一种融入注意力机制的医疗病例实体识别方法
2022-03-07帅英杰
帅英杰,黄 勇
(1.广西民族大学人工智能学院,广西 南宁 530000;2.广西壮族自治区党委网信办,广西 南宁 530000)
命名实体识别在自然语言处理中是比较重要的任务,也是近几年热门的研究领域,其主要任务是在大量的文本中识别出有价值的实体并为后期搭建知识图谱提供实体数据。在识别过程中,识别方法要同时保证识别准确率和识别效率。早期传统的命名实体识别LaSIE-II[1]、NetOwl[2]等主要是基于规则、词典或在线知识库的方法,因医学领域的规则和词典不完整导致传统方法在进行命名实体识别时存在着很多局限性,而基于监督学习[3]和半监督学习[4]的识别方法是在早期传统方法之后的重要研究方向。近些年,深度学习网络模型被广泛应用在命名实体识别任务上,基于双向长短时记忆网络结合条件随机场[5](BiLSTMCRF)的网络模型是命名实体识别任务中最常见的模型结构。在医学领域命名实体识别的任务中,当前的模型和方法虽然已经取得不错的识别效果,但在识别方法的识别效率以及模型训练的时间上还有较大的提升空间。本文提出一种基于文本卷积神经网络、双向简单循环单元网络和自注意力机制的多网络联合模型(TextCNN-BiSRU-SelfAttention),以此解决传统网络模型对语义特征提取不充分的问题,提升模型准确率,缩短模型训练时间。
1.相关工作
医疗病历文本的命名实体识别主要包括以下三个重要步骤:首先对医疗病历的文本进行语义特征的提取,然后通过神经网络模型对特征进行学习,最后进行医疗实体的识别以及实体识别精确度的计算。
1.1 命名实体识别方法
命名实体是一个词或短语,它可以在具有相似属性的一组事物中清楚地标识出某一个事物[1]。在命名实体识别的研究历程中大致分为三个阶段:早期基于规则、词典以及在线学习的方法;基于监督学习和半监督学习的命名实体识别方法;以及近几年被自然语言处理广泛应用的神经网络模型。
基于规则、词典或在线知识库的方法,是早期常见的命名实体识别方法,它们依赖于语言学专家手工构造的语言规则,具有较强的依赖性。每条规则都有一个权值,当不同的规则发生冲突的时候,权值高的规则确定了实体所属的类型。较为著名的基于规则的命名识别系统有LaSIE-II[1]、NetOwl[2]、Facile[6]等。E.Alfonseca和Manandhar[8]提出了一种基于WordNet的实体分类方法。Word-Net区别于普通词典之处是根据语义而不是词形来组织词汇信息,WordNet相当于一部语义词典,其中语义关系包括反义关系、上下位关系、部分关系等。由于医学领域的规则和词典并不完整,后期对词典和规则进行补充和完善的工作也比较难处理,因此基于规则的命名实体识别方法往往存在着很多局限性。另外,不同细分医学领域的规则难以通用,此类方法往往难以推广到其他领域,无形之中给自然语言处理的工作者增加了工作量。
