基于知识图谱的企业税收遵从风险关联研究
2022-03-13郑捷李一军
郑捷 李一军




摘 要:目前税收遵从风险的研究大多聚焦于企业自身的风险状态,忽视了广泛存在的风险关联传导现象。本文通过挖掘整合多源数据,构建了企业税收遵从风险相关的知识图谱,研究了以欠税风险为代表的税收遵从风险在企业内外部的关联传导问题。结果表明:同一企业,不同税收遵从风险传导特征较为明显,税收遵从风险与失信风险因政府监管而呈现负相关特征;不同企业,具有相同法人代表、相同联系方式的情形下,税收遵从风险的关联度显著提升,其与失信风险的关联度也随之提高。本研究扩展了税收遵从风险的理论研究视野,并为税收管理实践提供了新的理念和思路。
关键词:税收遵从风险;知识图谱;风险关联
中图分类号:C931.6 文献标识码:A 文章编号:2097-0145(2022)01-0048-08 doi:10.11847/fj.41.1.48
Abstract:Most of existing research on tax compliance risk only focused on a single enterprise, ignored the widespread phenomenon of risk correlation transmission. This paper integrates multi-source data to construct a knowledge graph of enterprise tax compliance risk. Based on the knowledge graph, the correlation of tax compliance risks inside and outside enterprises are studied from multiple perspectives. Research shows that tax compliance risk does not exist in isolation. Within the enterprise, the tax compliance risk conduction characteristic is obvious. Externally, the same legal representative and contact method can improve the correlation of tax compliance risks among different enterprises, and also improve the correlation between tax compliance risk and trust-breaking risk. This study expands the theoretical research field of tax compliance risk, even provides new ideas for tax management practice.
