基于深度学习的区块链蜜罐陷阱合约检测
2022-03-01张红霞王琪王登岳王奔
张红霞,王琪,王登岳,王奔
(中国石油大学(华东)青岛软件学院、计算机科学与技术学院,山东 青岛 266580)
0 引言
以太坊是一个开源的公共区块链分布式平台,可以通过图灵完备的虚拟机来处理点对点之间通信的智能合约。部署在以太坊公链上的智能合约具有不可篡改和自动执行的优越特性,使智能合约和区块链相结合的研究逐渐成为热点。但区块链技术的去中心化、匿名特性[1]以及缺少第三方机构直接管控等问题,造成在交易过程中很难获知参与者的身份信息。研究表明[2],随着智能合约在各个领域的应用越加盛行,加密数字货币的价值不断攀高,基于区块链智能合约的漏洞和陷阱攻击正变得日益猖獗。蜜罐陷阱合约是一种隐藏在以太坊智能合约面具下的新型恶意陷阱合约。由于缺乏以太坊以及智能合约等领域的专业知识,普通用户和投资者通常对这类恶意陷阱难以防备。一份关于以太坊的数据分析[3]估计,截至2019 年,以太坊上部署着数千个蜜罐陷阱合约。所以,针对以太坊上蜜罐陷阱合约的检测工作刻不容缓。
近年来,研究者采用符号执行的方法或是机器学习对以太坊上部署的蜜罐智能合约进行检测[3-5],依照蜜罐陷阱合约的不同特性将蜜罐陷阱合约划分为8 个类别,开发了利用符号执行可用于检测蜜罐陷阱合约的工具。通过引入智能合约中的交易行为作为特征,采用决策树等算法对蜜罐陷阱合约进行检测。但目前的研究仍存在以下问题:1)未考虑到蜜罐陷阱合约数据的类别不平衡和重复性,导致训练出的模型存在过拟合问题;2)基于频率的特征选取方法,导致机器学习模型训练特征过于庞大,泛化性较差。
本文通过分析蜜罐陷阱合约的特点,提出了关键操作码的概念,并在蜜罐陷阱合约检测领域引入深度学习方法,在传统的长短期记忆(LSTM,long short-term memory)模型中加入关键操作码权重机制,构建了能够同时捕获蜜罐陷阱合约中隐藏的序列特征以及关键操作码特征的关键操作码长短时记忆(KOLSTM,key-opcode long short-term memory)模型,提出了基于KOLSTM 模型的蜜罐陷阱合约检测方法。具体来说,首先,采用基于简易数据扩充(EDA,easy data augmentation)的数据增强过采样技术对蜜罐陷阱合约数据集进行有效的数据增强;然后,利用关键操作码(Key-Opcode)提取方法在嵌入层加入权重机制,有效区分操作码特征的重要性,实现对蜜罐陷阱合约的隐藏序列特征及关键操作码特征的捕获;最后,采用真实数据集进行实验,结果表明,本文提出的方法在二分类和多分类检测场景下的F 值较现有模型分别提升2.39%与19.54%。
本文的主要贡献如下。
1)提出了KOLSTM 深度学习模型用于检测蜜罐陷阱合约,该模型可以有效地捕获蜜罐陷阱合约中隐藏的序列特征和关键操作码特征。
