采用光流特征对齐的压缩视频超分辨率重建*
2022-03-01付凌宇王正勇熊淑华何小海
付凌宇,王正勇,熊淑华,何小海
(四川大学,四川 成都 610065)
0 引言
随着通信技术的不断发展,视频在日常生活中的应用越来越广泛。为了满足不同拍摄和成像设备的传输需求,同时为了节省带宽,视频在传输前往往需要先下采样为低分辨率视频再进一步压缩,这将导致视频质量显著下降。为了解决这一问题,高效视频编码(High Efficiency Video Coding,H.265/HEVC)标准[1-2]被提出,该标准针对视频数据中的冗余成分进行压缩,然而在减少视频数据量的同时,也会产生一定的压缩伪影。此外,针对低分辨率视频进行压缩,不仅会降低视频的分辨率,也会进一步损害视频的质量。因此,亟待提出更有效的压缩视频超分辨率重建算法。
近年来,深度学习技术在各个领域都展现出了巨大的潜力,在压缩视频和图像的质量增强方面也得到了越来越广泛的重视。文献[3]提出了第1个神经网络框架——面向减少伪影的卷积神经网络(Artifacts Reduction Convolutional Neural Networks,AR-CNN)来去除单幅图像的压缩伪影。文献[4]将卷积神经网络引入HEVC的环路滤波器中,提出了一种可变滤波器尺寸的残差学习卷积神经网络(Variable-filter-size Residue learning Convolutional Neural Networks,VRCNN),能够有效提升压缩视频的质量。文献[5]将多帧输入的思想引入压缩视频质量增强任务中,提出了一种多帧质量增强网络(Multi-Frame Quality Enhancement,MFQE),通过在网络中设计一个运动补偿模块来利用峰值质量帧增强相邻帧。文献[6]通过使用更加高效的网络模块,将MFQE扩展到MFQE2.0,进一步提升了重建视频的质量。文献[7]在网络中利用了一种时空可变形融合模块(Spatio-Temporal Deformable Fusion,STDF),从而更好地利用了相邻帧的信息,在压缩视频质量增强方面取得了一定的效果。
