融合视觉信息的语义导航实体搜索算法*
2022-03-04杨观赐
江 涛,杨观赐,李 杨
(贵州大学现代制造技术教育部重点实验室,贵阳 550025)
0 引言
当前,移动机器人已经在工业生产、物流搬运和家庭服务等领域中扮演重要角色[1]。服务机器人作为移动机器人重要组成部分,通常工作于以人为中心的复杂环境中,这为服务机器人实现人机交互能力的提升带来了挑战,因此如何帮助服务机器人理解环境,在人类环境中达到良好的工作状态是一个值得研究的问题。
针对服务机器人要求实时性以及智能化导航的特点,文献[2-4]基于语义地图提出了一种解决方案,其利用SLAM(simultaneous localization and mapping)技术建模三维点云空间环境,缓解了实时性以及智能化导航的问题。但由于其系统模型对算力要求高,实时性要求难以得到保证,难以实现机器人的实时导航。针对现有机器人语义地图构建方法硬件要求高、可移植性差和不利于人机交互等问题,SUNDERHAUF等[5]探索了一种基于卷积神经网络(CNN)的场所识别和语义地图方法,其能够识别厨房、办公室、走廊等多个室内场所。但该方法对场景识别不够准确,导致一些错误的语义映射结果。胡美玉等[6]提出了一种基于深度学习技术的移动机器人实时语义地图构建方法,但这种方法所建立的语义地图每个物体之间缺少关联性,无法满足机器人以人的习惯进行实体搜索要求。CRESPO等[7]提出了一种在室内环境中的语义导航,提出本体和包含在关系数据库中的环境信息的设想,但其没有明确定义房间和物体之间的关系。YANG等[8]提出了一种在家庭环境下能够迅速重定位且节约了字典存放机制的问题,但其只是在SLAM性能上优化了算法,并不具备使服务机器人完成语义导航与实体搜索能力。
以上研究在一定程度上能够增强服务机器人的导航能力,但都不足以解决家庭服务机器人在导航系统中导航交互与实体搜索能力不足的问题。基于此,本文设计了一种面向语义导航的实体语义知识库,提出一种融合视觉信息的语义导航实体搜索算法,以使服务机器人具有高水平的环境感知和行为推理性能。
1 基于Places205-AlexNet的场景自适应语义地图构建
为使机器人理解其周围环境,提高机器人对场景标注的灵活性,本文通过检测室内空间物体以达到室内场景识别目的。首先,基于Places205-AlexNet对每幅图像进行分类,该网络模型专门针对地点识别任务训练[9-10]。将机器人场景识别后得到的场景信息映射到激光SLAM构建的地图后形成场景语义地图,如图1所示。室内家庭环境场景自适应语义地图构建步骤为:
步骤1:加载激光SLAM构建的栅格地图,判断系统中是否存在该场景的语义地图,即地图中是否有场景标记,若存在,跳转到步骤5,反之跳转到步骤2;
步骤2:基于Places205-AlexNet对每幅图像进行场景识别,得出分类结果;
步骤3:机器人利用激光SLAM数据获取在栅格地图中自身的位置坐标,利用递归贝叶斯滤波更新地图单元格中的语义类概率;
步骤4:将场景识别结果映射到栅格地图,得到具有场景语义信息的语义地图;
步骤5:保存带有场景信息的语义地图,得到如图1的室内家居环境场景语义地图。
在步骤3中,机器人获得场景识别结果后,机器人利用激光SLAM估计自身的坐标,并将激光扫描到的房间区域内的地图单元格用场景标签标记。

图1 室内家居环境语义地图
2 实体在语义地图上的位置映射方法
2.1 基于YOLO v3的实体语义信息获取方法
为使服务机器人具备室内物体识别能力,本文基于Yolo v3预测室内环境中的物体并计算每个边界框中的tx、ty、ph、pw坐标,提取边界框内像素以计算物体空间位置[11]。

