自适应卷积神经网络在情感分析中的应用*
2022-03-16杜波超秦继伟
杜波超,秦继伟
(新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046)
0 引言
情感分析又名意见挖取,其主要挖取的是对象的意见、情感、评价、看法和态度等主观的感受[1]。人们一般通过微博和论坛之类的社交平台发布个人观点想法,进行信息交流和意见表达,如对于相关政策的意见[2]、对相关产品的满意程度[3]和对各种社会事件的看法[4]等。因此,利用挖取的海量数据分析用户情感倾向,获取用户情感趋势已经成为了目前情感计算中的热点问题之一。
有相关学者基于文本细粒度归纳情感分析的方法[5],整理出当前情感词典的构造方法和深度学习的多种模型,并总结了在处理不同语境下不同情感之间情感分类的差异性。刘思琴等人[5]和方英兰等人[6]采用基于转换器的双向编码表征(Bidirectional Encoder Representations from Transformers,BERT)模型来预训练Word2Vec 词向量,并且把这些词向量嵌入其他模型后,取得了准确的分类效果;Kim[7]在加入预训练词向量方法时,采用图像中3 通道的处理方式,用Static 与No-static 这两种词向量搭建嵌入(Embedding)层,此方法能解决一些静态词向量的偏差的问题。在上述分析的基础上,本文考虑到处理数据的复杂性,采用Kim 提出的加入预训练词向量方法,将两层训练后的词向量作为Embedding 层词向量,并在求解训练学习率和模型权重时采用模型优化器进行优化。
本文第1 节对论文相关工作进行简要介绍;第2节给出自适应卷积神经网络(Adaptive Convolutional Neural Network,ACNN)模型推理过程及算法分析;第3 节通过实验,对提出的算法进行性能测试,并对实验结果进行分析;第4 节对本文进行总结。
1 相关工作
在自然语言处理中,文本挖掘任务中最主要的是处理文本的分类或者聚类问题[2,8]。在处理分类和聚类时,主要任务集中在模型算法上的改进[9,10],从而忽略了对词向量的处理以及针对模型优化器的优化。
1.1 词向量
在建立词向量时,有建立随机词向量、加入静态词向量、动态词向量等方式。在分类时建立随机词向量的缺点在于,其训练精度不是很高,词典向量需要维持更新且难以构造符合主题的词典[2,8]。在分类加入静态词向量时,一个单词不管上下文如何变化,只有一个唯一的词向量表示,所以它最大的缺点是无法表达多义性。在分类时加入动态词向量,会根据上下文动态适应性地调整词向量,可以一定程度上解决单词多义性。因此,本文采用混合通道词向量,一个通道采用静态词向量不进行参数更新,另一通道在静态词向量基础上进行参数更新,通过混合两通道构成新的词向量。
1.2 优化器
随机梯度下降(Stochastic Gradient Descent)优化算法正如其名,随机选择一个样本来更新模型参数,收敛过程中和正确梯度相比,存在来回摆动比较大的问题。而自适应矩估计(Adaptive Moment Estimation)优化算法,能独立地适应所有模型参数的学习率并且对内存需求较小,不过随着迭代次数增多,学习率过早和过量的减少,梯度会消失。本文提出的优化算法在自适应梯度算法(Adaptive gradient algorithm,Adagrad)的基础上使学习率自适应减少并设置最小阈值,防止训练期间出现梯度消失,并且对后期梯度累加爆炸问题进行了优化。
2 ACNN 模型
在CNN 的基础上,本文构建ACNN 模型。该网络结构除对Embedding 层采用动静词向量输入外,也在隐藏层采用逐次逼近型优化器。
2.1 Embedding 层采用动静词向量输入
在ACNN 模型的Embedding 层,本文采用双通道词向量,其中,静态词向量利用汉语类比推理勾勒出显式语义关系预训练,动态词向量是对预加入的词向量求导[11,12]。具体是先根据上下文动态适应参数,勾勒出隐式形态关系,然后对处理后的动静向量进行拼接,形成双通道的动静混合词向量。
2.2 隐藏层采用逐次逼近型优化器
对于梯度下降算法,最重要的是模型参数的更新计算[13,14]。更新模型参数时,笔者希望频繁出现的参数步长小一点,这样会使得更新后的模型参数更稳定,不至于出现受单个样本影响较大的情况。对于这个问题,Adam 优化器就能解决,而且它还能解决稀疏梯度和噪声[15]问题,其优化公式为:

