一种基于MCDDL算法的SDN多控制器部署策略研究
2022-03-11刘向举方贤进徐杨洋
刘向举,赵 犇,方贤进,徐杨洋
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
随着人们对网络需求的爆炸性增长,对传统网络提出了新的挑战.传统网络体系结构由于模块之间的耦合度过高、系统扩展性差、不能灵活地进行分布式部署以及管理层面所存在的种种不足[1].在此背景下,一种集中控制的新型网络体系架构软件定义网络(Software Defined Network,SDN)[2]应运而生.SDN设计之初只需要单个控制器就可以管理网络的全局信息,但随着网络规模的快速增长,SDN单控制器的弊端开始显现出来,已很难满足当前流量的需求,于是提出了逻辑上集中、物理上分布的多控制器部署方案[3].控制器部署得不合理会导致资源的浪费以及降低网络用户的体验,因此对控制器位置进行合理地部署显得尤为重要[4].与单控制器管理全局网络相比,多控制器部署可以减少交换机到控制器之间的时延,同时SDN网络的负载均衡、容错性强更容易实现.
目前,已有很多学者针对SDN多控制器部署问题进行了相关的研究.Heller等[5]首次提出了多控制器部署问题,并证明多控制器部署问题是一个NP-hard问题,文章研究了在给定网络拓扑中控制器的部署位置以及控制器管理哪些交换机,定义了平均时延和最坏时延并以此为目标,使用贪婪算法对控制器的最佳部署位置进行选取.实验证明文中部署位置比随机算法的部署位置更能有效地降低平均延迟与最坏时延,为SDN多控制器部署问题的研究奠定了基础.Wang等[6]提出了一种改进的K-means算法,引入质心和中心两个概念对K-means算法的初始聚类中心进行了选取,克服了K-means算法初始聚类中心选取的随机性,然后通过对网络进行合理的划分,实现最坏时延最小化.但是该算法只考虑了最坏时延,导致负载均衡度不理想.Li等[7]提出了一种基于粒子群优化的亲和传播算法,解决了偏参数与收敛系数初始值对聚类过程的影响,实现多控制器的均衡部署,但未考虑传播时延,并不适应用于链路很长的实际网络拓扑情况.胡涛等[8]设计了双向匹配的多控制器部署算法.通过收集网络链路中的跳数、时延以及流量信息,分别构建交换机和控制器的匹配列表.再根据匹配列表中元素的具体排序,设计一种互选策略,由交换机和控制器从其列表中选择最优的元素依次进行匹配,直到实现分布式网络的构建.Tao等[9]定义了交换机权重、交换机到控制器的路由成本以及控制器路由成本的总流量请求成本,提出了控制器的负载平衡因子,在已知控制器数量的情况下,通过最小化负载平衡因子和总流量请求成本的线性函数来确定控制器的位置,该方法实现了控制器间的负载均衡,但是未考虑交换机到控制器之间平均时延与最坏时延.赵文文等[10]以负载均衡度、平均时延和可靠性为优化指标,提出了基于模拟退火算法(Simulated Annealing,SA)与遗传算法相结合的控制器均衡部署算法,增强解空间的全局搜索能力,保证控制器负载均衡度的同时,降低网络的平均时延,但是文章未考虑最坏时延对网络的影响.赵季红等[11]通过对社区检测算法进行改进实现SDN多控制器部署策略,根据节点相似度对Louvain算法中的链路权重进行重新定义并引入负载均衡度限制每个子网络的节点数量,缩小社区间节点数量的差异从而减低平均传播时延并使控制器保持负载均衡.Li等[12]将改进的离散布谷鸟搜索算法应用到多控制器部署问题中,通过布谷鸟算法具有全局搜索特点避免陷入局部最优从而达到全局最优,进而实现平均时延和最坏时延两者之间的平衡,但是文中未考虑控制器的负载均衡.Zhu等[13]联合考虑了交换机与控制器之间和控制器与控制器之间的控制平面时延问题,并将控制器放置问题转化为交换机和控制器关联约束的控制器平面时延最小化问题,提出了一种基于K-means的启发式算法实现控制平面时延最小化,但是文章中的网络拓扑是随机产生的.