图2 使用维度先验和位置预测的边界框
如图2所示是本文所用被检测对象的边界框,边框的输出通过4个坐标表示,[tx,ty]为边框的左上角坐标,边框的宽度和高度分别记为tw和th。记单元格与图像左上角的偏移量为(cx,cy),且边界框先验的宽度和高度为pw和ph,预测值为:
bx=σ(tx)+cx
(1)
by=σ(ty)+cx
(2)
bw=pwetw
(3)
bh=pheth
(4)
本文使用均方误差函数来计算目标矩阵与预测矩阵的损失,从而有效的训练模型。将训练好的模型部署在服务机器人平台,并对模型检测出的物体进行位置计算,使服务机器人平台具有目标检测及目标定位的能力。
2.2 实体空间位姿计算
提取YOLO v3计算出的物体检测框坐标xmin、ymin、xmax、ymax内的像素点计算物体空间位置,其中(xmin,ymin) 为测框的左下角坐标,(xmax,ymax)为测框的右上角坐标。本文选取检测框中点进行计算,检测框中点的计算公式如下:
(5)
(6)
通过Kinect相机获取图像的深度值,然后根据像素来匹配点云,进而得到物体相机坐标系下的Xc、Yc、Zc,计算公式如下:
Xc=(u-cx)·z/fx
(7)
Yc=(v-cy)·z/fy
(8)
Zc=d/cf
(9)
式中,(u,v)表示图像像素坐标;d为某点的深度值;fx、fy分别为相机在x轴和y轴上的焦距,cf=1000。此时我们得到的是物体在相机坐标系下的坐标,要得到物体在机器人坐标系下的坐标需要进行如下转换:
(10)

3 融合视觉信息的语义导航实体搜索算法
3.1 面向语义导航的实体语义知识库构建方法
针对家庭服务机器人在语义导航系统中导航交互与实体搜索能力不足的问题,提出一种面向语义导航的实体语义知识库构建方法。该知识库允许服务机器人在执行语义导航的任何环境中管理并查询相关语义信息,以提供一种简单概念和语义环境之间快速切换方法。
为方便后文理解,我们做出如下定义,flag符号为移动标记,若物体移动,则flag=1,反之为0。在机器人地图坐标系下,用Pc(x,y,z)表示物体在机器人坐标系下的位置。依据本文所搭建的家庭环境,我们将家庭环境分为以下场景:E1:办公室;E2:卧室;E3:厨房;E4:客厅;E5:书房。各实验场景实验物体见表1。

表1 实验场景实体列表
在实际工作环境下,物体相对于场景的位置经常会发生改变。为解决这一问题,我们依据物体与场景之间的逻辑与空间关系,定义了服务机器人在寻找相关物体时的场景优先级,以便于服务机器人能够高效率的寻找到相关物体,从而提高服务机器人在家居环境下的快速定位导航能力与目标搜索准确率。基于此,机器人语义地图中物体语义信息的关系表如表2所示,是服务机器人基于场景优先级规则做出的部分路径规划。

