基于决策树和主动学习的护理院住院费用监管方法实证研究
2022-03-17许思特张天天刘佳兴
许思特 张天天 盛 韬 刘佳兴 罗 力△
1.复旦大学公共卫生学院(200032) 2.复旦大学计算机科学技术学院 3.复旦大学软件学院
随着我国医保覆盖面的扩大和保障水平的提高,违规骗保、过度诊疗、资源浪费等问题愈演愈烈。与此同时,根据国家进一步促进社会办医持续健康规范发展的要求,医保将面临越来越多的社会办医纳保的局面,更加大了医保基金的风险和监管压力。
近20年来,国内外有大量学者,将数据挖掘、机器学习等应用于医保费用监管、住院费用分析以及骗保行为甄别等。国外如Biafore使用数据挖掘技术从大量的复杂的异构数据中发现一定的数据模式及趋势,并以此提供决策支持[1];Milley将数据挖掘技术应用到医疗费用检测,并给出成功实施的案例[2];William J.Rudman,John S.Eberhardt等学者通过归纳分析了美国健康保险,利用机器学习与数据挖掘的相关技术构建模型对欺诈与骗保行为进行甄别并对其进行分析[3]。国内高臻耀,张敬谊等学者提出了利用数据挖掘与机器学习等技术构建模型库与方法库[4];蓝英、李春吉、王川等学者将机器学习、神经网络应用于多种疾病的住院费用分析中[5]。
现在国内主流的医保控费模式,主要有三种,基于规则集的智能控费模式、PBM第三方控费和DRGs组合控费,三种方式各有优势,但也存在着规则不完备、第三方盈利点不透明、付费服务项目不够精细的问题。根据国办发[2020]20号《国务院办公厅关于推进医疗保障基金监管制度体系改革的指导意见》,结合本研究对医保管理部门的咨询结果,为有利事前、事中的监管引导,应对相关医疗机构的费用加强大数据应用,制定“模糊规则”进行监管[6]。
如今,上海市有超过40家护理院,但对相关住院费用的监管始终缺少有效的手段。根据文献研究进展与实际管理情况,主要存在以下问题。
(1)建模问题
基于前期的调研结果与临床医生们的反馈,专家们表示难以给出明确的监管细则标准,因而传统通过专家咨询形成规则的建模方式在本研究中无法实现。参考相关文献,考虑将人工智能技术引入,对医生们的经验进行归纳建模。但受限于人力成本,在以往的住院费用研究中,大多采用了非监督学习、神经网络等无需人工标记的方法。这样的建模方式虽然效果较好,但可解释性较差,难以对实际管理操作产生有效反馈。
(2)管理问题
受限于管理者的临床专业知识与人力成本,对相关住院费用的监管始终没有成型的金标准,仅仅是采用一刀切的监管方法,即日均床位费不得超过400元。这种传统监管方法不仅不利于事前、事中的引导,同时使部分有违规收费倾向的医生掌握主动权,采取规避处罚的诊疗方向。
