改进的SSD算法在智慧交通中的应用*
2022-03-03杨艳红钟宝江2徐云龙
杨艳红,钟宝江2,徐云龙
(1.苏州大学应用技术学院 工学院,江苏 苏州 215325;2.苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引 言
随着当今城市人口和车辆越来越多,交通堵塞、交通安全等问题也日益严重,给城市发展带来了很大影响。为了解决交通问题,我国各城市智慧交通发展如火如荼,人工智能、机器学习、计算机视觉、深度学习等均在智慧交通发展中起到了重要作用。
在智能交通管理中,通过准确检测交通工具可以实现目标车辆监控、车流量统计、违法车辆追踪等,因此如何正确识别并检测交通工具具有非常重要的意义。目标检测的任务是找出图像中感兴趣的目标,并确定它们的位置与类别。近年来,卷积神经网络提取图像特征为目标检测等带来很大的提升,并且很多学者将其应用在各种领域[1-6]。目前很多学者提出了基于深度学习的目标检测算法,主要分为基于候选框的目标检测算法和基于端对端学习的目标检测两类。前者检测精度好,但是检测效率较慢,如R-CNN[7]、Fast R-CNN[8]、Faster R-CNN[9]等算法。后者将图像数据输入网络,不再单独提取候选框,直接对全图进行卷积和池化处理后提取有效特征层后回归出目标类别及目标区域,真正实现了端到端的训练。此类算法检测精度低于基于候选框的目标检测算法,但其检测效率高,如SSD(Single Shot MultiBox Detector)[10]、YOLO(You Only Look Once)[11]等算法。
SSD目标检测算法在当前主流算法中检测效率和准确率均较为优异,因此很多学者选择SSD目标检测算法。本文在其他学者研究的基础上参考金字塔网络对SSD算法的网络结构进行改进,可以更准确地实现交通工具目标检测。主要改进有:一是对SSD网络结构进行调整,将有效特征层block4、block7、block8、block9、block10、block11相邻层进行融合,同时减少卷积深度,提升了目标检测的准确率及计算效率;二是对有效特征层增加批处理,再进行目标分类预测,使模型能够更好地学习适应不同的数据分布,提高泛化能力;三是先验框由原来的8 732个改进为8 728个,略微提高了计算效率。
1 相关工作