2)提出了一种可用于选取智能合约中关键操作码的关键词提取方法,通过该方法,可以获取对智能合约类别有重要影响的操作码以及输出对该操作码影响大小的数值量化。
3)在真实数据集的实验结果表明,KOLSTM模型在二分类和多分类检测场景下的F 值分别为95.59%与91.01%,较现有模型分别提升2.39%与19.54%。
1 相关工作
由于区块链同时具有参与者匿名、无国界限制、金融支付[6]等天然特性,再加上缺乏有力的监管手段,相较于传统的互联网恶意陷阱,基于区块链的恶意陷阱具有更高的隐蔽性和伪装性[7]。对于普通的投资者和用户来说,这类陷阱更加难以防备。据研究统计[8],仅2013 年9 月2 日—2014 年9 月9 日,就有超过万名受害者深陷此类陷阱。Bartoletti 等[9]通过分析192 个基于比特币的恶意陷阱案例,将比特币区块链网络中的恶意陷阱划分为4 种类型。Chen 等[10-11]提出利用机器学习和数据挖掘的方法来对基于以太坊的庞氏骗局进行识别,在后续的模型应用中,估计以太坊上部署着超过400 个庞氏骗局。张艳梅等[12]在基于以太坊的庞氏骗局检测领域引入深度学习方法,进一步提高了检测精度。
而基于以太坊的蜜罐陷阱合约是2019 年新发现的区块链恶意陷阱类型,Torres 等[3]通过调查蜜罐陷阱合约的流行情况、交易行为以及对以太坊平台的影响程度,首次对蜜罐陷阱合约进行了系统分析。根据蜜罐陷阱合约不同的特性将它们划分为了8 个类别,并提供了一个利用符号执行可用于检测蜜罐陷阱合约的工具。该工具对于特征明显和特定类型的蜜罐陷阱合约具有很好的识别效果,但由于是基于符号执行,而且目前智能合约的发展更加趋向于简洁化与智能化,该工具对复杂场景下的蜜罐陷阱合约的有效识别较弱。Camino 等[4]提出了一种基于合约交易行为的数据科学检测方法,通过分析在合约创建者、合约、交易发送者和其他参与者之间的所有可能的资金流动情况,然后根据分析结果引入相应的特征,训练了一个用于蜜罐陷阱合约检测的机器学习模型[13]。该方法有效地利用了除智能合约源码以外的其他特征,包括合约中的交易记录、编译信息等。但该方法提出的检测模型的训练必须建立在足够多的交易记录数据特征上,而大多数智能合约中并不包含足够的用以特征提取的交易记录,一旦蜜罐陷阱合约包含足够的交易记录,就意味着可能不止一个用户深陷陷阱。Chen 等[5]认为蜜罐陷阱合约可以看作一种漏洞攻击,但已有的智能合约漏洞检测工具,包括智能审查[14]、规则检查[15]以及合约模糊器[16],却无法针对蜜罐陷阱合约进行有效检测。该研究从机器学习的角度出发,提出了一种基于N-gram 模型[17]选取操作码特征,并结合梯度提升决策树算法[18]来检测蜜罐陷阱合约的方法。该方法利用智能合约源码反编译得到的操作码作为特征进行模型训练,可以在字节码级别学习蜜罐陷阱合约的模式。但该方法未考虑到蜜罐陷阱合约数据存在的类别不平衡性和重复性[19]问题,以及基于N-gram 模型选取特征所导致的训练特征太过庞大,对新出现的蜜罐陷阱合约识别效果不佳。本文针对当前研究存在的问题,分析蜜罐陷阱合约的特点,基于深度学习方法构建检测模型,以期提高蜜罐陷阱合约检测的准确度。
