基于深度挖掘的图书馆数字资源整合与共享
2022-03-15赵雷
赵雷
(山东大学图书馆,山东济南 250100)
在图书馆资源存储平台中,由于数据覆盖现象的存在,导致其存在明显的信息孤岛,从而使数字资源间的实时互联互通效果受到影响[1]。传统的云计算型资源整合策略利用目录体系整合图书馆数字资源,再利用门户平台将这些信息参量整合成新型的数据流传输格式[2]。然而该方法解决信息孤岛问题的能力有限,很难建立全新的数字资源实时互联互通关系。
深度挖掘是指从大量应用数据中提取隐含信息参量。由于网络主机事先难以获知数据信息的实际传输方向,因此深度挖掘指令的执行方向往往是复杂且多元化的。在实际应用过程中,网络主机首先需要确定与挖掘任务相关的目标数据对象所处位置;然后根据预处理节点中所包含的具体数据信息量确定深度挖掘指令的实际作用范围[3];最后在数据库主机的作用下,将相关暂存数据全部调整至快速转录的实时传输状态。
为解决传统的云计算型资源整合策略存在的不足,文中提出了基于深度挖掘的图书馆数字资源整合与共享算法,在权重样本时间衰减周期参量的支持下,准确设定实值挖掘参数,再借助数字资源目录体系实现对图书馆数字资源共享元信息的实时编码。
1 深度挖掘处理图书馆数字资源
图书馆数字资源的深度挖掘处理包括计算权重样本时间衰减周期、数据集表达、实值挖掘参数设定3 个执行环节,具体操作方法如下。
1.1 权重样本的时间衰减周期
权重样本时间衰减周期是一个相对较为宽泛的物理系数指标。在图书馆数字资源存储空间中,由于深度挖掘框架体系的影响,权重样本时间衰减周期往往会对数据参量指标的实时存储行为造成直接影响。
对于图书馆数字资源来说,深度挖掘框架体系的实际覆盖面积越大,数据信息参量所具备的应用存储能力就越强[4]。简单来说,权重样本时间衰减周期的长度值水平并不完全固定,随待存储图书馆数字资源量的增大,该项物理指标的数量级水平也会有所提升。但为了不影响最终的信息参量整合与分享结果,权重样本时间衰减周期指标也包含一定的约束能力,即在固定数值空间内,权重样本时间衰减周期指标能够影响图书馆数字资源的整合与共享处理结果[5-6]。
假设s、e分别代表两个不同的图书馆数字资源权重样本系数,n代表图书馆数字资源信息的样本采集系数,联立上述物理量,可将权重样本时间的衰减周期表达式定义为如下形式:

其中,Ws代表样本系数为s时的图书馆数字资源信息特征值,We代表样本系数为e时的图书馆数字资源信息特征值,| ΔT|代表图书馆数字资源信息的单位整合时长。
1.2 数据集表达
在实施信息参量整合与共享指令的过程中,数据集能够将所有未定义的图书馆数字资源信息囊括在内,并按照权重样本时间衰减周期的具体数值水平,更改已存储信息参量的实际传输速率。
数据集是一个相对宽泛的信息参量定义条件。为更有效地满足深度挖掘框架的实际应用需求,应在顺向转存图书馆数字资源信息参量的同时,将剩余数据指标整合成全新的传输形式,一方面满足图书馆主机对于数字资源信息的整合与分享需求,另一方面也可暂时缓解由权重样本时间衰减周期所引起的信息参量存储及时性较差的问题[7-8]。设u代表图书馆数字资源的信息共享系数,联立式(1)可将图书馆数字资源的数据集表达式定义为:
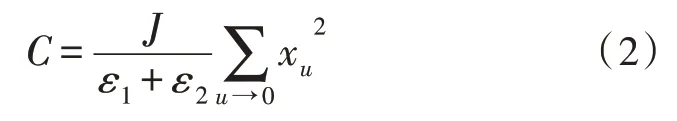
式中,ε1、ε2分别代表两个不同的图书馆数字资源信息参量定义条件,xu代表既定的数字资源信息整合基向量。
1.3 实值挖掘参数设定
实值挖掘参数设定是深度挖掘的关键处理步骤之一,可在已知权重样本时间衰减周期与数据集表达条件的基础上,对图书馆数字资源信息的整合与共享能力进行初步约束,从而不断提升图书馆主机的数据参量查询能力。图书馆数据存储平台同时管理着大量的数字资源信息,且由于参量整合与共享模式的不同,这些信息文件的最终传输方向也有所不同。但大多数情况下,其传输行为都有利于参量深度挖掘指令的进行与实施[9-10]。
假设pmin代表图书馆数字资源挖掘深度值的最小值,pmax代表图书馆数字资源挖掘深度值的最大值。一般情况下,上述两者之间的物理差值水平越大,实值挖掘参数的设定结果也就越精准。在上述物理量的支持下,联立式(2)可将实值挖掘参数设定结果表示为:

