基于度量学习的无监督域适应方法及其在死亡风险预测上的应用
2022-03-09蔡德润李红燕
蔡德润 李红燕
(北京大学信息科学技术学院 北京 100871)
(机器感知与智能教育部重点实验室(北京大学) 北京 100871)
突发公共卫生安全事件往往会对社会医疗资源造成巨大的压力.例如2020年初新冠肺炎疫情的暴发所带来的医护人员人手短缺、医疗资源挤兑等问题.其原因之一是新型冠状病毒感染者容易出现“炎症风暴”[1],导致病情迅速恶化,死亡风险上升.医护人员需要投入大量的精力去观察和跟踪患者生理状况的变化,并需要根据患者死亡风险程度调配不同的医疗设备.例如体外膜肺氧合设备能够为抢救赢得宝贵的时间,但是数量比较少,适用于重症心肺功能衰竭患者.如果能够利用患者的生命体征数据构建深度学习模型,对死亡风险上升的患者发出预警,则可以节省医护人员的精力,及时对医疗设备进行合理的配置,增加医疗资源的利用率[2-7].
深度学习模型的成功应用是建立在大量带标签训练数据上的,并往往要求测试数据和训练数据服从同一分布,这在实际应用中常常不能得到满足.由于各种现实条件的限制,收集到的训练数据具有一定的局限性,例如可能某年龄段[8]、某科室或者某种并发症占据了大多数.这种局限性导致深度学习模型不能够对其他情况下的数据进行普适地预测.域适应(domain adaptation)方法能够利用源域和目的域的相似性,将源域上学习到的知识迁移到目的域上,从而解决该问题.
但是,将域适应方法应用在重症监护病人死亡风险预测任务上时还遇到主要来自3个方面的困难:整体数据分布偏移、类别之间的数据分布偏移以及时序数据的多样性和复杂性.其中整体数据分布偏移与类别之间的数据分布偏移如图1所示:
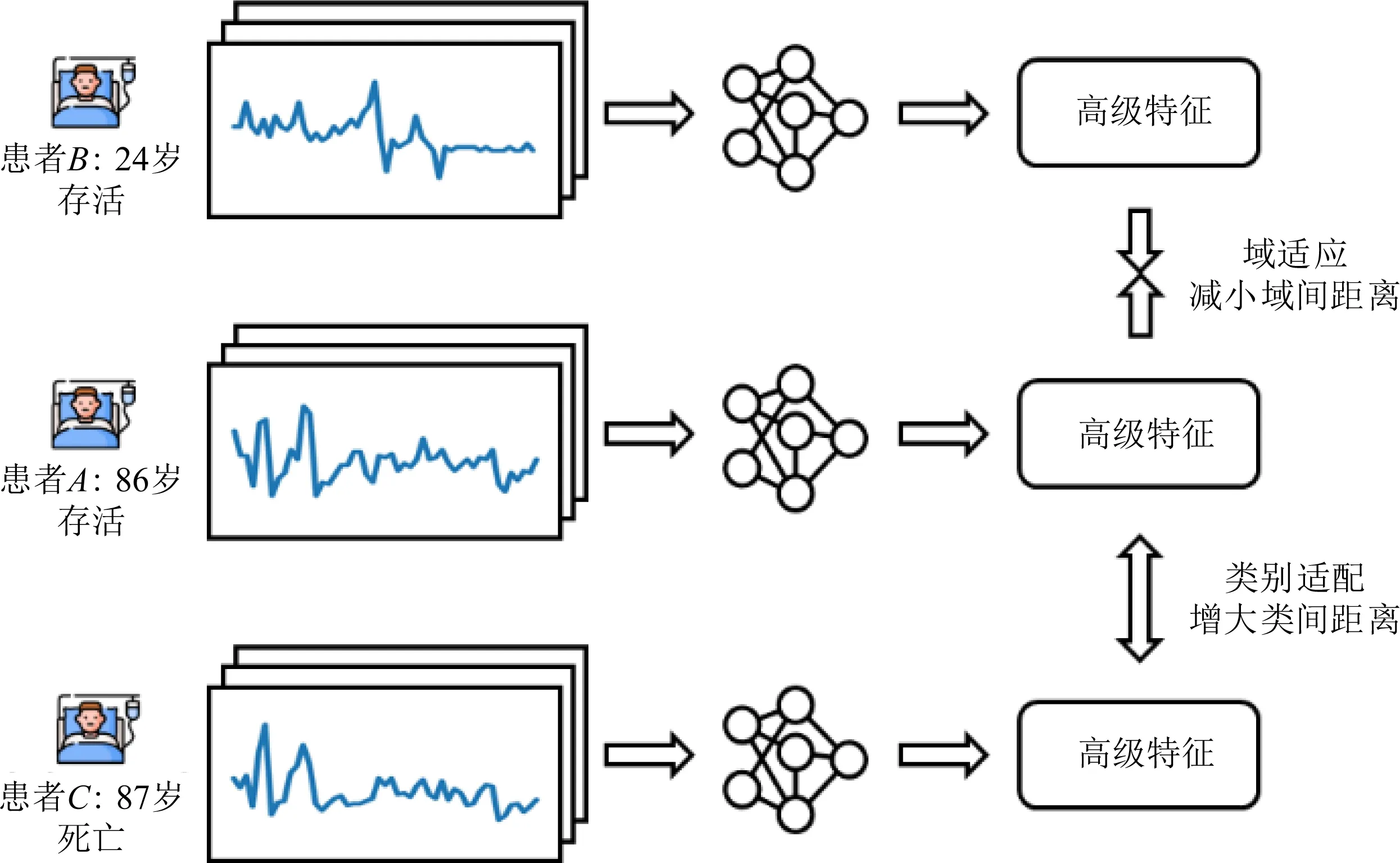
Fig. 1 Data distribution shift图1 数据分布偏移
整体数据分布偏移指的是源域和目的域整体的数据分布往往不相同.例如,在重症监护室内收集到的数据中可能老年人占据大多数.图1中老年患者A与青年患者B的生命体征不相类似,表示以老年患者为主体的源域和以青年患者为主体的目的域的数据分布是有差异的.以医疗领域的MIMIC-Ⅲ(medical information mart for intensive care Ⅲ)数据集为例,血压作为反映患者生理状况的重要指标之一,在不同年龄段的患者之间的分布是不同的.如图2所示,患者的平均血压随着年龄增加而逐渐变低.这些生理指标分布的差异导致在老年患者数据上训练的模型不能够很好地泛化到青年患者的数据上.域适应方法能够适当减小患者A与患者B的高级特征之间的距离,消除整体数据分布偏移所带来的影响.