上述模型主要注重平均时延、最坏时延或者负载均衡中的一个或两个,目前很少有文献资料同时考虑到平均时延、最坏时延和负载均衡3个要素的情况下又考虑网络的联通性.基于上述研究方面的不足,提出一种基于时延和负载的多控制器部署方案(Multi Controller Deployment based on Delay and Load,MCDDL).MCDDL算法首先采用改进的基于密度峰值的快速聚类(Clustering by Fast Search and Find of Density Peaks,CFSFDP)算法[14]进行初始聚类中心的选取;然后使用改进的K-means算法进行迭代聚类,迭代聚类后通过SA算法[15]对结果进行优化;最终得到交换机与控制器之间的映射关系.最后通过真实网络拓扑进行仿真实验,实验结果表明该算法能够有效地降低交换机和控制器之间平均时延与最坏时延,同时保持良好的控制器负载均衡.
1 问题模型
对于确定的网络场景,SDN多控制器部署应该满足以下两个条件.
1) 降低平均时延与最坏时延.当交换机接收到一个新的数据包时,由于交换机中的流表中没有对应的转发规则,交换机需要向控制器发送流安装请求,然后等待控制器回应安装请求;这个时间段产生的时间就是时延.如果SDN网络中流安装的时间长则会降低网络的实用性,因此降低平均时延与最坏时延可以提高网络的服务质量[16].
2) 负载均衡.SDN多控制部署中,每个控制器管理自己区域下的交换机,负责该区域中所有交换机的流安装请求.控制器管理交换数量的不合理会导致时延增加.因此应使各控制器管理交换机的数量尽可能地相近.

控制器ci到交换机vj之间的时延主要由传播时延、处理时延与传输时延组成.
定义1控制器ci到交换机vj之间的总时延为Dij:
D(ci,vj)=LK+LT+LV,
(1)
其中LK是控制器到交换机的传播时延,LK=d(ci,vj)/vc,d(ci,vj)表示控制器ci到交换机vj之间的最短距离,vc=3×108表示数据在链路中的传输速率.LT是数据包的传输时延LT=Pl/Bv,传输时延指一个交换机传输一个数据包所需要时间,Pl表示数据包的长度,Bv表示网络链路的最小传输速率.LV是交换机的处理时延,该时延受交换机处理速率的影响.其中控制器的部署位置在网络节点上,并与该节点交换机之间的时延为0.
定义2平均时延Dave是交换机到其控制器总时延之和的平均值.
(2)
其中xci,vj表示控制器与交换机之间的映射关系,每台交换机只能由一台控制器控制,xci,vj=1表示交换机vj连接到控制器ci,否则xci,vj=0.
定义3最坏时延Dwc是交换机v到其控制器C最大时延,
(3)
定义4负载均衡度BL是衡量控制器负载差异情况,本文采用概率学中的标准差表示负载均衡度.
(4)
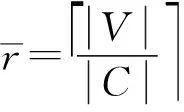
基于上述分析,对于网络拓扑G=(V,E),得到在控制器数量确定的网络拓扑中SDN多控制器部署问题是一个多目标优化求解问题,为了简化求解多目标问题,本文将多目标优化问题简化为单目标优化问题,待优化目标函数obj为式(5),其中α+β+ε=1且α,β,ε∈[0,1].
obj=αDave+βDwc+εBL.
(5)
2 MCDDL算法
2.1 初始聚类中心的选取
对于含有n个网络节点进行分类,其本质上就是通过聚类进行合理的网络划分.K-means算法将n个数据划分成k个不同的簇,使得每个簇内的相似度尽可能高,不同簇之间的相似度尽可能低.K-means算法的实现过程简单方便,收敛速度快,对于大多数数据都有较好的分类效果,但K-means算法的初始聚类中心是随机选取的,初始聚类中心的选取不同会导致聚类结果的不同.为此,MCDDL算法通过改进的CFSFDP算法进行初始聚类中心的选取.