2 KOLSTM 模型
2.1 Key-Opcode 提取方法
Key-Opcode 提取方法是KOLSTM 模型的重要组成部分,利用该方法可以获取对智能合约类别有重要影响的操作码,并对操作码影响大小进行数值量化处理。智能合约中的操作码是表示以太坊基于堆栈虚拟机的执行命令,不同类型的智能合约中的操作码以及操作码频率具有较大差异,如图1 所示,蜜罐陷阱合约中表示判断以及跳转命令的操作码频率要比非蜜罐陷阱合约高得多。基于此,本文认为不同类型的智能合约中所包含的操作码及其频率是不同的,存在某些操作码对合约类别有着重要影响。这类操作码就是Key-Opcode,其定义为智能合约中对合约类型判定起关键性作用的操作码。

图1 蜜罐陷阱合约与非蜜罐陷阱合约操作码词云
针对智能合约操作码的词频无法有效衡量操作码的重要程度,智能合约数据的长度分布毫无规律,且类别不平衡,无法对关键操作码进行有效度量等问题,本文基于逆向文本频率(IDF,inverse document frequency)[20],提出选取智能合约关键操作码的Key-Opcode 提取方法sigmoid 逆向文本频率(SIDF,sigmoid inverse document frequency),通过sigmoid 函数对初始权重值进行缩放处理,将操作码的权重值控制在[0,1]范围内,进而确定操作码对合约类别的影响程度,计算方法为
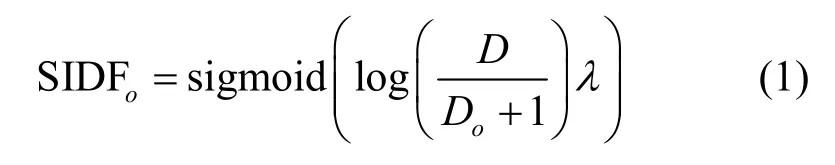
其中,D为合约总数,Do为包含操作码o的合约数,λ为常数。
利用该方法对数据集进行关键操作码选取,创建权重字典并应用到之后的模型中。表1 是权重字典的部分输出结果。
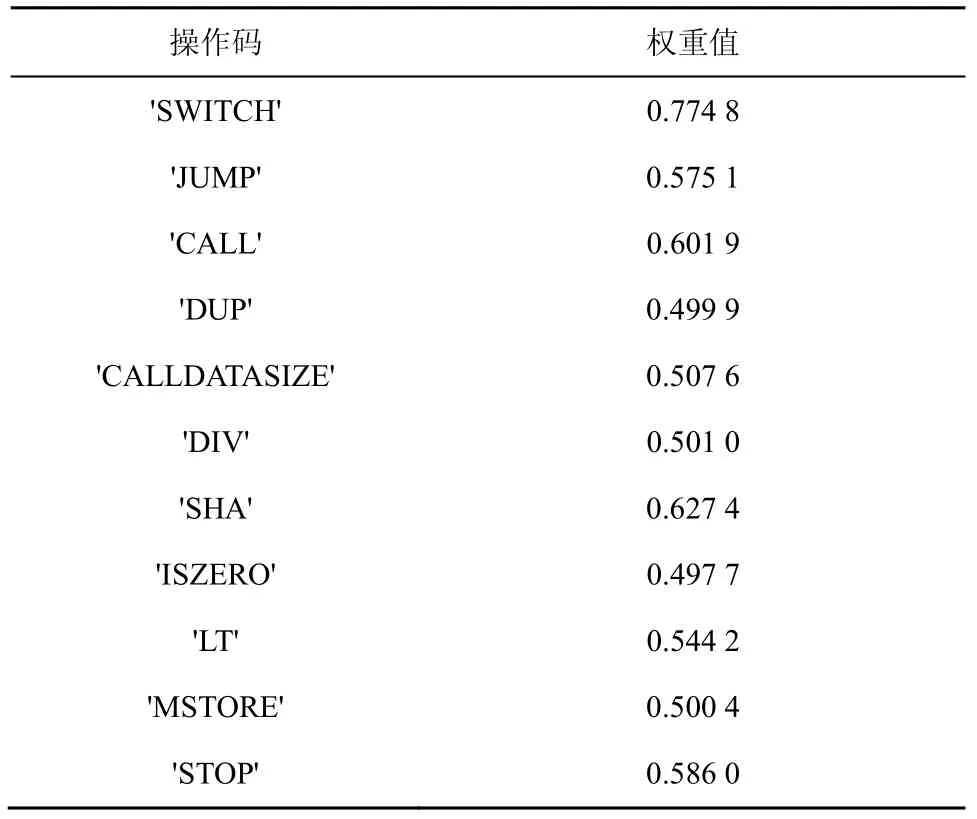
表1 权重字典的部分输出结果
2.2 KOLSTM 模型
智能合约操作码的本质是基于堆栈操作指令的集合,操作码的前后顺序即序列特征,对蜜罐陷阱合约检测至关重要。LSTM 模型通过引入门结构克服长期依赖问题,在处理序列类型的输入数据时具有优越的性能。关键操作码和序列特征是蜜罐陷阱合约的重要特性,直接影响蜜罐陷阱合约检测的准确性。同时,关键操作码权重机制能够有效区分操作码的重要程度,基于此,本文构建了能够同时捕获关键操作码与序列特征的KOLSTM 模型。