Key words:tax compliance risk; knowledge graph; risk correlation
1 引言
税收是国家公共财政最主要的收入来源和形式,其本质是国家凭借公共权力参与国民收入分配的一种特殊分配关系,对于调节经济利益、维护国家权益、促进社会发展有着极其重要的意义。
税收遵从(Tax Compliance)是与税收紧密相关的一个概念,经济合作组织OECD将其定义为纳税人遵守其所在国家税收法规的程度,例如,纳税人及时申报和缴纳税款。税收遵从风险是指纳税人受各种负面的不确定因素的影响,未依法履行纳税义务或者未服从税务机关及税务人员合法合规管理,而造成的国家税收流失风险和纳税人利益损失风险。企业欠税行为就是一种典型的税收不遵从行为,也是税收遵从风险的典型表现形式,在全世界普遍存在且影响重大[1,2]。
当前国内外学者对税收遵从风险的研究主要从企业的个体状况切入,基于企业各项财务指标,研究企业自身的经营状况与税收遵从风险之间的关系。Hglund[3]针对芬兰的欠税现象,构建了一类能够分析欠税的通用决策支持模型,综合考虑企业的偿债能力、流动性、付款周期等多方面信息,对企业潜在的欠税行为进行识别。Su等[4]构建了集成学习模型,通过营业利润、投资额、经营成本、净利润等多项财务指标对企业的欠税行为进行了分析。
根据税收契约理论,税收在本质上是所有纳税人与政府之间建立的一种契约,税收不遵从行为具有明显的违约行为特征,因此税收遵从风险也是一种广义的违约风险[5,6]。实证研究表明,企业的违约行为可能导致其关联的企业以更大的概率发生同类风险[7]。例如,美国银行业、汽车业和房地产业间存在着明显的违约风险传染现象[8]。陈作华[9]基于2212个我国上市企业样本研究了企业关联与避税行为之间的关系,结果表明异常关联交易是控股股东和上市公司掏空国家税收的重要途径,是公司避税的重要手段。在税收遵从风险的实践监管过程中,各种税收违法事件之间也体现出不同形式的关联,例如,2021年查处的湖南“1·23”增值税发票虚开案中,5名犯罪嫌疑人通过控制22家相关联的空壳公司虚开发票金额6亿元;杭州税务局在2020年通过某商贸公司的重大发票虚开疑点,一举查处62家违法关联企业。由此可知,包括税收遵从风险在内的违约风险能够在企业间关联传导,当前对于企业税收遵從风险的单点研究模式已不能充分反映风险的特征和变化规律。
因此对于税收遵从风险的研究,还需引入新的理念和工具方法,更加全面地分析不同主体之间的关联影响。知识图谱概念与方法的提出,恰好能够为税收遵从风险研究提供新的途径。本文基于网络数据建立税收遵从风险相关的知识图谱,并从群体关系角度研究企业税收遵从风险的内外部关联。研究试图达到以下目标:(1)引入先进的大数据分析理论与技术,丰富税收遵从风险研究的方法体系。(2)扩展税收遵从风险相关的研究框架,实现从单点研究向关联关系研究的延伸。(3)将税收遵从风险与其他类型的风险进行协同研究,在更广阔的研究视野下探讨不同风险之间的关联传导。
2 研究对象界定
