HRDA-Net:面向真实场景的图像多篡改检测与定位算法
2022-03-01朱叶余宜林郭迎春
朱叶,余宜林,郭迎春
(1.河北工业大学人工智能与数据科学学院,天津 300401;2.深圳市媒体信息内容安全重点实验室,广东 深圳 518060)
0 引言
图像编辑软件的日益普及,使图像编辑越来越容易,甚至单张图像存在多类篡改操作。因此,多篡改图像的检测与定位任务的研究至关重要。
主流图像篡改盲取证方法可分为基于图像级的篡改检测和基于像素级的篡改定位[1]。基于双通道 R-FCN(region-based fully convolutional network)模型在篡改检测任务中表现了较高性能[2]。基于空间光照一致性[3]的图像篡改检测算法,对噪声后处理稳健性较高。随着卷积网络的发展,基于预训练卷积神经网络(CNN,convolutional neural network)[4]和基于分块CNN[5]的卷积网络训练方式被提出以检测篡改图像。针对像素级图像单一篡改,Liu 等[6]提出基于全卷积网络和条件随机场的拼接篡改像素级定位框架,但是受数据集限制容易陷入过拟合。继而,文献[7]提出环形残差U-net 网络,加强CNN 的学习能力。文献[8]使用U 型检测网络和全连接条件随机场进行篡改检测。
针对像素级的篡改定位,文献[9]提出基于串行模型的篡改分支和相似度分支融合的复制-粘贴定位算法,即将篡改区域和源区域定位后再进行分类;文献[10]提出基于自适应注意力机制和残差细化模块的卷积网络框架,进一步提升篡改区域定位精度。针对图像移除篡改取证,Li 等[11]利用不同方向高通滤波器提出增强篡改痕迹特征,进行图像移除篡改定位。另外,针对包含多类篡改的数据集,文献[12]采用多尺度卷积得到篡改概率图,并与分割结果进行融合,实现篡改区域的像素级定位。Bappy 等[13]采用长短期记忆网络和CNN 的混合网络学习边缘矛盾特征,实现了端到端的篡改定位网络。基于RGB流+噪声流的双流网络[14]、ManTra-net[15]、空间金字塔注意力网络(SPAN,spatial pyramid attention network)[16]陆续被提出,实现了对拼接、复制-粘贴和图像移除篡改的像素级定位。
综上所述,主流篡改检测和定位方法都是针对单一类别篡改取证问题,其应用场景非常局限。主流图像篡改数据集仅包含单一篡改操作,且训练数据集仅包含篡改数据,对真实图像定位存在“伪影”现象,即篡改数据集训练的篡改定位网络在真实图像上仍能定位到篡改区域。并且,目前主流篡改数据集单幅图像仅包含单一种类篡改操作。为此,本文构建面向真实场景的多篡改数据集(MM Dataset,multiple manipulation dataset),每幅篡改图像同时包含拼接和移除2 种篡改操作。以此为基础,本文提出面向真实场景的多篡改检测与定位算法,即高分辨率扩张卷积注意力网络(HRDA-Net,high-resolution representation dilation attention network),以高分辨率网络(HRNet,high-resolution representation network)[17]为基线,同时完成篡改检测和定位任务。本文的主要贡献如下。
1)构建面向真实场景的MM Dataset,为真实场景下多篡改操作检测与定位提供支持。
2)提出HRDA-Net 模型,同时进行多篡改检测与定位任务,即检测图像是否篡改,同时定位拼接和移除篡改区域。
3)创新性地引入了余弦相似度损失作为辅助的损失函数,有效加快网络更好收敛。
1 相关工作
1.1 图像篡改数据集
基于深度学习的图像篡改取证方法离不开大规模数据集的支持,目前公开的篡改数据集有CASIA[18]、NIST[19]、COVERAGE[20]、DEFACTO[21]等。其中,CASIA 包含拼接篡改和复制-粘贴篡改;NIST 包含拼接、复制-粘贴和移除篡改;COVERAGE 包含100 幅复制-粘贴篡改图像;DEFACTO 从COCO[22]数据集中挑选了149 000 幅图像,并且自动对图像进行拼接、复制-粘贴和移除操作。但是,以上公开数据集篡改图像仅包含单一种类篡改操作,目前没有同时包含多类篡改操作的公开数据集。本文提出面向真实场景的MM Dataset,包含1 000 组篡改图像和真实图像,每一幅图像都包含拼接和移除2 种篡改操作。
1.2 注意力模块
