基于机器学习的实时云数据关联规则提取与运维分析方法
2022-02-27倪家明贺小刚王丹丹
倪家明,张 耀,刘 鹏,贺小刚,王丹丹
(1.国网天津市电力公司,天津 300010;2.天津三源电力信息技术股份有限公司,天津 300010)
关联规则提取的主要方向是实时云数据挖掘,将该规则应用到数据挖掘过程中,能够展现出不同数据之间的关系[1-2]。随着因特网数据规模的不断扩大,各维度云数据的复杂性越来越高,对实时云数据关联规则展开有效提取有利于后期的数据运维分析[3]。
文献[4]中设计了基于Spark 的关联规则并行化挖掘与提取方法,该方法能够发现大量实时云数据之间的联系,并确定数据之间的连续性,通过关联分析过程实现规则挖掘与提取。文献[5]中设计了基于多目标协同进化遗传算法的关联规则提取方法,该方法利用帕累托原理优化遗传种群个体,然后利用个体相似度的基因型完成个体配对,并分割变异种群,再利用精英种群保存交叉种群的方式求取帕累托最优解集,从而寻找连续型数值属性,完成对规则的提取。然而,在实际应用中发现,传统提取方法的项集标记结果不全面,易导致实例数据集与实际情况不一致。为此,该文设计了基于机器学习的实时云数据关联规则提取方法,利用其为数据运维分析奠定基础。
1 提取任务调度模型设计
1.1 机器学习网络架构
该文在贝叶斯概率支持下设计机器学习网络模型,并调整隐层和可视层权重参数,由此生成深度网络目标数据。机器学习网络架构如图1 所示。

图1 机器学习网络架构
图1 中,多层玻尔兹曼集组成了一个机器学习网络。神经网络将神经元分为显性神经元和隐性神经元,上层和下层神经元之间有联想记忆单元,这一联结是没有方向的,可用于实现联想记忆功能[6-7]。
1.2 机器学习网络训练
机器学习网络训练主要包括无监督训练和调优两个步骤:
步骤一:无监督训练。特定任务是分层训练受限制玻尔兹曼机器,每一层输出结果都可作为上层输入层[8]。上部神经元被标记时,需要进行标记联合训练[9]。
步骤二:调优。调优主要分两个阶段进行:认知阶段和制作阶段。其中,认知阶段是依据机器学习模型输入特征信息,并逐层输出结构,再依据梯度下降法生成逐层权重参数。基本状态信息由生成阶段的顶层标签标注并与向下权重信息组成,向上权重信息也在该阶段被修改[10-11]。
在机器学习网络的特征提取过程中,需要对输入信号进行向量表示,并对其进行训练。最高级别的联想记忆单元根据下级提供的线索来划分任务[12]。通过基于标记数据的前馈神经网络,机器学习网络能够精确调整分类性能,并在最后一层训练中进行识别[13]。与直接使用前向神经网络相比,该方法具有更高的效率,因为机器学习网络只需要修改权重参数就可以进行局部训练[14],因此训练速度快、收敛时间短。
1.3 模型构建