税收遵从风险有基于企业和监管两个角度,本文主要针对后一种进行研究。从监管的角度出发,OECD将纳税遵从风险分为四类:(1)未正确登记纳税人数;(2)未按规定提交纳税文件;(3)未正确申报应纳税款;(4)未按期缴纳税款。根据OECD的调查,80%以上的风险为第三类和第四类风险,因此理论和实践上对这两类风险的关注程度也相对集中。
其中第三类风险更为隐性和复杂。对于这类风险的识别和研究,主要依据企业申报的财务数据及其他相关信息,结合一定的评价指标体系和算法,估算出企业的应纳税额,并将其与企业实际申报的纳税额进行比较,从而判断是否存在可能的税收遵从风险。此类研究存在以下困难:一是数据的真实性,企业提交虚假财务数据申报税款是逃税的主要手段之一,因此依据财务数据进行税收遵从风险分析结果可靠性较低。二是数据的可获得性,非上市公司的财务报表由企业自愿公开,工商、税务等政府部门中备案的企业财务报表也很难随意获取,因此在不具有大量合法授权的财务数据的情况下,第三类风险的相关研究很难开展。
第四类风险则更为直观和显性。一方面,欠税行为具有“发生即可感知”的明显特征,一经发生即可100%识别。另一方面,企业的欠税信息具有良好的可获得性和真实性,根据国家税务总局《欠税公告办法》,税务机关将按季度公告欠税企业的名称、纳税人识别号、法定代表人或负责人姓名、证件号码、经营地点、欠税税种、欠税余额和当期新发生的欠税金额,数据来源可靠,能够为第四类风险的研究提供充分的支撑。
综上分析,本文将从监管的角度,聚焦欠税行为对应的税收遵从风险,对企业间的欠税风险关联传导,及欠税风险和失信风险之间的关联传导进行分析。
3 税收遵从风险知识图谱构建
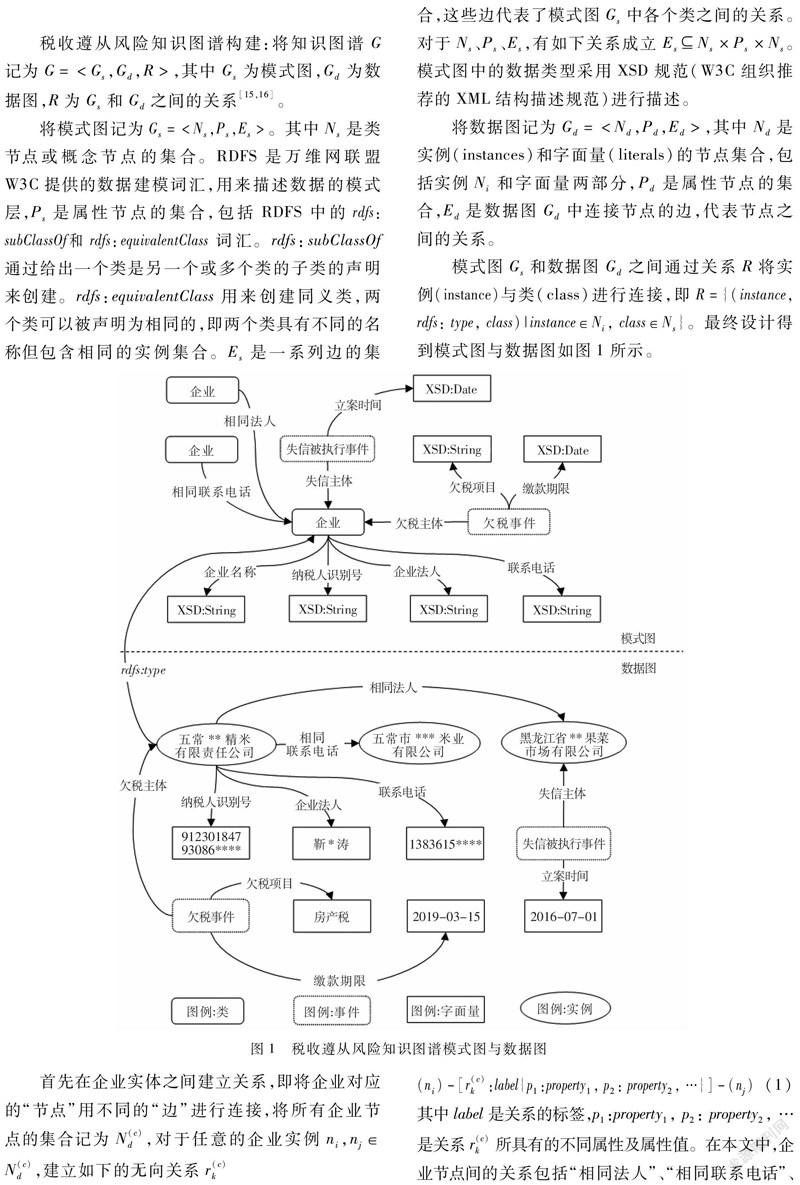
知识图谱(Knowledge Graph)通过图的形式来描述人、事物、概念等实体以及这些实体之间的关系。由于其同时包含了图的属性信息和结构信息,知识图谱对于现实世界中的复杂关系能够提供相对更好的表现方式[10]。在具体的知识图谱构建过程中,主要涉及模式图与数据图设计、知识抽取、知识图谱存储等环节[11,12]。
3.1 模式图与数据图设计
构建知识图谱有自顶向下和自底向上两种模式。自顶向下是通用知识图谱的主要模式,即先定义本体与数据模式,再将相应的实体加入图谱。自底向上是行业知识图谱的主要模式,即先从数据中提取实体,再进一步构建顶层的本体[13,14]。本文所要构建的知识图谱主要关注税收遵从风险,具有行业知识图谱的特征,因此选择自底向上的模式。
“相同法人”既包括了不同企业拥有相同法人,也包括同一企业拥有“相同法人”两种情形。同理,“相同联系电话”既包括了不同企业拥有相同联系电话,也包括同一企业拥有“相同联系电话”;“相同电子邮件”既包括了不同企业拥有相同电子邮件,也包括同一企业拥有“相同电子邮件”。为了避免混乱,后续将“相同法人”、“相同联系电话”、“相同电子邮件”均限定为不同企业间的关系,而对于上述同一企业拥有“相同法人”、“相同联系电话”、“相同电子邮件”的情形统一归为“相同企业”。此时式将变成如下形式
3.2 知识抽取