计算机视觉领域最早应用的注意力模块是由Hu 等[23]提出的SE(squeeze-and-excitation)模块,同时提取特征图的空间与通道信息,在视觉领域的各种任务中得到广泛应用。Woo 等[24]提出CBAM(convolutional block attention module)模块,在SE 模块的基础上,利用串联结构提取通道与空间信息。Zhang 等[25]则使用shuffle 单元整合空间与通道信息,提出SA-net,参照人类视觉系统自上而下的特点,将每个尺度的输出特征图进行融合。
但是,相比于其他视觉识别任务,篡改取证特征较难识别[26]。因此,本文提出改进的自顶向下扩张卷积注意力(TDDCA,top-down dilation convolutional attention)模块,利用扩张卷积显著增强特征提取能力。
1.3 损失函数
损失函数是深度学习模型训练中非常重要的部分,可在训练中集中于正确的特征集合。计算机视觉任务大多选择不同的损失函数。图像分类任务中常用的损失函数有交叉熵损失(CEL,cross entropy loss)函数[27]。目标检测任务中常用的损失函数有为解决类别不平衡问题的focal loss[28]。图像识别领域(包括行人再识别、人脸识别等)中常用的损失函数有CosFace[29]等。篡改检测领域大多采用交叉熵损失,但优化过程中没有关注向量的方向。为解决这个问题,本文设计余弦相似度损失作为辅助损失函数,更好地优化网络输出向量的方向,从而让网络可以更快更好地收敛到最优位置。
2 网络结构
本文提出一个端到端的多篡改检测与定位模型,输入一幅篡改图像,输出该图像篡改的置信度,并定位拼接和移除篡改区域。如图1 所示,以HRNet和密集网络(DenseNet)为基线,提取图像RGB域和SRM(steganalysis rich model)域双流特征信息,利用自顶向下扩张卷积注意力TDDCA 模块融合双流多尺度特征,最后利用扩张卷积(MDC,mixed dilated convolution)模块[30]训练完成篡改检测和定位任务。
2.1 双分支主干网络
主干网络由高分辨率HRNet 分支和SRM 密集分支(SRM DB,SRM dense branch)组成,如图1所示,其中HRNet 分支通过并行连接高分辨率到低分辨率卷积提取篡改图像RGB 流特征。为最大限度地利用SRM 流的信息,本文借鉴DenseNet[31]设计思路,提出SRM DB,利用密集连接SRM 流信息,不仅增强篡改特征提取能力,而且避免网络传播过程中特征丢失,降低梯度消失的风险。SRM DB中第l层的特征图Xl为
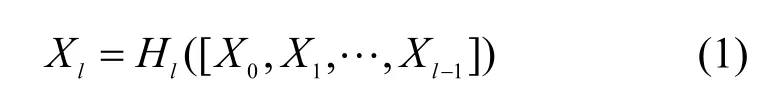
其中,[X0,X1,…,Xl-1]表示从第0 层到第l-1 层特征图的通道连接,Hl(·)表示第l层卷积模块。
本文选取SRM DB 中4、8、16 和32 倍下采样的特征图与HRNet 对应特征图进行通道连接,如图1 通道连接模块所示。
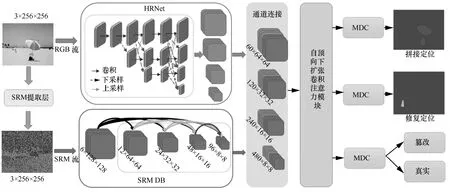
图1 高分辨率扩张卷积注意力网络结构
2.2 自顶向下扩张卷积注意力模块
文献[26]提出的自顶向下的注意力网络,模仿人类视觉注意力特点。但是,受其感受野限制,在篡改检测与定位任务中存在缺陷。基于此,本文提出自顶向下扩张卷积注意力模块,如图2 所示。在传统的注意力模块中加入扩张卷积模块,使其感受野更加丰富,并利用残差连接,在增强信息传递的同时还能避免梯度消失。本文对图像流和SRM 流中4 个尺度的特征图进行注意力,专注于篡改特征的提取,在多篡改检测任务上发挥更好的效果。
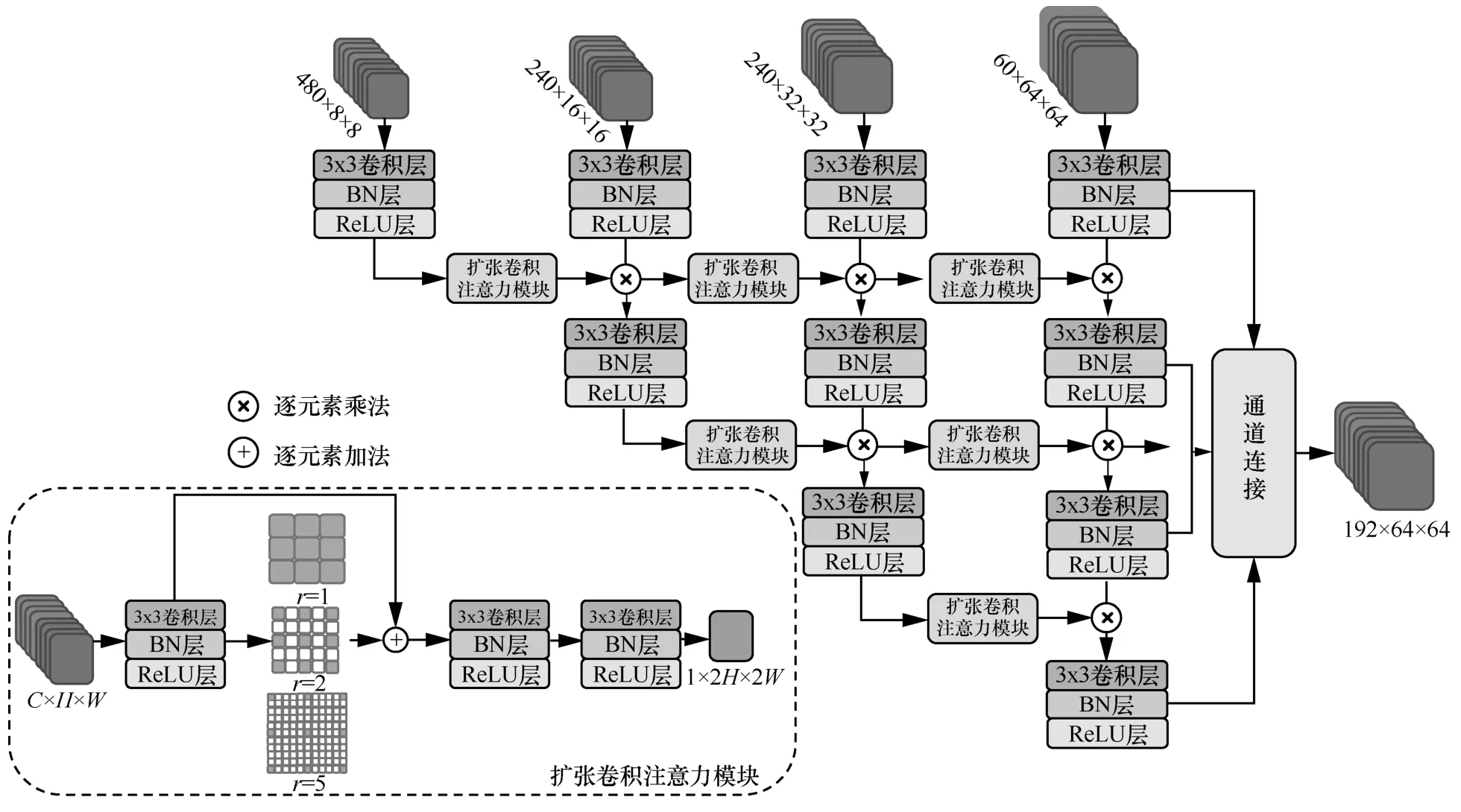
图2 自顶向下扩张卷积注意力TDDCA 模块
2.3 训练方法
多篡改检测和定位任务要求同时检测出多个篡改类型。实验表明,不同篡改类型具有不同的篡改特征,为了能够让网络学习到不同类型所独有的特征,引入扩张卷积模块进行不同篡改任务的特征提取。
HRDA-Net 在检测模块训练时包含真实图像,但是在定位模块训练时,真实图像的加入会造成网络难以收敛的问题。为解决该问题,本文采用分步训练方式。篡改检测和定位任务的特征图基本一致,即可先训练定位模块后冻结参数,再单独训练篡改检测模块,可在不影响定位模块的基础上,让检测模块学会提取检测任务所需特征。因此,本文的训练步骤主要分为两步:第一步,使用自制拼接数据集对网络进行预训练后,采用MM Dataset训练拼接和移除篡改定位模块;第二步,将主干网络参数冻结,单独训练篡改检测模块。训练步骤如图3 所示。

