红外光谱快速测定油茶籽油脂肪酸组成的模型建立
2022-03-10吴雪辉何俊华王泽富
吴雪辉,何俊华,王泽富
(1.华南农业大学 食品学院,广州510642; 2.广东省油茶工程技术研究中心,广州510642)
油茶籽油又称为茶油、山茶油、茶籽油、野山茶油等,是从山茶科植物油茶(CamelliaoleiferaAbel.)种子中提取的木本食用油。油茶籽油的脂肪酸组成与橄榄油相似,其中的单不饱和脂肪酸油酸含量高达80%以上[1-3]。油茶籽油中还含有多种功能活性成分,如角鲨烯、植物甾醇、多酚、脂溶性维生素等,具有很高的营养价值和保健功效[4-8]。
脂肪酸作为油茶籽油的主要成分,其组成、含量是评价油茶籽油品质的重要指标,也是决定油茶籽油高营养价值的主要因素。因此,快速、准确地测定油茶籽油的脂肪酸组成十分重要。目前,检测油脂中脂肪酸组成主要采用气相色谱法,样品前处理过程烦琐,时间长,成本高,不能满足快速分析的需要[9]。红外光谱分析技术是近年来迅速发展起来的无损检测技术,被广泛应用于油脂品质及掺伪检测[10-13]。吴雪辉等[14]利用偏最小二乘法(PLS)建立了油茶籽油中甾醇、维生素E和类胡萝卜素含量的预测模型,应用于油茶籽油中功能活性成分含量的快速检测。He等[15]基于分离富集得到的植物油不皂化物红外光谱图,采用偏最小二乘判别分析法(PLS-DA)和正交偏最小二乘判别分析法(OPLS-DA)构建了芝麻油鉴定模型。陈洪亮等[16]应用近红外光谱(NIR)分析技术,结合联合间隔偏最小二乘法(SiPLS)和带极值扰动的简化粒子群优化算法(tsPSO)建立了芝麻油中大豆油掺伪含量预测模型。Du等[17]采用近红外光谱结合偏最小二乘法,通过优化建模的预处理方法,建立了山茶油、菜籽油和葵花籽油多元掺假模型,模型的预测效果良好,其决定系数大于0.995,校正标准偏差(RMSEC)和预测标准偏差(RMSEP)分别小于6.79和4.98。何小三等[18]采用NIRFlexN-500型近红外光谱仪采集油茶籽油的红外光谱图谱,通过PLS建立了脂肪酸组成模型,除十七烷酸和α-亚麻酸有个别值相对偏差大于10%,其他脂肪酸相对偏差均小于10%。但是这些研究主要集中在采用近红外光谱技术结合线性偏最小二乘法建立食用油相关指标的快速检测模型,而应用红外光谱建立油脂中主要成分脂肪酸组成检测的模型研究较少,且大多采用线性的PLS建模方法,效果不理想。因此,本研究采用傅里叶红外光谱结合非线性的支持向量机(SVM)和BP人工神经网络(ANN)建立油茶籽油中主要脂肪酸的定量回归预测模型,旨在寻找一种快速、有效、无损检测油茶籽油中脂肪酸组成的方法。
1 材料与方法
1.1 试验材料
86个油茶籽油样本采集于广东省多家油茶籽油生产企业,样本包含有不同原料品种、不同提油方法、不同精炼工艺条件得到的油茶籽油。