1.1 SSD目标检测算法
SSD算法在图片的不同位置进行密集抽样,再利用卷积神经网络提取特征后进行目标检测。由于目标检测过程只需要一步,因此该算法速度快,并且在准确率上比YOLO等算法高很多。SSD目标检测算法成为了近几年比较流行的目标检测算法之一,它的基础模型是VGG16,在VGG16的基础上又增加了新的卷积层来获取更多的特征图用来检测。SSD目标检测算法的网络结构如图1所示。
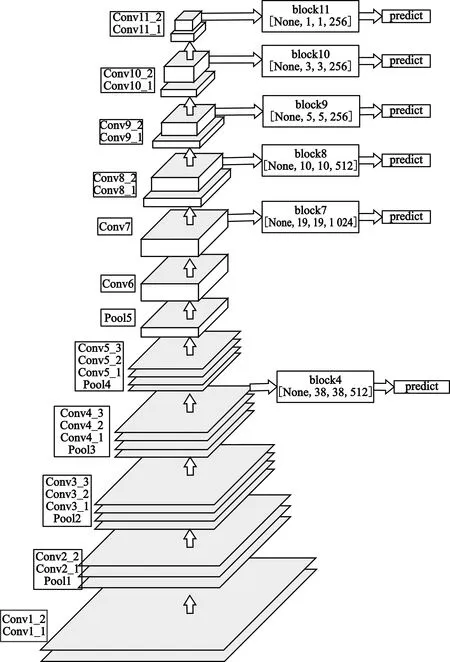
图1 SSD目标检测算法网络结构图
SSD网络结构图中,Conv1_1~Pool5为VGG16模型,Conv6~Conv12_2为SSD新增加的卷积层。SSD算法选取VGG16卷积层中的Conv4_3以及SSD新增卷积层Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2作为检测所用的特征图,它们的大小分别为(38,38)、(19,19)、(10,10)、(5,5)、(3,3)、(1,1),其中Conv7、Conv10_2、Conv11_2对应4个先验框,其余特征图对应6个先验框,因此共需要预测8 732个先验框,其工程量相当庞大。
SSD目标检测算法有以下优点:一是不再使用全连接层,计算效率提高;二是对输入图片的大小没有要求,图片输入后再统一修改尺寸,更加灵活;三是不再先提取候选框后对候选框预测,直接利用卷积一步计算出候选框和预测分类,简化流程。但是,SSD算法也存在一些缺点,主要是对小目标检测不够准确,并且在block7预测时深度较大。
1.2 特征金字塔网络
特征金字塔网络(Feature Pyramid Network,FPN)[12]在小目标检测上优于SSD目标检测算法,它主要解决物体检测中的图片不同尺度的问题。FPN分为自底向上卷积和自顶向下连接两部分,将高层特征图通过上采样变为和低一层的特征图一样大小,然后和低一层的特征图连接,再进行预测。
FPN网络结构如图2所示,左侧最底层为原图,经过卷积后依次得到高层,右侧对左侧相应层做2倍上采样后与左面下一层相连接,依次得到右边3层然后分别预测。FPN算法能将高层特征的语义信息和低层特征高分辨率相融合,通过融合后的特征进行预测。
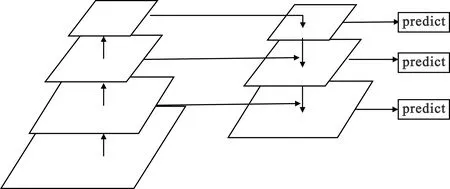
