图嵌入在上市公司信用风险预测中的应用
2022-03-04杨城,曲傲,成对,王畅
杨 城,曲 傲,成 对,王 畅
(1.西南财经大学 计算机与人工智能学院,四川 成都 611130;2.韩山师范学院 物理与电子工程学院,广东 潮州 521041)
2021年下半年恒大集团爆出债务危机,近几年类似的事件还有安邦帝国覆灭、海航破产重组,以及贾跃亭乐视没落等,这些大公司的暴雷事件通过持股关系、债务关系和关联交易被进一步放大,直接或间接导致多家关联企业和个人发生信用风险危险.传统模式下评估某家公司的信用风险往往局限于公司自身的财务指标,而对公司与外部世界的关联少有关注.当今经济全球化背景下,任何公司都难以独善其身,将其关联方作为研究对象以评估公司的信用风险有着重要的现实需求和理论意义.因此,近年来越来越多的学者在研究信用风险传染时,在传统财务分析之外引入复杂网络的思想,借助图论方法进行预测,以便更加具象化地对公司运营状况进行整体研究[1-3].
目前,对于复杂网络的研究已经不局限于社交网络、引文图谱、知识脉络等传统图论领域.随着人工智能和深度学习的持续火热,面向复杂网络和图的深度学习算法逐渐成为一个热门研究方向.图嵌入分析就是其中之一,其初衷是降低图分析问题中过高的计算成本和空间成本.具体而言,图嵌入将图映射到一个低维空间,其目的是将节点编码为低维向量,从而更好地整合节点的结构位置和邻居节点的信息.最先提出的图嵌入方法是Deepwalk算法[4],它通过对短随机游动流进行建模来学习顶点间的交互表示,游走路径随机采样.在此基础上,Node2vec 算法[5]提出了一种更优的图特征学习方法:它使用SGD梯度下降法来优化目标函数,以最大程度保留高维特征空间中每个节点的网络邻域信息,同时在原随机游走的基础上引入二阶随机游走,以保留更多的网络结构特征,包括网络结构的对等性和同质性.上述两种算法在图论经典模型“空手道俱乐部”问题的研究中均取得了良好的效果.除此之外,近些年图嵌入方法有了进一步的发展,主要分为LINE、Struc2Vec、GraphWave等以网络结构为标准的,和CANE、CENE等以网络结构配合节点信息为标准的两大类图嵌入方法.
受上述图嵌入方法的启发,将图嵌入算法的随机游走采样类比成上市公司信用风险的传染,并根据分析对象和网络结构的特征进行算法改良,将其应用于持股网络中的上市公司信用风险的分析和传染预测.
1 信用等级评定
首先基于KMV 模型和Z-score 模型对上市公司的信用风险进行评估,再使用历史违约记录进行调整,形成公司的综合信用风险等级,并对其做离散化处理,形成信用风险标签,以用于后续的图嵌入分析.本文采用的数据是2000 年到2020 年中国A 股上市公司每年披露的资产负债表、利润表和十大持股股东信息表,以及上市公司的违约记录表,数据来源为国泰安金融数据库.
KMV模型又叫做预期违约率模型,是一种应用广泛的信用风险评估模型.实践中由于部分公开数据的缺失,用中间参数“违约距离”DD 来评估风险,这也是KMV 模型的常用近似计算法[6-7].Zscore模型又称为Z值分析法,它是一种通过多变模式来衡量企业破产风险的财务分析方法[8].本文在具体计算时采用了适应度最广的四变量模型:营运资金/总资产(X1)、留存收益/总资产(X2)、息税前利润/总资产的利润(X3)和股东权益的市场价值总额/负债总额(X4).
由于违约距离和Z 指标来源于两个异构的评估模型,并且其数值在不同公司和不同年份之间的差距较大,因此将两个风险评估值离散化,映射为0-6共七个风险等级,其中0表示高度安全,6表示严重风险.然后将二者平均,得到一个平均信用风险指标.接下来引入上市公司的违约记录,在常规财务分析的基础上整合公司更全面的运营状况,使得信用风险等级更能体现公司的实际状况.调整方案是对平均风险等级进行降级:上市公司在某年内多次违规或发生重大违规时将等级降低两级,其他情况下等级下调一级,最终得出公司的综合信用风险指标.图1 展示了2015 年上市公司基于Z-score 模型、KMV 模型和综合指标计算的信用风险等级的分布情况.其他年份的综合信用风险等级分布与2015年基本类似.