视频超分辨率重建的目标是从相应的低分辨率(Low-Resolution,LR)视频帧和其相邻帧中重建出高分辨率(High-Resolution,HR)视频帧,从而恢复视频的细节信息,提高视频质量。文献[8]以光流估计和运动补偿作为子模块,提出了第1个端到端的视频超分辨率重建框架。文献[9]、文献[10]、文献[11]延续了文献[8]的思想,利用光流进行相邻帧之间的运动补偿,随后利用这些参考信息来帮助重建高分辨率视频帧。文献[12]在网络中提出了一个亚像素运动补偿层(Sub-Pixel Motion Compensation,SPMC),以充分利用亚像素间的运动信息,并且首次将卷积长短期记忆网络(Convolutional Long Short-Term Memory,ConvLSTM)[13]引入视频超分辨率重建网络中。文献[14]提出了一种时域可变形对齐网络(Temporally-Deformable Alignment Network,TDAN),引入可变形卷积来代替光流估计进行运动补偿。文献[15]提出了一种采用增强的可变形卷积的视频超分辨率重建框架(Video Restoration framework with Enhanced Deformable convolutions,EDVR),该 框架使用了一种新的时空注意融合模块,并且对可变形卷积的运动补偿模块进行了改进。文献[16]通过重新设计一些视频超分辨率的基本模块来改进特征传播和对齐过程,在速度和性能上均实现了一定的提升,这些模块作为视频超分辨率的基础在后续的研究中也得到了广泛应用。
然而,大多数质量增强和超分辨率重建算法仅面向单一任务,无法实现面向压缩低分率视频的超分辨率重建任务。解决压缩视频的超分辨率重建问题的方法分为两种,一种是结合视频压缩编码的先验知识,针对压缩后的低分辨率视频进行优化,如文献[17]提出了一种端到端的恢复重建网络来解决这一问题,该网络在针对压缩视频的超分辨率重建任务上取得了一定的效果;另一种是将此任务分为两步依次进行处理,在提高视频分辨率的同时减少压缩伪影。基于第2种思想,本文通过两个阶段的操作来解决压缩视频超分辨率重建问题,第1阶段使用质量增强网络对视频进行质量增强以减少视频的压缩效应,第2阶段使用超分辨率重建网络将质量增强的低分辨率视频恢复至原始分辨率,进一步提升视频的质量。
1 针对压缩视频的超分辨率重建框架
为了模拟在实际应用中由于拍摄和成像设备的传输限制而导致的某些视频分辨率不足的情况,首先对高分辨率视频进行下采样以获得低分辨率视频。视频的下采样过程可以表示为:
式中:HR为原始高分辨率视频;D为下采样过程;LR为下采样后的低分辨率视频。其次对下采样后的低分辨率视频进行压缩,最终本文的待处理视频可以表示为:
式中:C为视频的压缩过程;V为经过压缩的低分辨率视频。本文旨在将经过压缩的低分辨率视频V恢复重建为质量增强的高分辨率视频。由于待处理视频V依次经过了下采样和压缩两个降质过程,并且在下采样和压缩过程中对视频的处理方式不同,输出视频的降质类型也不同,因此将压缩视频超分辨率重建视为一个单一任务,并且使用独立的网络从待处理视频V中直接恢复重建出质量增强的高分辨率视频比较困难。基于此考虑,本文将压缩视频的超分辨率重建任务分为两个阶段来分别进行处理:首先对待处理视频V进行质量增强来减少压缩过程中产生的伪影,得到质量增强的低分辨率视频;其次对质量增强的低分辨率视频进行超分辨率重建来恢复下采样过程造成的信息损失。将压缩视频的超分辨率重建过程分解为两个阶段,可以更有效地针对下采样和压缩两种不同的降质类型进行处理,网络的独立训练也会更加灵活有效。
本文提出的压缩视频超分辨率重建算法的总体框架如图1所示。

图1 本文提出的压缩视频超分辨率重建算法
如图1所示,所提算法首先对原始视频进行下采样操作得到相应的低分辨率视频;其次对低分辨率视频,通过HEVC编码标准进行压缩编码得到相应的码流;最后码流经过HEVC解码得到压缩后的低分辨率视频,即本文的待处理视频。对待处理视频,本文首先通过一个质量增强网络来减少编码过程中产生的压缩效应,得到质量增强的低分辨率视频;其次通过超分辨率重建网络将质量增强的低分辨率视频恢复至原始分辨率。该算法框架可以表示为:
式中:xt为压缩后的低分辨率视频;yp为质量增强的低分辨率视频;hp为针对压缩降质类型的质量增强过程;hs为针对下采样降质类型的超分辨率重建过程;ys为最终获得的质量增强的高分辨率视频。待处理视频依次经过质量增强网络和超分辨率重建网络进行处理,得到的输出视频在有效去除压缩伪影的同时,能很好地恢复下采样过程造成的信息损失,最终实现高质量的高分辨率压缩重建视频。
2 网络结构
本文的压缩视频超分辨率重建框架由质量增强网络和超分辨率重建网络构成,二者的网络结构相似。质量增强网络可以在超分辨率重建网络的基础上关闭上采样模块来获得,因此本文着重介绍超分辨率重建网络的具体细节。
2.1 超分辨率重建网络
