针对多姿态迁移的虚拟试衣算法研究
2022-03-05陈亚东杜成虎姜明华
陈亚东,杜成虎,余 锋,2,姜明华,2
针对多姿态迁移的虚拟试衣算法研究
陈亚东1,杜成虎1,余 锋*1,2,姜明华1,2
(1.武汉纺织大学 计算机与人工智能学院,湖北 武汉 430200;2.湖北省服装信息化工程技术研究中心,湖北 武汉 430200)
针对人体姿态迁移结果会损失服装和人脸等大量细节,以及现有的虚拟试衣算法没有实现多姿势迁移,提出一种新的姿态迁移网络。通过设计解析图生成网络,对目标姿势的解析图进行生成,再对空间变换网络(Spatial Transformer Network, STN)扭曲目标服装进行正则限制,最后利用优化的融合网络对服装和人体进行融合得到最终的姿态迁移图像。实验结果表明了该方法具有较高的鲁棒性和可靠性。
姿态迁移;虚拟试衣;解析图;空间变换网络
近年来,随着购物方式从线下向线上转变,线上服装购物方式受到了消费者的青睐,然而却存在不能试穿的问题而让消费者无法体验到服装穿在自己身上的效果[1]。目前存在的方法中,很多文献只局限于对单个姿势进行换装[2-5],而缺少多姿势的换装方法,这极大的降低了网上购买服装的体验。
姿态迁移[6-9]是将一个物体从原始姿态转换到目标姿态,期间不能改变物体的外表特征。应用到人体上,则可以实现人体的姿势迁移[10-11]。由于人体是非刚体,从技术层面上看,人体的各个部位的姿态变化十分丰富,因此迁移后很难对细节进行复原。其次,如果将虚拟试衣和姿态迁移进行融合,则可以实现多姿势的虚拟试衣方法。
传统的姿态迁移分为基于2D图像的方式[12-13]和基于3D模型重建[14-15]的方式,基于3D模型重建的方法根据人体的三维信息、图像、目标姿势点等来重建和调整人体的3D模型,在模型层面上进行换装后生成结果图像。文献[16]提出了一个端到端的神经网络模型,模拟三维空间结构,生成目标姿态的三维空间信息,然而,该方法未能实现对人体进行换装。文献[17]将人体模型进行重建后,再根据目标姿势的掩模对目标服装进行对应人体的变形,最后将导出的模型图像和服装图像进行融合,生成最终的结果。然而该方法没有对多姿势进行扩充,而且产生的服装细节丢失严重。上述的3D重建方式对设备算力,性能和生成的模型质量要求相对较高,在实际的应用方面还需要更成熟可靠的技术发展,这使得更多研究者转向研究基于2D图像的方法。