图2 FPN网络结构图
2 改进的SSD目标检测算法
2.1 改进的SSD网络结构
由于交通状况复杂,交通工具的检测准确率受到一定影响。为了提高目标检测的准确率,本文对含有丰富语义信息的高层特征图和含有丰富位置信息的低层特征图进行有效融合,从而适当弥补高层特征图位置信息表达能力不足的缺点。其网络结构如图3所示,虚线框内为5个有效特征层及其预测。
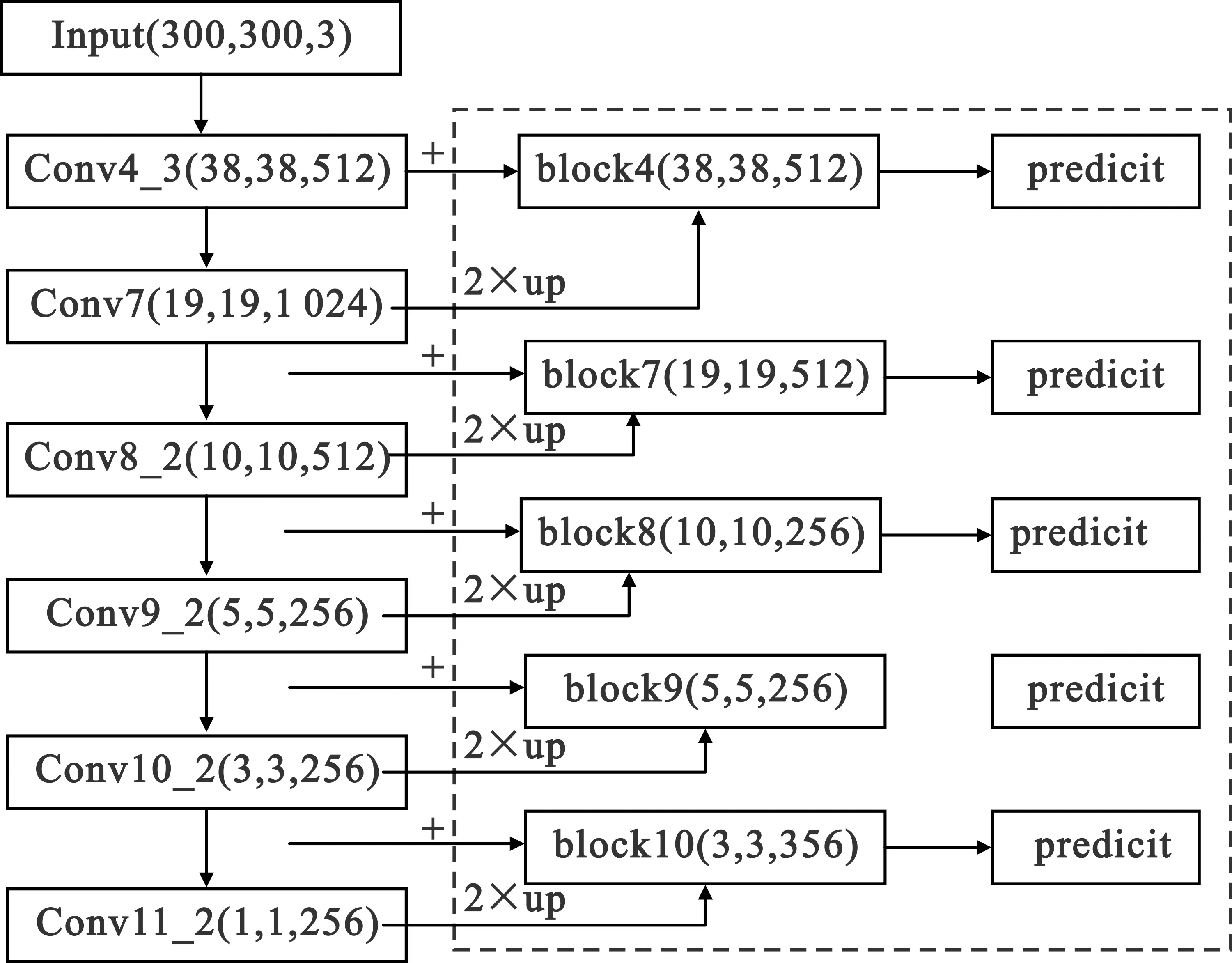
图3 改进的SSD目标检测算法网络结构
改进的SSD目标检测算法借鉴FPN金字塔网络结构的思想,对高层信息采用双线性插值法进行上采样,与相邻底层信息进行特征融合。上采样是利用已知图像矩阵中的点来确定未知的点,从而扩大图像尺寸,文中采用双线性插值法[13-14]实现上采样。双线性插值利用原图像目标点四周四个真实存在的值来共同确定目标图像矩阵中的一个未知的值,如图4所示,Q11(x1,y1)、Q12(x1,y2)、Q21(x2,y1)、Q22(x2,y2)为原图像矩阵中的四个点,P为需要求的未知点。

图4 双线性插值算法图示
在图4中,x方向的插值是在Q11、Q21之间插入点R1,在Q12、Q22之间插入点R2,根据式(1)、(2)可求解R1、R2:
(1)
(2)
通过计算出来的R1、R2可以求y方向的线性插值,从而计算得到P点,如式(3):
(3)
改进的SSD网络结构低层依旧使用VGG16,图像输入大小为300×300。为了提高计算效率将Conv7由图1中的[None,19,19,1 024]修改为[None,19,19,512],通道变为原来的一半。Conv4_3~Conv11_2参考FPN金字塔网络结构进行改进,将相邻两层进行融合运算,如SSD中原来的block11对应的Conv11_2采取双线性插值向上采样由原来的维度[None,1,1,256]变为[None,3,3,256],与Conv10_2进行融合变为block10,依次求block9维度为[None,5,5,256],block8维度为[None,10,10,256],block7维度为[None,19,19,512],block4维度为[None,38,38,512]。