超分辨率重建网络结构如图2所示。输入视频帧首先通过一个残差块来进行特征提取,这些特征以双向传播的方式在网络中进行传播。其中,对齐方式采用基于光流的特征对齐以获得更好的性能,对齐后的特征通过多个残差块进行进一步的细化,随后通过一个卷积层和pixel-shuffling层生成输出视频帧。
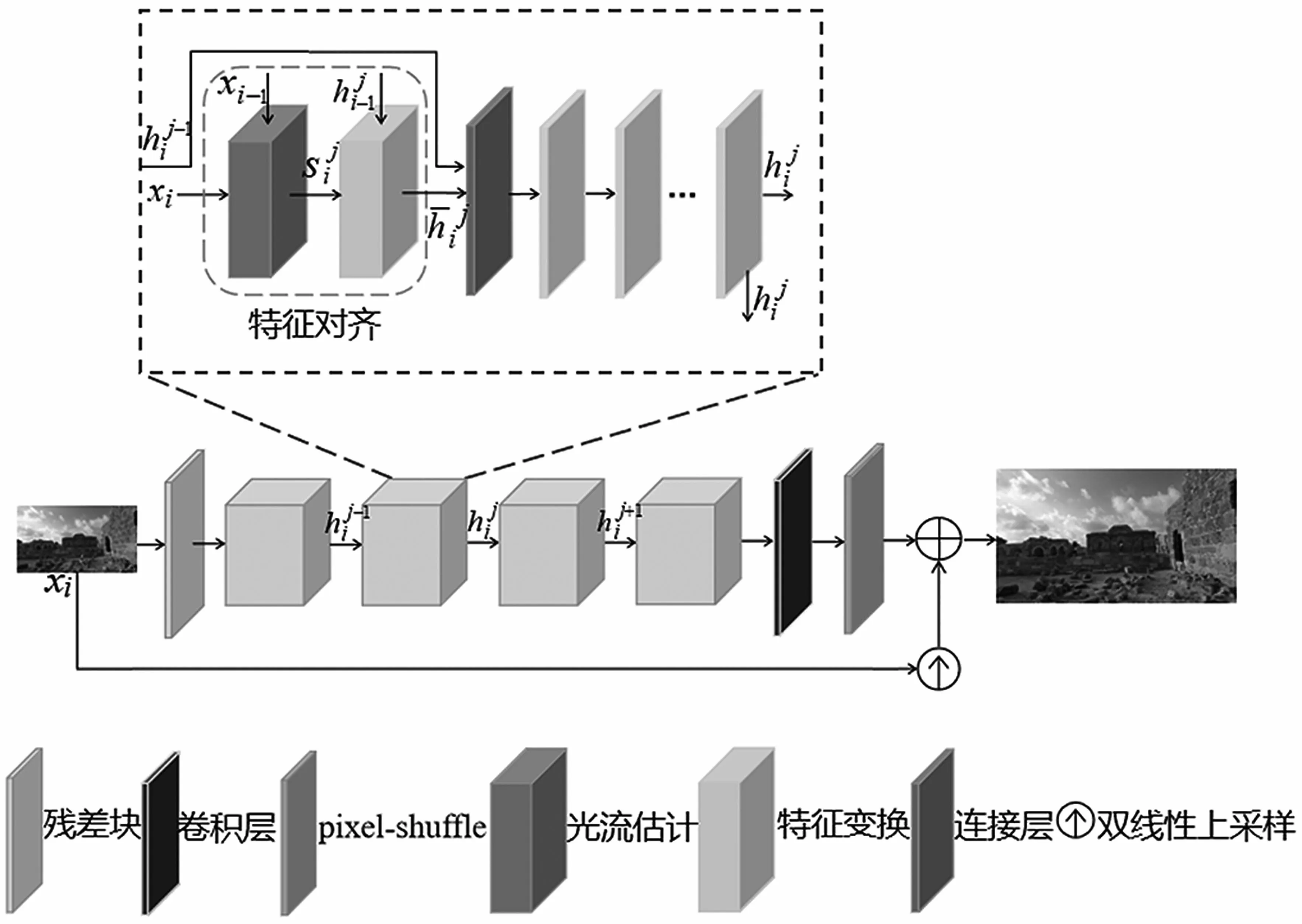
图2 本文超分辨率重建网络结构
首先,为了更好地利用视频传输过程中的时域信息,本文的超分辨率重建网络采用双向传播的方式,网络中特征以交替的方式独立地向两个方向进行传播,网络从整个序列中重复地提取信息,提高了特征的表达性。这里以正向传播过程为例,具体的传播过程可以表示为:式中:为第i个时间步长的第j个传播分支的特征;F(·)为特征传播分支的表达式,一个特征传播分支包含4部分输入;xi和xi-1分别为当前低分辨率视频帧和相邻低分辨率视频帧;为前一个时间步长的第j个分支传播来的特征;为同一个时间步长里前一个传播分支的特征。反向传播过程与正向传播过程类似,反向传播的分支和正向传播分支相邻。在反向传播分支中,特征逆向传播,在整个网络中,特征以交替的方式向两个方向传播。
其次,为了提高对齐的准确性以使网络获得更好的性能,本文采用基于光流的特征对齐模块。该模块包括1个光流估计模块和1个特征变换模块,再通过1个连接层将特征传递到后续残差块中,其中每条传播分支包含5个残差块。具体而言,基于光流的特征对齐过程可以表示为:
式中:S(·)为光流估计过程;为获得的光流;W(·)为特征变换过程;R(·)为残差块;c(·)为通道维度的特征连接。先将当前视频帧xi和相邻视频帧xi-1输入光流估计模块,以获得估计的光流;然后基于光流对前一个时间步长的第j个分支传播来的特征进行特征变换;之后将特征变换的输出结果和同一个时间步长里前一个传播分支的特征共同作为连接层的输入;随后输出结果,通过多个残差块来获得该传播分支的输出特征最后输出特征又作为输入分别传递到下一个传播分支和相邻的时间步长中。
本文的网络在每一个时间步长i上包含4个特征对齐模块及相应的残差块,最后网络的中间特征通过由1个卷积层和pixel-shuffle层组成的上采样模块来生成高分辨率视频帧。网络还将双线性上采样模块加入残差学习的框架来保证训练的稳定性。网络的上采样过程可以表示为:
式中:u为上采样模块。
2.2 训练阶段
