基于谱减与自适应子带对数能熵积的端点检测
2022-03-16张洪德韩鑫怡
张洪德,韩鑫怡,柳 林,柳 扬
(1.陆军工程大学 通信士官学校, 重庆 400035; 2.合肥讯飞数码科技有限公司, 合肥 230088)
1 引言
随着人工智能技术的发展,语音信号处理技术的应用越来越广泛,语音端点检测作为语音信号处理技术中的关键环节,也是成为研究者们关注的重点。准确的检测,不但可以获得较好的处理效果,更能够极大地减少计算量,提升处理效率。常用的语音端点检测方法主要分为两大类:模式识别类和语音特征类。其中模式识别类主要以深度学习和神经网络为基础,由于需要进行建模和数据训练,通常该类方法计算量大且复杂;语音特征类是基于语音特征参数的一类检测方法,这类方法复杂度低、实时性高,因此在实际应用中多使用特征参数法进行检测。常用的语音特征参数包括短时能量、短时过零率、Mel倒谱距离、能零比和能熵比等,这些参数在高信噪比环境下具有较高的准确率,但随着信噪比降低,检测性能也相应下降,特别是在5 dB甚至0 dB的极低信噪比环境下,常规的检测方法难以准确地进行检测。
针对上述问题,本文提出了一种由改进的多窗谱估计谱减法与自适应子带对数能熵积法相结合的端点检测算法,即首先使用改进的多窗谱估计谱减法对信号进行增强处理,再利用自适应子带对数能熵积这一新的语音特征参数进行端点检测。此算法在低信噪比环境下具有较好的准确率和鲁棒性。
2 改进的多窗谱估计谱减法
谱减法是对纯净语音信号的幅度谱或功率谱进行估计重构的一种增强方法,因此谱估计的准确程度将直接影响谱减效果。多窗谱估计是利用多个正交的数据窗对同一个数据序列分别求谱后进行平均的一种误差更小的谱估计。
多窗谱估计谱减法使用FFT变换,得到信号()的幅度谱|()|和相位谱(),以此计算信号()的相邻帧的平均功率谱密度为:

(1)
式(1)中,和分别表示第帧和第条谱线。
通过平均功率谱密度计算得到谱减增益值,即:
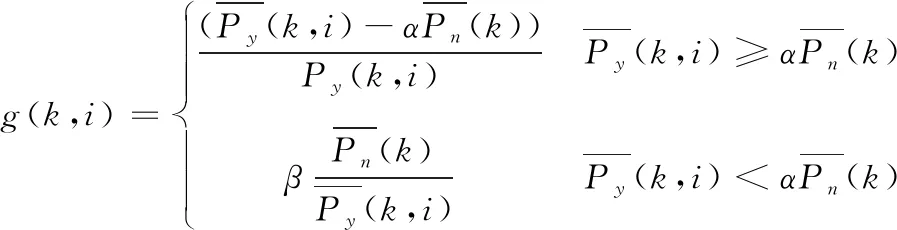
(2)

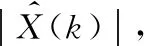
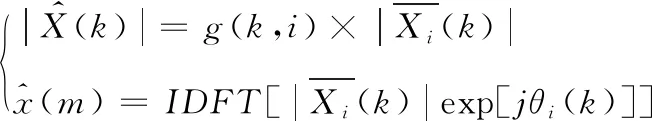
(3)
通过实验发现,过减因子的取值直接影响谱减的效果,且最优过减因子的值随信噪比变化而变化。但传统多窗谱估计的谱减法的过减因子为固定值,导致通常不能得到最优谱减效果。针对上述问题,本文提出基于自适应过减因子的改进多窗谱估计的谱减法,即过减因子的大小随信噪比变化而变化,而不再是固定值。经过大量实验测试,过减因子随信噪比的最优变化模型为:

(4)
式(4)中,表示原始信号信噪比。实验中将增益补偿因子固定为1×10。
3 自适应子带对数能熵积法
3.1 自适应子带对数能量和谱熵
传统的对数能量与谱熵的检测方法在低信噪比噪声环境下效果较差,文献[12]将子带技术应用于语音端点检测方法中,通过将每帧信号分成若干子带,计算每个子带的对数能量和谱熵,降低单一谱线幅值受到噪声的影响,能够提升在低信噪比环境下的检测准确率。
但常规子带方法中每帧信号子带数量的划分是固定的,而实际每帧信号受到的噪声干扰程度是不同的,且干扰的强弱直接影响信号有效子带的数量。因此,Wu等提出自适应的子带划分方法,将第帧的归一化最小带能参数Min和有效子带划分数量定义为:

(5)

(6)
根据每帧信号归一化最小带能参数的取值估计噪声干扰程度,进而确定有效子带划分数量,实现自适应子带划分的效果。具体自适应子带对数能量和谱熵的计算如下:
将第帧的信号预划分为个子带,=,其中表示帧长,表示子带的长度,则第帧第个子带功率谱能量为:
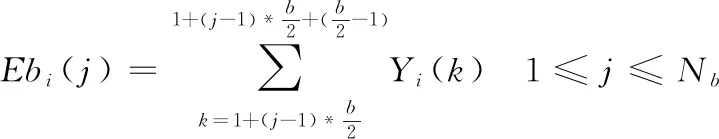
(7)
由式(5)和式(6)求得有效子带个数,并以此计算有效子带能量概率分布为:
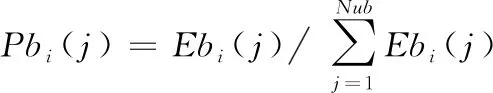
(8)
第帧的自适应子带对数能量和自适应子带谱熵分别为:

(9)
3.2 自适应子带对数能熵积
通过大量的语音样本计算,可发现自适应子带对数能量和自适应子带谱熵的曲线(见图1)显著特征,即在语音区间上自适应子带对数能量的图像是向上凸起的,而自适应子带谱熵则刚好相反。

图1 2个特征参数曲线
根据上述特点,本文提出一种新的语音特征参数:自适应子带对数能量熵积,具体定义如下:
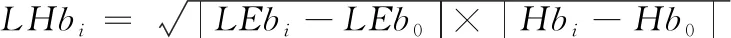
(10)
式(10)中,和分别表示前导无话段的自适应子带对数能量和自适应子带谱熵的平均值。
以作为端点检测的特征参数,不仅可以放大有话段和噪声段的数值差距,突出有话区间,增强彼此间的区分度,同时能够避免类似能熵比特征参数中可能出现分母为0的错误。
3.3 动态阈值双门限检测
传统双门限检测法使用固定阈值进行检测,适应噪声变化能力差,本文将固定阈值改进为基于特征参数的动态阈值,使其具备对噪声变化环境下的语音自适应检测能力。设初始阈值、为:

(11)
式(11)中:为前导无话段的自适应子带对数能熵积的均值;表示自适应子带对数能熵积的最大值;为标准差;和分别为上下限系数。于是阈值的动态更新可以表示为:
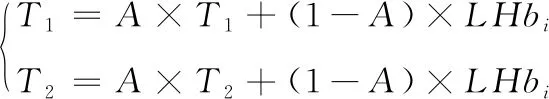
(12)
式(12)中:为阈值更新系数;为第帧信号的自适应子带对数能熵积。其中上下限系数决定检测门限高低,阈值更新系数影响阈值随样本变化的更新率,两者取值通常根据经验值设定。
本文对测试样本经过反复实验,测得最优取值为:=005,=015,=092。且若值过高,则会出现漏检,而值过低,则存在错检。
4 实验仿真
4.1 实验流程
本算法首先通过谱减提升语音信号质量,为后续端点检测奠定基础,而后计算增强信号的自适应子带对数能熵积,最后使用动态阈值更新双门限检测法进行端点检测,实验流程如图2所示。

