基于SVM 和背景模型的显著性目标检测算法
2022-03-15张艳邦张姣姣
张艳邦,张 芬,张姣姣
(1.咸阳师范学院数学与统计学院,陕西咸阳 712000;2.咸阳师范学院智能信息分析与数据处理研究所,陕西 咸阳 712000)
显著性目标检测的主要任务是使计算机模拟人类视觉注意机制,自动确定图像中有吸引力的、有价值的目标,而抑制其他不含重要信息的背景区域。随着图像和视频数据的获取越来越便捷,面对数据量的激增,显著性检测作为一种重要的图像预处理方法,在减少计算复杂度方面起着重要作用,目前已经广泛应用于许多计算机视觉任务中,如图像分割[1-2]、目标识别[3-4]、图像压缩[5]、图像检索[6-7]等。
由于人类视觉系统对颜色的敏感性,颜色特征一直是显著性目标检测算法考虑的主要因素。现有的显著目标检测方法主要通过计算目标区域与局部周围区域或全局图像场景的差异性来探索图像显著性。
1998 年,Itti 等人[8]指出人类视觉系统对对比度较高的有意义区域敏感,根据图像的亮度、颜色和方向等底层特征提出了经典的显著性检测模型。2009年,Achanta 等人[18]提出基于频域的颜色和亮度特征估计中心周围对比度。Fareed 等人[9]提出了一种利用多种颜色特征的对比度特征和分布特征的自底向上显著性检测方法,文中还采用了平滑函数,以提高检测效果。在文献[10]中,Cheng 等人分别计算了超像素全局对比度及局部对比度,并通过加权融合特征凸显显著性区域。这些无监督的方法复杂度较低,不需要太多的运行时间成本,而且没有针对固定的目标,检测算法推广性较好,然而,它们的检测精度往往不能令人满意。
几十年来,目标先验一直是显著特征提取的重要线索。可是,由于目标的多样化,对图像进行显著性检测之前,人们往往对图像目标一无所知,也就无法获取前景目标的先验信息。然而,背景先验模型提供了另一条思路,在该领域得到了一定的应用。通过假设图像的大部分窄边界为背景区域,根据图像像素与图像边界的连通性获取图像背景先验信息,计算显著性图。虽然这些方法可以有效地提高检测效果,但是仅仅利用边界区域的像素特征来直接计算像素的差异性,这种获取目标显著特征的方法仍然不足以增强预测效果。深度学习是近几年发展的热点,利用构架深层的神经网络可以显著提高算法的分类或检测性能。目前,深度学习算法在各个研究领域得到了广泛应用[11-14]。然而,为了提高深度学习算法的性能,在训练过程中需要大量的已标注数据,增加网络深度的层数,这对实验设备要求也比较高。为了降低对实验设备的要求,以及针对检测目标的不确定性,基于已有的研究成果,文中提出了结合SVM 和背景模型的显著性目标检测算法。首先,将靠近图像边界区域的超像素特征作为图像背景特征表示构建初始背景模型,通过计算颜色对比度得到初始显著图;然后,通过选取不同的阈值,得到带有标注信息的前景像素和背景像素及待检测像素;接着,采用SVM 算法对带有标注信息的前景像素和背景像素训练,学习得到前景和背景的分类模型,再结合信息熵评价特征图,迭代优化背景模型,进而得到显著性目标。在公开的数据库上测试了文中算法,实验结果表明,文中提出的算法具有较好的检测效果。
1 显著性目标检测算法
1.1 超像素分割
文中采用简单线性迭代聚类(Simple Linear Iterative Clustering,SLIC)算法[15]对输入图像进行超像素分割预处理。SLIC 算法与其他超像素分割算法相比计算速度较快,而且分割得到的超像素具有较好的特征一致性。与像素级表达图像特征相比,超像素级包含了语义信息,描述图像更加准确,既能抑制噪声,又可以降低计算复杂度。超像素的分割个数越多,保留的图像细节信息越多,但是计算量增大;超像素个数越小,计算量越小,同时也丢失了部分细节信息。为了权衡算法计算量与图像细节信息,文中在实验中将图像分割为200 个超像素。
1.2 背景模型
当拍照时,通常会把目标放于靠近图像中间的区域,而图像的边缘区域一般为人们不关心的背景区域。根据这一事实,文献[16]选择将靠近图像边界区域的颜色特征作为图像背景的代表特征,显著性特征定义为图像内部区域像素与边缘区域中部分像素的特征差异,由此得到了简单有效的显著性目标检测模型。
为了简化计算,文中仍然选择靠近图像边缘的区域为背景,这些超像素的颜色特征作为图像背景的代表特征,然后计算其余区域的颜色特征与背景区域超像素颜色特征的差异,获得图像初始显著图。目标存在不确定性,虽然目标一般处于图像内部区域,但是也可能目标比较大,目标的局部位于边缘区域,因此,图像的边缘也不一定完全是背景。为了避免这一现象引起的漏检,在显著性特征计算中,只选择与对应像素差别最小的5 个超像素,将它们间的加权和作为该超像素的显著性特征。令S(i)表示第i个超像素的显著性特征值:
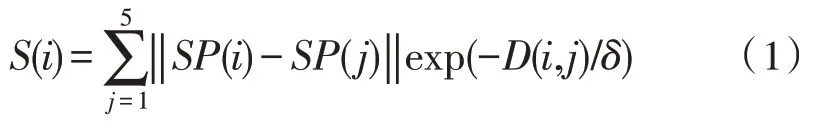
其中,‖SP(i)-SP(j) ‖表示Lab 颜色空间中第i个超像素与第j个超像素间的欧式距离。‖·‖ 为取2范数运算。D(i,j)表示第i个超像素与第j个超像素间的欧式距离。两个超像素距离越近,相互间影响越大;距离越远,影响越小。δ是调节参数,与图像的大小有关,这里选择为图像的对角线长度。
1.3 模型更新
背景模型中目标的先验信息只有像素的位置信息,用图像边缘部分的像素特征描述图像背景特征,对于图像靠近内部的区域是否也可以描述图像背景特征呢?为了获取图像内部区域中背景先验信息,通过选取阈值将特征图二值化,根据不同的阈值将图像像素分为前景、背景和待检测区域。
特征值大于TH的超像素标记为前景,特征值小于TL的超像素标记为背景,其余超像素标记为待检测像素。TH和TL计算如下:

对于已标注超像素的像素值,运用SVM 分类算法建立二分类模型,对未标注的像素进行测试,更新图像背景模型。
由于显著目标的分布集中,背景区域包围目标区域,分布较为分散。根据这一特点,文献[17]提出二维信息熵可以作为衡量显著图优劣的一个较好的标准。文中继续采用该方法,对得到的显著图计算其二维信息熵,当信息熵变化量小于给定阈值时,说明背景模型渐趋于稳定,迭代停止。文中算法流程图如图1 所示。
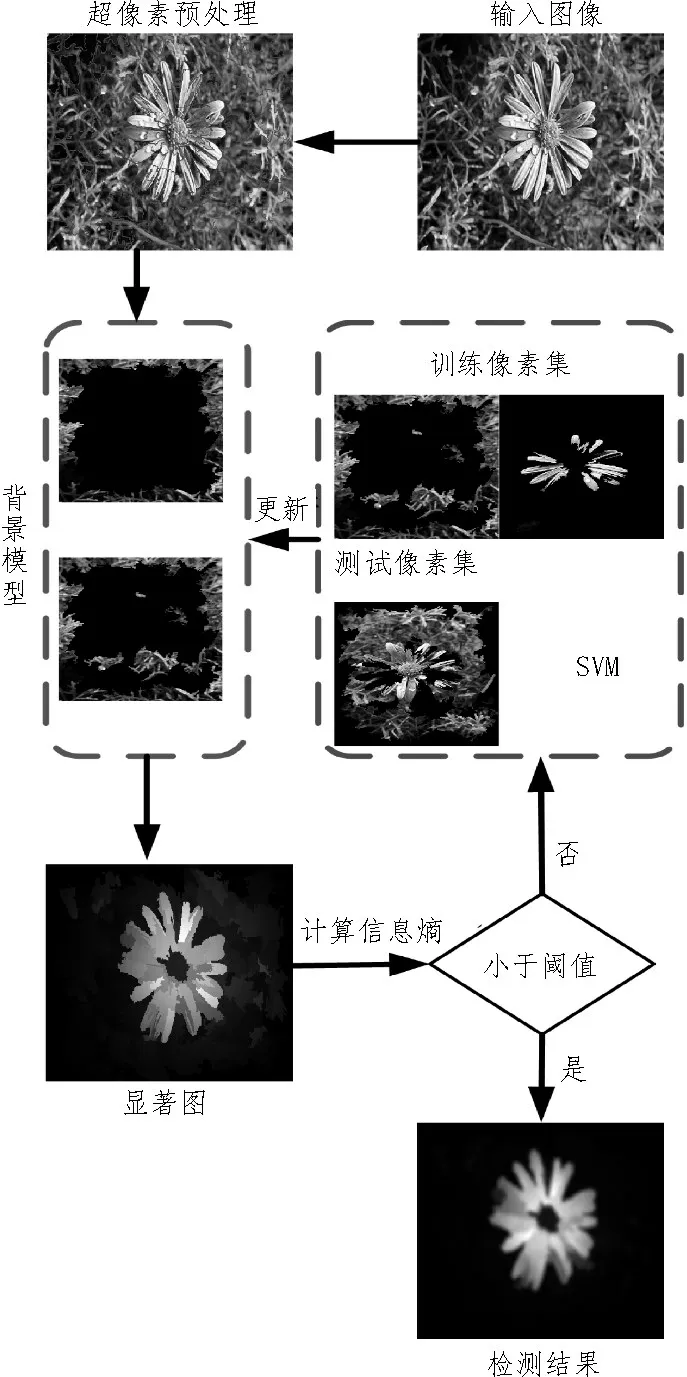
图1 文中算法流程图
2 实验结果及分析
文中方法测试的实验平台是64 位的Windows10操作系统,内存是8 GB,处理器是Intel(R)Core(TM)i7-7500,主频是2.7 GHz,软件版本是Matlab R2016a。为了综合评价文中算法的有效性,在公开的基准数据集MSRA[18]上进行了实验。MSRA 数据集是微软亚洲研究院建立的可以定量评价视觉注意力算法效果的公开大型图像数据库。该数据库包含了1 000幅自然图像,每一幅图像都有人工标记的基准图。
为了测试文中算法的性能,与目前主流5 种算法:视觉注意测量算法(IT)[8]、频率协调算法(FT)[18]、超复数傅里叶变换(HFT)[19]、测地距离(LIN)[20]以及直方图对比度(HC)[10]进行比较。
图2 给出了在MSRA 数据库中文中算法与现有其他5 种算法的直观比较。图2 中,从左到右第1 列为测试图像,第2~7 列依次为IT、FT、LIN、HFT、HC和文中算法的检测结果,最后1 列为基准图。HC 与其他几个算法相比,能够较好检测到目标,但是存在较多的误检。而文中算法对于图像中的目标个数是一个还是两个、目标位于图像边缘还是中心区域,都能够较好地检测到目标,并抑制背景的干扰。另外,文中给出了PR[21]、ROC[22]、AUC[22]、IOU和MAE[23]方面的实验结果。
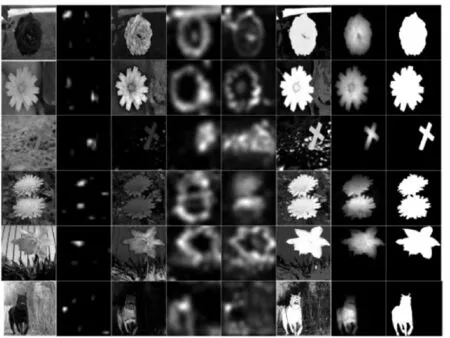
图2 在MSRA 数据库中文中算法与现有文献直观比较
PR 曲线是一种常用的显著性评价指标。每一个显著性特征图都被规范化为[0,255],然后选取整数阈值从0 到255,得到256 个二进制显著性对象掩码。SB(i)和GT(i)分别表示二值化特征图对象掩码和对应的基准值。准确率和召回率分别定义为:
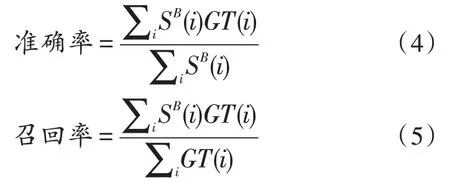