图2 中显示了所采用的系统模型结构。左侧为任务队列,右侧为资源队列,中间为负责任务与资源匹配的中央服务器。

图2 任务调度模型
该模型在加入辅助变量后产生亏损队列,该队列表示当前收益与目标收益差值,通过加入调节权重能够控制系统收益平衡,以最小化构建排队处理与运维任务[15],具体过程如下:根据资源聚类内容,生成调度队列,保证队列资源分配合理;对于一个队列,选择合适的辅助资源,从中挑选最大值;在最大挑选结果支持下,获取生成资源向量;根据不同公式间生成关系,更新任务、资源向量[16]。
2 实时云数据关联规则提取
2.1 关联规则
假设存在m个项目集合I={i1,i2,…,im},确定事务数据库D,其中每个项集T都具有唯一标识符TID。若项目集为X⊂I且X⊂T,则事务集T包含项目集X,且X⇒Y蕴涵形式为关联规则的一般表示。
关联规则包括支持度和可信度两个方面,当事务集同时支持多个事务时,可将其归纳到同一个事物数据库中,该数据库为关联规则支持度。支持度对表达规则的频率提供支持,并描述数据集中规则的前因和前因出现的比例。用minsup表示最小支持度,support(X)表示支持度统计显著值。
对已知的事务数据库D来说,在支持事务集X的事务中,还有支持事务集的事务,即关联规则X⇒Y的置信度。置信度代表着规则的强度,描述了规则在满足其前提条件下发生的可能性。用minconf 表示规则的最小可信度,置信度大于最小可信度的关联规则成为强规则。
此关联规则基于以下条件建立:
1)事务数据库中,至少存在一个支持度,作为整个数据库的支持度;
2)交易数据库中,至少存在一个支持度,该支持度(在支持事务集X的事务中,还有支持事务集Y的事务)作为整个数据库的支持度。
关联规则挖掘问题在于,在事务数据库中,指定一个支持度最低值和一个信任度最低值,确定一个支持度和信任度高于两个预定值规则。
关联规则提取可以分为如下两步:
1)找到一组项集,其支持程度不低于用户给出的最小支持度,即为强项集;
2)从强项集中导出关联规则,对于每一个强点集A,如果B⊂A且B≠ϕ,就有一个关联规则B⇒(A-B)。
2.2 寻找强项集
因为不同项目集的数量较大,所以要计算出所有项目集的支持是不可能的。机器学习算法是一种快速有效的方法,该方法将多次扫描数据库中的大型项目集。
为方便表述,假设事物中项目集按照字典顺序排列,该序列中包含k项集,每一个项集有一个计数域count,以储存对项集的支持度。count≥minsup的k项集称强k项集,记为Lk。若r为强项集,则所有非空白项也是r。反之,如果一个项目集的非空子集不是强项集,那么其就不是强项集。
基于此,求取Lk强项集Ck,该项集中任意一个项集的非空子集为强项集,即:

其中,s⊂r,且s≠ϕ,support(s)≥minsup。