一种交通工具一般情况下不会超过图片的50%,因此改进的SSD算法选择38×38、19×19、10×10、5×5、3×3共5个尺度的特征图进行目标检测,丢弃了原SSD算法中Conv11_2对应的1×1特征图。在后续实验中证明去掉1×1特征图对检测效果并无明显变化,因此不再使用原SSD算法中最大的先验框,即特征图为1×1的Conv11_2层。
与SSD算法相比较,改进的SSD算法block7最后一维度变小,并且不再计算SSD中block11,因此在计算效率上有所提高。
2.2 归一化
卷积神经网络在学习过程中是为了学习数据分布,训练数据与测试数据分布不同会使网络泛化能力大大降低。针对每批次数据的分布不同,网络需要在每次迭代后去学习适应不同的分布也会降低网络训练速度,因此对有效特征层的信息做归一化处理后再进行预测。传统的SSD只对conv4_3做L2范数,此种方法只是在单张图片的channel上做归一化,并未涉及到多张图片之间的问题。本文借鉴FSSD[15]对改进的SSD做BN(Batch Normalization)[16]归一化之后再进行预测。后文中提到的改进的SSD算法均指对SSD实现两层融合并增加BN后的算法。BN是网络的一层,对特征层的信息进行批量标准化。在卷积神经网络中,Batch就是训练模型时设定的图片数量即batch_size。BN归一化过程如下:
输入:B={x1,2,…,m},γ,β。
输出:{yi=BNγ,β(xi)}。
求均值:
求标准差:
归一化:
线性变换:
增加BN后的网络结构如图5所示。
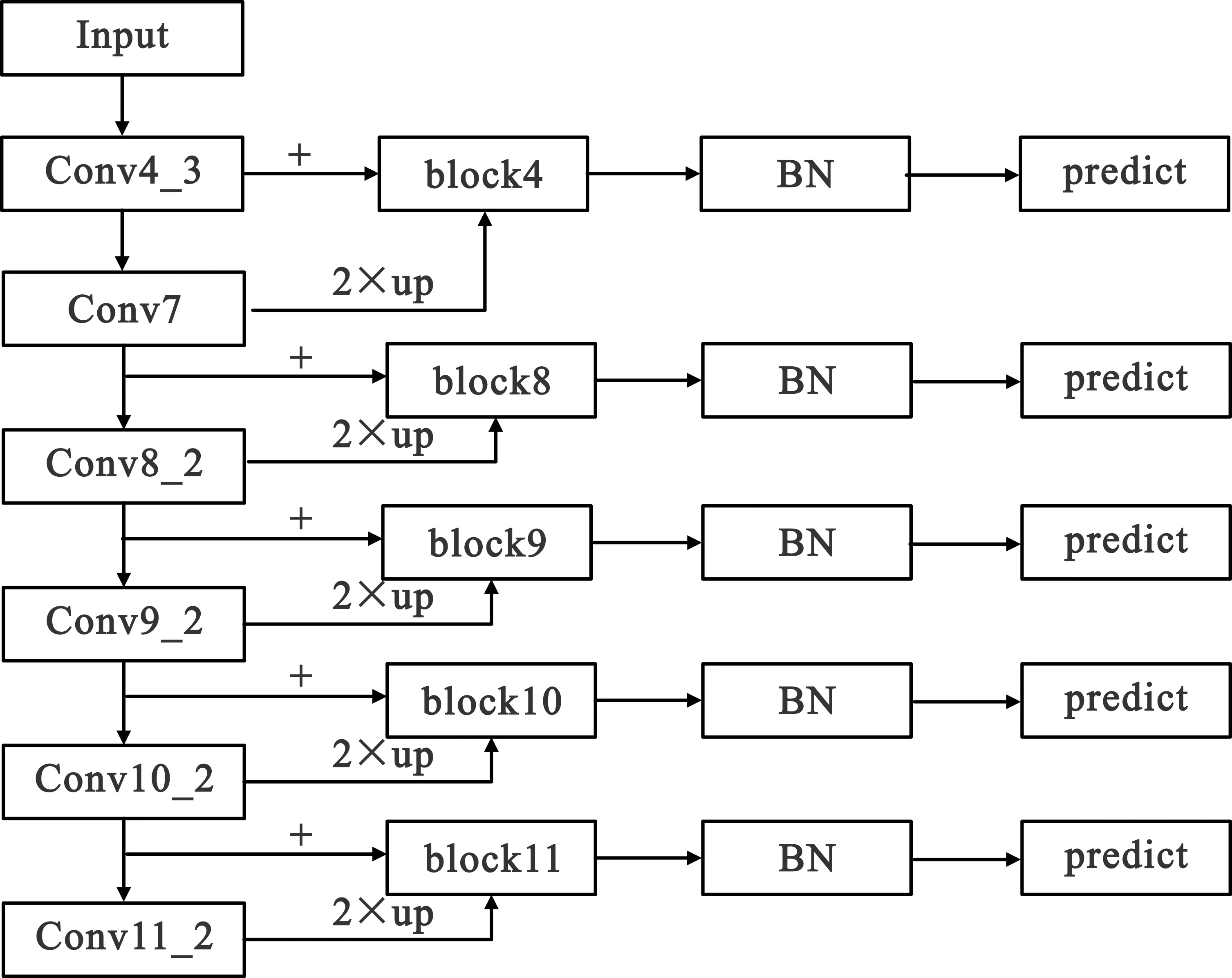
图5 增加BN后改进的SSD网络结构图
改进的SSD网络结构中,对有效特征层block4、block7、block8、block9、block10进行BN归一化处理后再进行位置与类型预测。
2.3 损失函数
目标检测损失函数由位置误差Lloc和类别置信度误差Lconf两部分组成,如式(4)所示:
(4)
式中:x为当前预测框的类别信息;c为预测框信息的置信度;l为预测框的位置;g为真实框的位置;N为先验框的正样本数,即与真实目标框相匹配的先验框;α为权重系数;Llocf(x,c)为类别置信度误差,采用交叉熵损失函数;Lloc(x,l,g)为位置误差,采用smoothL1损失函数。
类别置信度误差Lconf(x,c)是Softmax多类别损失函数,如式(5)~(6)所示:
(5)
(6)
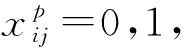
位置误差Lloc(x,l,g)是预测框与真实框之间的smoothL1损失,如式(7)所示:
(7)
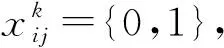
3 实验与分析
3.1 实验环境
本次实验在Win10 64位操作系统下,使用TensorFlow框架构建改进的SSD神经网络。硬件配置:CPU为Intel(R) Core(TM)i7-9700K CPU @ 3.60 GHz;内存为16 GB;GPU为NVIDIA GeForce RTX 2060 SUPER。
3.2 实验过程
实验所用训练数据集为Pascal VOC2012和VOC2007的训练数据集,测试集为Pascal VOC2007的测试数据集。Pascal VOC2012在目标检测、图像分割网络对比实验与模型效果评估中被广泛使用,该数据集共有21类共17 125张图片。实验需要对交通工具进行目标检测,因此在Pascal VOC2012和VOC2007中选取出bicycle、motorbike、bus、car 4种交通工具的图片及其标注信息,实验中将此部分图片作为训练数据集。
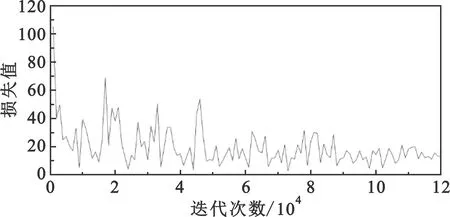
图像输入尺寸为300 pixel×300 pixel,在同样参数配置的情况下对改进的SSD和标准的SSD模型进行实验比较。本文提出的改进的SSD模型在训练迭代几万次后损失值在0~20之间波动。图6所示为改进的SSD与标准的SSD训练12万次的收敛曲线,可以看出SSD损失值稳定在0~40之间,而且稳定性没有改进的SSD好,损失值相对也比较高。
(a)改进的SSD模型
SSD与改进的SSD模型在相同参数及配置下训练12万步后进行比较,如图7所示,在第一张图片中,改进的SSD优于原始的SSD,可以检测出全部小汽车和公共汽车,第二张街道图片中均存在漏检的情况,第三张骑行比赛的图片中均能正确检测出自行车。在检测目标密集并且有遮挡物时两种模型均存在漏检,但是改进的SSD漏检较少。

图7 模型识别效果