图3 训练步骤
2.4 损失函数
主流篡改检测模型使用的损失函数通常不关注输出向量方向的优化。为解决该问题,本文提出余弦相似度函数作为辅助损失函数,在向量方向上进行优化,其目标是预测值ypred和标签值ylabel一致,即ypred和ylabel之间的夹角余弦值为1。因此,本文设计余弦相似度损失函数Lcos如式(2)所示,取值范围为[0,1]。
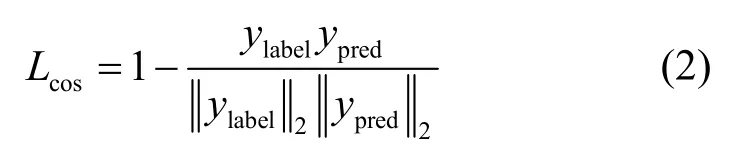
HRDA-Net 的训练主要分为2 个步骤,每个步骤都有各自的损失函数,如图3 所示。第一步为拼接和移除区域定位训练,包含2 个并行的MDC 模块,所以定位的损失函数Lloc包含拼接损失Lsplice和移除损失Lremove,如式(3)所示。
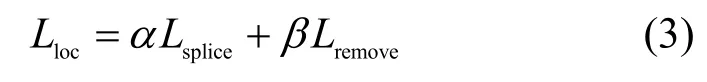
其中,权重α=0.5 和β=0.5 以保证拼接和移除定位任务平等。Lsplice和Lremove如式(4)和式(5)所示。

