区块链增强果蔬质量追溯可信度方法研究与系统实现
2022-03-14弋伟国何建国刘贵珊康宁波
弋伟国 何建国, 刘贵珊 康宁波
(1.宁夏大学物理与电子电气工程学院, 银川 750021; 2.宁夏大学食品与葡萄酒学院, 银川 750021)
0 引言
果蔬供应链往往涉及农业种植企业、物流公司、监管部门、消费者等多个参与实体,追溯过程具有点多、线长、面广的特点[1],追溯数据具有多源异构的特点,过程复杂度高和数据耦合性强使果蔬质量追溯体系的建立尤为困难。文献[2]提出利用人工智能技术降低追溯过程断链程度;文献[3]提出通过区块链技术重新构建追溯体系,完成追溯信息的上链管理,形成农产品供应链联盟系统内的信息可溯源;文献[4]提出的链上链下追溯信息双存储设计,降低区块链数据存储的负载。利用区块链技术解决质量追溯系统可信度低、链条不完整、存在信息孤岛等问题已成为业内共识。
目前果蔬质量追溯体系存在的问题是各参与方对数据的信任度较低,供应链各参与实体之间处于一种博弈关系,各个实体间信息不对称,造成对追溯数据的信任度低和信任成本高[5]。传统质量追溯系统应用中心化数据库,追溯过程各个环节的数据由企业自主管理,存在信息丢失和被篡改的可能,产生纠纷时举证困难、责任难以明确[6],增强追溯数据的可信度是目前亟需解决的技术问题[7]。
在增强追溯数据的可信度研究方面,一些学者进行了研究[8-12],近些年来针对质量追溯数据可信度增强方法研究主要集中在通过物联网数据采集设备减少数据采集环节的人为干预,通过非对称加密算法防止数据传输过程篡改,在数据存储和处理端采用分布式系统多节点共同验证来保证数据真实性。随着区块链技术的发展,利用区块链天然的数据不可伪造篡改能力保证质量追溯系统数据可信度的研究越来越多,但是区块链平台数据读取速度慢的特点使其应用在果蔬质量追溯这种需要大量读取数据的系统时往往受到限制,因此需要结合实际应用特点研究保证数据可信并提高数据读取效率的解决策略[13-18]。
本文针对果蔬质量追溯系统数据可信度低的问题,将区块链技术应用到果蔬质量追溯系统,利用二次上链方法提高查询效率,通过试验验证并应用到果蔬质量追溯系统中,研究提升果蔬质量追溯系统可信度和提高果蔬质量追溯查询效率的方法。
1 可信追溯方法研究
1.1 追溯流程
将果蔬质量追溯从供应链角度划分为种植、仓储、物流和销售环节。种植环节包括播种、施肥、除草、浇水、收割、采摘等作业,需具备记录产地信息、田地环境变量、作业时间、作业人员、农资信息、完成进度、作业照片等功能;仓储环节需记录果蔬入库时间、出库时间、冷库温湿度;物流环节需记录果蔬打包上车时间、物流过程物流车GPS定位和冷链温湿度;销售环节能够记录果蔬销售城市和分销地点。