针对建模中可解释性差的问题,本研究采用机器学习中可解释性较强的决策树模型,从而有效反馈特征重要程度、机器决策路径关键信息。针对建模与管理中人工标记的成本问题,本研究采用主动学习算法,甄别较难分类的高价值标注数据,进行重点标记,从而通过较少成本提升算法的效果。针对管理中一刀切的方式,本研究将病人基本信息与费用信息悉数囊括,综合考虑有效数据特征,从而更为准确地判别相关住院费用数据的合理性。
综上,为捕捉结合医学、管理学、计算机的契合点,理解医生思维,辅助医保更有效地对护理院住院费用进行监管控制,本研究尝试将人工智能技术引入,以脑梗死后遗症为例,构建护理院住院费用合理性判别模型。
资料与方法
1.资料来源
研究的数据来源是上海市医保中心提供的2016-2018年上海市病案首页数据库,选择以脑梗死后遗症(ICD编码为I69.300)为主疾病的病例资料,收集患者信息字段与费用字段,包括年龄、住院天数、住院次数、有无手术、并发症详情等;统计患者各单项住院费用字段,包括一般医疗服务费、一般治疗操作费、西药费、护理费等。
2.数据预处理
本研究变量赋值及预处理的基本情况见表1,具体处理过程如下:
(1)剔除年龄、主疾病等关键患者信息字段有缺失的数据;
(2)剔除费用字段缺失超过1/3的数据,用中位数填补费用字段缺失不超过1/3的数据;
(3)患者住院费用属于偏态分布,对数据进行Box-Cox变换,使其近似正态分布。继而对数据进行归一化,使其收敛于[0,1]之间;
(4)运用独热编码与哑变量处理分类型的信息特征字段,如性别、医疗付费方式等。其中,由于“新农合”、“城镇职工”、“其他”三种付费方式,在病案首页数据库中均记录为“医保”,因而未做进一步分类;
(5)运用二值化与分段处理连续型的信息特征字段,如年龄等。

表1 变量赋值及预处理
3.建模方法
(1)抽样与标记
从全市邀请了204位,从医5年以上的护理院临床医生,参与大型的线上专家咨询。对抽样的18697条病案数据进行第一轮合理性的判断,并利用费用字段构建初步模型。所有相关资质医生基于自身经验,在阅读完整病案信息的情况下进行费用量和费用构成的合理性判断。一条数据,若被医生判断为‘费用量合理’且‘费用构成合理’,则认为该条数据合理;若被医生判断为‘费用量不合理’或‘费用构成不合理’,则认为该条数据不合理。每条数据会由三位专家进行判断,判别一致的数据用于建模,以保证标签与模型的准确性。
由于受相关资质医生的数量限制,本文以系统抽样为基础,借鉴梯度下降法的思想,进行抽样标记。按主疾病分别抽取样本记录,以均值为中心点。由欧氏距离最远处开始以学习率α(即步长)逼近中心点,并给医生判断是否合理。每条数据由多位专家判断。学习率α视判断一致率情况进行调整,离中心点较近或较远处,α较大。
共抽样18697条数据,有效回收15488条,回收率82.8%。其中,经数据预处理,脑梗死后遗症疾病相关数据共2352条。
(2)决策树模型的建立