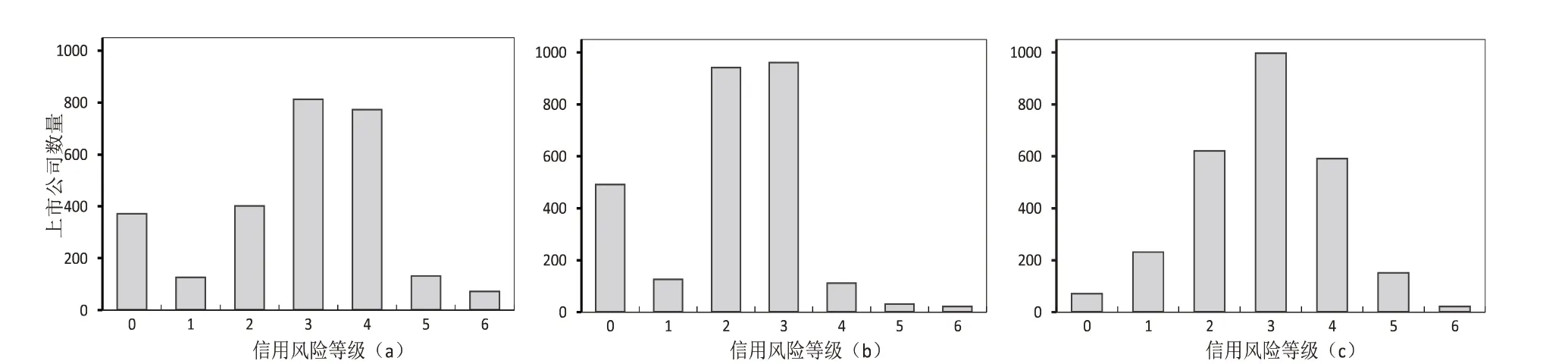
图1 基于KMV模型(a)、Z-score模型(b)和综合信用风险等级(c)的上市公司整体分布图(2015年)
在后续持股网络中,为了更方便地体现公司节点的信用风险,引入全局标签节点.当上市公司综合信用风险小于或等于三级时,将节点属性定义为good,其他节点属性定义为bad.
2 持股网络的构建与分析
2.1 构造持股网络
将上市公司十大持股股东数据集里面的各家上市公司作为节点(注:很多股东非上市公司,未采用),彼此间的持股关系作为边,构建持股关系网络.定义某时间点t的横向网络数据集为Dt,对应的

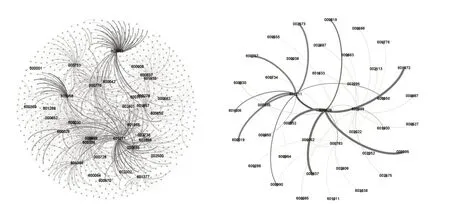
图2 2015年上市公司的持股网络图(左)和中国石化及其关联公司构成的连通子图(右)
将GT中的子图个数取3,即以每三个连续年份的持股网络为一个构造单元,将每年的数据集Dt与前两年的数据集Dt-1、Dt-2合并为一个新的数据集DAT,对应一个三层的纵向持股网络图.同时,将每一层中的相同公司逐层连接,相同公司间的权重设为该公司后一年的平均持股权重.这样每家公司不仅与其同期的关联公司相连,也与过去的自己相连,使持股网络具备了时间延续性.如此,每一份新数据集DAT对应的网络结构不仅包含当年的持股信息,还共享了前两年的持股信息.即持股网络汇集了基于空间的横向关联与基于时间的纵向关联,使得后续的风险传染预测能够更加全面地反映上市公司当前与过去所受到的综合影响.
2.2 持股网络的随机游走
上市公司间的信用风险传染可以看作是持股网络中不同节点的随机游走.在传染路径中,每家公司均有可能受到其上下家的影响,影响有好有坏,由关联上市公司的信用风险决定.区别于标准的时间序列游走,基于持股网络中时间点的固定性(公司财报),通过添加额外约束进行改良,提出了一种新的时间跳跃模式:自环,即游走序列允许相同的公司节点连续存在.此时游走路径的时间t变为t- 1,游走网络由gt更新为gt-1.对于每一个数据集DAT,每次游走取其最上层Dt中的某初始节点为起点,依据游走路径的长度,最远游走至最下层Dt-2.
