风险预警等涉及领域广、实时性要求高的情景。首先通过BERT模型获得字词的初始词向量表征;其次,通过对抗网络进行领域无关特征的提取,通过双向LSTM进行上下文特征的提取;最后将两个特征融合进行情感分类,通过加入梯度反转层实现对抗网络的端到端训练。在公开数据集上的实验结果表明,本文模型能提高多领域情况下情感分类准确率。