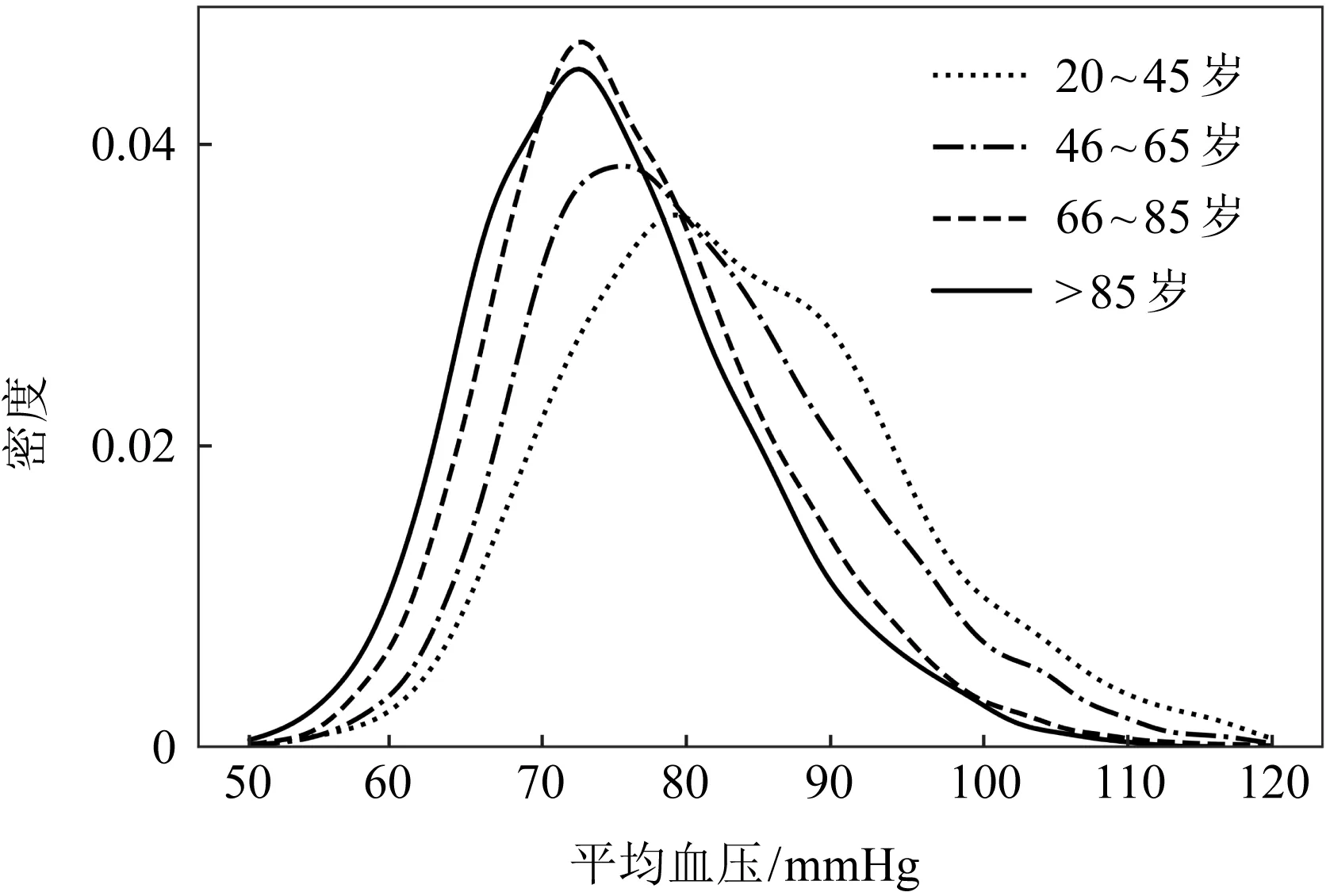
Fig. 2 Distribution of mean blood pressure with age图2 平均血压随年龄的分布情况
类别之间的数据分布偏移指的是不同域之间同一类别的数据分布往往不同.无论特征来自哪个域,相同类别的特征之间应该相隔较近,不同类别的特征之间应该相隔较远.因此需要在域适应的基础上进行类别适配.如图1所示,患者A与患者C的年龄相近,数据分布也类似.但二者的存活结果不相同,属于不同的类,因此需要进行类别适配,增加二者高级特征之间的距离.
时序数据的多样性和复杂性所带来的困难指的是患者各项生理指标构成了数据分布互不相同的不同通道,不同通道的时序变化趋势共同描绘了病人的生理状况.深度学习模型只有在理解不同时间步之间复杂的时序依赖关系并且有效地提取高级特征之后,才能进行域适应.