其中,γ1=γ2=1.0,δ1=δ2=0.4(经多组实验选取的经验值,可加快收敛速度)。LBCE表示交叉熵损失函数,如式(6)所示。

其中,ylable和ypred分别为真实和预测标签。第二步单独训练篡改检测时,使用交叉熵LBCE作为其损失函数。
3 实验结果
为验证HRDA-Net 多篡改检测与定位性能,本文在MM Dataset 进行消融和稳健性实验。在对比实验中,本文首先与主流语义分割模型进行对比,将多篡改定位作为3 类语义分割任务,即将篡改图像分类为背景、拼接和移除区域。为验证HRDA-Net在单篡改定位任务上的性能,本文在CASIA 与NIST 数据集上进行微调,与主流单篡改定位模型进行对比。
3.1 MM Dataset 与实验数据集
本文构建MM Dataset,真实图像从COCO[22]数据集中选取,包含1 000 组真实图像和篡改图像,分辨率为640 像素×480 像素,使用Photoshop 工具对每一幅图像进行拼接和移除篡改。拼接操作下,篡改源与目标图像的光照、对比度、尺度等信息不同,因此,本文针对目标图像的像素分布特点,对拼接源区域进行了相应的后处理操作,包括亮度、对比度、尺度变换、目标翻转等。在移除篡改操作中,利用Photoshop 仿制图章、修复画笔、修补工具等,根据待移除区域的像素分布特点选取相对应的移除区域,如图4 所示,其中,篡改区域中黑色为背景区域,灰色为拼接区域,白色为移除区域。

