基于用户画像技术的商品推荐研究与实现
2022-03-11王国珺
王国珺
(福州职业技术学院 福建 福州 350000)
0 引言
所谓推荐算法就是利用用户的一些行为,通过一些数学算法,推测出用户可能喜欢的东西。大数据推荐算法最早源于国外对于Hadoop系统的算法优化,Pessemier在2011年便着手研究在Hadoop系统和Mapreduce框架下的推荐算法,推荐算法也第一次在大数据环境下进行相关理论研究和数据测试[1]。
常见的推荐方法很多,但当前最流行的两种方法是基于内存的过滤和协同过滤。其中内容的过滤,主要是获取物品或用户的属性信息及某种相似度定义,通过相同的相似度定义来与物品或用户进行匹配。而协同过滤主要是依靠以往的行为,例如已有的评级或交易,这里的评级包括用户对物品的显示评级和隐式评级,认为过去表现出相似偏好的用户在未来偏好也会类似。
ALS算法是基于模型的推荐算法,基本思想是对稀疏矩阵进行模型分解,评估出缺失项的值,以此来得到一个基本的训练模型,然后依照此模型可以针对新的用户和物品数据进行评估。ALS是采用交替的最小二乘法来算出缺失项的,交替的最小二乘法是在最小二乘法的基础上发展而来的。
本案例采用协同过滤方法的ALS算法实现商品推荐。
1 基于大数据仓库用户画像的业务研究
在数据仓库业务中,事实表中放研究对象,维度表中放一般事实的属性。关于业务研究主要分为以下4个步骤:
1.1 选择业务过程
业务过程是由组织完成的微观活动,例如,获得订单、开具发票、接收付款、处理服务电话、注册学生、执行医疗程序、处理索赔等。业务过程包含以下公共特征,理解它们将有助于区分组织中不同的业务过程:业务过程通常用行为动词表示,因为它们通常表示业务执行的活动。与之相关的维度描述与每个业务过程事件关联的描述性环境。
•业务过程通常由某个操作型系统支撑,例如,账单或购买系统。
•业务过程建立或获取关键性能度量。有时这些度量是业务过程的直接结果,度量从其他时间获得。分析人员总是想通过过滤器和约束的不同组合,来审查和评估这些度量。
•业务过程通常由输入激活,产生输出度量。在许多组织中,包含一系列过程,它们既是某些过程的输出,也是某些过程的输入。
1.2 声明粒度
声明粒度意味着精确定义某个事实表的每一行表示什么。粒度传递的是与事实表度量有关的细节级别。它回答 “如何描述事实表中每个行的内容” 这一问题。粒度由获取业务过程事件的操作型系统的物理实现确定。
典型的粒度声明如下:
•机场登机口处理的每个登机牌采用一行表示
•仓库中每种材料库存水平的每日快照采用一行表示
声明粒度是不容忽视的关键步骤。如果不能清楚地定义粒度,整个设计就像建立在流沙之上,对候选维度的讨论处于兜圈子的状态,不适当的事实将隐藏在设计中。不适当的维度始终笼罩着DW/BI实现。设计组的每个人都要对事实表粒度达成共识,这一点非常重要。
业务过程确定后,设计小组将面临一系列有关粒度的决策。明确在维度模型中应该包含哪个级别的细节数据。
有许多理由要求以最低的原子粒度处理数据。原子粒度数据具有强大的多维性。事实度量越详细,就越能获得更确定的事实。将所知的所有确定的事情转换成维度。在这点上,原子数据与多维方法能够实现最佳匹配。