定义对于某一时间点t的节点u,它下一步可能游走的节点集合L(ut)={N(ut)∪ut-1},其中N(ut)表示节点u在时间点t的邻居节点.节点间的游走策略采用时序有偏采样,即游走概率由体现彼此持股比例的权重决定
其中W(u,vti)为两节点之间边的权重,体现了各邻居节点在网络中的重要性差异.特别地,相同节点在不同年份间纵向跳跃时,权重定义为节点进行无偏采样时的概率(即所有节点以相同的概率被选择)
其中Degree( )ut为节点u在t时刻的总度数.当节点拥有较多的邻节点时,游走路径会更多地在当前年份内延伸(横向跳跃);而当节点的邻节点较少时,游走路径更容易向其他年份延展(纵向跳跃).
2.3 持股网络的图嵌入与向量学习
对于多年份持股网络GT,我们的目标是使用这些网络结构化数据学习一个方程映射关系Φ:V→RN,使得GT中的所有节点映射到一个N维的向量中,并且能够很好体现其结构化特征.如此,给定某一游走序列St,需要解决的时间网络结构的图向量表示的最优化问题为
其中w为关联向量集的大小,即窗口大小,表示随机游走中所有可能搭配的长度值;WdT=vi-w,…,vi+w为随机游走对应的关联向量集,且对于任意WdT⊆St,T(vi-w,vi-w+1)≤…≤T(vi+w-1,vi+w);Φ:V→RN为节点向量化方程.为方便计算,简单假设关联向量集WdT中的每个节点对于点vi的影响概率相互独立,则
其中WT={vi-w,…,vi+w} vi.依据上一小节游走策略中的“自环”规则,游走序列的滑动窗口中可能存在同一个节点vi在vi-w到vi+w中多次出现的情况,故要求WT中的元素均不等于vi.这种更新的方法称为SkipGram,它最初是一种语言模型,可最大程度地提高出现在窗口w内句子中单词间的共现概率,以更利于网络学习.在这种类似于语言序列的游走序列中,它使用上面的独立性假设来近似替代公式中的条件概率,将每个源节点对(vi,vj)的条件似然建模为一个softmax 单元,其中的参数为两个节点的特征向量的数量积
实际应用中发现,当仅仅采用上述方法进行图嵌入时,不同时间段的GT对应的图嵌入向量在数值上有较大的差异,因此需要对嵌入向量作一定的方向性指引.这是一种较为常见的方法,2018 年Airbnb 公司就引入全局变量来引导推荐系统的学习倾向[9-10].将节点属性(good/bad)作为全局变量对学习结果进行引导,此时最优化问题变为


在完成以上初步嵌入的基础上,本文对GT中各节点作进一步的处理.将游走路径WdT中的第一个节点v1作为目标预测项,后续节点作为v1的影响因素α,总影响权重为β.影响因素由节点的标签标记tag(v)决定:除目标项外,WdT中每出现一个新节点,β值增加1;若新节点为bad节点,则α值增加1.特别的,如果在WdT中出现相同节点连续的情况(意味着网络层级的切换),之后的α 值和β值都将成倍增加,以此来增大不同年份间的权重.
据此,本文在使用第一步梯度下降算法的基础上,提出了一个二次代价函数以更好地引导节点位置,它可以将节点一定程度上限制在某一个(信用风险等级基本相当的)区域
其中,x是GT中的节点在Φ节点向量化方程作用下的高维嵌入向量;ptgood和ptbad分别是空间中一对预定义的安全节点和风险节点.两个节点的连线对应着空间中一条由安全区域至风险区域的渐变线.越接近ptgood的点,公司经营状况越好;越接近ptbad的点,公司风险性越高.当忽略方程系数时,y表示嵌入向量x到两个预定义点的距离平方和.最小化y值会使得嵌入向量x最终落在渐变线的中点,此时公司处于风险不确定的混沌状态(风险等级为3).当考虑方程系数时,若α大于β/2,会使得令y取最小值的点向预设点ptbad偏移,若多次出现,x最终将距离ptbad更近,其代表的公司将面临更高的风险;反之,若α 小于β/2,会使得令y取最小值的点向预设点ptgood偏移,最终使得x代表的公司更不容易出现风险.实践中,设定good 节点的坐标为(1,…,1),bad 节点的坐标为(-1,…,-1),两个节点的坐标维度为实验时的嵌入维度.上市公司的信用风险就对应着该公司节点与两个标记点之间的距离差值,并且在使得距离差值的分布基本符合综合信用风险等级分布的情况下,将其整体划分为对等的七个等级.