如图1所示,从追溯流程角度要实现正向查询和反向追溯,消费者通过扫描果蔬包装上的二维码能够查询果蔬从种植到销售的可视化数据并对产品进行评价和投诉,在果蔬出现质量问题时监管部门和供应链参与机构能够反向追溯导致果蔬质量问题的环节和因素;从数据可信角度供应链参与实体能够提交数据,并能够保证提交的数据是多方可信的。果蔬在进入销售环节追溯链形成后追溯数据基本确定,此时如果完成数据可信验证将会大大减少消费者查询用时,提高系统响应速度。
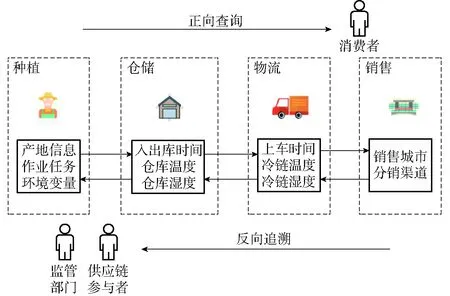
图1 查询和追溯过程Fig.1 Query and trace process
1.2 数据存储与验证方法
质量追溯系统中的数据是实时产生的,田间气象站和冷库及物流车上安装的感知设备产生的数据是基于时间序列的,这些数据需要实时存储,如果将完整数据直接存储在区块链系统中会造成系统阻塞。可以采用“数据入库+哈希值上链”的方式,保存数据时将原始数据存储在数据库中,将原始数据的哈希值添加到区块链上;读取数据时先读取数据库中的数据并计算哈希值,然后从区块链中查询该数据的哈希值,将计算的哈希值与区块链上的哈希值进行比对,即可验证数据是否被篡改。
“数据入库+哈希值上链”的方法在数据量小且对响应时间要求不高的情况下能够满足要求,但是果蔬质量追溯系统需要追溯果蔬全生命周期的所有数据,消费者进行一次追溯查询操作涉及农田环境、种植作业、仓储和物流等多个环节,需要查询多条记录。从区块链获取哈希值进行比对验证非常消耗系统资源和时间,尤其在消费者追溯环节对系统响应时间极高,系统延时会严重影响到用户使用体验。
本文在“数据入库+哈希值上链”方法的基础上通过数据哈希值二次上链和验证进行了改进。具体步骤为:
(1)数据保存。数据保存到数据库后计算数据哈希值,并将哈希值添加到区块链,完成第1次上链;在这个步骤中,数据输入可异步完成,无需用户或感知设备等待,对响应时间要求低,计算哈希值并添加到区块链中造成的等待时间对系统性能影响较小。
(2)提前验证并将数据打包上链。在果蔬销售环节追溯流程结束后追溯链形成,追溯数据已确定,追溯链相关数据在步骤(1)中已全部添加到数据库和区块链中。系统自动读取追溯链涉及的所有数据,并与区块链上的数据比对验证数据是否被篡改,完成第1次验证,验证结束后对所有数据打包后再次计算哈希值h1,并把哈希值h1添加到区块链,完成第2次上链。
(3)数据追溯。从数据库读取本次追溯涉及的所有数据,打包计算数据哈希值h2,再从区块链获取数据哈希值h1,对比h1和h2是否相等即可验证数据的真实性,完成第2次验证。这个步骤中追溯果蔬质量相关数据时,用户处于等待状态,对系统响应时间要求高,需要较快的数据查询速度。
1.3 理论分析
1.3.1数据可信度
数据在存储环节的不可篡改性是数据可信的重要基础,在数据存储到数据库之前利用MD5算法计算数据哈希值,在追溯链形成后把追溯链中涉及的数据和哈希值逐条验证,通过后将所有数据打包再利用MD5算法计算数据哈希值。