本文训练质量增强网络与超分辨率重建网络所用的训练样本对分别为其中Xi表示原始高分辨率视频帧,Li表示经过下采样的低分辨率视频帧,Vi表示对Li进行压缩后的视频帧,表示Vi经过质量增强网络处理后的视频帧。
式中:θ1为质量增强网络的参数;f(·)为质量增强网络的输出函数;ε为保证数值稳定设置的常数,本文设置为0.001。
训练质量增强网络所用的训练集和验证集来自REDS数据集[19]。本文将REDS数据集中240个320×180分辨率的视频序列作为训练样本,对每个序列,取前20帧在HEVC随机接入配置encoder_randomaccess_main.cfg,当量化参数(Quantization Parameter,QP)为{27,32,37,42}时,分别进行编码,随后将得到的经过压缩的低分辨率视频帧与未压缩的低分辨率视频帧共同组成质量增强网络的训练样本对。本文采用Adam(Adaptive Moment Estimation)优化器,主网络与光流网络的初始学习率分别设置为1×10-4和2.5×10-5,总迭代次数设置为2×105。
完成对质量增强网络的训练后,通过质量增强网络获得质量增强的低分辨率视频帧再将与原始高分辨率视频帧Xi组成超分辨率重建网络的训练样本对网络的损失函数表示为:
式中:θ2为超分辨率重建网络的参数;g(·)为超分辨率重建网络的输出函数。
训练超分辨率重建网络所用的训练集和验证集同样来自REDS数据集,首先将经过压缩的REDS数据集中320×180分辨率的视频序列作为质量增强网络的输入,得到质量增强的低分辨率视频;其次将质量增强的低分辨率视频与数据集中1 280×720分辨率的视频共同组成超分辨率重建网络的训练对。重建网络的网络设置均与质量增强网络相同。
3 实验结果
本文实验均在CPU为i7-9700 @3.00 GHz和GPU为Nvidia GeForce RTX 2080 Ti的计算机上运行。实验采用HEVC官方编码版本HM16.20,配置文件采用encoder_randomaccess_main.cfg,量化QP分别为27,32,37,42。
本文首先采用REDS数据集中的测试集来验证网络的收敛性,以证明网络结构的合理性和有效性。以QP=32为例,在训练质量增强网络和超分辨率重建网络的过程中,测试序列的峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和迭代次数之间的关系曲线如图3所示。由图可知,本文的质量增强网络和超分辨率重建网络均在REDS数据集上实现了有效收敛。