采用C 4.5决策树算法进行建模,该算法采用节点二分法,追求信息增益最大化。当选择某个特征作为节点时,我们就希望这个特征的信息熵趋近于0(即概率趋近于1),此时不确定性最小。为保证损失函数下降,即父子节点信息熵差为正的情况下,根据准确率与各参数的可视化,确定调参方向。
本文设置70%样本量为训练集,30%样本量为测试集,特征选择标准criterion选择信息熵entropy,特征划分点选择标准splitter选择random,最大深度max_depth选择3层,max_features选择None,随机种子数random_state选择420,内部节点再划分所需最小样本数min_samples_split和叶子节点最少样本数min_samples_leaf选择5,类别权重class_weight选择balanced,节点划分最小不纯度min_impurity_split选择0.3。
(3)主动学习反馈
主动学习是指通过一定的算法找到未进行类别标注的样本数据中最有标记价值的数据,交由专家进行人工标注后,将标注数据及其类别标签,纳入到训练集中迭代优化分类模型,改进模型的处理效果。主动学习的模型为A=(C,Q,S,L,U)。如图1所示进行迭代循环。

图1 主动学习模型
本研究中,机器学习模型C为经第一轮标记结果构建的决策树模型;查询规则Q为经第一轮标记的数据分别训练5个算法不同的分类器,如果某条样本被5个分类器按2∶3的比例给出了不同的预测,则将这个样本视为有重标价值;专家组S为参与标记的医生群体;标记样本集L为经第一轮标记过的数据集;未标记样本集U为未经第一轮标记过的数据集。
具体而言,我们将原始数据投入第一轮构建的模型中,得出机器的判断,并将机器的判断的结果给医生们进行二轮验证,验证模型的可靠性。第二轮验证过程中,选取经多种分类器判断不一的数据以第一轮的原则进行主动学习的反馈,给医生重新标记投入模型。每条数据会由6位专家进行判断。由于数据正负类别比例较高,采取少数服从多数原则进行验证结果的确定。重标后重新投入模型中形成反馈,对模型进行完善,直至模型在测试集准确率达到80%以上。
(4)统计分析
本研究中,决策树模型采用信息熵entropy作为模型的不纯度,主动学习算法采用边缘采样margin sampling作为查询函数。
其中,信息熵entropy的公式为:
边缘采样margin sampling的公式为:
Scikit-learn、Pytorch库用于实现相关机器学习算法的编写,Numpy库用于维度数组与矩阵运算,Pandas库用于数据分析与处理,Matplotlib库用于图表绘制及可视化。所有统计分析基于均运用Python语言实现。
结 果
1.基本情况