KOLSTM 模型的底层是合约操作码输入层,该层将合约中的操作码转换为相同映射表示的数字特征;合约操作码输入层之上的Key-Opcode 权重层是关键操作码权重机制实现的重要部分,该层将Key-Opcode 提取方法得到的结果应用到模型中,权重值的大小代表操作码的重要性,该层可以提高模型对关键操作码信息的关注度;词向量嵌入层使用基于海量智能合约操作码预训练的Word2Vec[21]词向量模型,将操作码序列映射为高维特征向量表示;嵌入层之上的LSTM 单元可以捕获合约中字节码级别潜在的序列信息特征,并且克服长期依赖问题;Softmax 层用于分类模型结果输出前的归一化处理;最顶层的输出层输出模型的分类结果,通常以数字表示。KOLSTM 模型的网络结构如图2 所示。
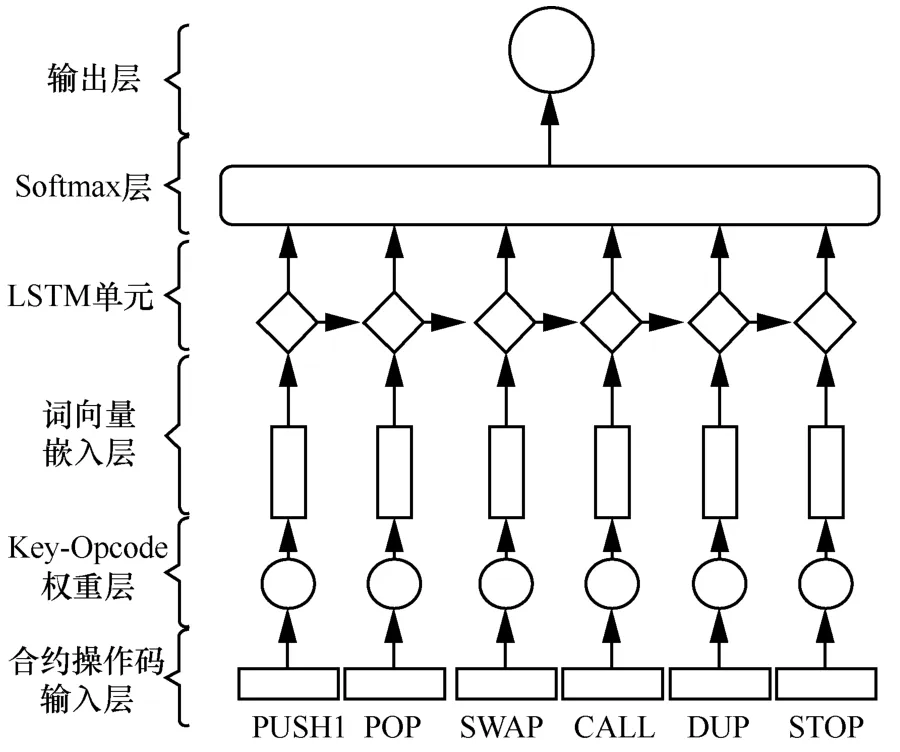
图2 KOLSTM 模型的网络结构
2.2.1 Key-Opcode 权重层
Key-Opcode 权重层将关键操作码提取方法得到的权重字典应用到模型中,在进行词向量嵌入转换之前,通过该层提高检测模型对关键操作码特征的关注度。直观来看,Key-Opcode 权重层是对词向量嵌入层的改进。无论是独热编码还是无监督训练得到的词向量模型,对词汇的向量表示都是基于词语间的相关性,这样的模式对基于文本的词汇表示是十分合适的,但对于智能合约中的操作码却不太适用,其无法凸显关键操作码对智能合约的特殊性。因此,本文在词向量嵌入层之前加入了Key-Opcode 权重层,可以表示为
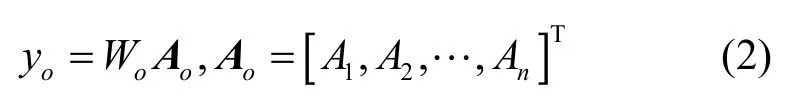
其中,Wo为操作码o通过Key-Opcode 提取方法得到的权重值,Ao为操作码o的词向量表示矩阵。Key-Opcode 权重层的实质是关键操作码权重机制,通过该权重机制捕获对蜜罐陷阱合约检测有重要作用的关键操作码特征。
同时,在该层保留传统LSTM 模型的权值共享机制,关键操作码权重也仅在输入层与词向量嵌入转换之间应用,这样的设置可以极大地减少模型参数量,降低训练时间。
2.2.2 词向量嵌入层
词向量嵌入层将输入的操作码信息转换为用以模型识别训练的高维特征向量。本文在该层引入了Word2Vec 词向量模型进行特征向量转换,通过训练海量的文本信息在双层的神经网络中进行非监督学习,将每个词汇转换为高维向量。
Word2Vec 模型的训练过程采用的是N-gram 模式,通过这种模式训练出的特征向量包含了一定的文本上下文信息。考虑到智能合约的特殊性,传统的英文预训练Word2Vec 模型无法有效地表征智能合约中隐含的操作码特征信息,本文使用的Word2Vec 模型是基于海量的智能合约数据预训练得到的。
2.2.3 LSTM 单元
针对蜜罐陷阱合约数据长度过长、操作码上下文关联性较强的特点,本文在模型中引入了LSTM单元进行合约数据处理。
LSTM 单元如图3 所示,通过引入遗忘门、更新门、输出门结构以及sigmoid、tanh 激活函数来控制信息的交互,维持和控制单元状态。本文设t时刻该单元输入的信息流为x