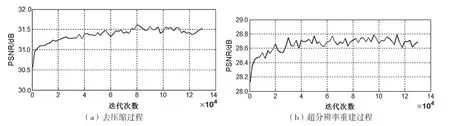
图3 迭代次数与PSNR的关系曲线
本文对19个视频序列进行实验,并选择两种两阶段的方法作为对比方法,首先采用文献[7]提出的去压缩网络STDF对视频进行质量增强,其次分别采用双三次插值算法与文献[14]提出的TDAN重建网络对视频进行超分辨率重建,所提算法与相关对比方法均在相同配置下进行。本文采用峰值信噪比来评估不同算法的性能,所有视频序列仅在亮度(Y)通道进行测量。
表1展示了所提算法、STDF+Bicubic、STDF+TDAN和标准HM16.20算法+Bicubic在QP分别为32,37,42时重建视频的PSNR对比。实验结果表明当QP为32时,相比于采用标准HM16.20算法压缩并采用双三次插值算法进行超分辨率重建,本文所提算法在所有视频序列上均有一定的质量提升,19个视频序列的PSNR平均提升为0.92 dB;与STDF+Bicubic和STDF+TDAN方法相比,本文所提算法也均有一定的质量提升,在19个视频序列上PSNR分别平均提升了0.69 dB和0.29 dB。同时,在QP为37和42时,本文所提算法与相关对比算法相比也实现了一定的性能提升。
为了验证本文所提质量增强网络的有效性,图4给出了4个不同分辨率的视频序列BQSqure 416×240、RaceHorses 832×480、BasketballDrive 1920×1080和PeopleOnStreet 2 560×1 600的率失真曲线。由图4可以看出,不同分辨率的视频序列在依次经过下采样和压缩后,经过本文所提的质量增强网络进行处理的视频序列的率失真曲线均在HEVC标准的率失真曲线的上方,证明了本文所提质量增强网络的有效性。
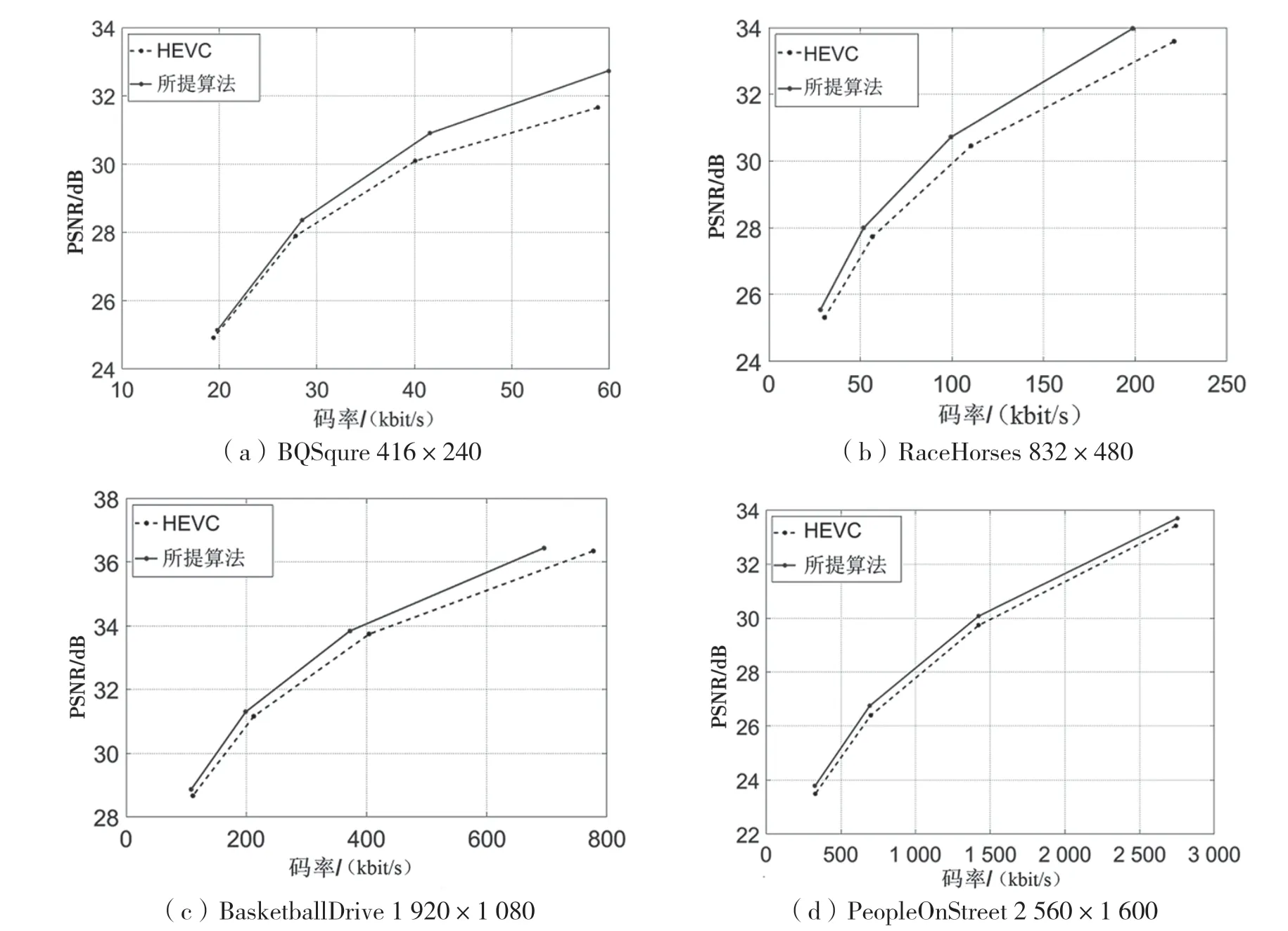
图4 不同分辨率视频序列的率失真曲线