经人工标记与数据预处理,脑梗死后遗症疾病相关2352条病案首页数据中。患者男性1027例,占43.7%;女性1325例,占56.3%。患者平均年龄(82.7±8.6)岁。其中,<40岁组0人;40~59岁组39人,占1.7%;60~79岁组573人,占24.4%;80~99岁组1731人,占73.6%;≥100岁组9人,占0.4%。患者实际住院天数最短1天,最长1151天,平均实际住院天数(148.1±143.0)天。其中,≤9天组167人,占7.1%;10~49天组347人,占9.3%;50~99天组523人,占22.2%;100~199天组859人,占36.6%;200~299天组219人,占9.3%;≥300天组237人;占10.1%。
2.住院费用基本情况
护理院脑梗死后遗症患者住院总费用最低162.5元,最高361936.8元,住院总费用中位数(四分位数间距)为38453.36(50342.96)元。从患者住院费用构成比来看,在人均住院费用中,康复费、治疗费、西药费占比较高。其中,康复费平均11992.4元,占22.3%,治疗费平均7687.4元,占14.3%;西药费平均7273.4元,占13.5%。护理院脑梗死后遗症患者住院日均费用最低54.2元,最高2095.2元,住院日均费用中位数(四分位数间距)为356.9(161.8)元。患者住院费用构成情况见表2。

表2 患者住院费用构成
3.医生判断结果与二轮验证结果
考虑医生人数及工作量,本研究共抽取800条数据进行医生判断一致性检验,每条数据由3位医生判断。共反馈有效数据696条,合理性判断一致率为68.5%。医生对合理性判断的一致性情况见表3。

表3 医生对合理性判断的一致性
由前文的判断原则,若被医生判断为“费用量合理”且“费用构成合理”,则认为该条数据合理;若被医生判断为“费用量不合理”或“费用构成不合理”,则认为该条数据不合理。可得费用量与费用构成综合后的医生判断情况。进行费用合理性综合判断的脑梗死后遗症数据共计2352条。其中,被标记为不合理的609条,总费用最小值240.4元,最大值282703.2元,住院总费用中位数(四分位数间距)为40499.6(53507.8)元;被标记为合理的1743条,总费用最小值162.5元,最大值361936.8元,住院总费用中位数(四分位数间距)为38090.7(49074.1)元。合理性综合判断情况见表4。
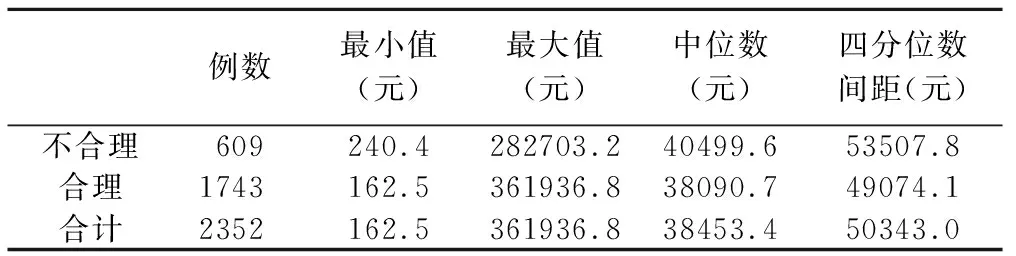
表4 合理性综合判断情况
考虑医生人数及工作量,本研究为验证模型的可推广性,随机抽取500条数据,分别进行人工和机器的二轮判断。邀请5位未参与第一轮标记的临床医生对其进行人工判别,另用主动学习后的机器学习模型进行机器判别,将两者的判别结果进行比对。500条数据中,420条数据判别结果一致,一致率达84.0%。
4.住院费用合理性判别模型构建及影响因素分析