表2 机器人语义表
如表2序号1,机器人所处位置为R1,而物体d1(长桌)依据路径优先级关系推断为属于场景E1(办公室),机器人读取物体在E1场景中的坐标位置P1(x,y,z),再依据物体位置规划路径为R1→E1。序号2与序号1类似。物体c3(水杯)所处位置为场景E3(厨房),依据语义知识库先验知识,机器人能够依据路径优先级关系推断c3属于E3场景,由此读取E3场景中的物体位置P3(x,y,z),再依据物体位置规划路径为R3→E3,此时若水杯被移动过(不在E3场景),机器人则按照R3→E3→E5→E4→E2→E1的路径优先级寻找水杯。序号4与序号3类似,台灯通常不会出现在厨房,所以机器人在寻找台灯时不会前往场景E3的搜索,避免在没有可能的场景寻找物体。其中Rc为机器人在接收指令时所处的地图坐标系下的位置。
3.2 融合语义知识库的语义导航实体动态搜索算法
面向语义导航的实体语义知识库为机器人在语义导航时提供快速查询并管理相关语义信息的功能,在进行实体搜索任务时,读取知识库中的内容并分析,提取环境中实体的相关信息,可推断出物体移动情况下可能出现的场景,从而完成实体动态搜索过程。例如,机器人接收到 “寻找水杯”命令的实体动态搜索算法具体步骤为:
输入:语义地图Maps、语义知识库Ks;输出:搜索结果Research。
步骤1:查看flag值,根据flag的值决定寻找水杯的路径,若flag=0,机器人认为在构建语义地图后水杯位置没有发生变化,转到步骤2,若flag=1,机器人认为水杯位置在语义地图构建之后改变,转到步骤3;
步骤2:读取语义知识库中存储的水杯默认位置P3(x,y,z),导航到场景E3寻找水杯,此时导航路径为:R3→E3,若找到水杯,则跳转到步骤4,反之,跳转到步骤3;
步骤3:由语义知识库路径优先级得到可能出现水杯的场景中,场景E*优先级最高(E*为语义知识库中场景路劲优先级列表),于是导航路径为:R3→E*,若找到水杯,则跳转到步骤4,若没有找到,则重复步骤3,直到所有区域都搜索完成;
步骤4:令语义知识库中flag=1,返回搜索结果Research,结束寻找。
上述语义导航实体动态搜索算法在服务机器人执行语义导航任务时,可帮助机器人根据语义知识库先验知识,快速定位导航目标。
4 语义导航系统测试与分析
4.1 家庭服务机器人平台
为测试本文系统的鲁棒性与准确性,搭建了家庭服务机器人平台[13-15]。将上文所提融合视觉信息的语义导航实体搜索算法集成于服务机器人平台,形成家庭服务机器人语义导航实体搜索系统。系统以EAI dashgo B1作为机器人移动底盘,搭载Inter NUC微型计算机作为机器人上位机,处理来自麦克风阵列和相机的数据,并进行上层调度规划。服务机器人平台以Kinect v2深度相机作为室内场景识别和目标检测的视觉传感器,麦克风阵列获取人发出的语音指令并转换为文本信息,并配备了16英寸工业触摸屏,用于人机交互,系统整体框架如图3所示。

图3 系统整体框架图
硬件层由传感器和执行部件组成,为MAT平台提供环境数据以及执行相应操作;控制系统层为MAT平台数据处理和算法处理中心,为人机交互层提供软件支持;交互层提供目标识别、语音识别、语义地图构建和语义导航功能。
4.2 实验设计与测试
为测试系统鲁棒性与准确性,本文模拟一般情况下的家庭环境。由于实验环境限制,本文在场景E3中摆放虚拟冰箱。实验场景以及场景所包含的实验实体如表1所示,实验模拟家庭环境图如图4所示,并进行如下实验设计。
实验1为验证本文系统场景定位系统收到指令后对目标场景定位结果的正确性,本文设计了场景定位实验从定位正确率方面验证系统的有效性,如表3所示。
实验2为验证系统的单个物体识别准确率,本实验将测试在E1~E5场景下单个物体的识别准确率,如表4所示。
实验3为验证系统识别单个物体的鲁棒性与有效性,实验测试在E1场景下多个物体的识别准确率,具体为在E1场景下,(1)桌子与打印机同时存在;(2)桌子与电脑同时存在;(3)桌子、电脑与打印机同时存在,如表5所示。
实验4为检测系统在全场景下的识别准确率与鲁棒性,本实验设计如下,(1)搜索未移动情况下的实体,如表6所示;(2)搜索移动情况下的实体两种情况,如表7所示。

图4 实验模拟家庭环境图
4.3 实验结果与分析
综上所述,我们进行了相关实验以分析本文系统的有效性,为直观展示本文实验效果,本文在获取实验数据的情况下还进行了可视化分析以帮助我们动态的调整本文参数,目标场景定位结果及可视化效果如图5所示,实体未移动情况下语义目标搜索及实体移动情况下语义目标搜索可视化效果图如图6、图7所示。
表3统计了目标场景定位结果的正确率,整体而言,系统的整体识别率均在0.80以上,这表明所提出的场景自适应语义地图构建方法能够有效地识别家庭环境,见图5。其次,本文在E1~E5场景的错误识别率分别为0.00、0.20、0.15、0.20与0.05,由此可见本文算法在E1场景能够保持较高的识别率,但与此同时本文对E2和E4场景的识别准确率较低,这体现了本文算法对于E2和E4场景的识别不够敏感,在后续的改进版本中应加强对E2和E4场景的数据采集,从而提高系统的识别准确率。
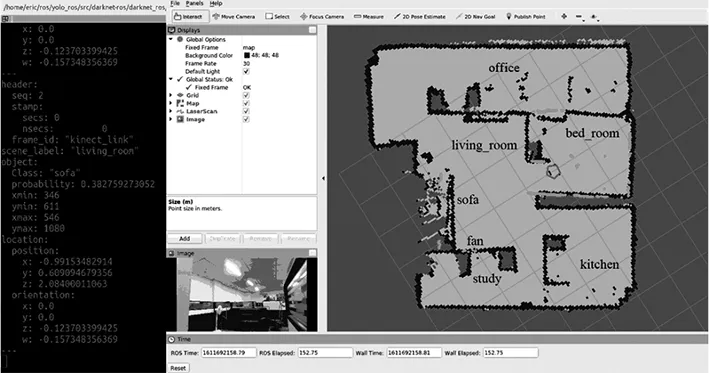
图5 目标场景定位结果及可视化效果