MD5算法将数据按512位为1组进行分组,分组后又划分为16个32位子分组。对于每个子分组的计算由4圈组成,每圈有16步,每圈的运算中包括4个非线性函数,即
(1)
算法的最终输出由4个32位分组组成,将这4个32位分组级联后生成一个128位散列值为最终结果[19]。从算法过程和非线性函数可以看出MD5算法是对原始数据的有损压缩计算,无论原始数据多长都会生成一个长度为128位的哈希值。
有研究表明通过一定的碰撞试验可以产生相同哈希值的原数据[20],但是本文通过两次哈希值计算并且数据具有一定的实际意义和特定的数据格式,通过碰撞产生的原始数据是随机的,经过程序的格式检测即可判断出真伪。
以上分析证明了通过把数据哈希值存储在区块链,原始数据存储在数据库,无法在哈希值不变的情况下修改原始数据,但是篡改原始数据的同时修改对应的哈希值可以实现数据篡改,下面将分析如何保证哈希值的不可篡改。
在区块链系统中每个哈希值生成一个数据区块[21],如图2所示每个数据区块包含区块头和区块体两部分:区块头封装了前一区块哈希值、当前区块的哈希值、当前区块随机数、Merkle根以及时间戳等信息[22];区块体包括当前区块的交易以及经过验证的区块创建过程中生成的所有交易记录,对于本文来说交易记录就是原始数据的哈希值,这些记录最终生成唯一的Merkle根记入区块头[23]。通过每个区块存储前一个区块的哈希值使区块首尾相连形成区块链,当区块链中任意区块的信息被篡改则所有区块的哈希值必然发生改变,以此来保证区块链上数据不可篡改。

图2 区块结构图Fig.2 Structure diagram of block
1.3.2存储效率
普通方法在追溯查询环节需要从区块链读取追溯相关数据的哈希值并从数据库中读取相关数据逐条计算哈希值,改进后的方法只需从区块链读取一次哈希值后从数据库读取所有相关数据并打包计算哈希值对比验证,两种方法的用时计算公式为
(2)
式中T1——普通方法用时
T2——改进后的方法用时
n——数据哈希值个数
t1——从区块链读取一条数据哈希值用时
t2——从数据库关联查询多条数据用时
通过式(2)可以看出普通方法算法时间复杂度为O(n),改进后的方法算法时间复杂度为O(1),理论上可近似认为改进后的方法与普通方法相比算法时间复杂度由线性阶降低为常数阶,数据查询效率明显提升。
1.4 试验与结果分析
对1.2节中提出的两种方法,将“数据入库+哈希值上链”方法称为普通方法,将基于“数据入库+哈希值上链”的哈希值二次上链和验证方法称为改进方法。改进方法在数据保存环节数据打包计算哈希值后添加到区块链操作本应该在果蔬进入销售环节后执行,但是在试验中为了便于对比数据且减小人为因素对试验的干预,将此环节放在数据上传完成后进行。试验步骤如图3所示。

图3 普通方法和改进方法试验流程图Fig.3 Test flow charts of common method and improved method