应用决策树对住院费用影响因素重要性进行分析。结果显示:康复费、并发症数量、住院天数等是影响脑梗死后遗症费用数据合理与否的重要因素。其中,特征重要程度(feature_importances_)的数值越高,表明该特征相对模型越重要[7]。本次模型拟合共纳入特征重要程度高于0.03的9个特征。其余特征在加入模型后,模型效能出现下降,准确率降低或假阳性率升高,因此予以剔除。
其中,“入院病情”“有无手术”“血液和血液制品类”字段的特征重要程度均为0。经观察,所有数据的上述三类字段均一致,故而出现特征重要程度为0的情况。模型特征重要程度见表5。
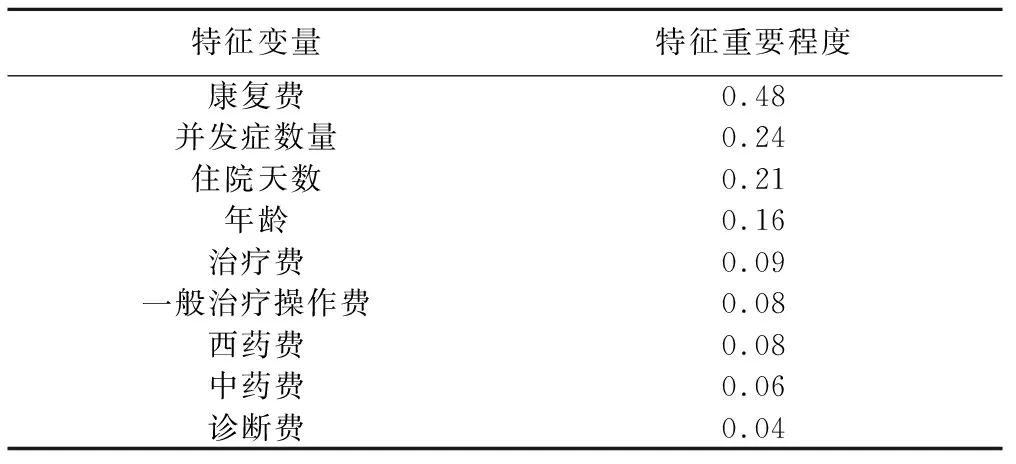
表5 模型特征重要程度
5.模型完善与评价
基于医保需求,本研究确定模型完善方向,着重于模型准确率的增高与假阳性率的降低(本研究以“不合理”为阳性,“合理”为阴性)。分别绘制“数据量-模型准确率、假阳性率趋势图”和“特征量-模型准确率、假阳性率趋势图”,分别见图2、图3。每个数据点建模10次,剔除两端极值取平均,消除随机性造成的误差;同时,在特征量趋势图中,将特征逐一投入,结合医学规律与模型敏感程度不断调整顺序。

图2 数据量-模型准确率、假阳性率趋势图

图3 特征变量-模型准确率、假阳性率趋势图
在现有数据量和特征量的基础上。在不考虑假阳性率的情况下,模型准确率能够达到90%以上;在考虑假阳性率稳定在最低3.2%的情况下,模型准确率能够达到80.9%。其中,医生与医生的判断一致率达84%。可以证明该决策树模型相对合理。同时模型中,节点的信息熵普遍低于0.3,表明信息增益较大,模型不确定性小,也可以证明该决策树模型相对合理。
我们将传统方法与前面的分类方法进行对比,这里我们选取两条主疾病为脑梗死后遗症的数据进行比较。以传统监管标准,即护理院日均费用不得超过400元/天,此时数据1为合理,数据2为不合理。但基于我们的费用合理性判别模型,综合了并发症数量、住院天数等基本信息后,合理性结果完全相反。进一步观察可以发现,研究所得模型明显比传统方法更能说明问题。对于数据1,虽然日均费用未超过400元/天,但诸多单项费用为0,不符合合理情况;而对于数据2,虽然日均费用超过400元/天,但经查病人的并发症数量达到了11种,病情严重,确实有合理的依据。传统一刀切的方法明显无法辨别这类数据的合理性。数据1、数据2的各项费用情况及两种方式判别结果见表6。

表6 数据选取
6.不合理类型脸谱
基于最终的合理性判别模型,本研究尝试对常见的护理院脑梗死后遗症疾病的不合理类型进行脸谱画像。常见不合理脸谱归为以下三类,具体见图4~6。机构名称等敏感信息已遮盖。
讨 论
1.监管建议
针对研究结果反馈的情况,本研究对多家不合理数据较多的护理院进行了实地调研,为医保管理部门提出以下需要关注讨论的问题。
(1)重点费用特征
结合机器学习模型与人工脸谱归纳,医保管理部门应着重对护理院住院费用中的康复费、治疗费、西药费等进行重点监管核查。