图4 多篡改数据集图像示例
深度学习模型训练需要有大量数据作为支撑,但CASIA、NIST 和MM Dataset 的数据量都不足以支撑模型训练。本文首先使用程序自动生成15 000 幅拼接篡改图像对模型进行预训练。自制数据集从COCO数据集中随机选择两幅图像,对其中一幅图像使用COCO 数据集提供的标注信息随机选取一个目标,并粘贴到另一幅图像。数据集使用情况如表1 所示。

表1 数据集使用情况
3.2 度量评价和实验参数设置
为了全面量化模型的性能,本文选用4 个指标进行评估,分别是准确率precise、召回率recall、F1 分数和误检率fp。其中,F1 度量多篡改区域定位的精度,误检率fp 度量真实像素被检测为篡改像素的比例,即“伪影”问题。计算式如式(7)~式(10)所示。


其中,TP 表示预测正确的篡改像素点数目,FP 表示预测错误的篡改像素点数目,FN 表示预测错误的真实像素点数目,TN 表示预测正确的真实像素点数目。本文采用正确率Accuracy 指标对篡改检测分类结果进行评估,如式(11)所示。

其中,correct_num 表示预测正确的图像数量,image_num 表示测试的图像总数。另外,本文与主流篡改定位方法对比,引入AUC(area under curve)指标,即接收者操作特征(ROC,receive operating characteristic)曲线下方与坐标轴围成的面积。
本文实验环境是Pytorch 1.8,Torchvision 的版本为0.4,CPU为Intel I5-10400f,内存大小为16 GB,显卡为RTX2060 6G。在整个实验过程中,学习率始终设置为1×10-4。使用SGD 作为损失函数,weight_decay 取值为5×10-4,moment 取值为0.9。在进行模型预训练的时候,本文使用HRNet 官方提供的语义分割预训练模型。
3.3 消融实验
1)模型有效性实验
为验证HRNet、SRM DB、TDDCA、MDC 和Lcos损失有效性,本节在MM Dataset 上进行消融实验,如表2 所示,其中,加粗字体表示性能最优值,√表示实验模型包含对应模块,×表示实验模型不包含对应模块。本文使用不同结构分支分别提取RGB流与SRM 流特征,产生特征空间位置偏移,如表2第二行所示,直接进行双流特征融合后,实验结果较单流HRNet 提取RGB 特征相比,拼接-F1 降低0.31,移除-F1 降低0.33,误检率fp 升高0.06,Accuracy 降低0.07。因此,为消除特征流空间位置偏移,本文提出TDDCA+MDC 进行特征融合,实验结果如表2 第三行和第四行所示。实验结果表明,采用TDDCA+MDC 的特征融合,F1 性能最优,且fp 最低。通过损失函数消融实验分析,在多篡改区域定位任务中,添加Lcos性能提升,但在多篡改检测任务中添加Lcos,误检率fp 保持不变,但由于过拟合F1 性能稍微下降。因此,本文在多篡改检测任务损失函数设计中,仅采用交叉熵损失,没有添加余弦相似度损失。
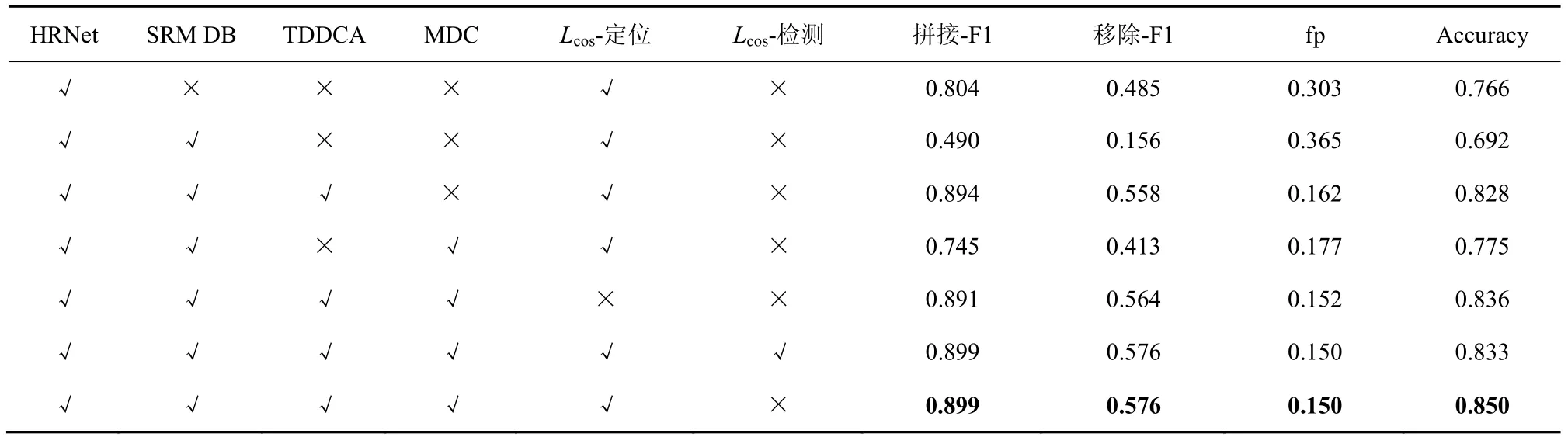
表2 模型有效性消融实验结果对比
2)训练方法有效性实验
为验证本文提出的分步训练方法有效性,本节分别对多篡改定位单任务、多篡改检测单任务,分步训练是否冻结参数进行消融实验,实验结果如表3 所示,其中,—表示没有相对应的实验数据。