Nicolet iS 10傅里叶变换红外光谱仪,赛默飞世尔科技有限公司;Agilent 7890B气相色谱仪,安捷伦科技(中国)有限公司。
1.2 试验方法
1.2.1 脂肪酸组成的测定
脂肪酸甲酯化的方法参照GB 5009.168—2016稍作修改。称取50 mg油茶籽油样本于20 mL试管中,分别依次加入正己烷1 mL、浓度为0.5 mol/L氢氧化钾-甲醇溶液1 mL,振摇1 min之后再加入水5 mL,继续振摇1 min左右,等待溶液分层,取上清液用于色谱分析。
脂肪酸组成测定采用气相色谱法。检测条件:色谱柱采用DB-23毛细管柱(60 m×0.25 mm×0.25 μm);进样口温度250℃;进样量1.0 μL;载气(N2)流速2 mL/min;燃气(H2)流速30 mL/min;分流比100∶1;检测器温度250℃;升温程序为色谱柱起始温度130℃,然后以10℃/min速度上升至180℃,保持10 min,然后以15℃/min速度上升至215℃,保持5 min,最后以5℃/min速度上升到230℃,保持5 min。
1.2.2 红外光谱采集及光谱数据预处理
参照何小三等[18]的方法稍作修改,红外光谱采集范围400~4 000 cm-1,分辨率4 cm-1,扫描次数64次,每个样品平行采集3次,以平均光谱作为样品光谱。
由于采集的红外光谱原始数据不仅包含了样本的化学信息,还包含了许多外界干扰信息,因此有必要采用合理的预处理方法消除干扰因素,以提高模型的准确性。经前期研究优化出油酸、棕榈酸和亚油酸的最佳预处理方法分别为Savitzky-Golay平滑(SG)、标准正态变换(SNV)和二阶导数(SD)[19]。
1.2.3 模型的建立与评价
分别采用支持向量机(SVM)和BP人工神经网络(ANN)建模,内部验证采用留一法交叉验证。
1.2.4 数据处理
采用MATLAB 2016b、Unscrambler X10.1和Microsoft Excel 2016等分析软件进行数据处理。
2 结果与分析
2.1 油茶籽油脂肪酸组成及样本分配
采用气相色谱法测定了86个油茶籽油样本的脂肪酸组成,由测定结果可知,油茶籽油中主要脂肪酸为棕榈酸(C16∶0)6.92%~11.33%、硬脂酸(C18∶0)1.51%~3.34%、油酸(C18∶1)71.72%~83.42%、亚油酸(C18∶2)0.83%~13.20%、亚麻酸(C18∶3)0%~0.67%和花生一烯酸(C20∶1)0.25%~0.64%等6种,其中棕榈酸、油酸和亚油酸含量较高,平均值分别为9.16%、79.42%、7.88%,合计占油茶籽油脂肪酸总量的97%左右,因此后面的模型建立选择这3种脂肪酸作为研究对象。同时将86个油茶籽油样本按照3∶1左右的比例,随机划分为校正集和预测集,校正集样本66个,预测集样本20个。油茶籽油划分样本主要的脂肪酸含量见表1。