机器学习扫描原理为:经过k次扫描后,数据库D中的强项集为Lk。经过k-1 次扫描后,得到的数据在Lk-1基础上,可由Lk求取出候选强项集集合Ck。
对于任意一个规则,如果在强项集Ck中出现,那么该项集的计数域count将会增加1。在完成扫描后,强项集Ck的count≥minsup所有项集均加入Lk中。
2.3 实时云数据库优化
对事务中每一次计算Ck支持的已删除项集,调用不包含任何标签的事务,在以后的扫描计数中计算候选项集的数目,支持的记录数目比实际事务在数据库中的数目少,且随着k值的增大,差异也随之增大,从而有效地减少候选项集的计数,提高算法的效率,数据库以及优化过程数据库变化如图3 所示。
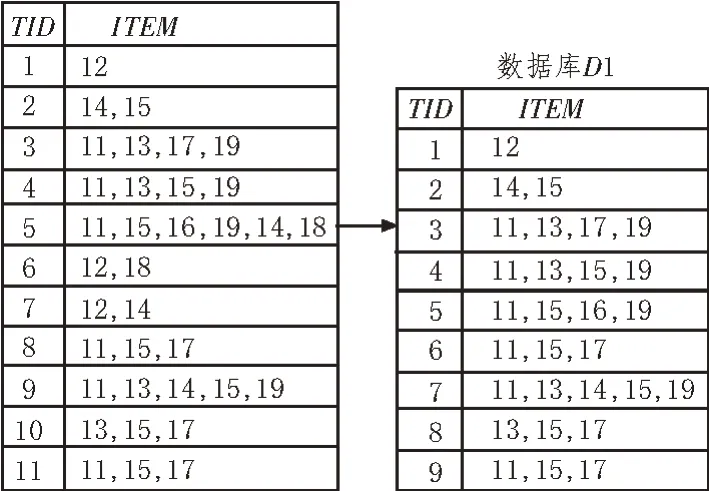
图3 数据库以及优化过程数据库变化
2.4 关联规则运维描述
依据数据库优化结果,描述关联规则运维流程:
Stepl:以数据库D为例,输入最小支持度,通过一次扫描计算每个项目集的支持度,得到集L1;
Step2:为了产生频繁的k个项目集Lk,要按照已优化的连通性方法产生k-1 个项目集Lk-1(项目集中的项目按其出现在整个数据库中的频率递增);
Step3:计算Lk-1项频率,然后标记频率小于k+1的项,删除包含任意元素的频繁项集合,得到一个新的较小的频繁项集合k-1;
Step4:没有任何项目集的事务被标记为Delete,随后单程扫描数据库,计算每一项的支持度Ck;
Step5:从Ck中删除不符合最低支持度项目集,并形成Lk;
Step6:重复Step2~Step5,直到无法生成一组新的频繁项目集为止。
3 实验与分析
为验证基于机器学习的实时云数据关联规则提取与运维分析方法的合理性,设计如下实验。分别使用传统的基于Spark 的关联规则并行化挖掘与提取方法和基于多目标协同进化遗传算法的关联规则提取方法作为对比,与该文方法共同完成性能验证。
3.1 实例数据分析
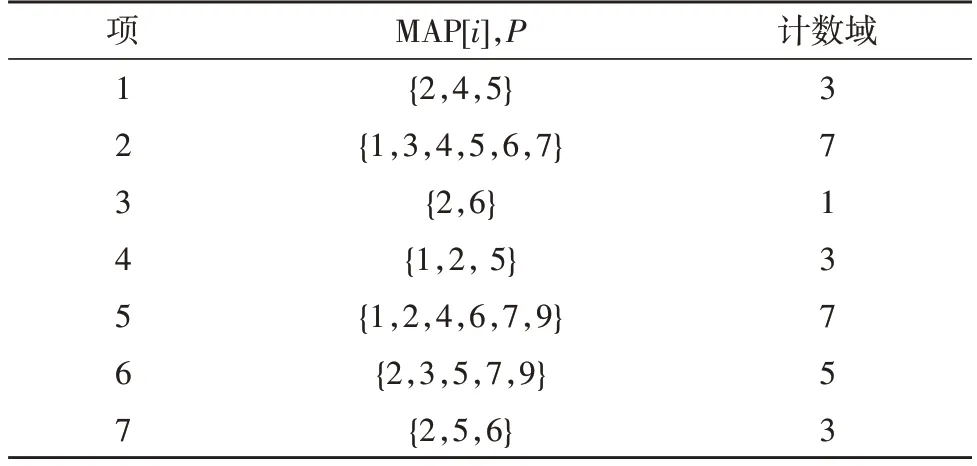
表1 实例数据分析
3.2 实验结果与分析
不同方法对实时云数据关联规则的提取结果如图4 所示。
由图4 可知,应用基于Spark 的提取方法后,获取的实例数据集与实际情况不符,存在10 个项集;应用基于多目标协同进化遗传算法的提取方法后,获取的实例数据集与实际情况不符,存在9 个项集;应用基于机器学习的提取方法后,获取的实例数据集与实际情况一致,存在7 个项集。由此可知,该文方法的提取效果更好。

图4 不同方法的关联规则提取结果
4 结束语
在生成大型实时云数据项目集后,利用机器学习法过滤强项集,减少繁琐计算步骤,避免了对机器学习算法的裁剪,减少了循环次数。实验结果表明,该文设计的基于机器学习的实时云数据关联规则提取方法是有效可行的,可为数据运维分析奠定良好的基础。