接下来就可以基于上述方法开展图嵌入向量学习了.学习主要分为两个部分:(1)使用关联关系网络游走形成的节点对进行学习;(2)使用节点对中的标签信息对节点作修正.第一部分主要研究持股网络的结构因素对节点风险的影响,第二部分主要使用节点的标签信息来更好地优化结构因素不具备的内容信息,从而更加全面准确地描述持股网络中关联公司间信用风险的相互影响.
综上,在对上市公司的信用风险进行分析和传染预测时,所采用的基于持股网络,并应用图嵌入改良方法的完整流程如图3所示.
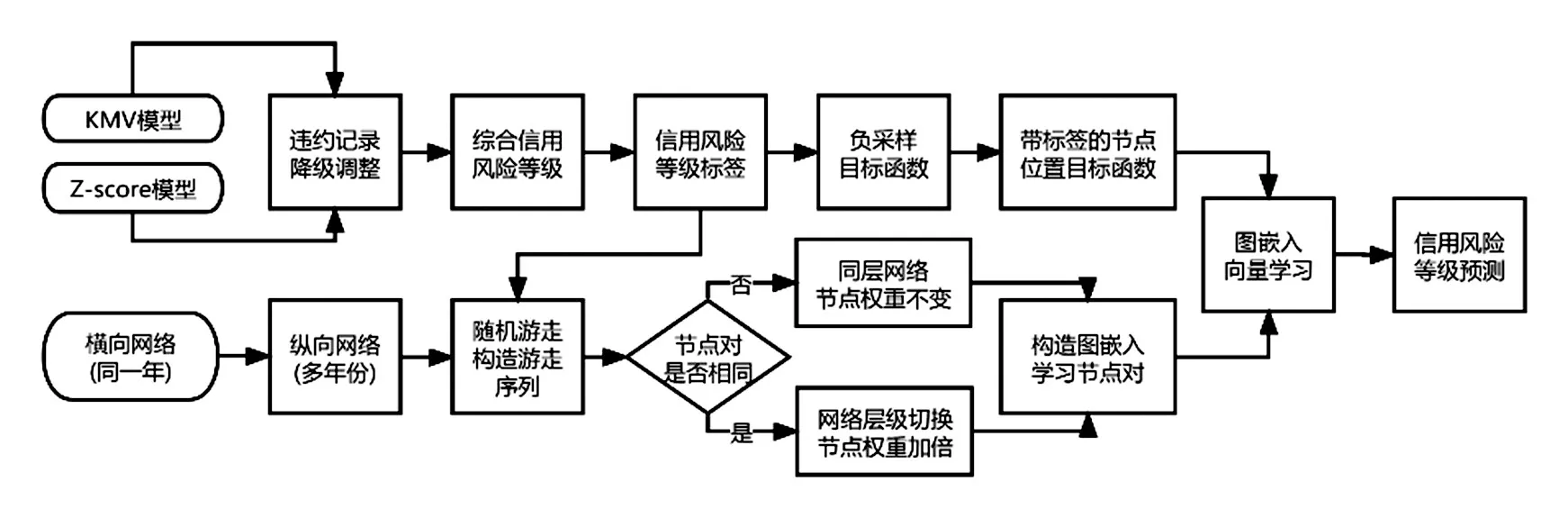
图3 基于持股网络的图嵌入改良方法的流程图
3 模型应用与信用风险预测
基于图3 所示方法的流程图,对2000 至2020 年上市公司信用风险等级进行预测和比较,并对2020年新冠疫情可能带来的影响进行预测.