当基于监督学习和半监督学习的方法被应用在命名实体识别中时,命名实体识别被看作一个序列标注的任务。经典的命名实体识别方法使用的是“BIO”标注法。其中“B”表示一个实体的头部,“I”表示一个实体的中部,“O”表示非实体。常见的序列标注模型有隐马尔科夫模型(HMM)[9],基于隐马尔科夫模型的识别方法假定了标签序列之间存在较强的马尔科夫性,但从实验效果看,并没有显著的效果提升。另外,在实际的命名实体识别任务中,还面临着缺少标注语料这一至关重要的问题,为此,半监督学习方法应运而生,较为典型的半监督学习方法是自举法[10]。该方法通常从少量标记的数据、大量未标记数据和一小组初始假设或分类器开始,迭代生成更多带标记的数据,直至达到某个阈值。此外,M.Collins和Singer[11]提出了一种基于协同训练的方法,该方法主要是学习两套不同的实体规则,在学习的过程中,每类规则为另一类规则提供弱监督,两类规则协同进行实体识别。监督学习方法和半监督学习方法在命名实体识别的任务中取得了较为不错的识别效果。
近几年,基于深度学习的命名实体识别方法受到了众多研究者的关注,被广泛地应用于自然语言处理的各项任务中,取得了显著成效。在基于神经网络的命名实体识别任务中,命名实体识别同样被看作一个序列标注的任务,相对于传统的命名实体识别方法,基于深度学习的命名实体识别方法更具有灵活性,而且大大节约了人工标注的成本。在识别过程中不局限于有限的规则,极大地提高了识别任务的效率。在基于深度学习的命名实体识别的方法中,最为典型的方法是基于长短时记忆网络结合条件随机场的方法。其中,长短时记忆网络是循环神经网络[12](RNN)的变种,条件随机场[13]是一种隐马尔科夫模型(HMM)改进的方法。但是,因为存在无法提取局部语义特征和模型训练时间过长的问题,此模型在命名实体识别的效果上还有一定的提升空间。
1.2 本文研究动机