(2)病案首页信息质量
在调研过程中,发现多家护理院的病案首页数据存在分列错位等数据质量问题,建议加强对病案首页数据收集的质量控制。
(3)机构端数据接口
在调研过程中,发现多家护理院存在医保数据上传接口不完备的情况,包括单项费用字段细化程度不一、上传费用字段不同等问题。建议统一第三方信息公司对数据上传接口搭建的规范,保证相关数据的可用性、有效性。
2.模型实际应用
为将本研究的成果更好地投入实际应用,向医保决策者提供切实可用的工具,本文基于研究所构建的判别模型,进行了完整的系统设计。具体设计见图7。

图4 不合理类型(1)

图5 不合理类型(2)
总的来说,判别模型对费用数据合理性给出判断,医保对聚类后的不合理数据进行二次判断,医院对二次判断仍不合理数据进行解释,专家对解释进行核查。如若解释可接受,则对数据标签进行更新,并重新投入模型中,从而达到不断完善数据及模型的目的。
3.模型不足及推广
本研究的模型构建方法,虽然能够更准确地甄别费用数据的合理性,但也需要较大的审核人力进行假阳病例的筛查。按现有正负类别比例6∶1,假使每年全市病案数据量为300万,仍需借助系统人工审核7万左右假阳病例。因此模型仍需要不断完善。通过上文模型准确率、假阳性率趋势图,可以明显发现,如果数据量不断增大,有效特征不断增多,模型的效能仍有提升的空间。
理论上,对于分类模型,Vapnik有经典结论,证明了如果想要构建一个强壮的机器学习模型,我们应该同时需要较大的数据量和特征量[8]。Jason Brownlee认为训练机器学习模型需要多少数据要根据很多因素,其中要考虑到类的数量、输入特征的数量以及模型参数的数量。非线性算法往往需要更多数据。一般把复杂的机器学习算法称为非线性算法,它们可以学习输入和输出特征之间复杂的非线性关系,但也需要更多的训练数据。Jason认为,对于简单的线性算法,每个类需要几百个训练样本,对于复杂的非线性算法,每个类需要几千个训练样本[9]。

图6 不合理类型3
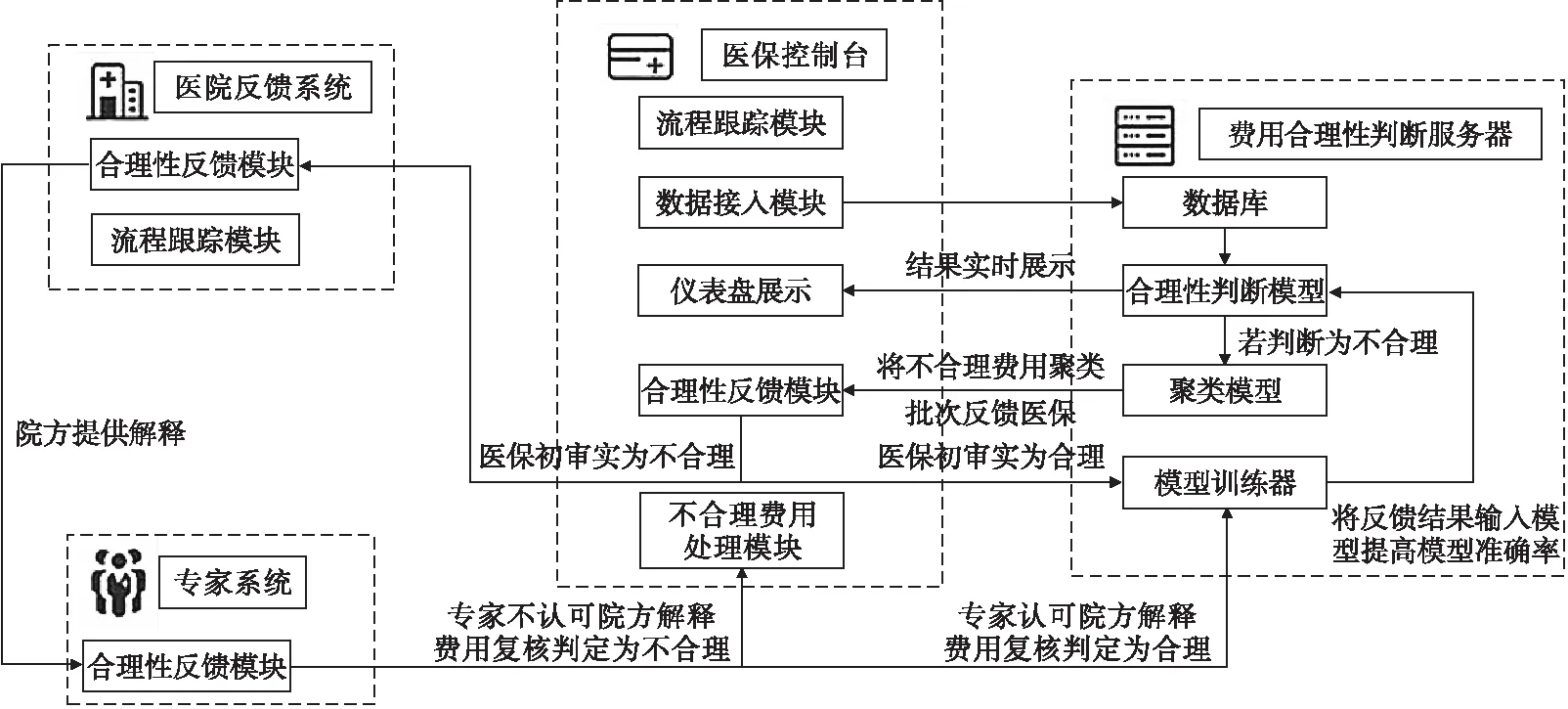
图7 系统设计
因而模型完善方向可归纳如下。
(1)细化病案首页信息特征,适量增加特征数量;
(2)不断收集病案首页数据,增加模型数据量;
(3)通过模型判别-医院解释-医保评判-数据反馈的完整系统,形成良性反馈。
本研究显示,对于护理院脑梗死后遗症疾病,上述方法学可有效监管判别其住院费用合理性。经尝试,该套方法学也可应用于其他疾病的监管,并可进一步推广至其他基层医疗机构或二、三级医院。本研究的方法也为行政部门制定适合脑梗死后遗症等疾病按诊断相关分组预付费方式、降低医疗费用提供参考,有助于提高医保服务质量与管理效率,遏制医保基金的不合理消耗,使得医保、医疗机构、患者各方效益最大化。