本文提出了一种基于域对抗和加性余弦间隔损失的无监督域适应方法(additive margin softmax based adversarial domain adaptation, AMS -ADA).其中域对抗是一种类似生成对抗网络的方法,能够解决整体数据分布偏移的困难.加性余弦间隔损失引入了度量学习的思想,能够解决类别之间数据分布偏移带来的困难.此外,本文使用带有注意力机制的双向长短程网络作为特征提取器来应对时序数据的多样性和复杂性.
1 相关研究工作
无监督域适应问题指的是利用源域的数据和标签以及目的域的数据训练深度学习模型,希望模型能够在目的域上取得尽可能高的准确度.与许多其他的迁移学习方法[9-13]相比,域适应对目的域上的标签不做要求,进一步降低了获取标注数据的压力.深度学习模型可以简单地视作特征提取器和分类器2个部分.如果深度学习模型的特征提取器能够从不同域之间的数据提取出域不变(domain invariant)的特征,那么在源域上训练的分类器就可以很好地应用在目的域上.域不变的特征是指在源域和目的域都具有表现力和判别力的特征,蕴涵了源域和目的域之间可以共享的知识.为了实现提取出域不变特征的这一目标,减少整体数据分布的偏移,通常的做法有2种:
1) 基于特征映射的方法.对深度学习模型从源域和目的域提取出的高级特征之间施加距离约束,使得神经网络学习出的高级特征的分布相似.如DDC(deep domain confusion)[14],DAN(deep adaptation network)[15]等方法使用了最大均值差异来衡量高级特征之间的分布差异,Deep CORAL[16]方法采用CORAL距离来衡量高级特征之间的分布差异.
2) 基于域对抗的方法.引入生成对抗网络的思想,用域判别器判断深度学习模型学习出的高级特征属于源域还是目的域.以对抗训练的方式使特征提取器和域判别器达到平衡.当域判别器无法辨别特征来自哪一个域的时候,说明特征提取器提取了具有域不变性的特征.如Adversarial Discriminative Domain Adaptation[17],Domain Adversarial Neural Networks[18]等.
近年来,域对抗方法以其优异的表现而备受关注.为了减少类别之间的数据分布偏移,进一步提升无监督域适应的效果,一些工作在域对抗方法的基础上引入了度量学习的思想.例如Wang等人[19]和Yin等人[20]在域适应任务中引入了三元组损失(triplet loss),在一定程度上最小化类内距离和最大化类间距离.但是三元组损失的计算需要遍历大量样本对,增加了额外的计算量,并且需要选取合适大小的隐层特征作为三元组损失的优化对象,增加了调整超参数的负担.
2 基于域对抗和加性余弦间隔损失的无监督域适应方法
为了解决将域适应方法应用在死亡风险预测任务上时遇到的困难以及相关工作的不足,本文提出了一种基于域对抗和加性余弦间隔损失的无监督域适应方法AMS -ADA.该方法在没有目的域样本标签的情况下,利用源域带标签的数据和目的域不带标签的数据进行训练,提升模型在目的域的准确度.该方法主要由特征提取器G、域判别器D和加性余弦间隔损失分类器C组成,其架构图如图3所示,源域和目的域数据流向分别用实线和虚线的箭头表示.