图2 本文方法的实验流程框图
此外,本文对自适应子带对数能量和自适应子带谱熵特征值的提取进行以下优化:
1) 语音信号通常分布在3 500 Hz以下,且100 Hz以下存在交流频率干扰,因此仅提取信号在100~3 500 Hz的部分进行分析处理。
2) 根据文献[14],在式(8)中引入常量=05,得到改进的有效子带能量概率分布为:

(13)
3) 加入中值平滑处理,保持平滑段之间数据的阶跃性,减少个别野点对结果的影响。本文选取前后共5帧进行中值平滑处理。
4) 设置最小有话段和最长静音长度,防止跳变的高能噪声被误判为语音或字间间断造成漏检。本文将最小有话段设为5帧,最长静音长度设为8帧。
5) 根据文献[11]提出的新对数能量关系,本文将式(9)中的常数设置为2。
6) 通过大量实验测试,对文献[13,15]中的有效子带个数计算公式进行改进,具体如下:

(14)
实验主要步骤为:
1利用改进的多窗谱估计谱减法对语音信号进行增强处理,得到增强语音信号,并提取频率分布在100 Hz到3 500 Hz的部分进行后续处理;
2将每帧信号预划分成25个子带,计算每个子带功率谱能量。由式(5)和式(14)计算归一化最小带能参数Min和有效子带个数;
3由式(9)计算自适应子带对数能量和改进的自适应子带谱熵,再由式(10)计算自适应子带对数能熵积,最后进行中值平滑处理;
4由式(11)和式(12)设置动态阈值,利用单参数双门限法进行端点检测。
4.2 实验环境
本实验在Windows 10系统下,利用Python 3.7平台进行。实验音频分别采用采样频率为8 000 Hz,采样精度为16 bit纯净男声,内容为:“蓝天,白云,碧绿的大海”;另从TIMIT语音库中随机选取10条纯净语音。噪声选自Noisex-92数据库中的White、Pink、Babble、F16、Volvo和Factory噪声。
4.3 实验评价标准
为了验证本文方法的实际性能,分别对增强效果和检测准确率进行评价,具体评价标准如下:
1) 增强效果:分别从信噪比提高和语音质量感知评估测度(PESQ)2个方面综合验证增强性能。
2) 检测准确率:语音端点检测准确率可以定义为:
=[-(+)]×100
(15)
式(15)中:为语音段的总帧数,是将纯净语音信号端点检测结果和人工校验结果综合所得;为噪声被误检成语音的帧数;为语音被漏检为噪声的帧数。由于本文设置的最长静音长度为8帧,因此定义检测结果偏差值小于8帧均为检测准确。
5 性能分析
使用常规多窗谱估计谱减法和本文改进的方法对10条TIMIT语音库纯净语音信号在不同信噪比环境下进行增强,结果取平均值如表1、表2所示。
对比表1和表2数据发现,本文改进的谱减法在各类噪声环境下的平均信噪比和平均PESQ分数都要好于传统方法,因此可以证明本文改进的多窗谱估计谱减法性能较好,能够有效提升语音质量。

表1 传统多窗谱估计谱减的平均信噪比/PESQ分数

表2 本文改进谱减法的平均信噪比/PESQ分数
为验证自适应子带对数能熵积法的准确性和鲁棒性,本文利用不同种类噪声在不同信噪比环境下进行仿真测试,同时使用传统短时能量和过零率方法以及文献[6]基于MFCC倒谱距离与对数的方法进行对比分析。图3~图5为0 dB White噪声环境中上述3种方法对“蓝天,白云,碧绿的大海”语音段的检测结果。