基于2D图像的方法利用了条件生成对抗网络(Conditional Generative Adversarial Nets, CGAN)[18]来达到生成图像的可控。Ma等人[19]提出了一个从粗糙到精细的CGAN架构,首先利用人体姿势点和图像生成一个粗糙的结果来关注全局结构,之后利用Unet[20]网络对粗糙的图像精细化填充。Wang等人[21]提出了一个两阶段的CP-VTON架构,首先使用结合形状上下文的薄板样条插值(Thin Plate Spline, TPS)模拟算法[22]的几何匹配网络[23]对目标服装的翘曲进行学习,再经过Unet网络将翘曲的服装利用掩模无缝的贴合在人体上。然而,该网络只能进行单姿势的试穿任务,对于多姿势的试穿没有合理的解决方案,并且产生的结果有严重的服装手臂交叉遮挡,皮肤和布料像素混淆,细节丢失等现象。
为了解决上述问题,本文对CP-VTON进行了改进,不但继承了原有的换装效果,而且对姿势迁移进行了探究拓展,解决了原论文中存在的缺陷,实验证明了本方法的有效性。
1 相关工作
1.1 生成对抗网络
生成对抗网络(GAN)[24]在虚拟试衣方面有很好的效果[25]。Cui等人[26]提出了一种端到端的虚拟时尚生成方法,将服装的草图或面料进行渲染。Lee等人[27]在服装的翘曲和服装的试穿阶段引入了对抗机制,加入了GAN损失,优化了服装的贴合程度,也使生成的图像更加合理。以上的方法分别融合了GAN机制进行效果的提升,表现出了GAN网络在图像生成方面的优越性,但没有合理的解决手臂遮挡和服装特征的缺失问题。
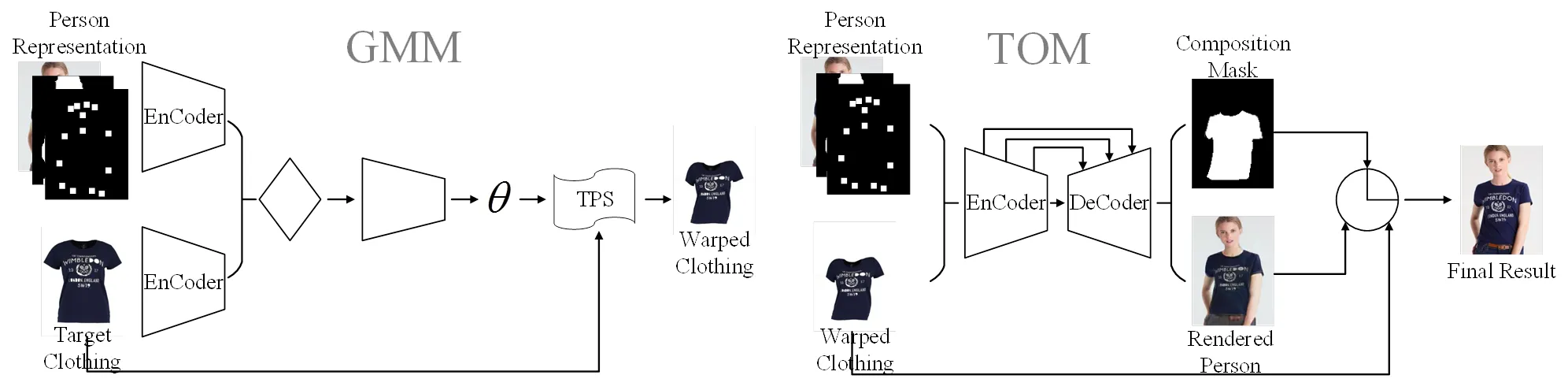
图1 CP-VTON整体结构图
1.2 CP-VTON
CP-VTON由GMM(Geometric Matching Module)和TOM(Try-on Module)两个模块组成。如图1所示,在GMM阶段,通过模拟TPS的几何匹配模块,对服装进行依据人体表征(姿势点,形状,头部图像)进行变换,生成粗糙的服装扭曲图像。但在GMM的训练过程中,没有对服装扭曲过程加以限定,造成服装的严重扭曲变形,如图2(a)第2列所示,加入不太合理的表征内容导致产生头发和上肢对服装扭曲的遮挡问题,如图2(a)第4和6列所示。