式中:dx为对x求的梯度;e为超参数;m为初始第一矩向量;v为第二矩向量;Δ为新一轮的梯度值;η1,η2∈[0,1],为矩估计的指数衰减率。
但笔者通过多次实验,发现Adam 优化器存在学习率提前减少和减少过多的问题,并且初始学习率需要人为调整。因此,本文提出一种自适应学习率的方法,其用到的部分表达式为:
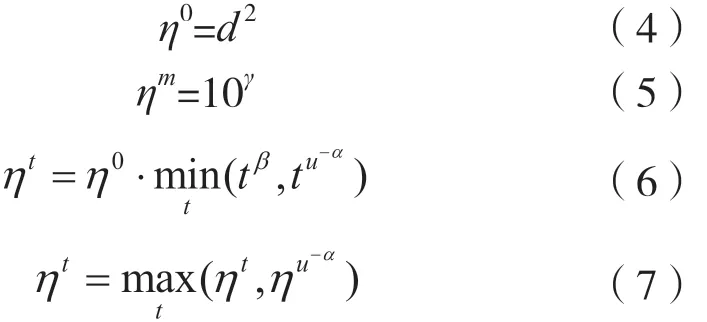
式中:η0为初始学习率;d为模型的一个超参数;u-α为开始学习率;这里设置最小学习率为ηm,是为了防止原地不动。经过t变大后,ηt,t β逐渐小于tu-α。
本文提出的自适应学习率的方法先计算式(4)到式(7),然后代入式(2)中,其中ηt能随着迭代次数的增加逐渐使学习率减少,并且为了防止梯度消失,本文设置了最小学习率的阈值。根据这个思路对原模型进行改进,在改进版的Adam 加入模型后,在数据集上进行实验,实验后得到了非常好的结果,其训练的效果如图1 和图2 所示。

图1 学习率变化
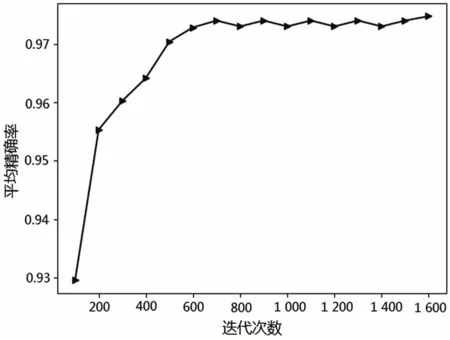
图2 测试精确度变化
上述介绍的自适应更新学习率方法能解决学习步进问题,但实验中发现由于预设学习率最小阈值,在模型训练后期会出现在最小损失点附近来回震荡的问题,这个通过调整学习率是不够的。经过长时间研究后发现可以采用平均权重,接近最小损失点,经过改进后结果得到很大提升,其计算原理为:
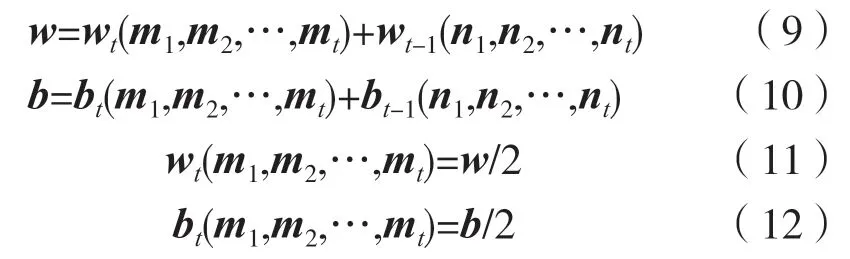
式中:wt为当前权重;wt-1为上次迭代的权重;w为更新后的权重;b为更新后的偏差;bt为当前偏差;bt-1为上次迭代的偏差;nt为当前的输入层与隐藏层之间的参数。
3 模型对比
以数据集的10%作为测试集,对随机初始化CNN、静态CNN、混合通道CNN、本文模型这4 种模型进行训练,测试后的准确度如表1 所示。

表1 不同模型训练后测试的准确度(数据集的10%作为测试集)
通过表1 发现,随机初始化CNN 对比其他CNN 变种表现不好,证明在有限的循环内,随机初始化的词向量不能很好地处理此次分类。接下来,静态CNN 对比随机初始化CNN 发现静态CNN 的效果明显提升,说明加入提前训练好的标准词向量有助于模型训练。混合通道CNN 与静态CNN 对比,混合通道CNN 性能好于静态CNN,这个结果说明,当非静态的时候保持一个通道加入静态向量,并且当模型在训练期间添加随机词向量作为额外维度,其训练结果好于单通道。然而,本文设计的模型ACNN,在相同条件下的训练结果相比其他模型,在精度上有很大的提升,这些结果证明前面提出在模型训练期间加入自适应渐变学习率优化器和均值权重的方法,对处理梯度更新有更高的有效性。
4 结语
本文提出了在双通道CNN 基础上加入自适应渐变学习率和均值权重的ACNN 模型,经过多次实验发现,本文提出的ACNN 模型与其他CNN 变种模型相比,本文模型均优于其他模型,有效提升了CNN 网络预测准确性。