医学领域的命名实体有着医学领域固有的特征,也是区别于其他领域的标志特征。首先,如何针对特定的医疗病历文本进行详细的特征提取是较为关键的一步。其次,如何更加精确地提升识别效果也是至关重要的一步。为此,本文针对医学领域的医疗病历文本提出一种融入注意力机制和神经网络的命名实体识别方法,该方法包含了文本卷积神经网络模型和简单循环单元网络模型以及注意力机制等。在保证提取复杂的医学领域实体特征的同时,进一步提高识别的精确度。在同等训练语料的情况下,相比其他已有的命名实体识别方法,在识别精准度上有一定的提升,同时大大缩短模型训练的时间。
2.TextCNN-BiSRU-SelfAttention联合神经网络模型
针对医疗病历文本中的数据特点,本研究中提出一种联合神经网络模型(TextCNN-BiSRUSelfAttention)。首先,将医疗病历数据进行预处理,过滤掉无用数据,进行分词、构建序列词典和标记词典等工作。其次,通过Word2vec提取数据的语义特征。然后,将特征向量同步传到文本卷积神经网络和双向简单循环单元中,通过文本卷积神经网络模型提取文本局部语义特征,通过简单循环单元神经网络模型(SRU,变种的循环神经网络模型)提取上下文语义特征的同时提升模型的训练速度。再将两个网络模型学习到的特征向量进行拼接,之后将拼接的向量送到自注意力机制中获得重新分配权重的特征向量,使得模型识别效果更佳。最后,将注意力机制模型学到的特征向量再与之前的融合向量进行再拼接,拼接之后的特征向量送到条件随机场进行实体标签的分类预测,从而完成实体识别。本文提出的联合神经网络模型框架如图1所示。
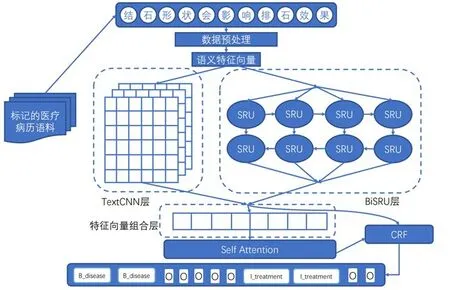
图1 TextCNN-BiSRU-SelfAttention联合神经网络模型框架
本方法的算法描述:
输入:中文医疗病历文本
输出:中文医疗病历文本中实体的标签
算法步骤:
(1)将输入文本的标签和文字序列分开,分别进行字典的创建;
(2)通过文本序列训练Word2vec模型,得到更适合医学领域的语义词向量;
(3)将语义词向量输入TextCNN网络模型中,经过TextCNN模型得到局部特征向量;
(4)将语义词向量输入BiSRU网络模型中,经过BiSRU模型得到全局特征向量;
(5)将局部特征向量和全局特征向量进行拼接,得到拼接后的融合特征向量;
(6)将融合特征向量再经过SelfAttention层,对融合特征向量进行权重分配;
(7)最后将重新分配权重的融合特征向量,经过CRF层,进行实体标签预测;
(8)进行精确度的计算,模型评估。
3.实验
3.1 实验数据及字词特征
3.1.1数据集简介及标注