表3 目标场景定位结果的正确率
如表4所示,实验测试本系统在E1~E5场景下识别不同物体的准确率,从中可以得出当物体为c1、c2、e和t2这类物体时,系统表现出了较高的识别准确率(均为1.00),这表明系统在电脑、椅子、电饭锅及台灯这类较小物体时具有较高的准确率,而如b1床、s沙发这类大物体时准确率较低。这是因为相机具有一定的视角范围,并且固定安装在机器人一定高度位置,在识别物体时受相机视角的影响,导致识别较小物体时能够观测完全,而在面对较大件物体时无法得到相对合适的图像,从而导致了大件物体准确率不够。整体上,系统在多场景单物体情况下系统的物体识别准确率在0.75~1.00,这表明系统的物体识别算法能够有效的识别家庭环境中的物体。

表4 多场景单物体情况下系统的物体识别准确率
如表5所示,在对E1场景下的多个物体进行识别检验时,d1长桌和p打印机同时识别的准确率最低,而c1电脑的识别基本不受周围物体的影响。物体识别率整体上保持在0.80以上,这表明系统具有较好的鲁棒性与有效性。

表5 单场景(E1)多物体情况下系统的物体识别准确率
如表6所示,在搜索未移动情况下的实体时,语义目标的导航准确率普遍较高,这是因为系统对于未移动的实体场景信息和空间关系信息存储在实体语义知识库中,执行搜索任务时可根据实体先验信息快速寻找到目标实体,如图6所示。这表明本文所建立的面向语义导航的实体语义知识库有助于增加系统对于实际家庭环境下语义目标的导航搜索准确率。

表6 搜索未移动实体情况下语义目标的导航准确率

图6 未移动实体情况下语义目标搜索可视化效果图
考虑到现实生活中物体具有被移动的性质,表7统计了搜索实体移动情况下语义目标的导航准确率,相对比于搜索未移动物体情况下语义目标的导航情况,其准确率分别下降了0.05、0.10、0.00、0.10、0.15及0.05,这是因为物体的位置更换导致了实体语义知识库中相对应的语义信息不再准确,机器人执行导航搜索任务时只能通过场景优先搜索路径去逐一寻找,如图7所示。

表7 搜索实体移动情况下语义目标的导航准确率

图7 移动实体情况下语义目标搜索可视化效果图
尽管在这种情况下导航准确率有所降低,但在20次的实验中,准确率基本保持在0.85左右,这表明本文设计的语义导航实体搜索算法能够使系统具有较好的鲁棒性和准确性。以上实验表明,本文系统能够较好的完成家庭环境下服务机器人语义导航实体搜索任务。
5 结论
综上所述,针对家庭服务机器人导航系统缺乏环境语义信息的问题,本文提出了一种融合视觉信息的语义导航实体搜索算法。该算法借助移动平台的导航和实时避障功能,并融合环境中的视觉语义信息完成语义导航任务。在实验测试中,服务机器人系统能够利用所建立的语义地图和实体语义知识库很好执行实体搜索任务,并且在实体移动情况下,系统搜索模块依然可以根据知识库中场景路径优先级进行导航定位,并最终寻找到物体。实验结果表明,融合视觉信息的语义导航实体搜索算法增加了服务机器人的自主性,能够较好的完成家庭环境下服务机器人语义导航实体搜索任务,为服务机器人自主与智能化导航问题奠定了一定基础。