试验在阿里云服务器中进行,服务器CPU为单核、内存为2 GB,操作系统为Ubuntu 20.04 64位、网络带宽为2 Mb/s,Fabric版本为2.0,Docker 版本为20.10.8。Fabric 联盟网络包括4个Peer节点,1个Orderer节点,Fabric中的数据库采用CouchDB,共识机制采用Kafka,试验用例基于fabric-gateway-java V2.2.2开发,Chaincode采用Node.js编写。
1.4.1数据可信度
在数据完成入库和上链后,利用Webyog SQLyog数据库客户端工具登录数据库管理系统随机修改50个追溯链中的其中1条数据,修改数据后再通过追溯查询客户端查询50个追溯链的结果,均显示数据已被篡改。
1.4.2数据保存和查询效率
为了保证试验的准确性,每组数据经过图3流程重复操作20次,计算20次平均值作为最终结果,针对两种方法分别进行试验。
如图4所示,改进方法数据保存用时比普通方法增加4%左右,主要由于改进方法多了数据逐条验证后打包计算哈希值并添加到区块链环节,由于数据保存属于异步操作无需用户等待,用时增加4%左右对系统影响很小;如图5所示,改进方法在数据查询平均用时0.066 s,而普通方法用时随着数据条数增加呈线性增加,在数据条数为300时改进方法查询用时为普通方法的0.29%。
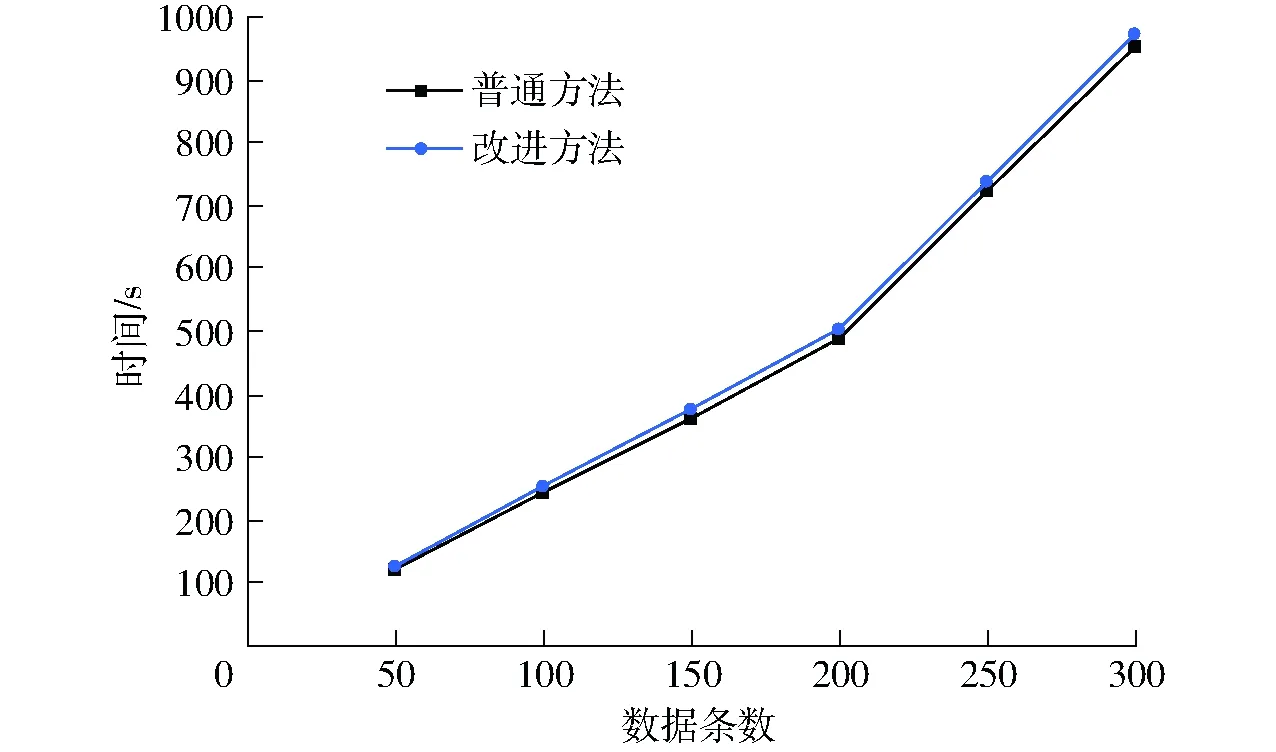
图4 普通方法和改进方法在不同数据条数下保存数据时间对比Fig.4 Comparison of data saving time of common method and improved method under different data pieces
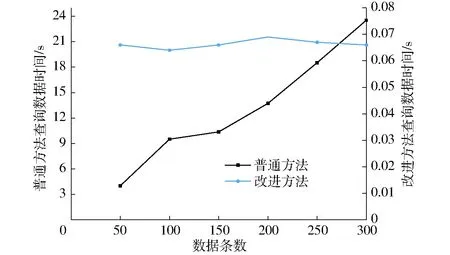
图5 普通方法和改进方法在不同数据条数下查询数据时间对比Fig.5 Comparison of data query time of common method and improved method under different data pieces
2 系统实现
2.1 相关技术
系统实现涉及的编程语言、环境、技术框架、底层架构及工具有Java、JavaScript、Node.js、Spring、SpringMVC、MyBatis、Express、Hyperledger Fabric、MySql、Maven、Tomcat、Git等;从功能上可将系统分为管理平台、数据平台和追溯客户端3个子系统,追溯系统管理平台和数据平台服务端开发语言采用Java,使用Spring、SpringMVC、MyBatis(经典的SSM框架)分别作为软件系统的 IoC和AOP容器、MVC 