本实验收集到了生物医学文本挖掘任务语料库(ChineseBLUE))[17],该语料库是由不同的生物医学文本挖掘任务和语料组成。该语料库涵盖了各种文本类型和不同大小的数据集,能为不同难易程度的自然语言处理任务提供数据支持,同时突出了常见的生物医学文本挖掘挑战。因此,该数据集有较高的实用价值,使用该数据集进行实验的实验结果具有可参考性。本文主要使用该数据集中针对命名实体识别的医疗病历文本数据集(cMedQANER),该数据集包括疾病、药物、综合征等25个分类标签,采用传统的“BIO”标注规则,结合医学领域的特定情况,给出了较为详尽的医学领域的标签。具体的分类标签如下表1所示:
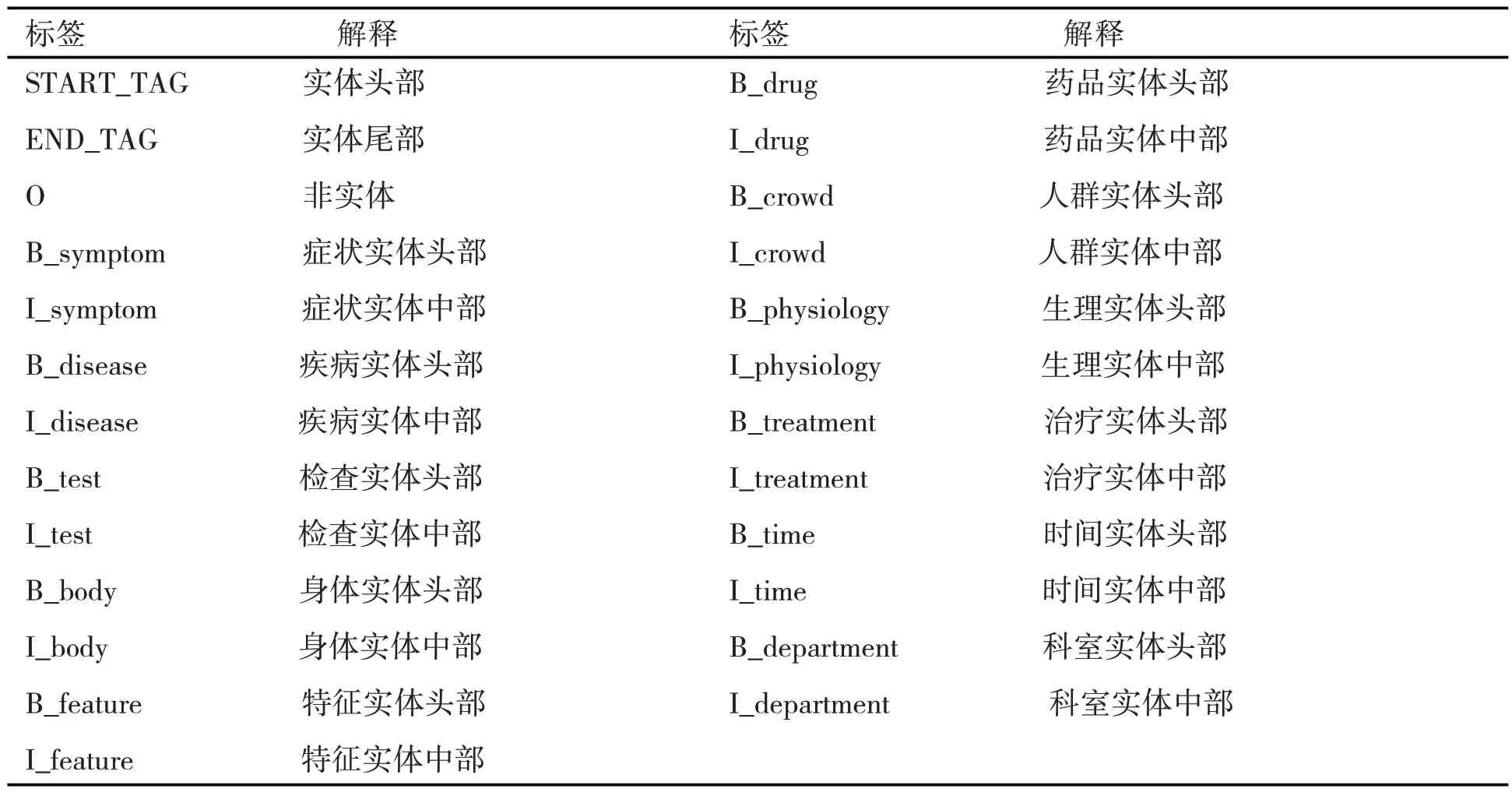
表1 医学领域实体标签分类及解释
3.1.2数据集预处理
本实验对数据进行了数据格式转换和数据清洗工作,过滤掉了文本中的空格、字符表情符号等没有意义的数据内容,获取到了更高质量的数据,保证了实验结果的客观性。
3.1.3语义特征提取
本实验使用Word2vec对医疗病历文本进行语义特征提取,得到语义词向量,词向量表现为矩阵形式。
3.2 实验评价指标
命名实体识别任务属于自然语言处理范畴,通常情况下采用的是自然语言处理任务中所使用的评价标准。本文采用的是F1-Measure、精确率(Precision)、召回率(Recall)三个评价标准。各评价标准的计算公式(1)、(2)、(3)如下,其中P、R、F1分别表示精确率、召回率、F1-Measure:
3.3 实验环境及参数设置
本实验中,实验环境为RTX8000、CUDA9.2,开源的框架选用的是Python3.8和Pytorch1.8.0。实验参数的设置分别为:语义词向量训练模型为Word2vec,使用的是skip-gram算法,训练的窗口大小为5,设置词频小于一次的词被丢弃,使用HS的方法,词向量的维度为512,训练轮次为50轮。双向简单循环单元网络(BiSRU)设置为2层,输入词向量大维度为512,每个批次读取数据的大小为64,Dropout为0.5,隐藏层的维度为1024。文本卷积神经网络(TextCNN)分别采用了卷积核大小为2,3,4的三个尺寸标准,每个尺寸的卷积核个数设为2个,输入词向量维度为512,步长为1。自注意力机制层为1层。模型的训练轮次为50轮,联合网络模型的学习率为0.001,优化器采用Adam优化器。
3.4 实验结果与分析
本实验采用的网络模型是由双向简单循环单元网络模型、文本卷积网络模型、自注意力机制联合的网络模型,实验数据集为ChineseBLUE数据集中提供的命名实体识别任务数据集(cMedQANER)。本实验中共设计了4组对照实验,将BiLSTM-CRF、TextCNN-BiLSTM-CRF、BiSRU-CRF、TextCNN-BiSRU-CRF等用于命名实体识别的网络模型作对比实验,实验对比结果如下表2。