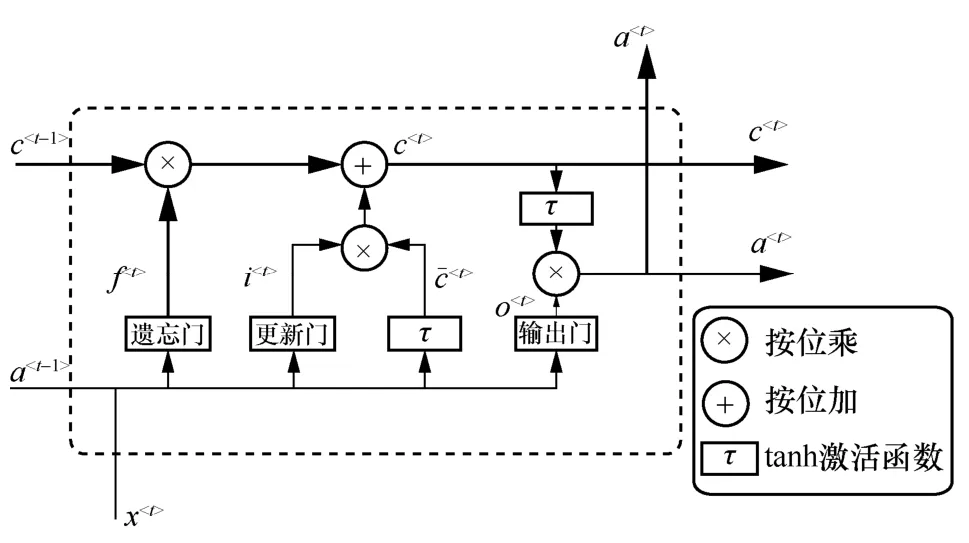
图3 LSTM 单元
输入信息进入LSTM 单元首先需要经过遗忘门,遗忘门可以对信息进行选择性遗忘,也就是对t-1 时刻的隐藏状态a
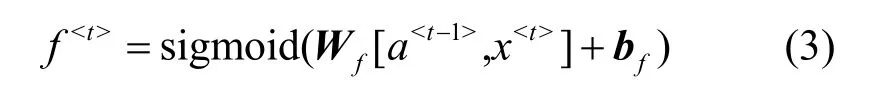
在进行遗忘之后,下一个阶段需要确定细胞状态中保存的信息内容,执行这一操作的是更新门以及其他激活函数。具体来说,首先更新门会通过sigmoid 激活函数确定更新的内容,这时需要创建一个新的数字向量,用来保存通过tanh 激活函数得到的新的信息。经过这两步可以得到用于细胞状态更新的准备信息。
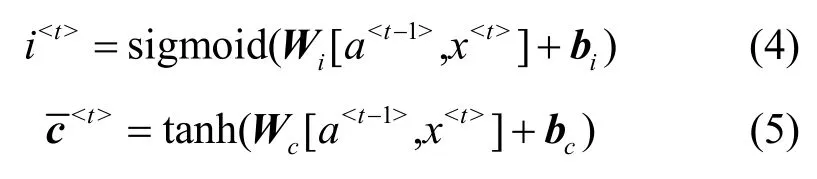
然后将准备信息以及遗忘门获取的信息进行拼接整合,得到新的细胞状态。
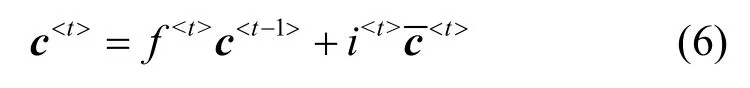
最后确定当前状态输出的信息。首先使用sigmoid 激活函数确定细胞状态的输出部分,然后细胞状态通过tanh 函数进行放缩之后再与sigmoid激活函数的输出结果相乘。这样便可以输出当前状态部分。
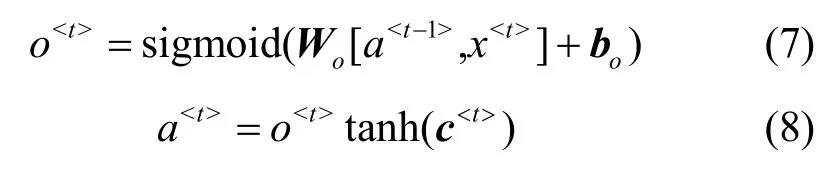
3 实验
3.1 实验步骤
实验流程共分为6 个步骤,包括数据获取、数据预处理、数据集增强、特征提取、模型训练及效果评估。在数据获取步骤中,基于以太坊平台获取实验所需的智能合约数据;通过数据预处理步骤将合约数据的源码文件反编译为模型训练所需的操作码格式;在数据集增强步骤中,针对训练数据存在的问题进行针对性的数据增强;特征提取是模型训练前的最后一个步骤,在这个步骤中将预处理后的操作码数据进行分词以及特征向量转换,获取可用于模型训练的有效特征;之后将在模型训练步骤中,训练本文提出的KOLSTM 模型以及其他对比模型;最后,通过效果评估步骤对实验结果进行性能评价和分析。
3.2 数据获取及预处理
本文实验采用的蜜罐陷阱合约数据集[3]包含857个经过验证的蜜罐陷阱合约文件,并根据它们的特性划分为了8 个不同的类别,包括隐藏状态更新(HSU,hidden state update)、继承障碍(ID,inheritance disorder)、未初始化结构(US,uninitialized struct)、稻草人合约(SMC,straw man contract)、平衡障碍(BD,balance disorder)、隐藏转移(HT,hidden transfer)、跳空字符串(SESL,skip empty string literal)和类型溢出(TDO,type deduction overflow)。而非蜜罐陷阱合约数据是通过以太坊浏览器得到的5 960 份具有唯一精准字节码匹配的合约数据。