CFSFDP算法具有灵活性好,能够识别各种不同形状的类簇,并且对初始值不敏感等特点,因此在聚类初始中心的选取上有很好的效果.但CFSFDP算法是通过欧式距离作为两点之间的距离,然后通过构造距离矩阵进行节点之间的密度和距离的计算,欧式距离使用的是两点之间的直线距离,不能保证两节点之间一定存在物理链路,因此本文通过构造最短传播时延矩阵代替原始的欧氏距离对CFSFDP算法进行改进.
定义5最短传播时延矩阵N.
首先通过Dijkstra算法计算网络中任意两点之间的距离d(vp,vq)=Dijkstra(p,q),然后通过传播时延公式LK=d(vp,vq)/vc得到任意两点之间的最短传播时延.根据节点间最短时延构造最短传播时延矩阵,如式(6).
(6)
其中1≤p,q≤n且p≠q,LK(vp,vq)为交换机vp和交换机vq链路之间的最短传播时延.
CFSFDP算法中节点Vp的局部密度ρ有两种计算方法,截断核(Cut-off Kernel)和高斯核(Gaussian Kernel),当数据点为离散值时使用截断核,局部密度ρ如式(7).
(7)
当数据点为连续值时,使用高斯核,局部密度ρ如式(8).
(8)
其中参数dc>0为截断距离(Cutoff distance),是一个超参数,是密度峰值聚类中的重要阈值,文中提到dc取值为将最短传播时延从小到大排序后前2%~5%,当LK(vp,vq)
δ表示数据点与密度较大点间的最小距离,如式(9).
(9)
其中,当节点Vp为最大的局部密度时,δp表示网络拓扑中与节点Vp传播时延最大的拓扑节点与节点Vp之间的传播时延,当节点Vp不是最大的局部密度时,δp表示在在网络拓扑中所有局部密度大于节点Vp并且与节点Vp之间传播时延最小的节点之间的距离.
综上所述,初始聚类中心选取算法概述如下.
步骤1 通过Dijkstra算法得到网络拓扑中任意两点之间的最短距离,然后求出任意两点之间的最短传播时延并构造最短传播时延矩阵N.
步骤2 通过确定dc值与最短传播时延矩阵计算每个节点的局部密度ρ和距离δ.
步骤3 将节点密度进行降序排列.
步骤4 对于局部密度ρ最大的节点,则将传播时延设为最大.如果不是密度最大的节点,则寻找比自己密度大且传播时延最小的节点.
步骤5 对每个节点的局部密度ρ和比自己密度大且传播时延最小的δ进行归一化.
步骤6 通过γ=ρ×δ得到每个节点的综合评分.
步骤7 对节点评分γ进行降序排,得到聚类初始中心.
2.2 节点分类与优化
根据改进的CFSFDP算法进行初始聚类中心的选取之后,下一步对网络节点进行分类.K-means算法在对网络拓扑进行聚类的过程中使用的是欧式距离作为两节点之间的相似度.基于欧式距离的局限性,因此MCDDL算法的节点分类采用最短传播时延代替欧式距离作为K-means算法中任意两点之间的相似度,两个节点之间的传播时延越小则节点之间的相似度越大,否则节点之间的相似度越小.
sim表示结点间的节点相似度.
(10)
其中Ci和vj是聚类中心和样本,也就是控制器部署位置Ci和控制器管理的交换机集合vj.N是式(6)最短传播时延矩阵.根据传播时延最小的聚类中心确定节点vj的簇标记,并将节点vj划入相应的簇Ri中,Ri=Ri∪{vj}.
在聚类的过程中,将每次聚类中计算的新均值向量ci′作为新聚类中心.
(11)
其中ci′为簇Ri新的均值向量,|Ci|是第i个聚类中心的样本总数,即ci′是新的控制器部署位置,|Ci|为控制器管理交换机的个数.通过对比新的部署位置和旧的部署位置是否一致判断是否进行新的一轮迭代,如果新的部署位置和上一轮旧的部署位置不一致,则重新计算控制器到各交换机之间的传播时延,然后根据传播时延最小的聚类中心进行划分.如果新的部署位置和上一轮旧的部署位置一致,则不再进行重新计算,并将本次分类结果进行输出.