图3 MSRA数据集上不同算法的PR曲线比较
ROC 曲线是描述在不同的判别阈值(从0到255)下真阳性和假阳性之间关系的图形。AUC(Area Under Curve)指ROC 曲线下的面积,是ROC 曲线的定量比较,它们是评价显著图最常用的度量指标。图4 展示了在测试数据集上各种显著性检测方法的ROC 曲线。表1 给出了不同算法的AUC。显然,该算法在5 种方法中表现出了领先的性能。

图4 MSRA数据集上不同算法的ROC曲线比较

表1 MSRA数据集上不同算法的AUC比较
为了进一步评价文中算法的性能,将其与另一种新的度量方法——联合交集(IOU)分数进行了比较。

其中,Rn是通过以显著图的特征均值的两倍为阈值而获得的二值化特征图,GTn是基准图,N表示图像数据集中图像的个数。
与其他度量方法相比,IOU可以表示显著图与基准图真值的重叠率,即它们的交并比。重叠率越高,值越高。在理想情况下,比值为1。因此,根据图5中数据集上的IOU分数可知,文中算法具有较好的检测性能。

图5 MSRA数据集上不同算法的IOU柱状图比较
MAE是一种简单可靠的显著图评价指标,用于计算基准图和显著图的差异性,定义如下:

其中,S和GT分别表示显著图和基准图,N表示图像数据集中图像的个数。图6 显示了数据集上基于MAE的不同算法的比较。

图6 MSRA数据集上不同算法的MAE柱状图比较
图2~图6 和表1 分别显示了所提出的方法在PR、ROC、IOU、MAE和AUC方面与其他5 种流行方法的性能比较。从以上展示的图和表中可以看出,文中算法具有较好的检测效果,优于流行的检测算法。
3 结论
文中提出了一个融合背景模型和机器学习算法的显著性目标检测模型,该模型在无人工标注训练数据的情况下得到了学习较强的显著目标检测算法。在基准数据集上的综合实验表明,文中方法优于现有的一些显著目标检测方法。由于文中只考虑了颜色特征,没有考虑纹理、形状等其他特征,因此对于目标和背景颜色相近的图像检测效果还不是很理想。下一步将加入更多的底层特征,更充分地描述图像内容,以提高检测效果。另外,还可以将提出的方法扩展到更多的计算机视觉任务中,如协同检测[24]、RGB-D 显著性检测[25]等。