本案例研究中,最细粒度的数据是用户订单中涉及的单个产品,假设要开发的系统按照一个购物车中某种产品为单一项而上卷所有销售。尽管用户可能不会对分析与特定订单交易关联的单项感兴趣,但您能预测所有他们需要获得的数据的方法。例如,他们可能希望知道周一与周日的销售差别,或者他们希望评估是否值得存大量某品牌的商品等。尽管上述查询不需要某一特定交易的数据,但他们提出的查询请求需要以准确的方式对详细数据执行分片操作而获得。如果仅选择提供汇总数据,则无法获得这些问题的正确答案。
这里需要特别注意的是:基于大数据仓库的这种智能的用户画像的系统几乎总是要求数据尽可能以最细粒度来表示,不是因为需要查询单独的某行,而是因为查询需要以非常精确的方式对细节进行切分。
1.3 确定维度
维度要解决的问题是“业务人员如何描述来自业务过程度量事件的数据”应当使用健壮的维度集合来装饰事实表,这些维度表示承担每个度量环境中所有可能的单值描述符。如果粒度清楚,维度通常易于区分,因为它们表示的是与“谁、什么、何处、何时、为何、如何”关联的事件。常见维度的实例包括日期、产品、客户、雇员、设备等。在选择每个维度时,应该列出所有具体的、文本类型的属性以充实每个维度表。
事实表粒度选择完毕后,维度的选择就比较直接了。产品与事务立即呈现。在主维度框架内,可以考虑其他维度是否可以被属性化为订单度量。例如,销售日期、销售店面、哪种销售的产品被促销、处理销售的店员、可能的支付方法等。我们将这些以另外的设计原则表达。
详细的粒度说明确定了事实表的主要维度。然后可以将更多维度增加到事实表维度应用于该案例中:日期、产品、促销、支付方式。
1.4 确定事实
可以通过回答“过程的度量是什么”这一问题来确定事实。商业用户非常愿意分析这些性能度量。设计中的所有候选事实必须符合第2步的粒度定义。明显属于不同粒度的事实必须放在不同的事实表中。典型事实是可加性数值,例如,订货数量或成本总额等。
需要综合考虑业务用户需求和数据来源的实际情况,并与4个步骤联系起来,如图1所示。强烈建议坚决抵制仅仅只考虑数据来源来建模数据。将注意力放在数据上可能不会像与商业用户交流那样复杂,但数据不能替代业务用户的输入。遗憾的是,许多组织仍然在采用这种看似最省力的数据驱动的方法,当然这样做基本不能取得成功。
设计的最后一步是确认应该将哪些事实放到事实表中。粒度声明有助于稳定相关的考虑。事实必须与粒度吻合:放入订单中交易的单独产品线项。在考虑可能存在的事实时,可能会发现仍然需要调整早期的粒度声明或维度选择。
2 用户画像大数据仓库的框架设计
在Spark生态圈中,MLlib组件支持ALS算法,它是协同过滤式推荐算法中非常经典的一种。主要实现通过学习用户对商品的评分来推断出用户的喜好,并向用户推荐适合的产品,或学习商品的信息,寻找可能潜在的用户进行推荐。
当前案例截取是电商平台用户购物的流程,见图2。
通过该业务,分析用户画像的行为,例如用户的留存率、新增用户占日活跃用户比率、用户行为漏斗分析、用户相对商品复购率分析、商品推荐计算等。涉及的库表众多,这里只选取有代表性的9张表,分别是订单表、订单详情表、商品表、用户表、商品一级分类表、商品二级分类表、商品三级分类表、支付流水表、商品评分表[2]。
图3为亚马逊网站的一个截图,每款商品都会有评分数据。应用ALS算法,可通过用户对商品的评分,实现通过商品寻找可能有兴趣的人,或通过人查找有兴趣的商品的功能。