K-means算法在迭代过程中对噪点敏感,在迭代聚类过程中可能陷入局部最优.因此得到聚类结果后,通过SA算法对聚类结果进行优化.SA算法通过设置初始温度,在退火前生成一个初始解,以初始解为初始状态进行干扰,模拟粒子在不同温度下移动状态,根据不同温度产生不同的新解,再对比新旧解,从而选取最优解,在新解的选取过程中采用Metropolis准则.Metropolis准则以一定的概率接收新的状态,即SA算法不仅以概率为1接收最优解,而且以一定的概率接收比当前解差的解,因此可以有效的跳出局部最优,从而实现全局最优解.

图1 MCDDL 算法流程图Fig.1 Flow diagram of MCDDL algorithm
Metropolis准则定义SA算法在物体的某一温度T下从当前状态obj(old)转化为新状态obj(new)下的概率.
(12)
其中e是自然对数,当前状态obj(old),新状态obj(new),Δ=obj(new)-obj(old).T表示初始温度.当obj(new)≤obj(old)时,该算法以概率为1接收新状态obj(new),当obj(new)>obj(old)时,该算法以概率为e-(Δ/T)接收新状态obj(new),从而有效地避免算法陷入局部最优.
节点迭代分类算法概述如下.
步骤1 通过改进的CFSFDP算法得到初始的聚类中心.
步骤2 通过调用K-means算法和最短传播时延矩阵以初始聚类中心进行迭代聚类,确定节点vj的簇标记.并将节点vj放入相应的簇中.
步骤3 通过式(5)计算目标函数obj,通过SA算法对目标函数obj以Metropolis准则进行调整,同时按照SA算法以退火速率降低该概率值.在进行多次退火后,结束退火调整,并对结果进行记录,最终得到目标函数值最小的分类结果.
步骤4 输出控制器与交换机之间的映射关系.
2.3 MCDDL算法流程及算法复杂度分析
MCDDL算法采用CFSFDP算法对初始聚类中心进行选取,K-means进行迭代聚类,SA算法对目标函数进行优化得到最佳的控制器部署结果.MCDDL算法流程图如图1所示.MCDDL算法伪代码如表1所示.
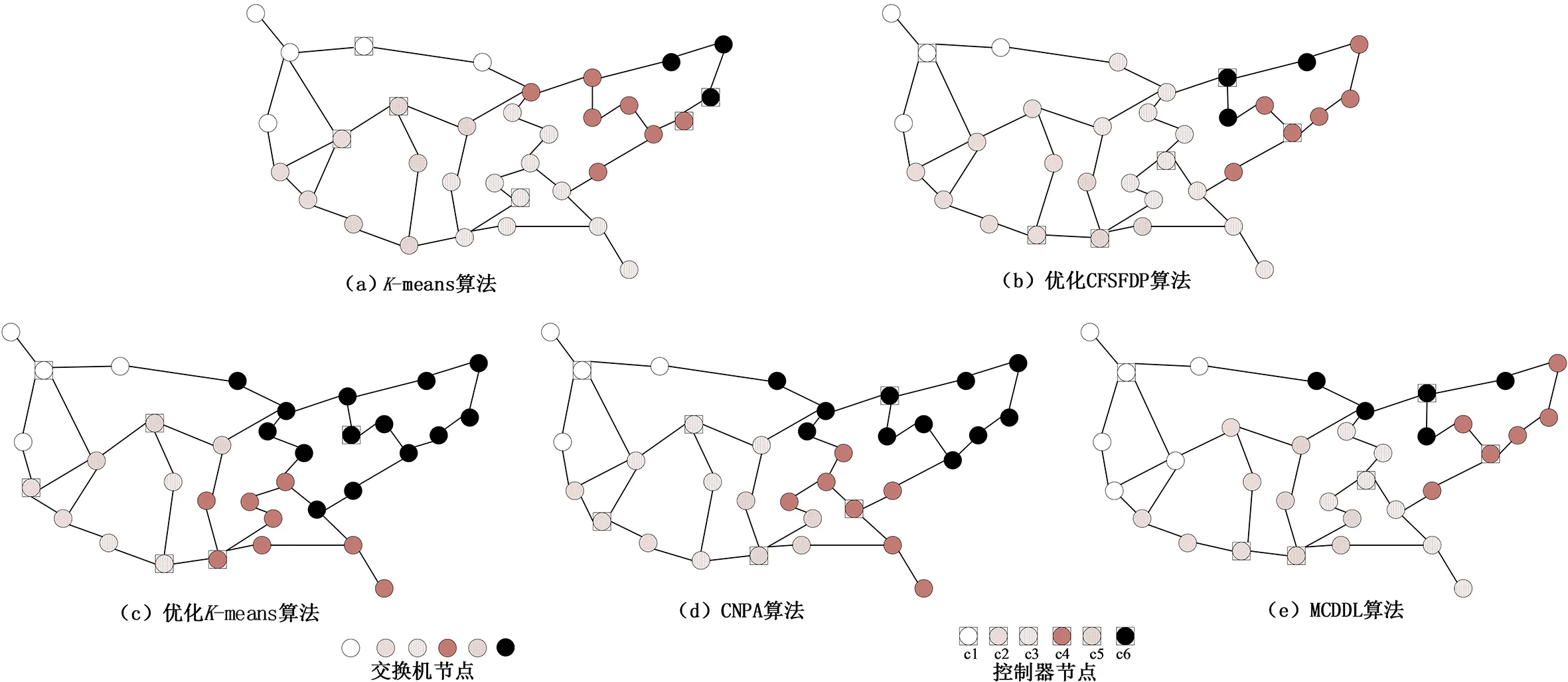
MCDDL算法首先通过Dijkstra算法计算两点之间的最短传播时延,然后通过CFSFDP算法得到初始聚类中心,时间复杂度为O(N2),K-means算法的时间复杂度是O(mkN),其中m是样本维数,k是类别维数;而SA算法主要与初始温度T0、离开温度Tend、温度衰减系数a有关,时间复杂度为O(l) 选取真实网络拓扑Internet2 OS3E[17](Open Science,Scholarship and Services Exchange)进行仿真实验,Internet2 OS3E网络拓扑被广泛用于SDN多控制部署问题,该拓扑具有34个节点与42条边,网络中的所有节点相互独立并都具有部署控制器与交换机的能力.