其中,f代表深度挖掘系数,λ代表数字资源信息的共享特征值,I1、I2分别代表不同的图书馆数字资源信息挖掘权限值。
2 图书馆数字资源的整合与共享
在深度挖掘原理的支持下,按照数字资源目录体系搭建、共享元信息编码、资源整合维度确定的操作流程,实现新型图书馆数字资源整合与共享算法的顺利应用。
2.1 数字资源目录体系
数字资源目录体系由一级单元、次级单元两部分共同组成。其中,一级单元也叫图书馆数字资源的总目录。受到深度挖掘框架的影响,该目录体系下级同时管理多个分目录组织,可在准确记录图书馆数字资源信息传输行为的基础上,对次级目录单元发出数据信息的整合与共享指令[11-12]。次级单元也叫作图书馆数字资源的二级目录,其下级连接结构也同时管理多个分目录组织,能够准确接收图书馆主机反馈而来的数字资源信息参量,并可以数据传输流的方式,将未完全消耗的数字资源信息传输回主目录结构体之中,从而较好地满足待传输数据信息参量的整合与共享需求。图书馆数字资源目录体系如图1 所示。
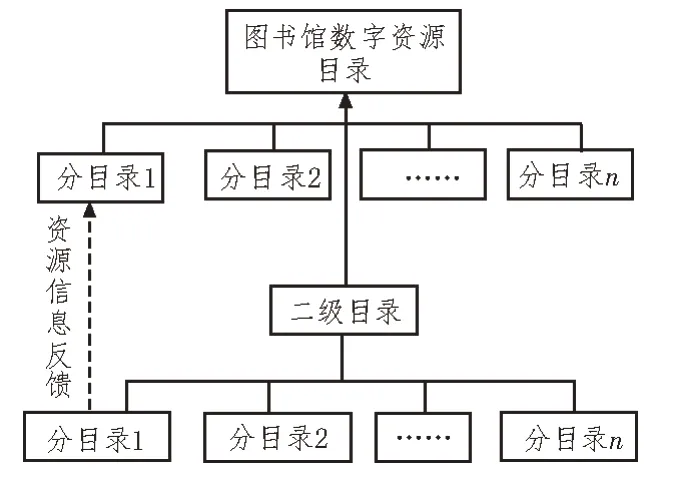
图1 图书馆数字资源目录体系
2.2 共享元信息编码
为降低图书馆体系的维修成本、提高数字资源信息参量的开发效率,建立良好的共享元信息编码条件就显得极为必要。良好的编码规范不仅可以使图书馆数字资源信息的排列行为变得更加简单,也可以大幅节省数据参量的存储时间。
共享元信息是指图书馆数字资源中未被完全转存的数据参量,具有极强的传输灵活性[13-14]。因此,在实施共享元信息编码的过程中,应同时注意命名约束、歧义避免、设计原则等多方面问题。一般情况下,命名约束可采用Pascal 标记的方式对图书馆数字资源信息进行命名,一方面实现对资源信息参量的实时编码,另一方面也可避免资源信息堆积行为的产生。共享元信息的编码原理如表1 所示。

表1 共享元信息的编码原理
2.3 资源整合维度
整合维度从空间角度阐述了图书馆数字资源所具备的共享能力,在已知元信息编码条件的情况下,可按照数字资源的目录体系结构,对数据信息参量在图书馆主机中的传输能力进行精准定义,从而使得图书馆数字资源信息的整合与共享能力得到最大化提升[15-16]。
整合维度是一个相对独立的物理量。在深度挖掘框架的作用下,待传输的图书馆数字资源信息量越大,与之匹配的整合维度覆盖面积也就越大。且由于共享元信息编码条件的存在,这些待整合的信息参量可在图书馆主机中进行自行传输。这样不仅能够较好地解决资源参量的不平等分布问题,也可以实现对数字资源信息共享传输范围的不断扩展。设代表待共享的图书馆数字资源信息量均值,代表信息资源参量的整合特征值,联立式(3)可将资源整合维度结果表示为:

其中,μ代表图书馆数字资源的整合维度定义系数,k′代表既定的资源信息特征整合指标。至此,实现各项实用系数指标的计算与处理,在深度挖掘框架的支持下,完成图书馆数字资源整合与共享算法的设计。
3 实验与分析
文中设计如下实验验证该研究的有效性。建立相关的图书馆数字资源调度模式,然后分别将实验组和对照组处理算法接入资源存储主机中。其中,实验组主机采用基于深度挖掘的图书馆数字资源整合与共享算法,对照组主机采用云计算型资源整合策略。
信息孤岛是一种严重的数字资源传输闭锁问题。通常情况下,信息孤岛现象越明显,数字资源的传输闭锁行为也就越严重。RPP 指标能够反映图书馆数字资源信息孤岛现象的出现几率,该项指标的数值水平越高,信息孤岛现象的出现几率也就越大。表2 记录了实验组和对照组RPP 指标数值的具体变化情况。
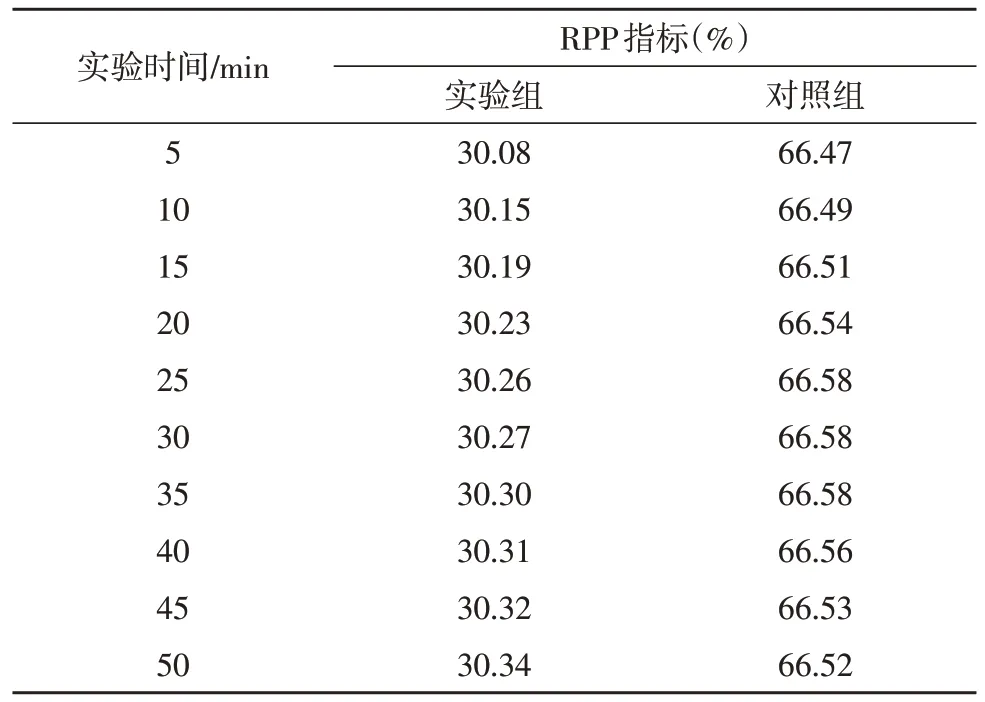
表2 RPP指标数值对比
表2 中,实验组RPP 指标数值始终保持连续上升的变化趋势,整个实验过程中,前期的数值上升幅度明显大于后期。对照组RPP 指标数值则保持先上升、再稳定、最后下降的变化状态,且前期上升幅度与后期下降幅度并无明显区别。从极限值角度来看,实验组最大值与对照组最大值相比,下降了36.24%。
综上可知,应用基于深度挖掘整合与共享算法后,RPP 指标数值水平得以明显提高,在一定程度上解决了图书馆数字资源的信息孤岛问题,实现了对数据信息参量的稳定传输。
SUT 指标能够反映图书馆数字资源信息的实时互联与互通能力。在不考虑其他外界影响条件的情况下,SUT 指标数值越大,图书馆数字资源信息的实时互联与互通能力就越强。表3 记录了实验组、对照组SUT 指标数值的具体变化情况。
分析表3 可知,实验组SUT 指标在实验前期始终保持绝对稳定的状态。从第25 min 开始,这种数值走向趋势开始逐渐趋于阶梯状变化,全局最大值达到了73.17%。对照组SUT 指标则在小幅下降状态后,开始逐渐呈现波动式变化状态,全局最大值仅能达到52.71%,与实验组最大值相比,下降了20.46%。

表3 SUT指标数值对比
综上可知,应用基于深度挖掘的整合与共享算法后,SUT 指标出现了明显上升的数值变化状态,能够促进图书馆数字资源信息实时互联与互通能力的不断提升。
4 结束语
与云计算型资源整合策略相比,基于深度挖掘的整合与共享算法打破了图书馆各级存储数据间的信息孤岛限制,从而实现数字资源的实时互联与互通。从搭建流程的角度来看,由于权重样本时间衰减周期值的存在,实值挖掘参数能够得到精准设定,可在建立图书馆数字资源目录体系的同时,实现对资源整合维度系数的有效控制,从而具备较强的实际应用价值。