设计的第l步是通过对业务需求以及可用数据源的综合考虑,决定对哪种业务过程开展建模工作。当前基于大数据仓库用户画像的业务应该将注意力放在最为关键的、最易实现的用户业务过程。最易实现涉及一系列的考虑,包括数据可用性与质量以及组织的准备工作等。在此电商购物业务案例研究中,管理层希望更好地理解通过当前系统获得的客户购买情况。因此将要建模的业务过程是订单下单到交易完成的过程。该数据保证商业用户能够分析被销售的产品,它们是在哪几天、哪个商店、处于何种促销环境中被哪类人群购买。表1是系统总线矩阵[3]。
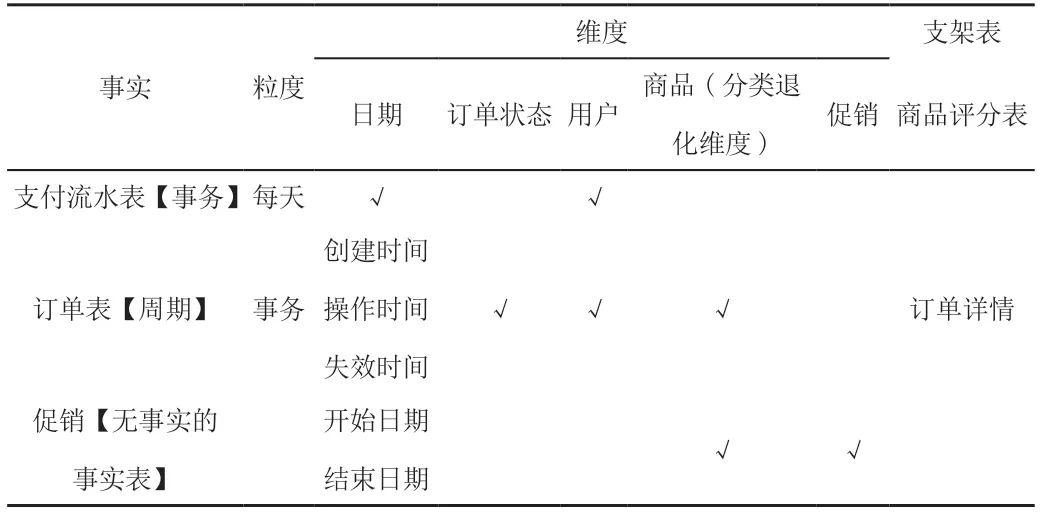
表1 系统总线矩阵
3 推荐算法的实现
本案例操作系统选择开源CentOS7,应用大数据工具选用Apache开源工具Hadoop、Hive、Spark、Zookeeper、HBase、Flume、Sqoop。
整个案例数据存储以Hadoop为基础,然后进行数据管理工具和分析工具及ETL工具的安装与配置。由于MapReduce本身的中间结果复写磁盘的特性,也决定了它并不适合交互性强、循环迭代的学习知识的过程,故在用户画像的产品推荐过程中,选用的基于内存计算的Spark工具,基于其内核,应用Spark SQL组件从Hive大数据仓库中提取数据,应用Spark MLlib机器学习组件,完成ALS算法参数的学习过程,使其依据用户对商品的历史评价数据,正确实现商品的推荐过程,即通过某个商品找到可能购买的用户,同时通过用户找到可能购买的商品[4]。
3.1 测试数据表的准备
3.2 项目开发前Hive的准备
在Hive工具的conf/hive-site.xml文件中配置远程服务,即加入下面参数配置项。
3.3 IDEA建立推荐算法的Maven项目
将Hadoop配置文件目录etc/hadoop下的core-site.xml和hdfs-site.xml文件拷贝到项目中resources文件夹中。将Hive配置文件目录/usr/local/hive/conf下的hive-site.xml文件拷贝到项目中resources文件夹中。拷贝路径见图4。
3.4 Recommend的实现
ALS协同算法,其全称是交替最小二乘法(Alternating Least Squares),由于简单高效,已被广泛应用在推荐场景中,目前已经被集成到Spark MLlib和ML库中[5]。
下面我们构造一组商品与用户的评分矩阵,见表2。

表2 商品与用户的评分矩阵
我们应用推荐算法,其目的就是找出两个属性的相似性,例如找出两个用户的相似喜欢,进而完成推荐过程。例如,表中“用户1”和“用户2”喜好相对最像,唯一的是“用户2”比“用户1”多了一个对商品4的评分,所以肉眼我们可认为当向“用户1”推荐商品时,可将“商品4”推荐给“用户1”。
以下是部分recommend代码:
其中:ratings:训练的数据格式是Rating(userID,productID,rating)的RDD。rank参数指当我们进行矩阵分解时,将原来的矩阵A(m×n)分解成X(m×rank)矩阵与Y(rank×n)矩阵。
Iteration:ALS算法重复计算次数。
4 运行结果测试
进行测试,通过输入不同的参数,观察推荐结果,例如:输入1,针对用户推荐商品时,发现给用户1推荐时,推荐了商品4。图5显示的是测试结果。
我们将学习参数按图中红色框中进行修改,然后再次研究推荐算法时,发现给用户1推荐的商品不是商品4,而是商品3了。
5 结语
综上所述,本文介绍了基于大数据仓库技术和数据画像进行商品推荐的过程,通过ALS算法,在选择商品的时候更加科学。