原始合约数据无法直接用以模型训练,需要将数据集中的源码文件反编译为操作码格式。本文使用了以太坊虚拟机(EVM,Ethereum virtual machine)数据包来完成这一转换,图4 展示了反编译后的操作码文件,可以看到其中共包含2 种类型的数据信息,分别是操作码和指令地址,对于模型的训练仅需要保留操作码。
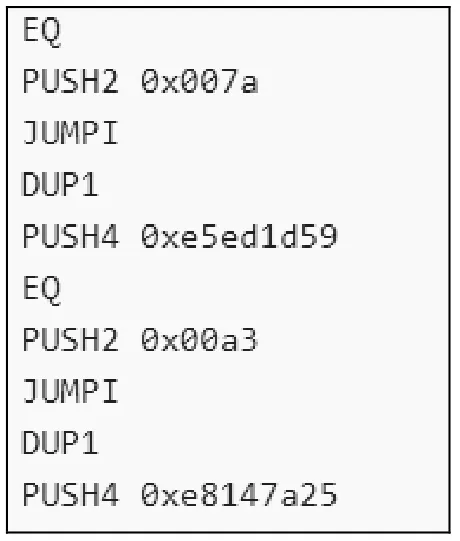
图4 反编译后的操作码文件
3.3 数据集增强及特征提取
对数据集进行检查时,本文发现蜜罐陷阱合约数据存在严重的合约复制[19]现象,而且由于时间问题部分合约已经自毁。在去除了重复合约以及自毁合约后,得到的蜜罐陷阱合约类别及数量如表2 所示。
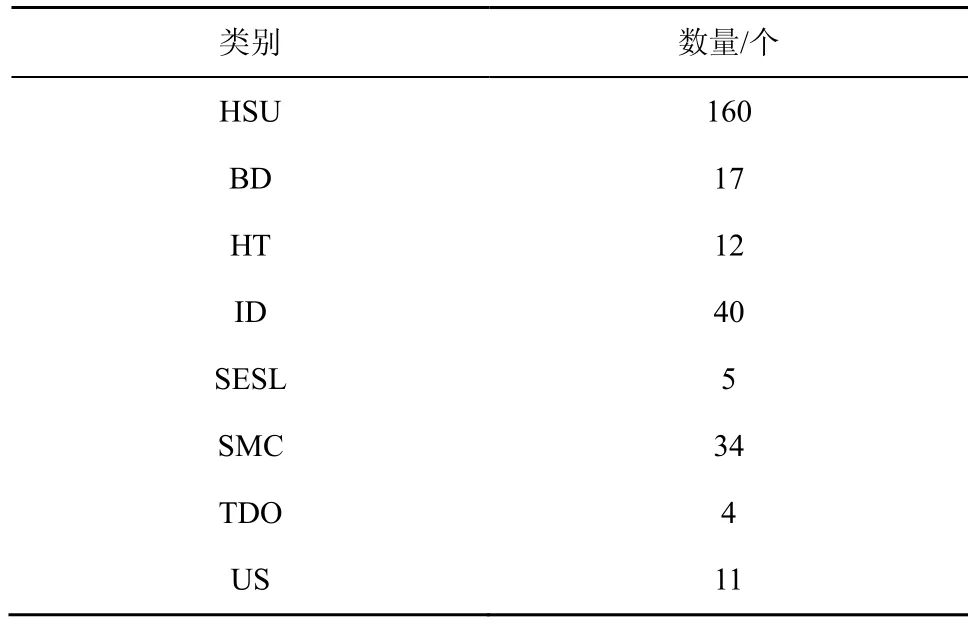
表2 蜜罐陷阱合约类别及数量
通过观察可得,蜜罐陷阱合约数据存在严重的类别不平衡以及数据量过少的问题,这对深度学习模型的训练是极其不利的。为了解决这一问题,本文使用了EDA 数据增强过采样技术[22]来扩充原有数据。为了保持合约数据的序列特征和上下文相关性,本文在进行数据增强时并没有打乱操作码的前后顺序。最终,共得到了4 650份蜜罐陷阱合约以及5 960份非蜜罐陷阱合约操作码。数据集的合约长度统计情况如图5 所示,其中合约长度指的是合约中所含操作码数量。
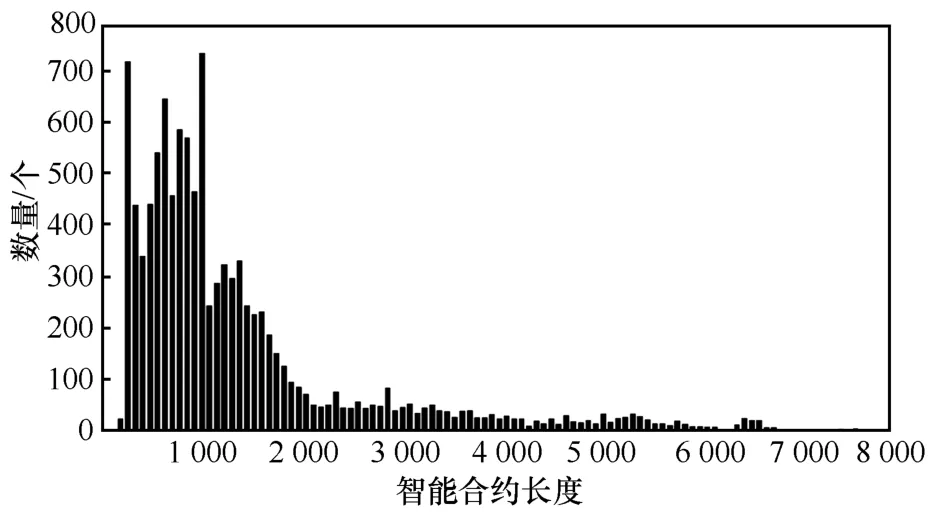
图5 数据集的合约长度统计情况
3.4 实验参数设置
本文在实验中将数据集按照6:2:2 的比例划分为训练集、测试集和验证集,其中训练集主要用于模型训练;验证集用于验证及优化模型参数,例如学习率或训练轮数等,并用来判断模型是否过拟合;测试集用来测试模型最终的性能及泛化能力。为了确定模型的最佳参数,本文在实验中使用了交叉验证[23]的方法。多次实验后得到的模型最佳参数设置如表3所示。
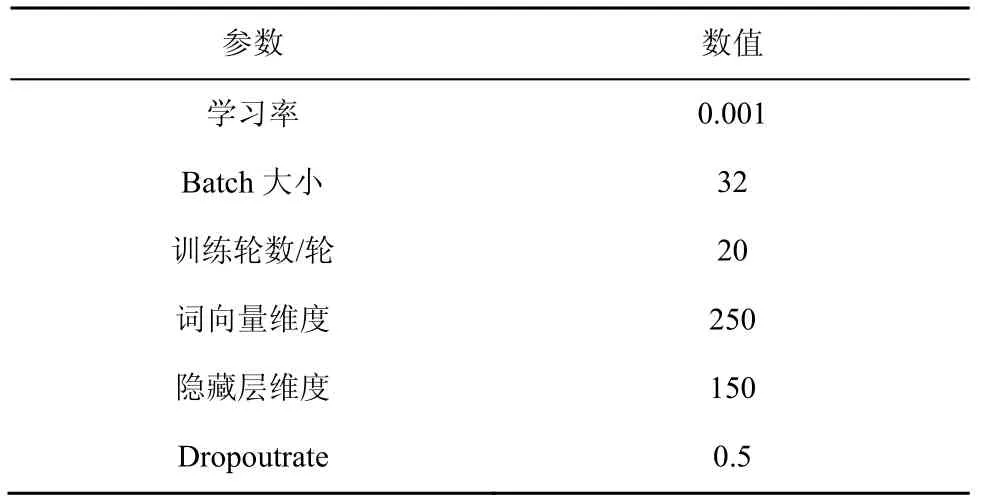
表3 模型最佳参数设置
3.5 实验结果分析
3.5.1 训练轮数分析
训练轮数的设置会影响模型的拟合情况,为了寻找KOLSTM 模型的最佳训练轮数,本文分别比较了验证集和训练集在不同训练轮数下的模型损失值和准确率,实验结果分别如图6 和图7所示。
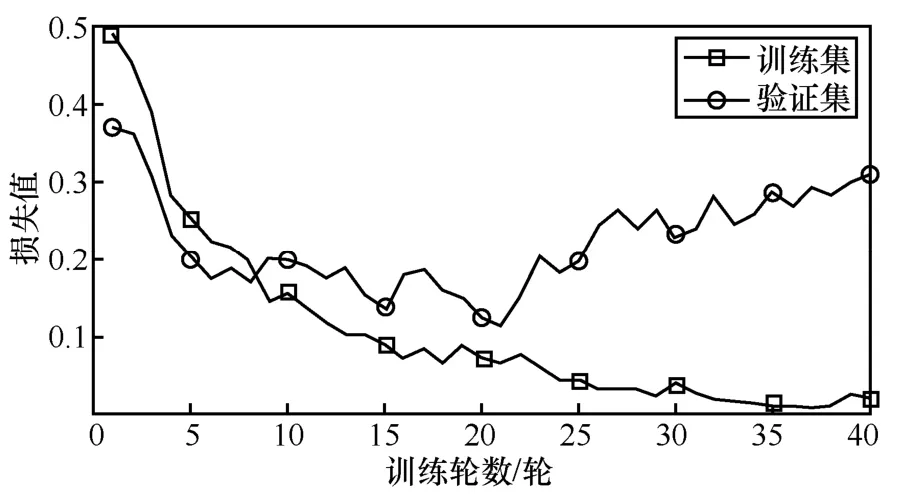
图6 验证集和训练集在不同训练轮数下的模型损失值
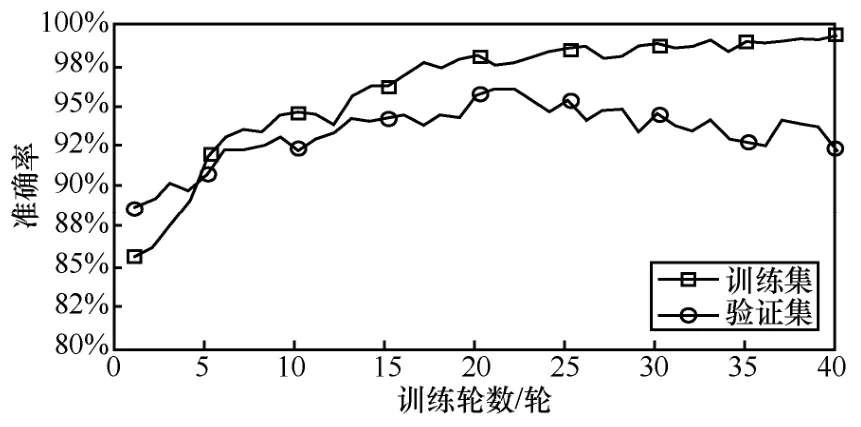
图7 验证集和训练集在不同训练轮数下的模型准确率
由图6 和图7 可以看出,在训练轮数超过20 轮以后,训练集损失值仍在下降,而验证集损失值虽然存在数据波动情况,但整体呈上升趋势;训练集准确率仍在上升,而验证集准确率呈下降趋势。这说明训练轮数超过20 轮以后,模型会出现过拟合情况,因此本文实验将训练轮数设置为20。