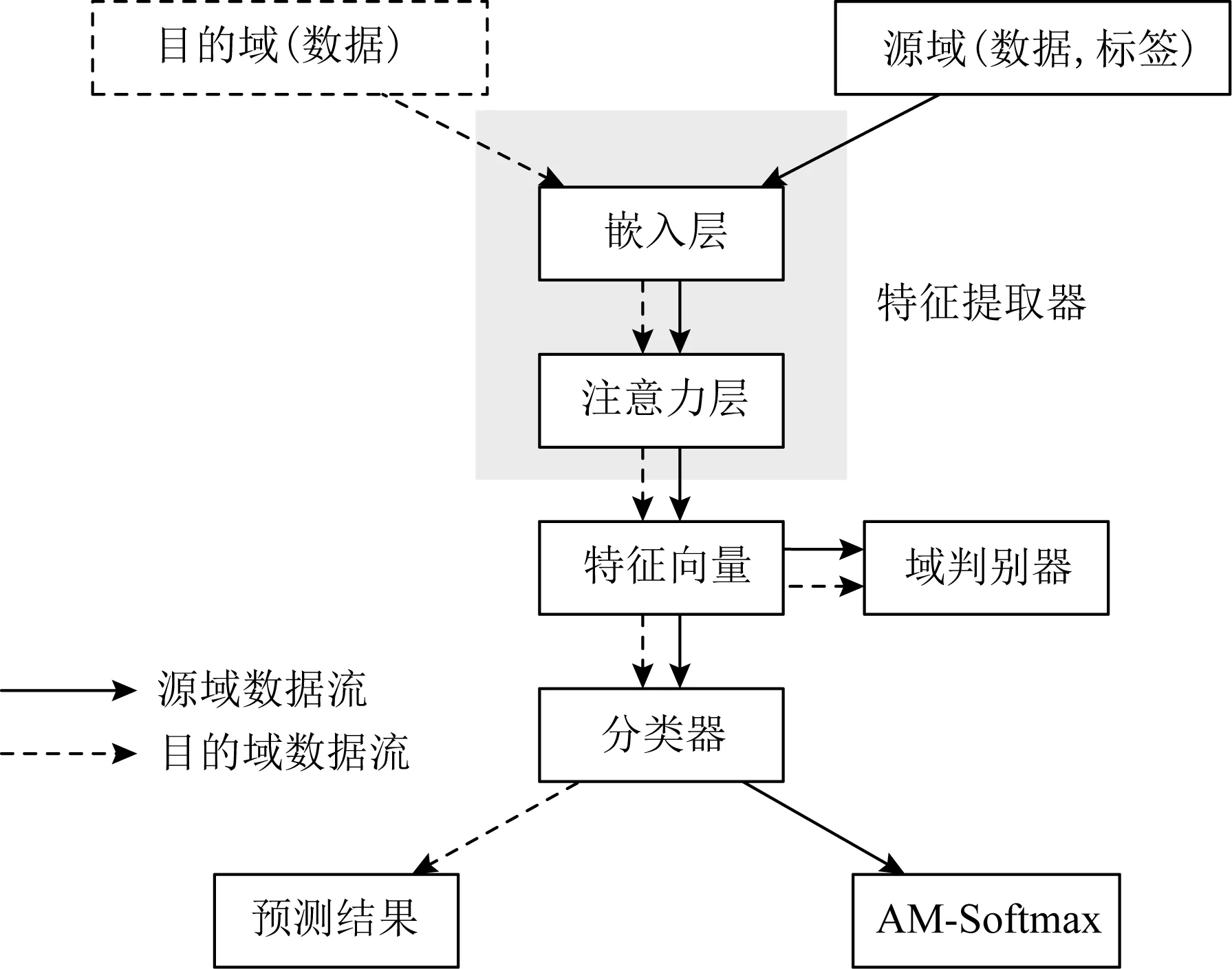
Fig. 3 Overall architecture图3 整体架构
2.1 问题定义
本文的研究目的是将无监督域适应方法应用在重症监护病人死亡风险预测任务上.在重症监护室内各种医疗设备每隔一段时间记录下病人的各项生命体征,这些记录可以自然地视为时序数据.
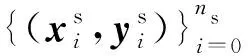
2.2 特征提取
特征提取器负责从输入数据提取有效的高级特征.为了应对时序数据的复杂性和多样性所带来的困难,本文选取了带有注意力机制的双向长短程记忆网络作为特征提取器.其中双向长短时记忆网络(bidirectional long short term memory, BiLSTM)作为嵌入层,对输入的特征进行初步的提取,捕捉基本的时序信息.嵌入层将输入x∈m×d变成输出H∈u×d,即每个时间步的特征维度从m变为u,并且包含了上下文的信息.
为了更好地提取时序信息,本文使用了自注意力机制[21],对嵌入层输出的每一个时间步计算注意力值ai,i=1,2,…,d,再根据注意力值对所有时间步进行加权求和.注意力机制能够使得深度学习模型更关注重要的时间步,从而能够提取出表现力更强的特征.
记W1∈na×u,W2∈r×na为参数矩阵,na为计算注意力的隐层向量维度,r为注意力头的个数.Softmax操作对每个行向量进行,目的是使得每个时间步的注意力值的和为1.注意力矩阵A∈r×d的计算方式表示为
A=Softmax(W2tanh(W1H)).
(1)
最后,注意力层的输出即为整个特征提取器的输出G(x)∈r×u,表示为
M=AHT.
(2)
2.3 域对抗
域判别器的作用是以域对抗的形式进行域适应,学习到域不变的特征,试图解决整体数据分布偏移的问题.域对抗借鉴了生成对抗网络的思想,使特征提取器和域判别器之间相互竞争,当域判别器无法辨别特征来自源于还是目的域时,特征提取器学会了如何提取域不变的特征.
记源域和目的域的概率分布为p(Xs)和p(Xt),域判别器D的优化目标可以表达为
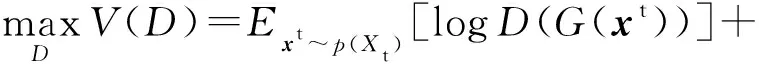
(3)
特征提取器G的优化目标可表示为

(4)
特征提取器和域判别器的优化目标可以结合在一起,写成极小极大的优化形式:
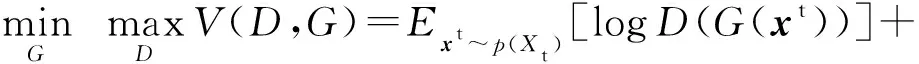
(5)
特征提取器和域判别器都是深度学习模型,在实践中通常以梯度下降最小化损失函数的形式进行优化.记特征提取器和域判别器的模型参数为θG和θD,域判别器的损失函数Ldisc(θG,θD)可以写为
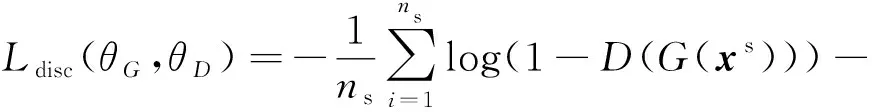
(6)
在对抗训练的过程中,特征提取器和域判别器的优化是交替进行的,形式化地表达为
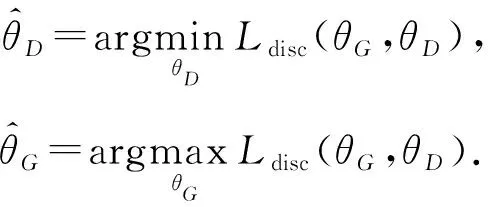
(7)
以域对抗的方式进行域适应,能够利用生成对抗网络强大的拟合数据分布的能力,更好地提取出域不变的特征.