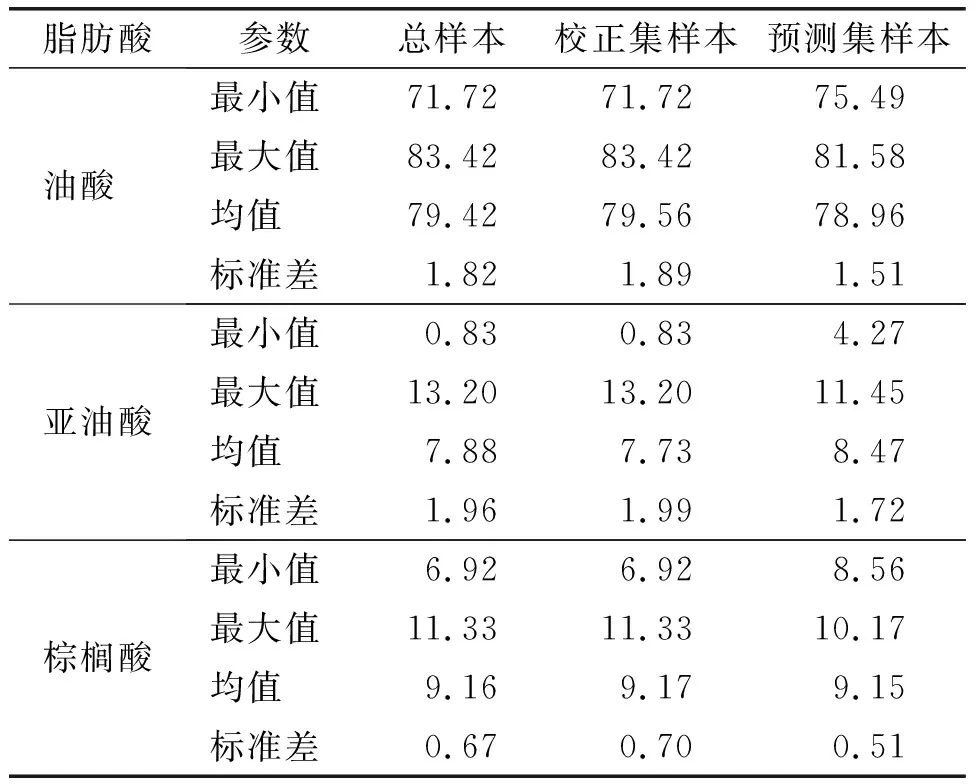
表1 油茶籽油划分样本主要的脂肪酸含量 %
2.2 油茶籽油红外光谱分析
86个油茶籽油样本的红外光谱图如图1所示。
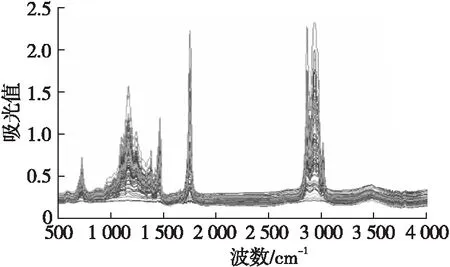
图1 86个油茶籽油样本的红外光谱图

2.3 油茶籽油中主要脂肪酸SVM模型的建立与预测
由于油茶籽油中物质含量与红外光谱吸收是非线性的,导致采用线性的最小二乘法回归建模方法存在一定的局限性,其相对标准偏差虽然小于10%,但是没有达到小于5%的水平[19]。因此,本研究选用常用的非线性建模方法——支持向量机进行建模。为了提高模型的预测效果,很好地提取3种脂肪酸的光谱信息,首先通过前期研究筛选出油酸、棕榈酸和亚油酸各自的最优子区间,其光谱波段分别为:油酸,763~1 125 cm-1、2 575~2 934 cm-1和2 995~3 644 cm-1;棕榈酸,400~763 cm-1、763~1 125 cm-1和1 847~2 205 cm-1;亚油酸,763~1 125 cm-1、1 125~1 488 cm-1和1 850~2 209 cm-1。
支持向量机的参数优化主要包括惩罚因子(C)、径向基核函数和松弛系数(g)。本研究基于网格全局法寻找最优C和g,网格全局寻优算法是将参数的寻优范围划分为网格形式并遍历网格内的所有参数点去搜寻最优值,采用网格全局寻优算法得到油酸、棕榈酸、亚油酸的惩罚因子(C)分别为0.25、0.1、0.25,松弛系数(g)分别为0.6、0.35、1,在此条件下建立SVM模型,得到油酸、棕榈酸、亚油酸的实测值与预测值的校正集、预测集样本散点分布情况,结果分别如图2、图3、图4所示。


图2 油酸实测值与预测值的校正集、预测集样本散点分布图


图3 棕榈酸实测值与预测值的校正集、预测集样本散点分布图


图4 亚油酸实测值与预测值的校正集、预测集样本散点分布图
图2~图4显示:油酸、棕榈酸、亚油酸校正集中所得到预测值与实测值的相关系数(R)分别为0.998 3、0.945 1、0.997 6,预测集中所得到预测值与实测值的相关系数分别为0.870 7、0.623 4、0.974 2,模型的相对标准偏差均小于5%(其中亚油酸的小于1%),预测效果达到应用检测水平;但是棕榈酸的预测集相关系数只有0.623 4,表明建立的棕榈酸定量回归模型泛化能力差,出现过度拟合情况,可能是选择几个子区间联合作为建模波段,波段点数较多,造成数据量过大,建模过程中支持向量机个数偏多,导致每一个样本出现一个临界域,这样建模集精确度很高,但泛化能力一般会很低。