3.1 信用风险预测与对比验证
实验采用基于初始数据逐步调优的控制变量法来找出相对较优的参数设置和整体最佳的预测效果,调试标准是使得每年预测产生的信用风险等级分布直方图均在符合正态分布的前提下,让实验准确率相对更高.经过反复调试,实验的关键参数设置如下:游走路径长度为6,路径数量为10,窗口大小为1,嵌入向量的维度为256,节点初始化区间为[-1,1],随机梯度下降算法的学习率为0.01.该参数集对应的各年份上市公司信用风险预测值的准确度基本分布在80%上下,最高83.0%(2006年),最低76.9%(2002年).应该说整体的准确率不算太高,这主要是因为持股关系网络的数据不完整,我们仅仅收集了前十大股东中上市公司的信息(资产负债表、利润表和持股比例及违约信息),而不包含大量的非上市公司和个人大股东,并且还忽略了重大事件,尤其是重大政策调整对当期整体信用风险的影响,这必然导致部分预测效果的偏差.
由于本文提出的面向持股网络的图嵌入方法主要受Deepwalk和Node2vec两种算法思想的影响,所以将实验结果与这两种方法进行了对比.在对比实验中,采用多分类问题中更常见的微平均Micro-F1作为预测性能的评价指标.Micro-F1因为考虑了各种类别的数量,同时兼顾了分类模型的精确率和召回率,所以更适用于样本数据分布不平衡的情况,通常在大规模预测中较为常见.图4 展示了三种方法分别在不同游走路径长度、路径数量和嵌入维度条件下,对上市公司信用风险等级进行预测的对比情况,其中实验数据为2015年的数据集,Deepwalk算法的返回概率p=0.25,游走方向控制参数q=4.
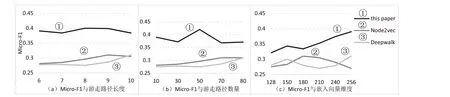
图4 三种图嵌入方法在不同参数下的预测性能对比(2015年)
如图4 所示,在不同参数下本文方法的预测性能均明显优于其他两种经典方法.主要原因是两种经典方法关注的仅仅是节点间的相似性,研究对象主要是网络结构;相比而言,本文在研究网络结构之外,还重点考察了节点自身的属性,即信用风险.而一些特殊的结构,如自环,经典方法不适用,但在多年份持股网络中却有着特殊的经济意义(跨年游走).此外,本文采用全局标签向量的方法,让嵌入向量具有实际意义,更加便于理解,同时本文还针对性地提出二次优化函数,使得结果值可以直接对应等级分类;而其他两种方法只有相对的结构含义,其产生的节点向量无法直接用于分类指导.
3.2 预测新冠疫情对上市公司信用风险的影响
2020年起,受新冠疫情的影响,我国经济受到较大的冲击,首当其冲的就是交通运输、住宿餐饮和旅游等行业,它们受疫情影响的严重性和持续性尤为突出[11].依据2016 版中证行业分类的标准(共9个一级大类),交通运输、住宿餐饮和旅游共同归属于“可选消费”行业,该类行业在2020年上市公司中的占比约为16%.为模拟疫情对于宏观经济的影响,分析疫情对不同行业的冲击程度,本文假设所有可选消费行业上市公司的信用风险全部一次性降低两级.这样的处理将首先导致65%左右的可选消费行业上市公司的信用标签从原来的good 状态转变为bad 状态,然后使用原始状态和调低信用风险之后的状态作为初始标签分别进行预测,以计算疫情对全行业信用风险等级的影响.
当调低可选消费行业上市公司信用风险后,信用风险将借助持股网络进行传染,进而影响所有行业.本文据此作出了各行业信用风险等级下降的公司数量占所有等级下降公司比例的预测图(图5.a);同时,选取国泰安的真实数据,分别计算2019 年和2020 年的上市公司风险等级数据,以统计各行业信用风险等级下降的实际占比(图5.b).