实验采用Mininet来模拟SDN网络环境,Ryu控制器作为实验控制器.选取平均时延的权重α=0.4,最坏时延的权重β=0.3,负载均衡度的权重ε=0.3.使用Python语言编写控制器部署算法.实验机器配置为Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz,16.0 GB RAM,装载ubuntu-16.04.7 4.0GB操作系统. 表1 MCDDL算法伪代码Tab.1 MCDDL algorithm pseudo code 图2 Internet2 OS3E网络拓扑子域规划结果Fig.2 Internet2 OS3E network topology subdomain planning results 通过对比K-means算法、优化CFSFDP算法、优化K-means算法[6]、CNPA(Clustering-based Network Partition Algorithm)算法[6]以及MCDDL算法在Internet2 OS3E网络拓扑上的网络规划能力. 在SDN网络划分过程中,每台控制器管理的交换机数量越接近,则网络划分得越合理,控制器负载越均衡.以6个控制器为例,在Internet2 OS3E网络拓扑中部署6个相同容量的控制器,每种算法的控制器位置及其管理交换机的位置如图2所示,为了更清晰地对比不同算法对网络划分的效果,对网络划分的实验结果进行比较,如图3所示.与MCDDL算法相比,其余4种算法的网络划分的每个子域中交换机数量相差很大,交换机最多的子域数量是交换机最少的子域数量的3倍以上,而MCDDL算法能够实现交换机在各子域的均衡部署. 图3 5种算法各控制器管理交换机数量对比Fig.3 Comparison of the number of switches managed by each controller of the five algorithms 根据定义4计算5种算法在控制器个数为k=4、5、6时负载均衡度,如图4所示. 在相同的控制器情况下,其余4种算法控制器管理的交换机数量相差最大.其中K-means算法的负载均衡度好于其他3种算法,是因为K-means算法是运行多次选取其负载均衡度最低的一次.优化CFSFDP算法和MCDDL算法的初始聚类中心相同但是由于迭代聚类未对噪声进行处理,导致负载均衡度较大.优化K-means算法在确定初始聚类中心后使用K-means算法进行网络分区,该算法在k=5时网络分区负载均衡度最好,k=4与k=6时效果不理想,因为优化K-means算法在部署控制器时,主要考虑交换机与控制器之间的最坏时延,从而导致控制器管理交换机数量差异较大.CNPA算法的负载均衡度好于其他3种算法,但依旧比MCDDL算法略差.MCDDL算法在控制器数量k=5时负载均衡度小于优化K-means算法以外,其余情况均优于另外4种算法,这是因为本文的初始聚类中心选取与聚类迭代和优化过程更加合理. 