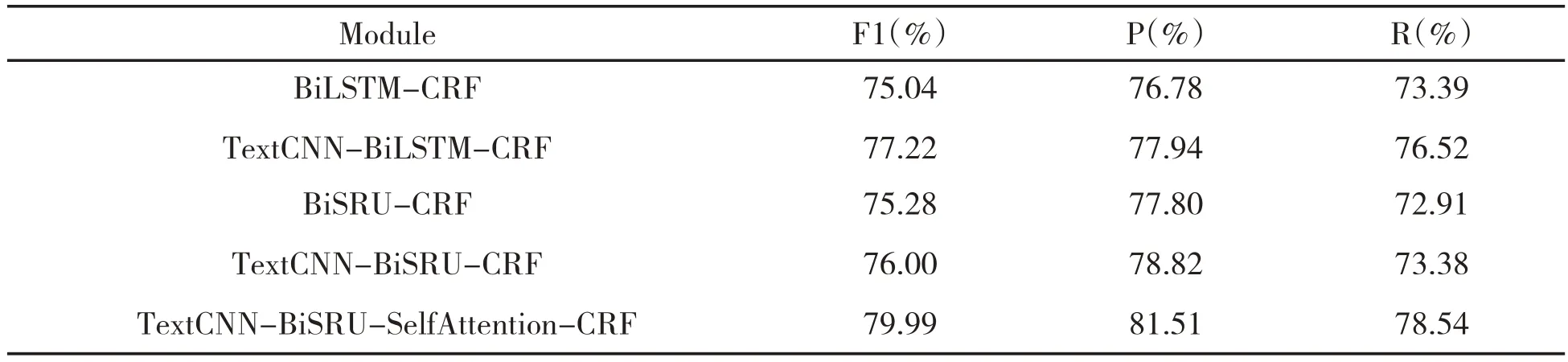
表2 ChineseBLUE中cMedQANER数据集测试结果
相比传统的神经网络模型,本文提出的联合网络模型在实验中有较好的表现。首先,使用简单循环单元网络模型,可以实现GPU并行计算,大大地提高了网络模型的训练速度,节省了时间成本,从时间上解决了长短时记忆网络由于串行结构而导致的模型训练时间过长的问题。模型训练时间对比可以参考表3。由表3可以看出,BiSRU-CRF模型在训练时间上比BiLSTM-CRF模型提升了57%。

表3 模型训练的时间对比
其次,由于卷积神经网络能很好地关注局部特征,将文本卷积神经网络提取的特征与循环神经网络提取的全局特征进行拼接,可以更好地捕获文本特征,由表2中的TextCNN-BiLSTMCRF、TextCNN-BiSRU-CRF网络模型可以看出,拼接后的模型相比原来的BiLSTM-CRF、BiSRUCRF神经网络模型在F1-Measure、精确率(Precision)、召回率(Recall)的评价标准上均有一定的提升。最后,由于自注意力机制能更好地重新分配权重,将更多的权重分配给更有价值的信息,所以将TextCNN-BiSRU神经网络模型输出的向量传到自注意力机制,再将自注意力机制输出的向量与原来神经网络模型输出的向量进行拼接后进行标签预测。由模型(TextCNN-BiSRUSelfAttention-CRF)可以看出,该模型相比其他模型在精确度、召回率和F1-Measure的评价指标上都有一定的提升。
4.结语
命名实体识别是近几年自然语言处理的一个热点。首先,传统用于命名实体识别的神经网络模型无法解决模型训练时实现并行运算的问题,本文提出的将简单循环单元神经网络用于命名实体识别则可以有效地解决这一问题,实现模型训练时在GPU上的并行运算。其次,将文本卷积神经网络与简单循环单元神经网络二者输出的词向量进行拼接,可以有效地弥补传统的神经网络模型不能同时获取局部特征和上下文特征的缺点。最后,引入自注意力机制,可以有效地提升模型的识别效果。实验证明,该模型在医疗病历文本的实体识别任务上表现出了不错的识别效果,在各评价指标上都有一定的提升。在今后的研究中,可以从词向量特征方面进行考虑,融合更多的特征向量,比如位置特征、词长特征等来提升模型识别的精准度。