单张图片具有特殊性,因此本文选取VOC2007测试集中的4种类别的车辆采用平均检测精度(Mean Average Precision,mAP)对改进后的算法与原算法进行比较。mAP计算方式不唯一,在VOC数据集中,精确度(precision)、召回率(recall)、单类别平均精确度(Average Precision,AP)、mAP分别如式(8)~(11)所示:
(8)
(9)
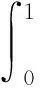
(10)
(11)
式中:TP为真的正样本数,FP为假的正样本数,FN为假的负样本数,n为检测的类别。
对于不同的参数得到的结果会有差别,在同样参数下对改进的SSD、SSD、未加入BN时改进的SSD算法进行比较,4种交通工具的AP值如表1所示。单类别平均精确度数值越高则单类别检测准确度越高。由表1可以看出,不同车辆的检测准确度存在一定差距,三种算法在检测公共汽车时准确度都比较高,在检测自行车、小汽车、摩托车三种较小的目标及目标密集并且有遮挡物时,SSD算法、未加入BN的SSD算法、改进的SSD算法均存在目标漏检的情况,但是改进的SSD算法整体效果优于其他两种算法。
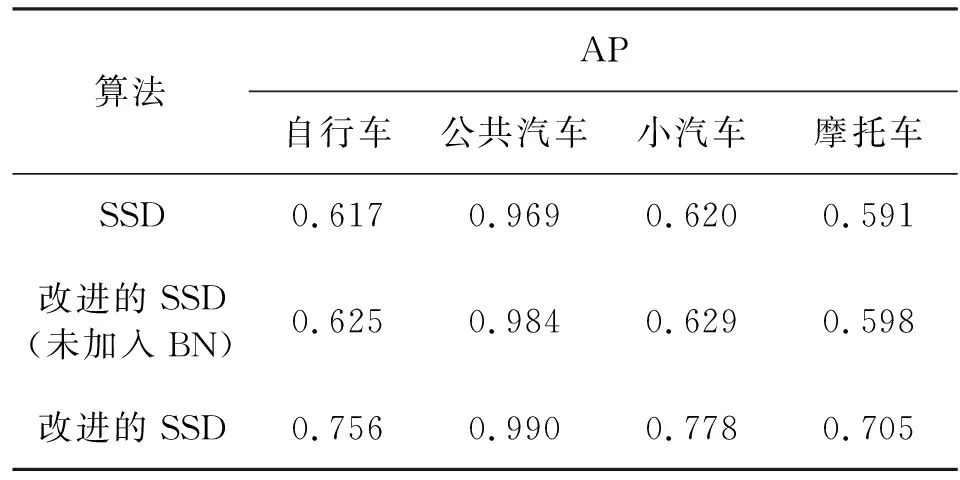
表1 改进的SSD与SSD的 AP比较
本文需要检测并识别4类交通工具,选择用mAP作为评价指标。表2为三种算法在训练5万步和10万步时,每批次检测图像所用时间和四种类别交通工具的平均精确度,每批次用时越短则效率越高,mAP值越高四种类别交通工具的平均检测准确度越高。从表2中可以看出,改进的SSD算法均优于SSD算法和未加入BN时改进的SSD算法。在训练10万步时,改进的SSD算法在准确率上高于标准的SSD算法10.9%,提高了15.59%,用时增加1.28%。

表2 改进的SSD与SSD效率和准确率比较
4 结束语
本文提出了基于深度卷积神经网络改进的SSD目标检测算法实现智慧交通中交通工具的分类及定位检测,可以对图片、已保存的视频、摄像头实时监控视频进行交通工具的检测,准确率达到80.8%,运行速度约每秒识别13帧。改进的SSD目标检测算法可以应用于智慧交通管理系统,帮助交通管理人员进行车辆监控、统计车流量、违法车辆追踪等。但是,本文改进的目标检测算法在复杂环境下均存在漏检现象,今后将围绕如何在复杂环境下提高检测准确率做进一步研究。