通过仿真实验对链路时延进行检测并记录,根据定义5和定义6计算得到交换机到控制器的平均时延与最坏时延,对比控制器个数k=4、5、6时,K-means算法、优化CFSFDP算法、优化K-means算法、Proposed算法[18]以及MCDDL算法的平均时延与最坏时延,结果如图5、图6所示. 图4 5种算法的负载均衡度 图5 5种算法平均时延的对比 图6 5种算法最坏时延的对比 K-means算法虽然负载均衡度比其他3种算法更好,但是平均时延比其他4种算法相比最高,最坏时延除k=4时比优化CFSFDP算法略低以外,均比其他算法高.k=4、5、6时,K-means算法平均时延为5.6、4.8、4.6 ms,最坏时延为13.2、12.9、13.1 ms,MCDDL算法平均时延为3.6、3.5、2.9 ms,K-means算法平均时延比MCDDL算法至少高出26.7%,最坏时延比MCDDL算法至少高出22.2%,主要原因是该算法在聚类迭代过程中使用的是欧式距离,未考虑网中两节点之间是否存在物理链路.优化CFSFDP算法平均时延为5.2、4.4、4.2 ms,最坏时延为14.9、11.3、11.1 ms,该算法比MCDDL算法在平均时延方面高出20.7%,在最坏时延方面比MCDDL算法高出19.3%,是由于空间密度分布的不均匀使聚类结果不均衡,导致平均时延与最坏时延较高.优化K-means算法在最坏时延方面和平均时延都比MCDDL算法略高,且当k=6时甚至比k=4时的平均时延还要高,这是因为k=6时优化K-means算法的网络划分不均衡,导致平均时延过高,但是依旧比随机选取初始点的K-means算法要好.Proposed算法平均时延为4.4、4.2、4.0 ms,最坏时延为9.5、9.0、8.7 ms,Proposed算法在最坏时延方面和MCDDL算法持平并且在k=4时好于MCDDL算法,但也仅仅高出约6.8%,但是在平均时延方面比MCDDL算法高出16.6%. 研究了SDN网络架构中的多控制器部署问题.通过对SDN时延进行分析,提出了一种MCDDL算法对网络进行合理划分,将网络划分为若干子网络,缩短了交换机到控制器的平均时延、最坏时延并降低了控制器负载均衡指数.仿真实验结果表明本论文算法能有效降低SDN多控制器部署问题中的平均时延、最坏时延并且负载更加均衡.但是SDN网络环境运行过程可能会出现网络设备或链路故障导致控制器与交换机失联[19],下一步将围绕设备故障与链路的可靠性两方面进行研究.3 仿真实验与分析
3.1 实验环境

3.2 网络规划实验

3.3 负载均衡实验
3.4 平均时延与最坏时延实验

4 结语