图2 CP-VTON中的各个模块存在的缺陷
在TOM阶段,依据人体表征和服装掩模将粗糙扭曲的服装进行对应人体的融合,将缺失的上肢和裤子进行生成。但TOM阶段在训练过程中,由于没有使用有效的引导对手臂和服装进行区分,造成了交叉遮挡和像素混淆的问题,如图2(b)第2和6列所示,没有对加入人体的裤子等不变的表征,造成人体不变特征丢失问题,如图2(b)第4列所示。
CP-VTON的提出,只用于解决单姿态下的虚拟试衣问题,并没有拓展到多姿势下的虚拟试衣。
2 方法
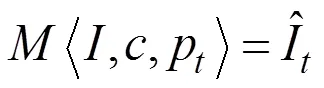
2.1 解析引导模块


图3 解析模块结构

如同pix2pix[30]等网络一样,使用解析图来限定和控制生成结果,可以很好地解决前文提到的像素混淆,交叉遮挡的问题,为生成姿态迁移图像提供了区域划分和目标形态确立的基础。
2.2 服装匹配模块


图4 STN结构


为了避免服装图像变形前和变形后像素和像素之间的距离不过大,以此来做到防止服装图像的过度扭曲,本文将TPS的采样坐标视为一个网格,以此来对各个网格线之间的距离差做到统一。通过实验表明,该方法可以很好的对服装形态进行转化,并防止过度扭曲的现象。
2.3 迁移融合模块
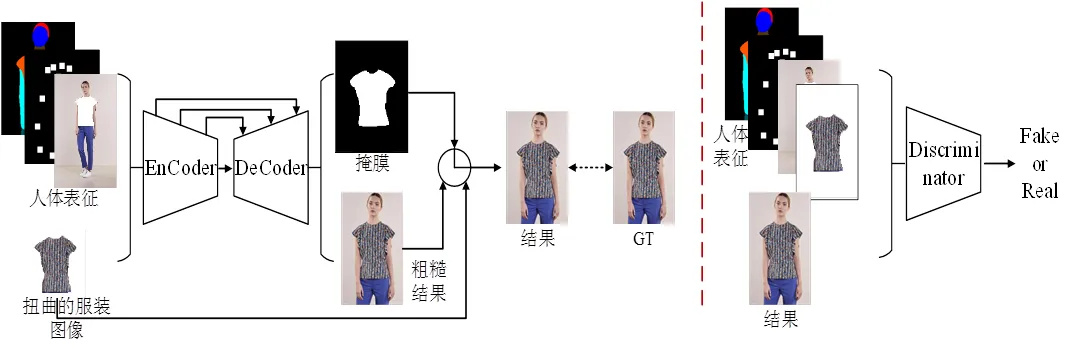
图5 迁移融合模块结构
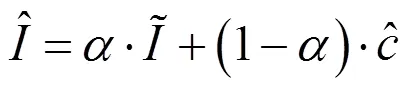
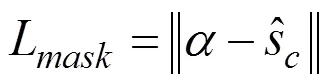
改进该损失函数之后,可以有效的避免上肢和服装交叉遮挡的问题。
2.4 网络损失函数
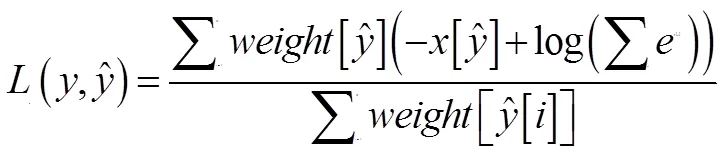


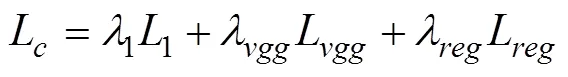
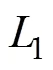


3 实验结果与分析
3.1 实验数据集

3.2 实施细节
实验的硬件环境采用一个Intel Gold 5118 CPU,64G RAM,以及一张Tesla V100 GPU 所组成的工作站,其中搭载着Python语言和Pytorch框架的Ubuntu16.04系统。
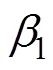
3.3 定性评价
首先,我们对解析阶段中的基准网络Unet和本文提出的网络生成的解析图效果进行可视化的对比。如图6所示,分别将网络生成的手臂解析图和服装解析图进行对比,可以看出,本文方法生成的解析图,如图6中4组图像中的第1组和第4组,手臂轮廓被清晰的分了出来,能够有效的避免手臂和服装之间的交叉遮挡问题。如图6中的第2组和第3组图像所示,服装的领口和袖长分割的也很合理,可以看出本文方法能比基准方法Unet取得更好的效果。

图7 CP-VTON和本文方法对目标服装的扭曲效果
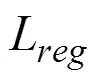
为了验证改进方法对姿态迁移的有效性,我们对单服装的姿态迁移进行了实验。如图8所示,在基准方法CP-VTON上加入解析引导模块,可以有效的避免皮肤和布料的像素混淆,本文方法产生的结果对身体各个部分能清晰有效的界定,因此也很好的解决了手臂遮挡和像素混淆的问题。对服装匹配模块的改进控制了服装严重的变形,而通过解析图引导生成的迁移融合模块也极大程度上保留了目标服装的细节,使生成的目标图像更加的真实合理。

图8 姿态迁移结果

图9 基于姿态迁移的虚拟试衣结果
最后,我们验证了本文方法对于多姿态的虚拟试衣效果,如图9所示,可以看出,本文方法所产生的图像质量更高,保留了大量的原始细节,并对虚拟试衣有着较高的鲁棒性和较低的耦合性。
3.4 定量评价
实验采用了SSIM(Structural SIMilarity)[33]来评估试穿结果和真实图像(GT)之间的相似度,采用IS(Inception Score)[34],FID(Fre´chet Inception Distance)[35]和PSNR(Peak Signal to Noise Ratio)[36]来评估生成的结果质量,定义如下所示:




表1是使用MPV测试集,对CP-VTON和本文方法之间的结果进行定量比较。结果表明,本文方法不但在直观的可视化效果展现上有较好的表现,在图像生成的硬性指标上也具有较高的参数。相较于基准方法CP-VTON,有很大的性能提升,参数指标表明本文方法生成的图像质量高,噪点少,局部辨识度较高,具有接近于真实样本(GT)的效果表现。

表1 不同方法之间的定量评价
4 结束语
本文对CP-VTON进行了改进,提出了一个多姿态的虚拟试衣网络。实验结果证明,增加的解析图引导很好地解决了CP-VTON网络中存在的交叉遮挡等缺陷,填补了在多姿态的虚拟试衣方面的空白。通过实验计算,本文方法较基准方法CP-VTON,IS提高了0.09,SSIM提高了0.0319,PSNR提高了1.7296,FID降低了9.18。定性和定量结果表明,本文提出的方法有着很好的姿态迁移与虚拟试穿效果,保留了大量细节,提升了生成图像的质量。最后,我们未来将进一步提升该网络的性能,优化图像的生成质量。
[1] GOLDSMITH RE, FLYNN LR. Psychological and behavioral drivers of online clothing purchase[J]. Journal of Fashion Marketing and Management, 2004,8(1): 84-95.
[2] HAN X, WU Z, WU Z, et al. Viton: An image-based virtual try-on network[C]. Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. 7543-7552.
[3] JANDIAL S, CHOPRA A, AYUSH K, et al. Sievenet: A unified framework for robust image-based virtual try-on[C]. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2020. 2182-2190.
[4] YU R, WANG X, XIE X. Vtnfp: An image-based virtual try-on network with body and clothing feature preservation[C].Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019. 10511-10520.
[5] YANG H, ZHANG R, GUO X, et al. Towards photo- realistic virtual try-on by adaptively generating-preserving image content[C].Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020. 7850-7859.
[6] SUN S H, HUH M, LIAO Y H, et al. Multi-view to novel view: Synthesizing novel views with self-learned confidence[C].Proceedings of the European Conference on Computer Vision (ECCV). 2018. 155-171.
[7] ZHOU T, TULSIANI S, SUN W, et al. View synthesis by appearance flow[C].European conference on computer vision. Springer, Cham, 2016. 286-301.
[8] LV K, SHENG H, XIONG Z, et al. Pose-based view synthesis for vehicles: A perspective aware method[J]. IEEE Transactions on Image Processing, 2020, 29: 5163-5174.
[9] ZHOU T, TULSIANI S, SUN W, et al. View synthesis by appearance flow[C].European conference on computer vision. Springer, Cham, 2016. 286-301.
[10] ZHAO B, WU X, CHENG Z Q, et al. Multi-view image generation from a single-view[C]. Proceedings of the 26th ACM international conference on Multimedia. 2018. 383-391.
[11] DONG H, LIANG X, GONG K, et al. Soft-gated warping-gan for pose-guided person image synthesis[J]. arXiv preprint arXiv:1810.11610, 2018.
[12] MINAR M R, TUAN T T, AHN H, et al. Cp-vton+: Clothing shape and texture preserving image-based virtual try-on[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. 2020, 2(3): 11.
[13] HAN X, HU X, HUANG W, et al. Clothflow: A flow-based model for clothed person generation[C]. Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019. 10471-10480.
[14] ALLDIECK T, MAGNOR M, XU W, et al. Video based reconstruction of 3d people models[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018. 8387-8397.
[15] GUNDOGDU E, CONSTANTIN V, SEIFODDINI A, et al. Garnet: A two-stream network for fast and accurate 3d cloth draping[C].Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019. 8739-8748.
[16] WANG J, WEN C, FU Y, et al. Neural pose transfer by spatially adaptive instance normalization[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020. 5831-5839.
[17] MIR A, ALLDIECK T, PONS-MOLL G. Learning to transfer texture from clothing images to 3d humans[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020. 7023-7034.
[18] MIRZA M, OSINDERO S. Conditional generative adversarial nets[J]. arXiv preprint arXiv:1411.1784, 2014.
[19] MA L, JIA X, SUN Q, et al. Pose guided person image generation[J]. arXiv preprint arXiv:1705.09368, 2017.
[20] RONNEBERGER O, FISCHER P, BROX T. U-net: Convolutional networks for biomedical image segmentation[C].International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015. 234-241.