2.4 加性余弦间隔损失分类器
加性余弦间隔(additive margin softmax, AM-Softmax)损失引入了度量学习的思想,能够增强不同类别的样本之间的可区分性.它作为最终的分类损失函数,能够同时端到端地最小化类内距离和最大化类间距离,不需要再耗费时间去选取深度学习模型中哪一层的特征作为优化目标.相比于三元组损失函数,它不需要额外计算样本对之间的距离,节省了训练所需时间.此外,在角度空间端到端地对类内距离和类间距离进行优化相比于三元组损失对隐层向量进行优化能取得更好的效果.接下来以对Softmax损失进行改进的形式介绍加性余弦间隔损失的动机和原理.
记n为当前批次训练样本的数量,yi为样本xi的类别标签,共有c类.Ⅱ(·)为示性函数,当括号内表达式为真时其值为1,当表达式为假时其值为0.p(j|xi)为模型给出的样本xi属于第j类的概率.Softmax损失函数LS可以写为
(8)
记样本xi对在深度学习模型中最后一层的输入为fi,W为最后一层的权重矩阵,Wj为权重矩阵中对应输出类别j的行向量.省略偏置项,Softmax损失函数进一步写为
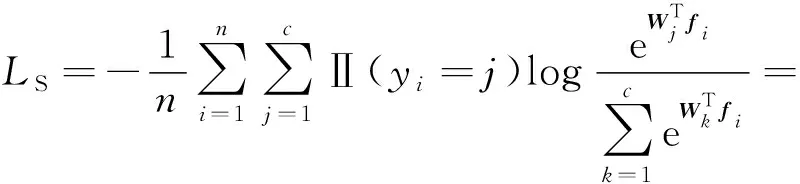
(9)
记fi与Wj的夹角为cosθi,j,对权重矩阵和输入进行归一化,即令‖fi‖=1,‖Wj‖=1.记缩放值为η,Softmax函数可以用余弦值来表示:
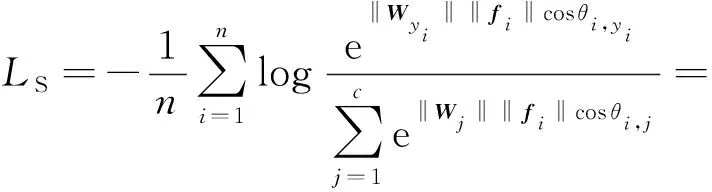
(10)
将向量内积写成夹角的形式,使得对决策边界的分析从欧氏空间转变为角度空间.现在以二分类的场景对决策边界进行分析,如图4所示.此时类别数c=2.当cosθi,0>cosθi,1时,样本xi被判定为c0类.同理,当cosθi,1>cosθi,0时,样本xi被判定为c1类.当前情况下,Softmax损失能够为不同类别划分清晰的界限,但是没有显式地优化类间的离散度度以及类内的聚合度.为了增加决策边界的宽度,引入边界阈值m.现在对决策边界施加更加严格的要求,当cosθi,0-m>cosθi,1时,样本xi被判定为c0类,当cosθi,1-m>cosθi,0时,样本xi被判定为c1类.将二分类的情况推广为多分类便可得到加性余弦间隔损失.记特征提取器和分类器的参数分别为θG和θC,加性余弦间隔损失LAMS(θG,θC)形式化地表达为
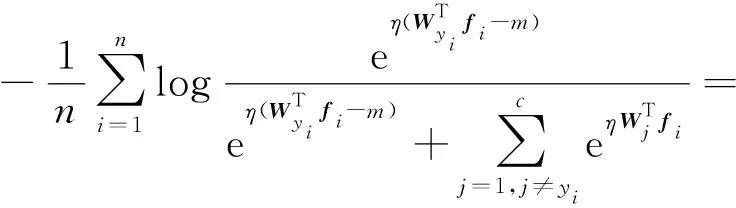
(11)
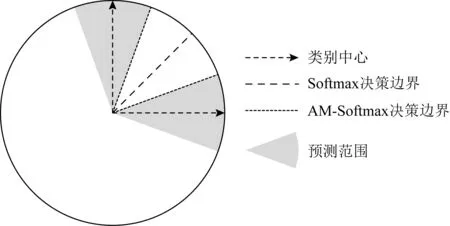
Fig. 4 Comparison between AM-Softmax Loss and Softmax Loss图4 加性余弦间隔损失和Softmax损失的对比
对决策边界施加的限制能够在角度空间最大化分类器的决策边界,从而达到最小化类内距离和最大化类间距离的目的.
2.5 训练流程
本文提出的方法含有可训练参数的部分为特征提取器、域判别器和分类器,其参数分别记为θG,θD,θC.由式(6)和式(11)可得最终的损失函数L(θG,θC,θD):
L(θG,θC,θD)=LAMS(θG,θC)-λLdisc(θG,θD),
(12)
其中λ为平衡因子,调节LAMS和Ldisc的比例.
本文提出方法的详细训练流程如AMS-ADA算法所示.首先对特征提取器、域判别器和分类器的参数进行随机的初始化.训练过程中对这些参数以梯度下降的形式进行交替优化.本文选用深度学习领域中常用的Adam优化器完成梯度下降的任务.在对抗训练的每次迭代的过程中,为了使得域判别器能够更好地指导特征提取器生成域不变的特征,需要增加域判别器的更新次数,即域判别器更新Ndisc次之后,特征提取器和分类器才更新一次.域判别器的更新是指计算Ldisc(θG,θD)后通过反向传播更新域判别器的参数.特征提取器和分类器的更新也是类似地计算各自的损失函数后通过反向传播对参数进行更新.当损失函数收敛之后,得到训练好的模型.此时将目的域的数据输入模型,得到最终的预测值.