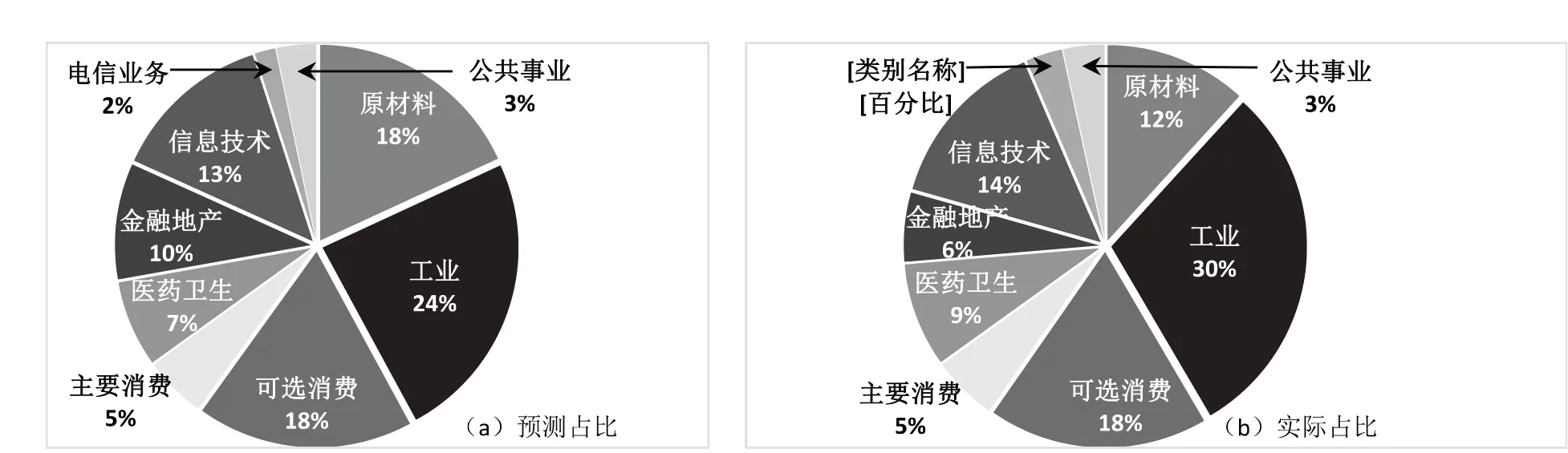
图5 2020年受疫情影响的信用风险等级下降行业预测与实际比例
由预测图可知:(1)工业是信用风险等级下降量最多的行业,占比近四分之一,其次才是可选消费行业(18%).由于我国GDP 中工业占比远高于世界平均值,而这次疫情直接冲击着全球的供应链生态,导致企业销售和原料两头受困,将对工业类上市公司产生长期且深刻的影响.这与刘志彪等学者认为疫情对制造业的影响比服务业可能更加严重的预测是不相符的[12-13].(2)原材料和信息技术行业的信用风险等级下降的比例都超过10%,疫情对这两个产业的影响也比较大.(3)公共事业和电信业务领域的等级下降占比最小,不超过3%,说明其所受影响较小,抗风险能力最强.整体而言,预测数据基本拟合实际值,模型准确判断出工业信用等级下降的比例最大,原材料和公共事业的实际下降数较少,总体准确率较高.
4 结论
从2019年开始,我国经济受到外贸环境恶化、通胀压力持续、资源环境约束等多重不利因素的冲击,当年12月份新冠疫情逐渐开始爆发,疫情延续至今.虽然经过灵活有效的宏观调控,我国经济基本保持了稳定,但这些冲击还是让我国大量的上市公司面临沉重的现实困境和潜在风险隐患.后疫情时代,如何通过上市公司的财务状况、持股关系和关联交易等信息进行信用风险的综合分析与预测,显得尤为重要.因为在经济全球化的今天,单一公司的风险很可能直接或间接影响多家关联公司,尤其在整体经济形势长期低迷的情况下,一些表面毫不相关的公司也可能受其牵连.
本文基于经典图嵌入算法,对游走方式、全局标签、目标函数等方面进行针对性改良,在信用风险的预测时不仅考虑公司自身财务指标和违约记录导致的风险,还依据持股网络关系引入其他关联公司的信用风险影响,并从多个时间维度为上市公司进行画像,全面立体地考察信用风险的传染过程,取得了良好的实验效果.本文的研究方法既可以广泛地应用于整体经济形势或行业领域的宏观预测、评估和调控指导,也可以针对某些具有复杂持股关系和债权债务关系的企业公司的信用风险进行微观分析和决策参考.未来还可以在持股网络的基础上,进一步引入关联交易、债务关系,甚至企业核心人员的关系网络等其他关联信息,将信用风险的传播和预测延伸到更多的维度上去.