[21] WANG B, ZHENG H, LIANG X, et al. Toward characteristic-preserving image-based virtual try-on network[C]. Proceedings of the European Conference on Computer Vision (ECCV). 2018. 589-604.
[22] DUCHON J. Splines minimizing rotation-invariant semi-norms in Sobolev spaces[M]. Constructive theory of functions of several variables. Springer, Berlin, Heidelberg, 1977. 85-100.
[23] ROCCO I, ARANDJELOVIC R, SIVIC J. Convolutional neural network architecture for geometric matching[C]. Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. 6148-6157.
[24] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks[J]. Communications of the ACM, 2020,63(11): 139-144.
[25] HONDA S. VITON-GAN: Virtual try-on image generator trained with adversarial loss[J]. arXiv preprint arXiv: 1911. 07926, 2019.
[26] CUI Y R, LIU Q, GAO C Y, et al. Fashiongan: Display your fashion design using conditional generative adversarial nets[C]. Computer Graphics Forum. 2018, 37(7): 109-119.
[27] JAE LEE H, LEE R, KANG M, et al. LA-VITON: a network for looking-attractive virtual try-on[C]. Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. 2019. 0-0.
[28] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]. Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. 770-778.
[29] WANG X, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]. Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. 7794-7803.
[30] ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks[C]. Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. 1125-1134.
[31] JADERBERG M, SIMONYAN K, ZISSERMAN A. Spatial transformer networks[J]. Advances in neural information processing systems, 2015. 2017-2025.
[32] KINGMA D , BA J . Adam: A Method for Stochastic Optimization[J]. Computer Science, 2014. 32–40.
[33] WANG Z. Image Quality Assessment : From Error Visibility to Structural Similarity[J]. IEEE Transactions on Image Processing, 2004. 600–612.
[34] SALIMANS, TIM GOODFELLOW, IAN ZAREMBA, WOJCIECH CHEUNG, VICKI RADFORD, ALEC CHEN, XI. Improved Techniques for Training GANs[J]. IEEE. 2016. 2234–2242.
[35] HEUSEL M , RAMSAUER H , UNTERTHINER T , et al. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium[J]. arXiv preprint arXiv: 2017. 6629.
[36] POOBATHY D, CHEZIAN RM. Edge detection operators: Peak signal to noise ratio based comparison[J]. IJ Image, Graphics and Signal Processing, 2014: 55-61.
Research on Virtual Try-on Algorithm for Multi-pose Transfer
CHEN Ya-dong1, DU Cheng-hu1, YU Feng1,2, JIANG Ming-hua1,2
(1. School of Computer Science and Artificial Intelligence, Wuhan Textile University, Wuhan Hubei 430200, China;2. Engineering Research Center of Hubei Province for Clothing Information, Wuhan Hubei 430200, China)
A new pose transfer network is proposed to address the fact that human pose transfer results in the loss of a large amount of details such as clothing and faces, and that existing virtual try-on algorithms do not implement virtual try-on with multiple pose transfer. A parse map generation network is proposed to generate a parse map of the target pose, then a Spatial Transformer Network (STN) distorts the target clothing with regularization restrictions, and finally an optimised fusion network is used to fuse the clothing and the body to obtain the final pose transfer image. The experimental results demonstrate the high robustness and reliability of the method.
pose transfer; virtual try-on; parse map; Spatial Transformer Network(STN)
余锋(1989-),男,讲师,博士,研究方向:人工智能与图像处理.
湖北省教育厅科学技术研究计划青年人才项目(Q20201709);湖北省服装信息化工程技术研究中心开放课题(900204);湖北重点研发计划项目(2021BAA042).
TS941.17
A
2095-414X(2022)01-0003-07