表3 训练方法有效性消融实验结果对比
实验结果表明,本文提出的多篡改定位和检测分步训练方法在冻结参数后,加入真实图像进行篡改检测任务训练时不影响多篡改定位性能,但较多篡改检测单任务Accuracy 降低0.02。若训练篡改检测任务时不进行参数冻结,受真实图像影响,拼接-F1和移除-F1 分别下降0.36 和0.35,误检率fp 升高0.11,但篡改检测任务Accuracy 提升0.06。因此,本文选择分步训练时,冻结多篡改定位任务参数,保证多篡改定位和检测2 个任务性能指标较优。
3.4 稳健性实验
真实场景下,篡改图像大多经过各类后处理操作,如网络传输压缩、噪声等。因此,抗后处理操作稳健性的篡改检测与定位框架尤其重要。本文设计6 种后处理操作的稳健性实验,分别是JPEG 压缩、高斯噪声、高斯模糊、亮度、对比度和色彩平衡,具体的参数设置如表4 所示。

表4 稳健性实验后处理操作及其参数设置
本文在MM Dataset 分别对HRDA-Net 的篡改检测(Accuracy)和篡改定位(拼接-F1、移除-F1、fp)2 个任务进行实验,如图5 所示。实验结果表明,在篡改定位和篡改检测任务中,HRDA-Net 在各个参数的后处理操作下,实验结果平稳,稳健性较好。移除篡改定位任务在高斯噪声和亮度后处理操作中,随着参数增大性能有所降低,但在JPEG 压缩、高斯模糊、对比度和色彩平衡后处理操作中稳健性较优。

图5 稳健性实验结果
3.5 对比实验与分析
1)语义分割模型对比实验
训练语义分割模型时,将多篡改任务当成一个三分类的语义分割任务,损失函数全部使用多分类的交叉熵损失。本次实验中与HRDA-Net 进行对比的模型包含FCN[32]、Deeplabv3[33]、PSPNet[34]、DANet[35]、RRU-net[7]和HRNet[17],实验结果如表5所示,其中,加粗字体表示最高值。在拼接篡改定位、移除篡改定位和篡改检测任务中,HRDA-Net 相较其他模型有明显优势,除拼接篡改定位任务的precise指标低于FCN[32],本文HRDA-Net 的precise、recall和F1 均最优。由此,HRDA-Net 相对于传统语义分割模型更加适合于多篡改检测与定位任务。另外,相较于拼接篡改定位,移除篡改定位分数较低,一方面是因为在预训练只使用拼接篡改图像,另一方面是移除篡改的特征相对于拼接篡改来说更难提取。HRDA-Net 在MM Dataset 的实验结果示例如图6 所示,其中,黑色表示背景区域,灰色表示拼接篡改区域,白色表示移除篡改区域。