图3 0 dB White噪声环境中短时能量和过零率检测曲线

图4 0 dB White噪声环境中文献[6]提出的MFCC距离检测曲线

图5 0 dB White噪声环境中本文提出的自适应子带对数能熵积法检测曲线
图3中,短时能量和过零率检测法漏检掉了3.5 s左右的“大海”这一部分内容。虽然文献[6]和本文提出方法均较为完整地检测出所有的语音段,但如图4所示,文献[6]方法在2.1 s附近区域将部分噪声错检为语音。
图6~图8为0 dB Volvo噪声环境中上述3种方法的检测结果。如图6所示,短时能量和过零率检测法此时出现了大量的错检,将噪声段检测为语音段;图7中,文献[6]基于MFCC倒谱距离与对数的方法同样在3.5 s左右出现部分错检,将部分噪音错判断为语音;图8中,本文使用的自适应子带对数能熵积法能够较为准确的检测出各语音段,没有出现明显的漏检和错检。

图6 0 dB Volvo噪声环境中短时能量和过零率检测曲线

图7 0 dB Volvo噪声环境中文献[6]提出的MFCC距离检测曲线

图8 0 dB Volvo噪声环境中本文提出的自适应子带对数能熵积法检测曲线
为进一步验证本文算法的稳定性和鲁棒性,将随机提取的10组TIMIT语音库纯净语音信号分别以-5、0、5和10dB的信噪比添加选取的6种不同噪声,而后使用3种语音端点检测方法进行检测,将所得检测结果取平均值,得到各自检测法的平均检测准确率如表3~表5所示。
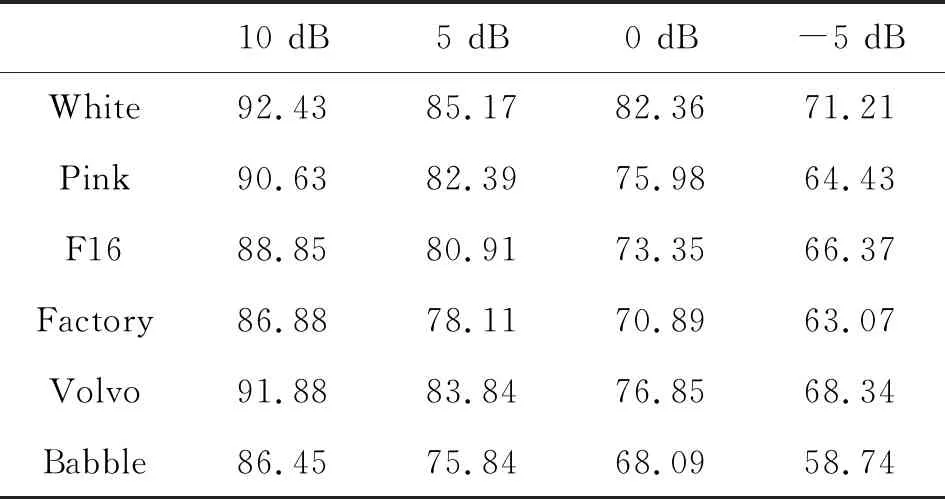
表3 短时能量和过零率法的平均准确率

表4 文献[6]提出的MFCC距离法的平均准确率

表5 本文方法的平均准确率
对上述结果进行分析,发现3种方法在White噪声环境下表现都好于其他噪声,而Babble噪声对检测结果影响最大。短时能量和过零率检测法总体检测效果最差;文献[6]的算法在高信噪比环境下检测效果较好,但在极低信噪比环境下的表现有待提高;本文采用的自适应子带对数能熵检测法虽然在极低信噪比环境下也存在个别漏检和错检,但整体表现明显优于另外2种检测方法,在不同的噪声环境下准确率较其他方法也有提升。
6 结论
提出一种新的语音端点检测方法,通过改进的多窗谱估计谱减法,提高语音信号的信噪比,改善语音质量,并以自适应子带对数能熵积为阈值,基于动态阈值双门限检测方法进行端点检测。仿真实验结果表明,基于谱减与自适应子带能熵积检测法在低信噪比环境下检测性能得到有效提升,相比短时能量和过零率检测法和基于MFCC倒谱距离与对数的语音端点检测方法,能够更为准确的实现语音端点检测,且具有更好的抗噪性和鲁棒性。