3.5.2 词向量分析
为了探究词向量对KOLSTM 模型检测性能的影响,本文比较了不同类型预训练词向量下的检测性能。预训练词向量包括基于合约操作码预训练词向量和维基百科词向量,在相同维度(250 维)下的实验结果如表4 所示。由表4 可以看出,相较维基百科词向量,基于合约操作码预训练词向量在检测性能上有所提升。
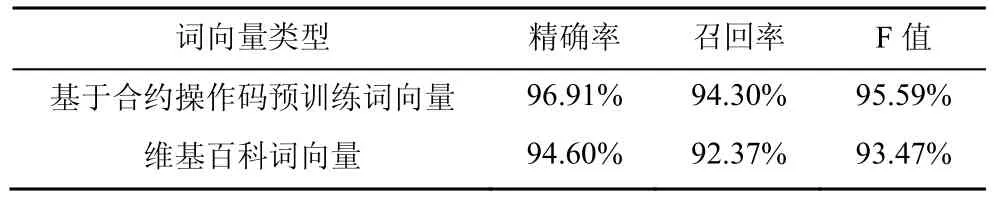
表4 不同类型词向量在相同维度(250 维)下的实验结果
本节实验进一步对比了不同维度下模型的收敛速度,词向量维度包括100 维和250 维。实验中都使用了基于合约操作码预训练词向量,结果如图8所示。由图8 可以看出,相比于低维度的词向量模型,高维度词向量模型表征能力更强,具有更快的收敛速度。
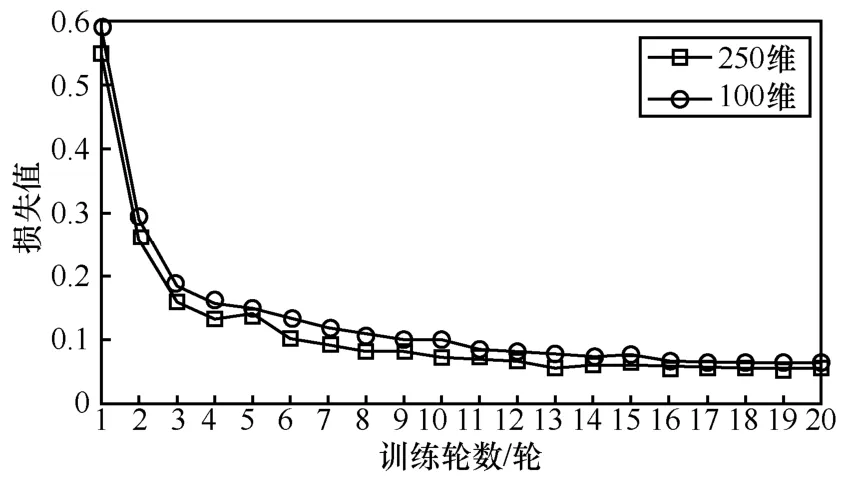
图8 100 维和250 维词向量对损失值影响
3.5.3 输入句长分析
为了验证KOLSTM 模型的检测性能,将本文提出的方法与卷积神经网络(CNN,convolutional neural network)、循环神经网络(RNN,recurrent neural network)以及LSTM 模型进行了对比实验。为了避免实验中所用模型出现过拟合或欠拟合问题,所有模型都加入了Dropout 机制[24],且设置了相同的训练轮数。
本节实验针对输入句长对模型检测性能的影响进行分析,分别比较了不同输入句长下4 类模型的检测性能,输入句长指的是模型设置的最大句长输入。实验结果如图9 所示。
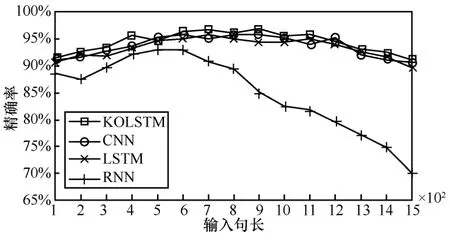
图9 输入句长对不同模型的性能影响
由图9 可以看出,在输入句长达到600 以后,RNN 模型的精确率呈下降趋势,而其他3 类模型的检测精确率相对稳定,都维持在90%以上。本文分析认为RNN 模型由于自身循环输入的结构限制,在处理较长序列输入时会出现梯度消失或爆炸问题,导致精确率的骤降,而LSTM 模型以及CNN模型通过引入门结构或者卷积操作克服了长期依赖问题。KOLSTM 模型因为加入了权重机制,精确率相比CNN 模型与LSTM 模型都有所提升。当输入句长为900 时,KOLSTM 模型的检测性能达到最佳。因此本实验将输入句长设置为900。
3.5.4 收敛速度分析
为了分析模型的收敛速度,本文对比了4 类模型训练时的损失值下降速率,结果如图10 所示。
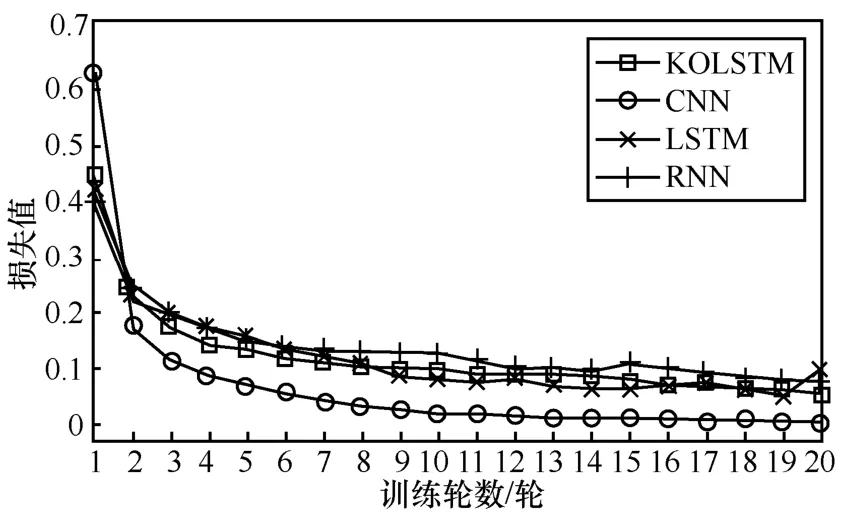
图10 不同模型的损失值变化