算法1.基于域对抗和加性余弦间隔损失的无监督域适应方法.
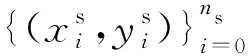
① 随机初始化θG,θD,θC;
② repeat
③ fori=1,2,…,Ndiscdo
④ 根据式(6)计算Ldisc(θG,θD);

⑥ end for
⑦ 根据式(12)计算L(θG,θC,θD);
⑩ until模型参数收敛
3 实 验
本文选用MIMIC-Ⅲ数据集[22]进行实验.MIMIC-Ⅲ数据集是麻省理工大学维护的公共临床数据库,包含2001—2016年之间约6万例的住院记录,每条记录包括人口统计特征、医疗干预记录、成像报告、生命体征记录、护理记录等信息.
Harutyunyan等人[2]在MIMIC-Ⅲ数据集的基础上定义了死亡风险预测任务.一般来说,患者进入重症监护室后的48 h以内的情况较为危急,因此本文选取患者进入重症监护室之后的48 h以内的数据对患者的存活结果进行预测.
根据Harutyunyan等人[2]的工作,本文在MIMIC-Ⅲ数据集中提取了76维的特征,包括心率(heart rate)、舒张压(systolic blood pressure)、收缩压(diastolic blood pressure)、血氧饱和度(SpO2)、毛细血管填充率(capillary refill rate)等60维的连续特征和格拉斯哥昏迷指数(Glasgow coma scale)等12维的离散特征以及4维的关于患者信息的常量.经过数据清洗和预处理后,最终得到的输入数据共有48个时间步,每个时间步有76维的特征.
Purushotham等人[23]尝试在不同年龄段的急性低氧性呼吸衰竭患者之间进行了迁移学习.本文沿用了该文的实验设置,将MIMIC-Ⅲ数据集的ICU数据库中所有患者按照年龄分为4组,如表1所示:
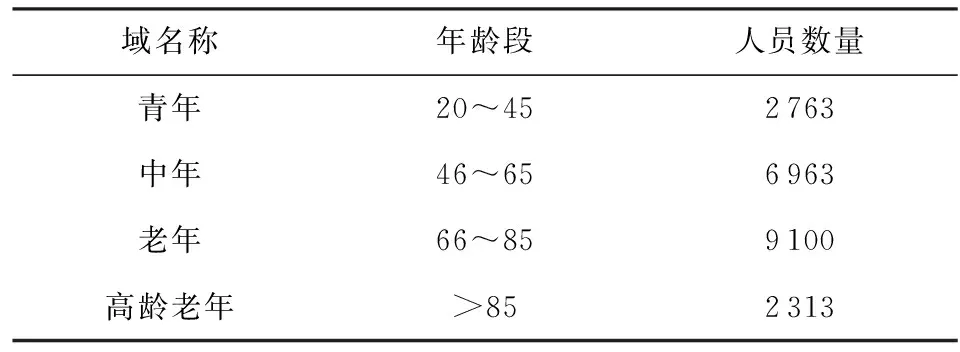
Table 1 Different Domains of MIMIC-Ⅲ Dataset表1 MIMIC-Ⅲ数据集不同域的划分
由于数据集中的正负样本比例相差较大,且属于二分类问题,为了避免正负样本不均衡对评价指标带来的影响,本次实验采用ROC曲线(receiver operating characteristic curve)下的面积值(area under curve, AUC)作为评价标准.本文采用了5种方法与本文提出的AMS-ADA方法进行对比:
1) BiLSTM.使用结合自注意力机制的BiLSTM网络作为基线,在源域上训练,在目的域上测试,没有使用任何无监督域适应学习方法.
2) CORAL.使用结合自注意力机制的BiLSTM网络提取特征,采用基于特征映射的迁移学习方法Deep CORAL[16].该方法以CORAL距离衡量源域特征分布和目的域特征分布的差异.
3) DAN.使用结合自注意力机制的BiLSTM网络提取特征,采用基于特征映射的迁移学习方法DAN[15].该方法以最大均值差异衡量源域特征分布和目的域特征分布的差异.
4) ADA(adversarial domain adaptation).与1)~3)所述方法采用相同的特征提取器,并且使用了域对抗方法,使用Softmax损失函数.
5) Tri-ADA(triplet loss guided adversarial domain adaptation)[19].与1)~4)所述方法使用相同的特征提取器.使用了域对抗方法.并且在此基础上加上三元组损失函数,以解决类别之间的数据分布偏移的问题.
本文在4个不同年龄段,即4个域之间两两进行无监督域适应任务,实验结果如表2所示.例如将青年患者的数据作为源域,将中年患者的数据作为目的域,无监督域适应任务记为青年→中年.