本文数据主要包括企业基本信息、风险事件信息、企业内外关联信息等,有直接的一级数据来源和间接的二级数据来源。其中一级数据来源主要为半结构化网页数据,涉及全国企业信用信息公示、中国裁判文书网、中国执行信息公开网、企业欠税信息公告等。二级数据来源主要为企查查、天眼查等数据服务商,他们对企业部分信息已进行较为系统的收集、清洗和整合,可以显著提高数据获取效率,但由于各厂商业务重点不同,数据往往不能覆盖全部研究需求。鉴于此,本文将采用一二级整合的数据采集方式:首先从天眼查、企查查等二级数据源采集已结构化或半结构化的数据,进一步从一级数据源抽取更为直接的原始数据作为补充,最终形成研究样本数据集合。
在数据获取技术方面,通常情况下优先考虑通过爬虫程序从网页上提取所需数据。对于允许自由爬取的非商業性的公开数据源(例如企业欠税公告、失信被执行案件信息等),方法成熟,不做进一步讨论。问题的难点是二级数据源知识抽取,数据服务商提供的企业信用报告为PDF格式,信息主要以表格的形式体现。但在PDF文件规范中并没有明确的内部表格表示方式,这为提取PDF的表格信息造成了技术障碍[17]。针对不同类型的PDF文件,研究者提出了多种表格提取方法[18,19],开发了多种表格识别工具,camelot是其中具有代表性的一种[20]。
然而开源工具camelot对于PDF中跨多个页面的较大表格,只能识别出表格首页信息。而批量获取的企业信用报告中,大量的信息以跨页表格的形态呈现,camelot并未提供有效的处理方法。因此,需要对camelot算法做出进一步的改进与优化。方法要点如下:
(1)分析所要提取表格的具体特征,利用章节标题对表格进行定位。例如,对于失信被执行人的列表,将其所在章节标题“失信被执行人”作为表格开始标记,将其后续章节标题“限制高消费”作为表格终止标记。(2)明确表格定位算法之后,采用如下方法逐页识别表格:对于第i页文件,先在页面中搜索表格起始标记(本例中为“失信被执行人”字段),如果发现该标记,则获得表格起始页码page_start和表格在该页的定位坐标。继续向后搜索表格结束标记(本例中为“限制高消费”字段),如果发现该标记,则获得表格结束页码page_end和表格在该页的定位坐标,并结束搜索。(3)基于NumPy的开源Python库Pandas对数据进行分析,并用Pandas的DataFram储存获取的表格内容数据,采用Pandas库中的cancat方法进行合并。
基于上述要点,可以给出算法优化关键流程,具体如图2所示。
3.3 知识图谱的存储
知识图谱常用的存储方式有关系型数据库和图数据库。选用关系型数据库时,需要将数据中的关系分解为多个三元组形式,并将三元组与关系表进行映射,然后将关系表存储在关系型数据库中。具体可以采用三元组表、整合存储、分割存储等映射存储方式,但这些方式会导致查询时运算请求的大幅增长,及后期更新和维护难度的增加[10]。
图数据库是一种以节点和关系(连接节点的边)为基础结构的数据库,基于图的结构数据存储实体以及实体间的关系[21]。不同于关系型数据库,图数据库节点之间的关系无需通过大量连接查询关联节点“计算”,而是直接“读取”出来的,效率大幅提升。本文采用图数据库Neo4j实现知识图谱的存储与查询。基于图结构,Neo4j只需从起始节点开始,遍历节点的邻边就能够实现对所有关联节点的访问。最终形成的知识图谱可视化效果如图3和图4所示。