架构、数据持久化工具,浏览器端采用HTML、JavaScript、CSS等前端编程语言实现,项目构建采用Maven,Web容器采用Tomcat;追溯客户端服务端采用Node.js语言开发,使用Express框架,追溯客户端之所以采用基于Node.js环境开发而没有采用Java,主要是因为追溯客户端后端业务相对简单,主要是数据渲染,对系统响应时间要求较高,Node.js以非阻塞方式处理输入/输出,这意味着单个线程可以同时管理多个输入/输出请求,无需等待一个请求完成即可开始处理其他请求,响应速度较快;3个子系统的数据存储数据库选用MySql,区块链平台选用Hyperledger Fabric。
2.2 系统开发
2.2.1区块链搭建
Fabric系统分为种植机构、仓储机构、物流机构和监管部门4个组织,每个组织内都包含承担不同功能的Peer节点。如图6所示,每个组织都有各自对应的Fabric-ca服务器负责动态生成Fabric的账号,Committer Peer接收生成的交易区块,Leader Peer负责将交易从排序节点分发到组织中的其他节点,Endorse Peer在满足背书策略的条件下对交易进行确认,Anchor Peer负责与其他组织中的节点进行通信,所有的组织共用一个统一的Orderer集群,Kafka是一个分布式消息队列系统,负责打包数据。
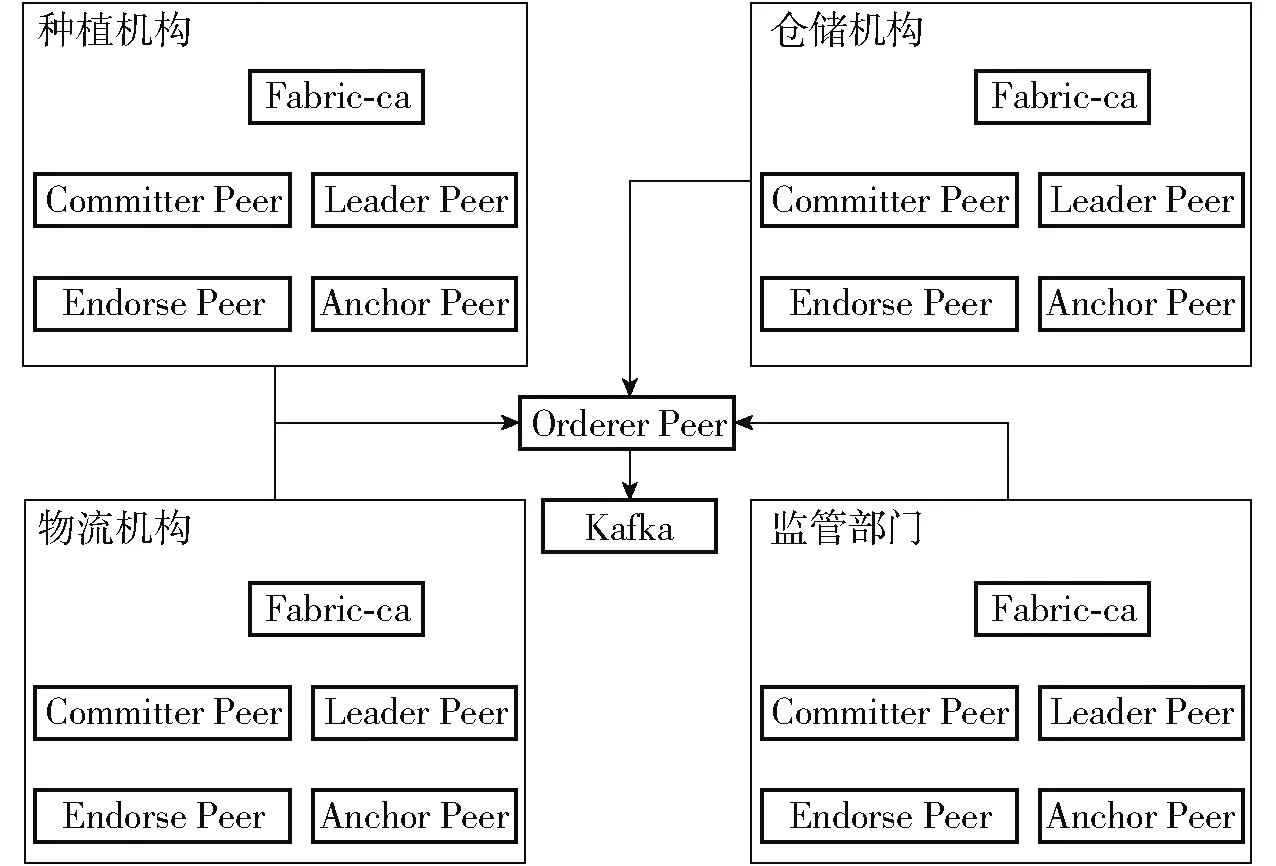
图6 Fabric系统结构图Fig.6 Fabric system structure diagram
每个参与方都可以向Fabric系统中添加数据,并通过Gossip广播协议同步到其他节点,当一个节点接收到交易信息后,随机选择x个节点同步消息,节点收到信息后,更新数据,这样使得每个节点都能维持完整的链上数据,且不需要节点时刻处于连接状态,还能处理节点故障和拜占庭问题[24]。
2.2.2硬件系统搭建
在农田安装气象环境监测站感知农田环境因子。气象站由数据采集器、环境传感器、视频监控系统、物联网数据传输模块组成,主机电源供电方式采用户外太阳能供电和内置锂电池组供电,数据采集模块采用MODBUS485通信,自动识别各类型支持485通信的传感器,最多可采集256个传感器数据,目前可采集空气温度、露点温度、空气湿度、光照强度、大气压力、风速、风力、风向、降水量、土壤温度和土壤湿度。主机采取的多种远程数据传输方式,能够通过以太网、WiFi或4G网络将数据实时传输到数据平台。
2.2.3软件系统开发

图7 果蔬质量追溯管理平台部分界面Fig.7 Partial interface of fruit and vegetable quality traceability platform