由图10 可以看出,KOLSTM 模型的收敛速度要比LSTM 模型与RNN 模型略快一些,但要慢于CNN 模型。本文分析认为,KOLSTM 模型中的Key-Opcode 权重机制其实可以看作预训练机制,通过这一机制可以提前告诉模型哪些是关键操作码,相较于LSTM 模型与RNN 模型,有效加速了模型收敛。而CNN 模型特有的卷积操作可以直接捕获关键操作码特征,模型收敛速度要快于KOLSTM模型。
3.5.5 检测性能分析
进一步通过实验分析本文所提模型的性能,并与其他模型进行对比,实验结果如表5 所示。
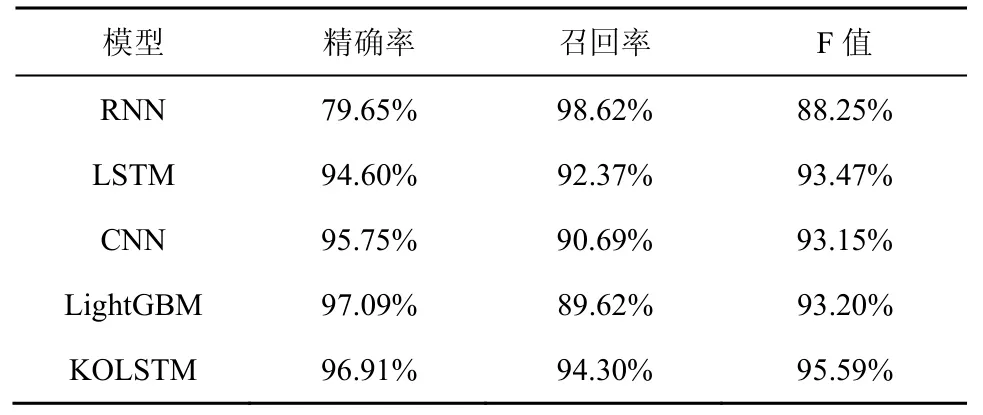
表5 不同模型的实验结果
由表5 可以看出,相较于其他深度学习模型,KOLSTM 模型具有最佳的检测性能。RNN 模型虽然具有极高的召回率,但精确率偏低,仅达到了79.65%。相较于RNN 模型,LSTM 模型的检测性能有了较大的提升,精确率达到了94.60%。CNN 模型用于蜜罐陷阱合约检测也取得了较好的效果,精确率达到了95.75%。LightGBM 模型为Chen 等[5]在蜜罐陷阱合约检测分类实验中所用的模型,该模型具有较高的检测精确率,但召回率仅为89.62%。相较于上述4 种模型,KOLSTM 模型的检测性能有明显提升,精确率达到了96.91%,F 值达到了95.59%。
3.5.6 多分类实验结果分析
为了验证KOLSTM 模型在多分类场景下的检测性能,将其与LightGBM 模型[5]进行对比,实验结果如表6 所示。多分类实验指的是对蜜罐陷阱合约进行类别判断的实验。由表 6 可以看出,LightGBM 模型对于某些类别的分类出现了明显的过拟合和欠拟合现象,平均精确率与平均F 值仅达到74.71%与71.47%。而KOLSTM 模型在蜜罐陷阱合约类型识别工作上同样具有不错的表现,类别平均分类精确率达到89.34%,平均F 值达到91.01%。但同时也可以注意到,KOLSTM 模型对于某些类别的分类精确率相对偏低,比如ID 类别的分类精确率仅达到73.68%。本文分析认为可能是由于该类别原始合约数据过少,在进行数据扩充和模型训练时无法有效捕获类别特征,导致该类别的分类结果不佳。
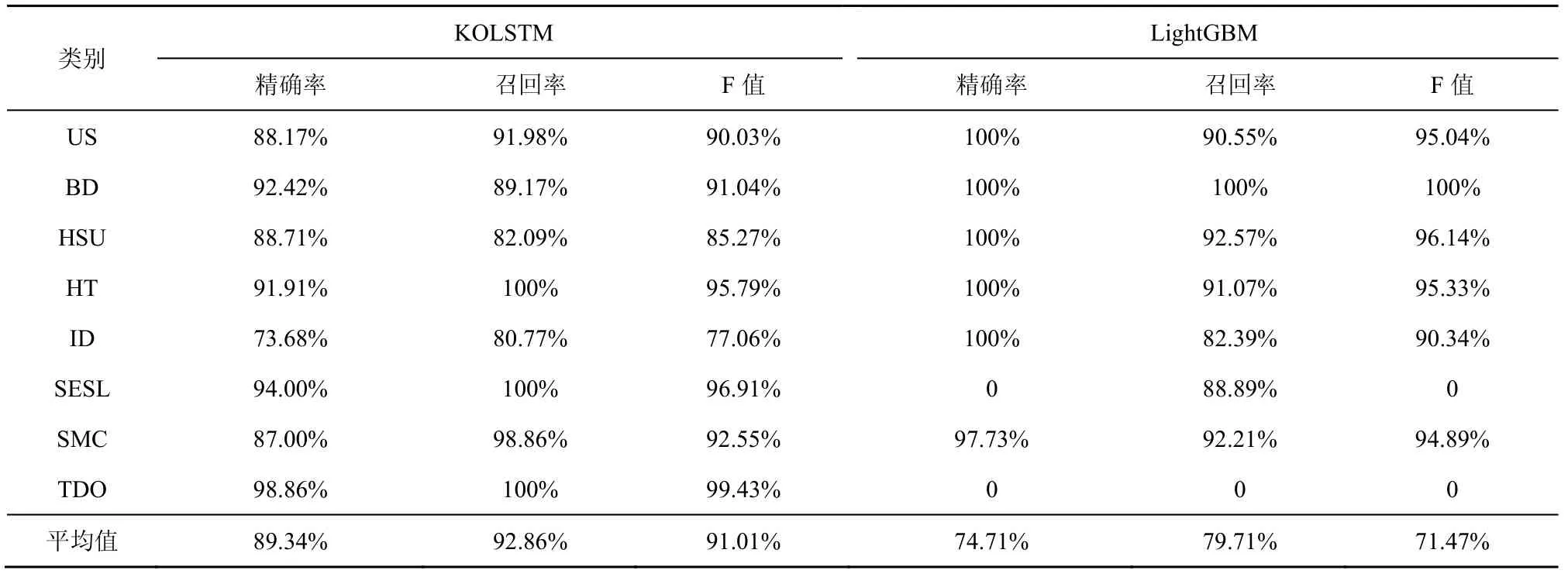
表6 多分类实验结果
4 结束语
本文针对基于区块链的蜜罐陷阱合约检测识别进行研究,通过分析蜜罐陷阱合约的特点,提出了 KOLSTM 深度学习模型。该模型通过Key-Opcode 提取方法引入权重机制,可以有效捕获关键操作码特征以及序列特征。实验结果表明,本文所提模型的检测性能要优于传统检测模型。本文计划下一步将更多的智能合约特征引入模型训练,包括交易记录、历史信息等,希望以此来进一步提高模型的检测性能。
由于匿名和去中心化特性,区块链的应用将更加广泛,但基于区块链以及数字货币的恶意陷阱也正变得越加猖獗。在未来的工作中,将持续追踪和研究基于区块链的其他类型的漏洞和陷阱攻击,以维护区块链生态健康。