鉴于所构建的知识图谱规模较大,本文选择部分子图进行展示。图3为包含392个企业节点的图谱以及其中四个节点构成的子图。图4为包含2000个风险事件节点的图谱以及其中三个节点构成的子图。
4 基于知识图谱的税收遵从风险关联数值分析
4.1 风险关联判定指标计算
从企业特征设定角度,研究涉及的企业基本信息包括20余项,其中能较为直接地作为企业之间关系的包括纳税人识别号、企业名称、法定代表人、所属省市地区、联系电话、电子邮件地址、企业类型、所属行业、企业地址、经营范围等10项。通过所属省市地区、企业类型、所属行业所建立起的企业关联过于宽泛,导致图谱的复杂性大幅增加,但实质上有价值的关联信息却未得到明显体现。企业地址、经营范围信息条目中的内容较为复杂,不同企业间能够相互匹配的情形很少,构建出的关系数量不足以支撑研究。因此,研究主要选取纳税人识别号、企业名称、法定代表人、联系电话、电子邮件地址等信息,构建“相同企业”、“相同法人”、“相同联系电话”、“相同电子邮件”等关系,作为研究的主要关注点。
从时间范围设定角度,一方面,理论研究表明,不同企业之间风险的关联存在不同程度的潜伏期[22];另一方面,从实践数据来看,能够相互关联传导的违约风险,90%的传导潜伏期都不超過12个月[23]。因此将欠税事件与欠税事件、欠税事件与失信被执行事件之间的关联传导潜伏期限定在12个月(365天)以内(即|Δt|365天)。
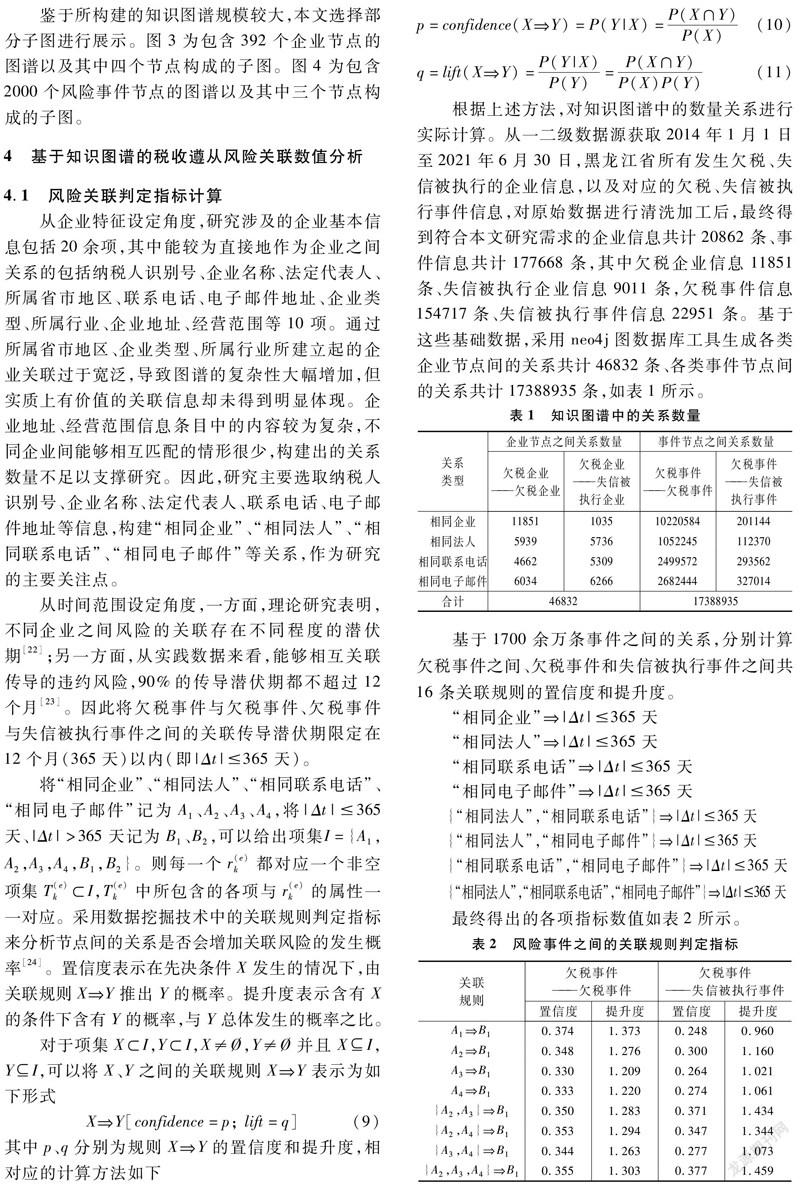
根据上述方法,对知识图谱中的数量关系进行实际计算。从一二级数据源获取2014年1月1日至2021年6月30日,黑龙江省所有发生欠税、失信被执行的企业信息,以及对应的欠税、失信被执行事件信息,对原始数据进行清洗加工后,最终得到符合本文研究需求的企业信息共计20862条、事件信息共计177668条,其中欠税企业信息11851条、失信被执行企业信息9011条,欠税事件信息154717条、失信被执行事件信息22951条。基于这些基础数据,采用neo4j图数据库工具生成各类企业节点间的关系共计46832条、各类事件节点间的关系共计17388935条,如表1所示。
基于1700余万条事件之间的关系,分别计算欠税事件之间、欠税事件和失信被执行事件之间共16条关联规则的置信度和提升度。
最终得出的各项指标数值如表2所示。
4.2 风险关联程度分析
(1)“欠税事件——欠税事件”的关联
这一组别中,提升度最大的是A1B1,提升度为1.373。意味着节点之间存在“相同企业”关系时,欠税风险关联传导的潜在发生概率提升了37.3%。这一结果可以解释为:欠税风险更容易在企业内部产生关联传导,已经欠税的企业更容易在1年内再次欠税。
该组别其他关联规则提升度均超过1.2,“相同法人”、“相同联系电话”、“相同电子邮件”中的任意一个或多个关系的存在,皆使欠税风险在不同企业之间关联传导概率增加20%以上,且多个关系的组合比单一关系对关联传导的提升更为显著。