表5 HRDA-Net 与主流语义分割模型对比实验结果

图6 HRDA-Net 在MM Dataset 的实验结果示例
2)单篡改定位模型对比实验
本文在CASIA 与NIST 数据集上与主流单篡改定位模型进行对比,实验结果如表6 所示,其中,加粗部分表示相应列中的最高指标,—表示在发表的论文中没有相对应的数据。实验结果证明,HRDA-Net 在NIST 数据集上的F1 和AUC 分数均最优,其中F1 和AUC 分数分别比次优SEINet 高了近6%和1.3%;在CASIA 数据集上的F1 分数达到最优,比SEINet 高0.8%,且AUC 分数与GSCNet持平。由此证明,HRDA-Net 泛化性较好,进行单篡改定位任务时性能仍较优秀。HRDA-Net 在CASIA和NIST数据集上的可视化结果如图7所示,其中,黑色表示背景区域,灰色表示拼接篡改区域。

图7 HRDA-Net 在CASIA 和NIST 数据集上的可视化结果
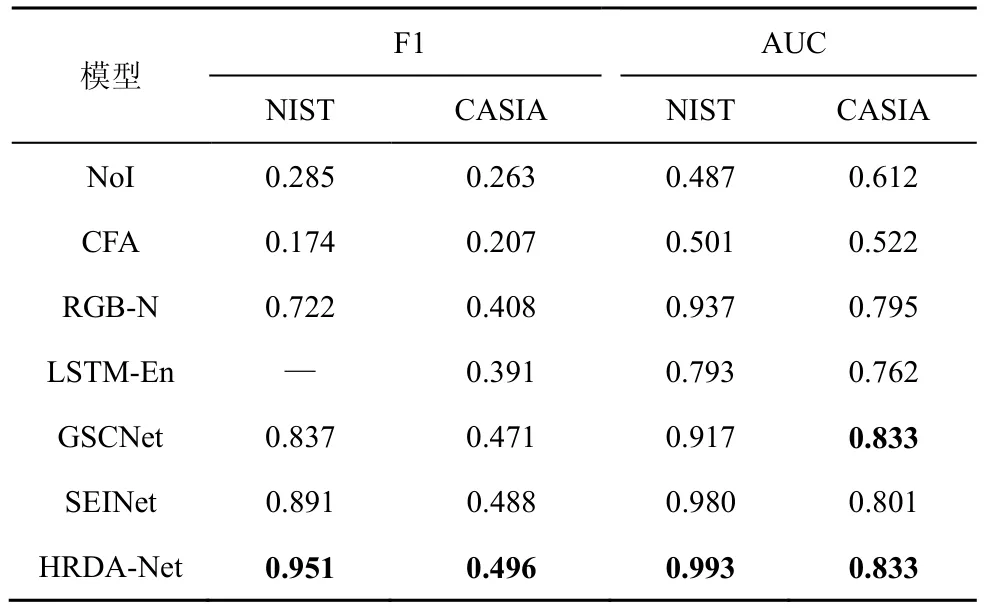
表6 CASIA 和NIST 数据集中单篡改定位对比实验
4 结束语
针对真实场景下图像篡改通常包含多类篡改操作问题,本文提出MM Dataset 及多篡改检测和定位模型HRDA-Net。对比实验结果证明,HRDA-Net模型具有较强的篡改检测和定位性能,并且在6 种后处理操作中都具有较好的稳健性和泛化性。本文是多篡改取证任务的一次初步尝试,所提出的MM Dataset 目前只包含拼接和移除2 种篡改手段。在今后的工作中,作者将会继续完善,包含更多篡改操作,如复制-粘贴等,并提出更加具有泛化性以及拥有更强检测性能的多篡改检测与定位算法。