2.4 油茶籽油中主要脂肪酸ANN模型的建立与预测
虽然非线性SVM建模效果较好,但没有交叉验证,且3个子区间输入的变量数为282,而建模样本数只有66个,远小于建模输入的变量,很容易导致过度拟合,造成模型的泛化能力差。因此,进一步采用具有内部交叉验证的非线性方法BP人工神经网络建模。
构建BP人工神经网络模型,参数选择:网络结构选择一个3层的人工神经网络,输入分别为优化后的联合子区间,输出分别为油酸、棕榈酸、亚油酸含量,同时需对输入、输出层参数进行归一化处理。对隐含层神经元数、传递函数、训练函数、学习函数、网络性能函数、仿真函数、训练校验次数、学习速率等参数进行优化,将数据输入设定好的网络模型中,对模型进行训练。应用建立BP的人工神经网络模型对校正集和预测集样本进行仿真应用,得到油酸、棕榈酸、亚油酸的实测值与预测值的校正集、预测集样本散点分布情况,结果分别如图5、图6、图7所示。
从图5~图7可以看出:3种脂肪酸的校正集和预测集样本基本均匀地分布在回归线上,油酸、棕榈酸、亚油酸的校正集中所得到预测值与实测值的相关系数(R)分别为0.998 7、0.945 1、0.995 7,预测集中所得到预测值与实测值的相关系数分别为0.955 7、0.926 2、0.981 6,表明模型预测值与实测值非常接近,模型的预测效果较好;3种脂肪酸模型的相对标准偏差分别小于1%、5%和1%。
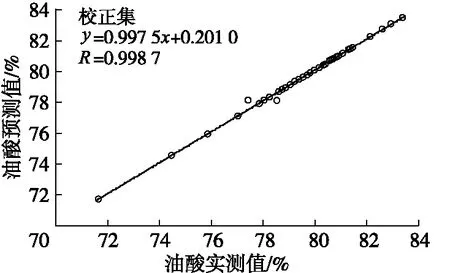
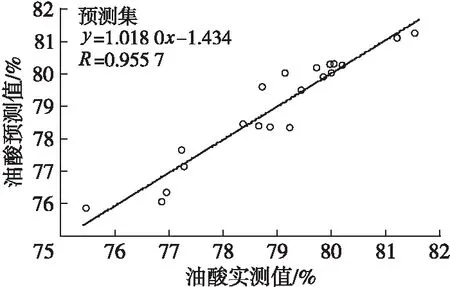
图5 油酸实测值与预测值的校正集、预测集样本散点分布图


图6 棕榈酸实测值与预测值的校正集、预测集样本散点分布图

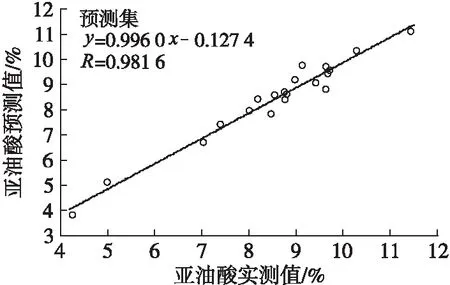
图7 亚油酸实测值与预测值的校正集、预测集样本散点分布图
3 结 论
通过对从企业收集的86个油茶籽油样本进行脂肪酸组成测定和红外光谱扫描,利用非线性回归方法SVM、ANN分别建立油茶籽油中油酸、棕榈酸和亚油酸的定量回归模型。对油酸和棕榈酸而言,ANN建立的定量回归模型精确度比SVM高,油酸的ANN模型校正集和预测集相关系数分别为0.998 7和0.955 7,相对标准偏差小于1%,棕榈酸的校正集和预测集相关系数分别为0.945 1和0.926 2,相对标准偏差小于5%;亚油酸的SVM和ANN定量分析模型相对标准偏差均小于1%,校正集和预测集相关系数分别为0.997 6、0.995 7和0.974 2、0.981 6。说明红外光谱替代传统的气相色谱法快速测定油茶籽油中脂肪酸组成是完全可行的。