以上结论与已有“会计欺诈风险关联”的研究结论类似[25]。“相同企业”、“相同法人”、“相同联系电话”、“相同电子邮件”对欠税风险在企业内部或者企业之间的关联传导具有较为明显的解释能力或支持作用。
(2)“欠税事件——失信被执行事件”的关联
这一组别中,最小和最大的提升度分别为0.960和1.459,对应的关联规则分别是A1B1和(A2,A3,A4)B1。
A1B1提升度小于1意味着已经欠税的企业发生失信被执行事件的概率更小,这一结论似乎有悖于常情。然而政府监管力量使得该现象在现实中却是成立的。我国对税收违法行为实施了系统的、广泛的联合惩戒措施,对欠税企业的经营、投融资、银行授信、进出口审批、工程招投标、参加政府采购、申请生产许可等多方面活动进行了不同程度的限制,由此减少了相关失信事件的发生。监管力量的介入在不同程度上切断了欠税风险与失信风险在企业内部的关联传导,最终使得企业欠税后失信事件发生概率反而降低。
综合分析该组别除A1B1以外的其他7条关联规则,我国在对欠税、失信等事件进行监管惩戒时,其范围大多覆盖了欠税、失信企业本身以及法定代表人,较少牵涉到法定代表人名下的其他企业。即对于欠税、失信等事件,政府等外部监管力量并不会通过“相同法人”、“相同联系电话”、“相同电子邮件”等关系进行延伸。“相同法人”、“相同联系电话”、“相同电子邮件”均能提升欠税风险和失信风险在不同企业间的关联概率。但单一的关系对于关联的影响较弱,两种或两种以上关系组合提升效果较为明显,尤其是三个关系同时存在时,欠税风险和失信风险在不同企业间关联概率的提升幅度最大,高达45.9%。
5 结论与启示
本文通过挖掘整合多源数据,构建了企业税收遵从风险的知识图谱,并通过这一图谱研究了以欠税风险为代表的税收遵从风险在企业内外部的关联传导问题,得到如下结论:(1)税收遵从风险并不孤立存在,在不同企业之间,税收遵从风险与其他类型风险(失信风险)之间都表现出不同程度的关联传导特征。(2)同一企业内,不同税收遵从风险之间关联传导特征较为明显,发生过欠税事件的企业更容易再次欠税。企业发生欠税行为后,以税收违法联合惩戒为典型代表的外部监管力量的介入,使企业的银行授信、参与招投标等经营活动受到不同程度的限制,从而减小了失信行为的发生概率。因此税收遵从风险与失信风险之间存在负向关联的特征。(3)不同企业间,相同法人代表、相同联系方式(电话、电子邮件)均能在不同程度上提升企业间税收遵从风险的关联传导程度,同时也能提升企业间税收遵从风险和失信风险的关联传导程度。企业间的关系数量越多,关联传导的提升程度越大。
本文研究的政策启示:税收遵从风险在不同企业之间,税收遵从风险与其他类型风险之间皆存在关联传导可能性,税务机关对市场主体监督管理时需要对这一现象进行关注并采取相应措施。在拥有充分数据支持的前提下,监管部门可利用知识图谱等工具充分挖掘企业之间的各类关系,从孤立的企业税收遵从风险防范推进为相关风险的全局把控,有助于实现保障国家财政收入、提高税收征管水平、降低税收监管成本等多方面的税收遵从风险管理目标。
参 考 文 献:
[1] 李晓曼.税收遵从风险管理[M].北京:电子工业出版社,2016.7-10.