表2给出了6个不同分辨率的视频在依次经过下采样和压缩,并使用本文所提的质量增强网络进行质量增强后,分别采用双三次插值算法和本文所提的超分辨率重建网络进行重建的PSNR结果。由表2可以看出,本文所提的超分辨率重建网络在不同分辨率的视频序列上均比采用双三次插值算法有一定的质量提升,在4个QP上的PSNR平均提升为0.75 dB。并且,对比表1和表2中QP为32时的实验结果可以看出,对于压缩后的低分辨率视频,采用本文所提的质量增强网络进行处理后再采用双三次插值算法进行重建,比直接采用双三次插值算法进行超分辨率重建有一定的质量提升。由表1可知,在QP为32时直接采用双三次插值算法对PeopleOnStreet 2 560×1 600序列进行重建的PSNR为25.59 dB,而通过表2可以看出,对PeopleOnStreet 2 560×1 600序列首先采用本文所提的质量增强网络进行处理,其次采用双三次插值算法进行超分辨率重建,得到的重建视频的PSNR为25.89 dB,相比于直接采用双三次插值算法进行重建的结果提升了0.3 dB,进一步证明了本文所提的质量增强网络和超分辨率重建网络的有效性。

表1 本文算法和相关对比算法的重建视频质量PSNR参数对比
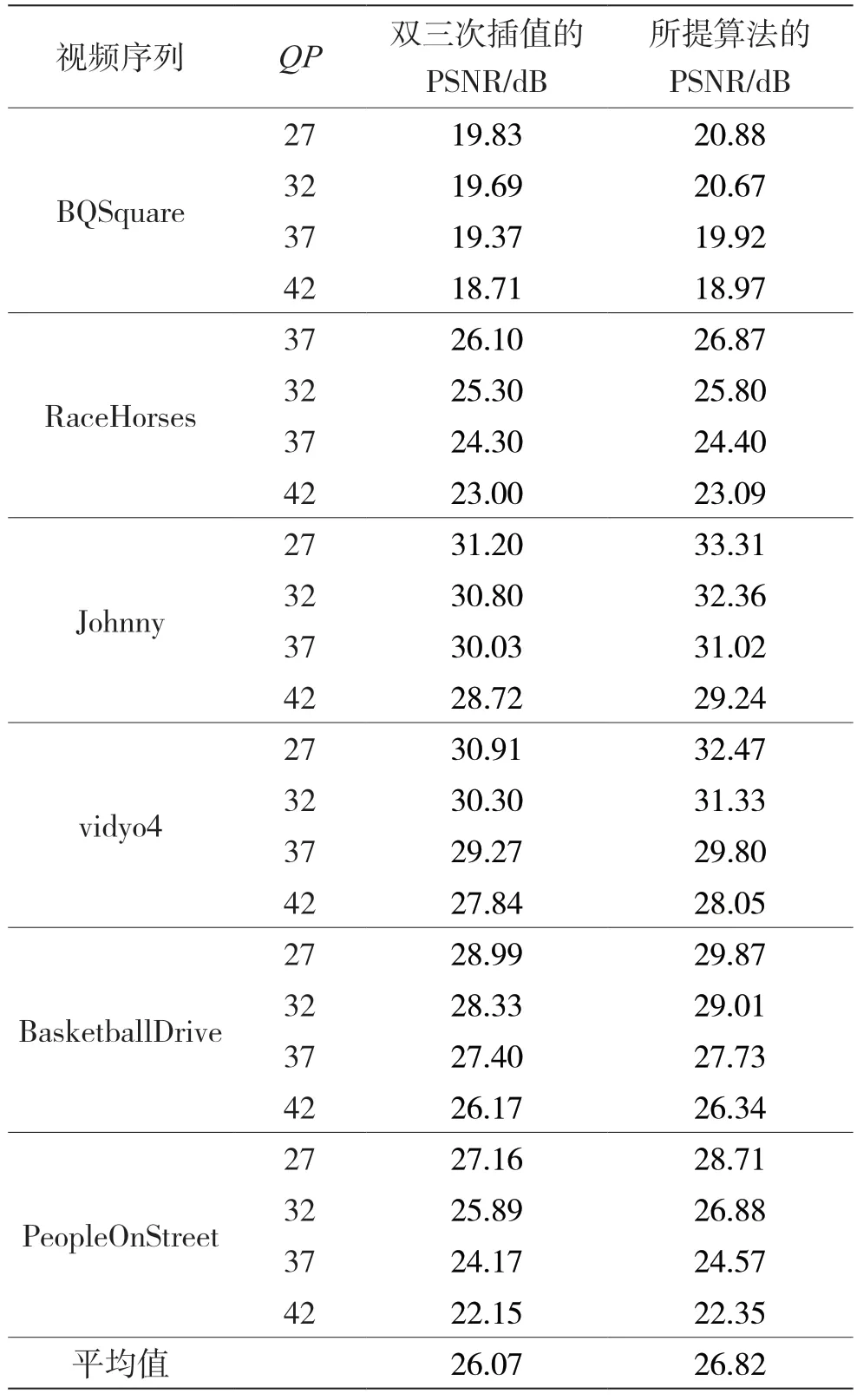
表2 本文所提超分辨率重建网络和双三次插值算法的重建视频质量PSNR参数对比
图5给出了KristenAndSara 1 280×720序列的主观对比结果。图5(a)为采用HEVC编码标准压缩后的低分辨率视频帧,图5(b)为采用本文所提的质量增强网络和超分辨率重建网络进行处理后的视频帧。由图中黑框内的部分可以看出,图5(b)中衣服上的条纹更为清晰,与图5(a)相比,显著减小了压缩效应。


图5 KristenAndSara 1 280×720序列主观效果对比
4 结语
本文提出了一种采用光流特征对齐的压缩视频超分辨率重建算法,对压缩后的低分辨率视频分为两个阶段进行处理。首先通过一个质量增强网络对经过压缩的低分辨率视频进行质量增强,去除压缩伪影;其次通过一个超分辨率重建网络对质量增强的低分辨率视频进行重建,将视频恢复至原始分辨率。所提网络均采用基于光流的特征对齐,特征以双向传播的方式在网络中进行传播。实验结果表明,与经过HEVC编码标准压缩后直接采用双三次插值算法进行超分辨率重建相比,本文所提算法在视频的客观效果和主观感受上均有一定的提升;与相关算法相比,本文所提算法在不同QP上的PSNR也都有一定的提升。下一步,将针对降低两阶段的压缩视频超分辨率重建算法的复杂度开展进一步的研究。