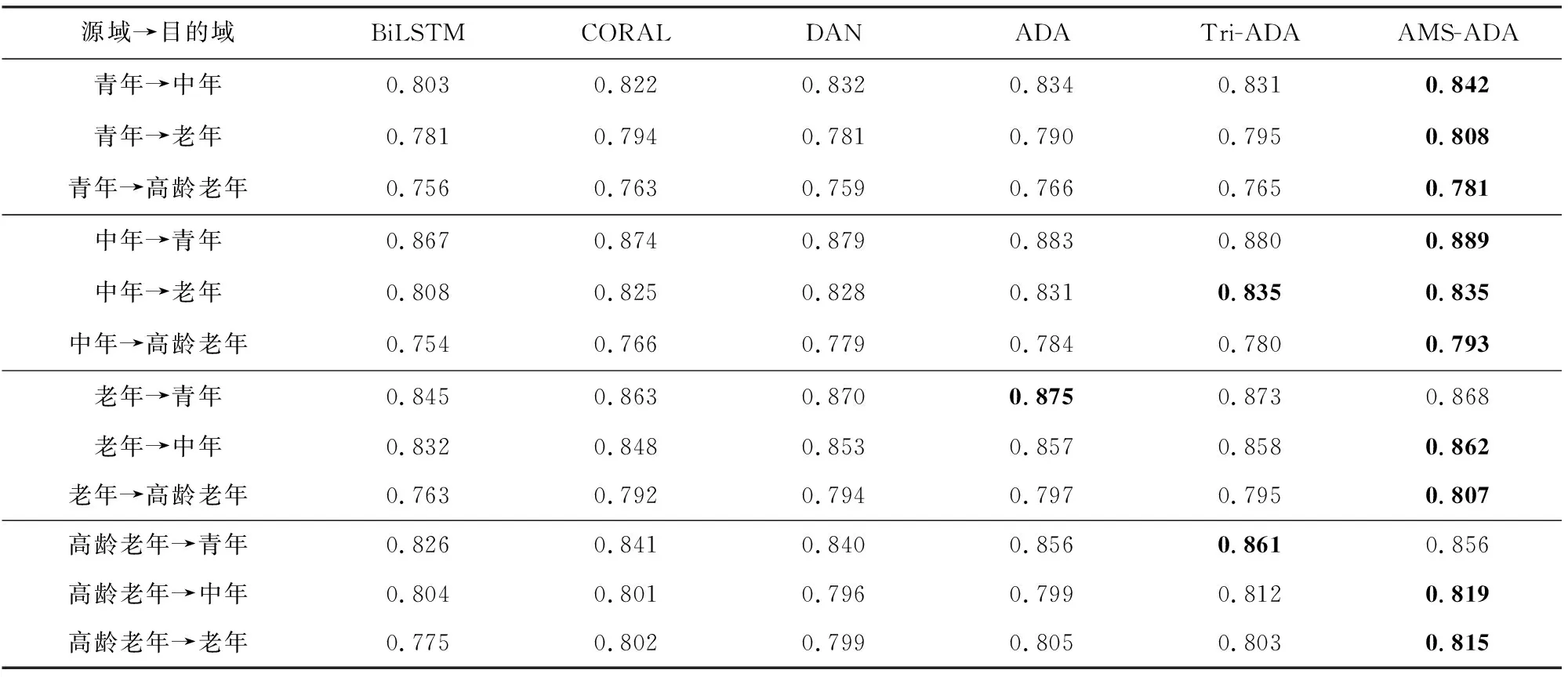
Table 2 Experimental Results of Mortality Prediction Task Based on Unsupervised Domain Adaptation表2 基于无监督域适应的死亡风险预测实验结果
本文提出的AMS-ADA方法在12个无监督域适应任务中的10个取得了最高的AUC值,说明了该方法的有效性.BiLSTM方法没有使用任何无监督域适应方法,因此表现较差.对于相隔较远的域,BiLSTM方法的表现下降较为明显.比如对于任务中年→青年,BiLSTM方法的AUC值为0.867,而对于任务中年→高龄老年,BiLSTM方法的AUC值下降为0.754.相隔较远的域意味着年龄相隔较大,数据的分布差异更为显著,因此对模型的准确度影响较大.CORAL方法和DAN方法使用了基于特征映射的迁移方法尝试解决全局的数据分布差异的问题,从结果上可以看出这2种方法相比BiLSTM方法有一定的提升.ADA方法引入了域对抗,相比于基于特征映射的方法能够更好地减少全局的数据分布差异,因此效果更好.Tri-ADA以域对抗的形式进行域适应,并且加入了三元组损失以减少类别之间的数据分布差异.实验结果较之CORAL和DAN方法有了一定的提升.为了更精细地对齐类别之间的数据分布,本文提出的AMS-ADA方法引入了加性余弦间隔损失,相比ADA方法和Tri-ADA方法的准确度有了进一步的提升,说明了本文提出方法的有效性.
为了直观体现本文提出方法的优越性,分别训练BiLSTM,Tri-ADA,AMS-ADA这3种方法,取各个方法的分类器的最后一层输出特征投影到角度空间进行可视化.选取青年患者的数据作为源域,高龄老年患者的数据作为目的域.BiLSTM方法的源域和目的域特征可视化结果分别如图5和图6所示.BiLSTM方法在目的域的准确度下降,其原因之一是类别之间的分布偏移.在源域训练时,不同类别的特征之间具有明显的界限.但是决策边界不够宽,在目的域测试时由于分布偏移导致分类错误.