[2] Alm J, Bahl R, Murray M N. Tax structure and tax compliance[J]. The Review of Economics and Statistics, 1990, 72(4): 603-613.
[3] Hglund H. Tax payment default prediction using genetic algorithm-based variable selection[J]. Expert Systems with Applications, 2017, 88: 368-375.
[4] Su A, He Z, Su J, et al.. Detection of tax arrears based on ensemble learning model[A]. Proceedings of the 2018 International Conference on Wavelet Analysis and Pattern Recognition[C]. Piscataway, NJ, 2018. 270-274.
[5] Lukason O, Abdresson A. Tax arrears versus financial ratios in bankruptcy prediction[J]. Journal of Risk and Financial Management, 2019, 12(4): 187-200.
[6] 蔡昌.税收原理[M].北京:清华大学出版社,2010.256-259.
[7] 李永奎,周宗放.基于小世界网络的企业间的关联信用风险传染延迟效应[J].系统工程,2015,33(9):74-79.
[8] 赵微,刘玉涛,周勇.金融风险中违约传染效应的研究[J].数理统计与管理,2014,33(6):983-990.
[9] 陈作华.关联交易与公司避税——来自中国上市公司的经验数据[J].证券市场导报,2017,(5):21-31.
[10] 黄恒琪,于娟,廖晓,等.知识图谱研究综述[J].计算机系统应用,2019,28(6):1-12.
[11] 陈晓军,向阳.企业风险知识图谱的构建及应用[J].计算机科学,2020,47(11):237-243.
[12] Song D, Schilder F, Hertz S, et al.. Building and querying an enterprise knowledge graph[J]. IEEE Transactions on Services Computing, 2019, 12(3): 356-369.
[13] 徐增林,盛泳潘,贺丽荣,等.知识图谱技术综述[J].电子科技大学学报,2016,45(4):589-606.
[14] 楊玉基,许斌,胡家威,等.一种准确而高效的领域知识图谱构建方法[J].软件学报,2018,29(10):2931-2947.
[15] Ruan T, Xue L, Wang H, et al.. Building and exploring an enterprise knowledge graph for investment analysis[A]. International Semantic Web Conference 2016[C]. Springer, Cham, 2016. 418-436.
[16] Lee J, Park J. An approach to constructing a knowledge graph based on Korean open-government data[J]. Applied Sciences, 2019, 9: 1-12.
[17] Zanibbi R, Blostein D, Gordy J R. A survey of table recognition: models, observations, transformations, and inferences[J]. Document Analysis and Recognition, 2004, 7(1): 1-16.
[18] Khusro S, Latif A, Vllah I. On methods and tools of table detection, extraction and annotation in PDF documents[J]. Journal of Information Science, 2015, 11(1): 41-57.
[19] Shigarov A, Mikhailov A, Altaar A. Configurable table structure recognition in untagged PDF documents[A]. 2016 ACM Symposium on Document Engineering[C]. Association for Computing Machinery, New York, 2016. 119-122.
[20] Fayyaz N, Khusro S, Ullah S. Accessibility of tables in PDF documents[J]. Information Technology and Libraries, 2021, 40(3): 1-20.
[21] Angles R, Gutierrez C. Survey of graph database models[J]. ACM Computing Surveys, 2008, 40(1): 1-39.
[22] 徐凯,周宗放,钱茜.考虑潜伏期的关联信用风险传染机理研究[J].运筹与管理,2020,29(3):190-197.
[23] 薛银.基于关联关系的企业风险模型[J].金融电子化,2021,(4):74-76.
[24] Han J, Kamber M, Pei J. Data mining concepts and techniques[M]. San Francisco: Morgan Kaufmann, 2012. 243-247.
[25] 陈强,代仕娅.基于金融知识图谱的会计欺诈风险识别方法[J].大数据,2021,7(3):116-129.
3741500338290