管理系统部分工作界面如图7所示,用户角色分为系统管理员和业务管理员,系统管理员是负责维护系统的工作人员,具有最高权限,业务管理员是种植机构、仓储机构、物流机构和监管部门工作人员;管理员可在企业管理界面根据业务实际需要添加企业,消费者可以通过扫描追溯码查看企业名称、描述、地点和照片;使用气象站、冷库和物流车感知设备之前需由业务管理员将设备信息添加到系统中,包括设备名称、设备类型、支持的网络类型、通信协议、硬件ID;果蔬存在一年收获多茬的情况,批次管理为了区分同一块农田种植的多茬果蔬,在果蔬种植前种植机构管理员需在系统中添加批次。
图8为气象站检测农田光照强度的曲线图,另外还可检测空气温湿度、露点温度、大气压力、风速、降水量、土壤温湿度、冷库和物流车门开关状态、物流车GPS位置等信息,针对每个指标可以设置预警值,当达到预警值时会通过短信将预警信息推送给管理人员。
消费者追溯客户端界面如图9所示,消费者可以通过扫描包装上的二维码查询果蔬种植企业信息、企业位置、种植过程、物流信息、农田环境信息、冷库温湿度和物流车温湿度,并能对果蔬进行评价和投诉。
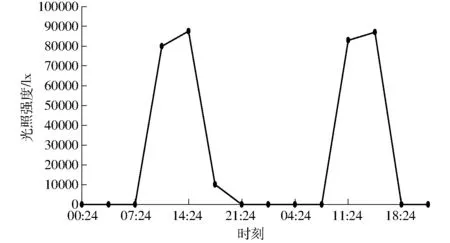
图8 物联网平台数据检测曲线Fig.8 Data detection curve of Internet of things platform
图9 追溯客户端界面Fig.9 Traceability client interface
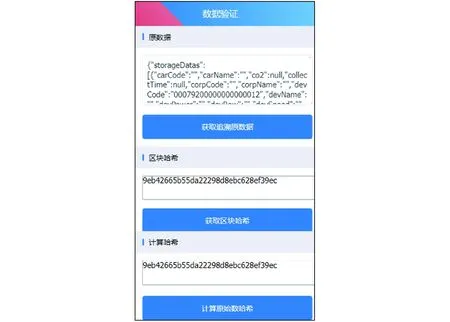
图10 数据验证页面Fig.10 Data validation interface
如图10所示,消费者在数据验证界面可以从数据库中获取本次追溯查询的所有原始数据,从区块链中获取本次追溯查询的哈希值,该页面还可以计算原始数据的哈希值,消费者通过计算原始数据哈希值后与从区块链获取的哈希值比较,如果相等则说明原始数据未被篡改,如不同则说明数据被篡改。
2.3 应用与示范
将本文研究的系统应用在宁夏鑫茂祥现代农业发展有限公司,该企业主要从事宁夏回族自治区供港菜心和芥蓝的生产,其两家子公司从事供港蔬菜的贮藏和运输。本文研究的果蔬质量追溯系统有效地提高了供港蔬菜的品牌效益,起到了质量控制效果。
3 结论
(1)基于区块链的数据哈希值二次上链和验证方法增强了果蔬质量追溯系统数据存储可信度,能够保证质量追溯多个参与实体之间数据的真实性,同时解决了区块链存储果蔬质量追溯数据时消费者追溯查询用时过长问题,追溯查询算法时间复杂度由线性阶降低为常数阶,消费者追溯查询用时控制在0.066 s左右,在数量条数为300时,查询用时是普通方法的0.29%,随着数据条数的增加查询时间基本保持不变。
(2)基于Hyperledger Fabric平台,采用Kafka共识机制,使用JavaWeb、Node.js等技术开发质量追溯系统具有很高的可行性,本文的实现方案和技术细节为开发区块链相关应用提供了方案设计和技术实现方面的参考依据。