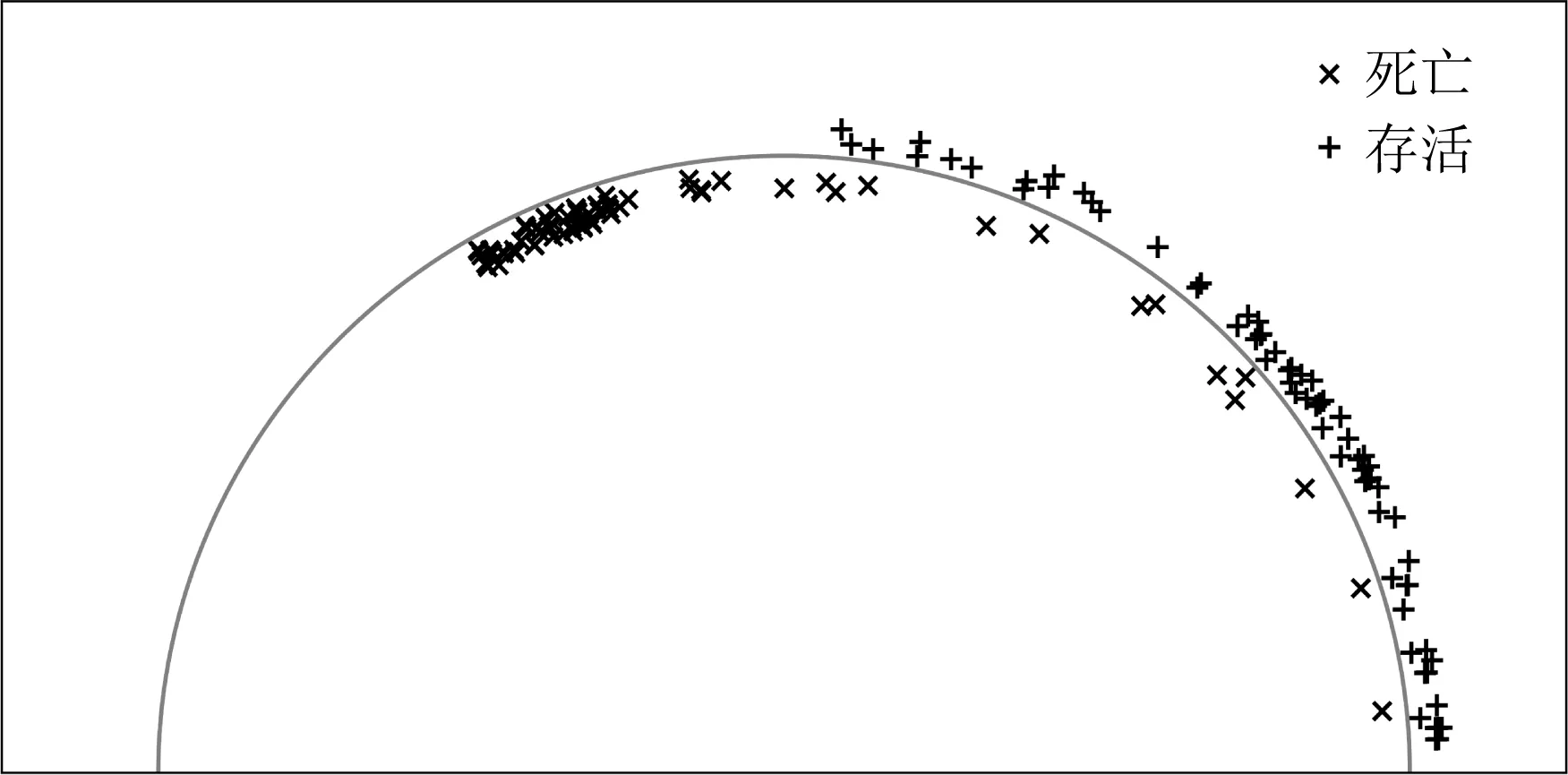
Fig. 5 Source domain feature visualization of BiLSTM method图5 BiLSTM方法的源域特征可视化

Fig. 6 Target domain feature visualization of BiLSTM method图6 BiLSTM方法的目的域特征可视化
因此,模型应该显式地增大决策边界,保持类内紧凑性和类间可分离性.Tri-ADA方法的源域和目的域特征可视化结果分别如图7和图8所示.Tri-ADA方法在源域训练时以三元组损失的形式增大了类间距离,因此在目的域测试时不同类别的特征之间可分离性加强,从而降低了错误率.

Fig. 7 Source domain feature visualization of Tri-ADA method图7 Tri-ADA方法的源域特征可视化

Fig. 8 Target domain feature visualization of Tri-ADA method图8 Tri-ADA方法的目的域特征可视化
AMS-ADA方法引入了AM-Softmax损失函数,能够进一步在角度空间增加决策边界的宽度,其源域和目的域特征可视化结果分别如图9和图10所示.存活患者的特征与死亡患者的特征的重叠部分进一步缩小,取得了很好的类间可分离性和类内紧凑性.得益于更宽的决策边界,在源域上训练的分类器对类别偏移的敏感程度下降,因此在目的域上测试时能够取得更好的准确度.
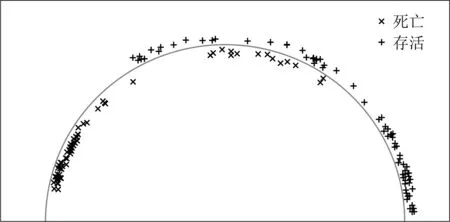
Fig. 9 Source domain feature visualization of AMS-ADA method图9 AMS-ADA方法的源域特征可视化

Fig. 10 Target domain feature visualization of AMS-ADA method图10 AMS-ADA方法的目的域特征可视化
4 结束语
深度学习模型的实际应用中容易遇到训练数据不足、整体数据分布偏移和类别之间数据分布偏移的问题.本文提出了一种基于域对抗和加性余弦间隔损失的无监督域适应方法应对这些问题.本文以域对抗的形式减少了整体数据之间数据分布偏移.为了进一步改善无监督域适应的效果,引入度量学习的思想,以最小化加性余弦间隔损失的形式减少了类别之间的数据分布偏移.所提出的方法在重症监护病人死亡风险预测任务上进行了验证,在MIMIC-Ⅲ数据集上的实验结果和可视化分析结果证明了该方法的有效性.未来的工作会尝试将所提出方法扩展到医疗领域的其他任务中,例如疾病预测和住院时长预测等任务.
作者贡献声明:蔡德润提出算法思路、完成实验并撰写论文;李红燕提出了指导意见并修改论文.
