基于EMD-LSTM的重介分选精煤灰分时间序列预测方法研究
2022-02-26王然风
程 凯,王然风,付 翔
(太原理工大学 矿业工程学院,山西 太原 030024)
煤炭重介分选是根据阿基米德定律通过改变重介质悬浮液密度分选出符合质量要求的精煤产品,重介精煤灰分作为衡量重介精煤质量最主要的指标,将重介精煤灰分精确控制在合理区间内不仅能保证重介精煤质量,而且能减少原煤的损耗,这对选煤厂的高效绿色发展有着重大意义。目前,重介选煤精煤灰分闭环控制处于起步阶段,由于选煤属于流程性工艺,实时重介精煤灰分检测相对于其对应的重介悬浮液密度设定存在一定的滞后性,所以重介精煤灰分还不能及时有效地反馈指导重介悬浮液密度的自动设定,从而无法充分保证重介精煤灰分能长期稳定在合理区间内。目前,国内外对于这方面的研究有所缺乏,文献[1]采用了BP神经网络构建预测模型,但该研究存在着一个比较大的缺陷:训练样本对于BP神经网络来说很重要,只有选择合适的样本才能保证预测的准确性。而对于选煤厂的实际运行情况来说,重介精煤灰分数据具有随机性、偶然性等特点,所以模型选择需要具有很强的普适性,适应绝大部分时间下的重介精煤灰分数据。文献[2]是通过回归分析法建立预测模型,但回归分析不能很好地拟合精煤灰分时间序列中的非线性数据,需要先判断变量之间是否具有线性关系。文献[3]则是采用0.618法对参数进行寻优,直接预测重介悬浮液密度,这无法适应原煤灰分波动较大的工况,具有很大的局限性。文献[4]根据质量守恒原理,建立了主要包括以合介桶所加重介质和补水量为输入、重介质悬浮液密度为输出的回路过程模型,以及以重介质悬浮液密度为输入、精煤产品质量为输出的运行过程模型,但该模型进行了大量的简化和假设,与实际的生产过程有比较大的差距。文献[5]通过原煤的特性、分离技术和运行指标实现对重介质悬浮液密度的智能控制,但原煤的复杂性要远远高于精煤,特别是灰分的非线性、非平稳性和随机性更强,不利于自动控制系统的构建。
基于上述问题,本文提出了一种基于经验模态分解(Empirical Mode Decomposition,EMD)和长短期记忆神经网络(Long Short-Term Memory,LSTM)的灰分预测方法,EMD-LSTM灰分预测方法既能保证对非线性、非平稳和随机性的原始信号的有效处理,减小原始精煤灰分信号中的噪声对预测准确度的影响,还适合于处理和预测类似重介分选精煤灰分时间序列这类属于流程工艺而造成的延迟较长的事件。根据应用在山西焦煤集团中兴选煤厂的实际灰分数据的实验结果表明提出的基于EMD-LSTM的灰分预测算法可有效提高重介精煤灰分数据的预测精度。
1 重介精煤灰分时间序列预测方法
1.1 重介精煤灰分预测的必要性
中兴选煤厂采用有压三产品重介旋流器分选工艺,原煤由给煤机送入到旋流器中,然后将一定密度的重介质悬浮液以一定压力打入旋流器中,通过离心力将原煤分为精煤、中煤和矸石,精煤再经过弧形筛和脱介筛进行脱介和脱水,最终得到符合质量要求的精煤产品。重介分选工艺属于典型的流程性工艺,重介悬浮液密度的设定处于流程的前端,重介精煤灰分的测定处于流程的末端。生产流程中影响精煤灰分的因素众多,包括原煤煤质、悬浮液密度等等,这就导致重介精煤灰分时间序列具有非线性、非平稳和随机性的特点,而且由于现场不确定的工况和人为操作失误等因素,重介精煤灰分时间序列还往往包含着“噪声”。
中兴选煤厂实际生产情况表明,当前重介精煤灰分值相对于其对应下的悬浮液密度设定存在着15min左右的滞后,这对于重介分选密度自动控制系统来说是一个不可忽视的问题,长时间的滞后可能会导致原煤和介质的不必要损耗以及重介精煤灰分无法及时有效地控制在合格区间内。所以,解决精煤灰分时间序列的大滞后性成为实现重介精煤灰分自动控制的首要问题。对重介精煤灰分进行短期预测是解决滞后性的一种有效可行的方法。
1.2 重介精煤灰分预测方法基本框架
针对重介精煤灰分时间序列非线性、非平稳、随机性和包含噪声,以及大滞后性等特征,本文提出了基于EMD-LSTM的重介精煤灰分时间序列预测方法。
1.2.1 EMD和LSTM
EMD是由Huang于1998年提出的一种新型自适应信号时频处理方法[6],由于EMD突破了傅里叶变换的局限性,EMD方法在理论上被广泛适用于将任何一种类型的包括精煤灰分时间序列(信号)分解成不同时间尺度的时间序列(信号)分量,因而在对精煤灰分时间序列划分时间尺度的数据处理上,比之前的传统的时频处理方法更加突出。它能将复杂的信号分解成为有限个本征模函数(Intrinsic Mode Function,IMF)和一个残差r(t),所分解得出来的各IMF分量都包含着原始时间序列中不同长期时间尺度的各个局部特征信号,残差所反映出来的往往是原始时间序列的长期总体的趋势[7]。通过分析经过分解后得到的不同时间尺度的分量,能判断出造成原始时间序列具有非线性、非平稳和随机性特征的“噪声”主要存在的时间尺度分量,再经过合理地选择IMF分量重构信号,摒弃包含“噪声”的IMF分量,就能达到降噪的目的,从而有效地减小噪声对预测性能的影响,提高预测的准确性。
LSTM作为一种为了解决一般的循环神经网络(Recurrent Neural Network,RNN)存在的长期依赖问题而提出的特殊的时间循环神经网络[8],由于其神经细胞单元中独特的门限设计结构,LSTM适合于处理和预测重介分选精煤灰分时间序列这类属于流程工艺而造成的延迟较长的事件[9]。
因此,EMD-LSTM算法对于重介分选精煤灰分预测不仅能在前期对原始数据进行有效的“降噪”预处理,还能利用LSTM适合于处理和预测时间序列中间隔和延迟较长的重要事件的特点,建立适合重介分选工艺的精煤灰分预测模型。
1.2.2 预测方法基本框架
基于EMD-LSTM的重介精煤灰分时间序列预测方法框架如图1所示。
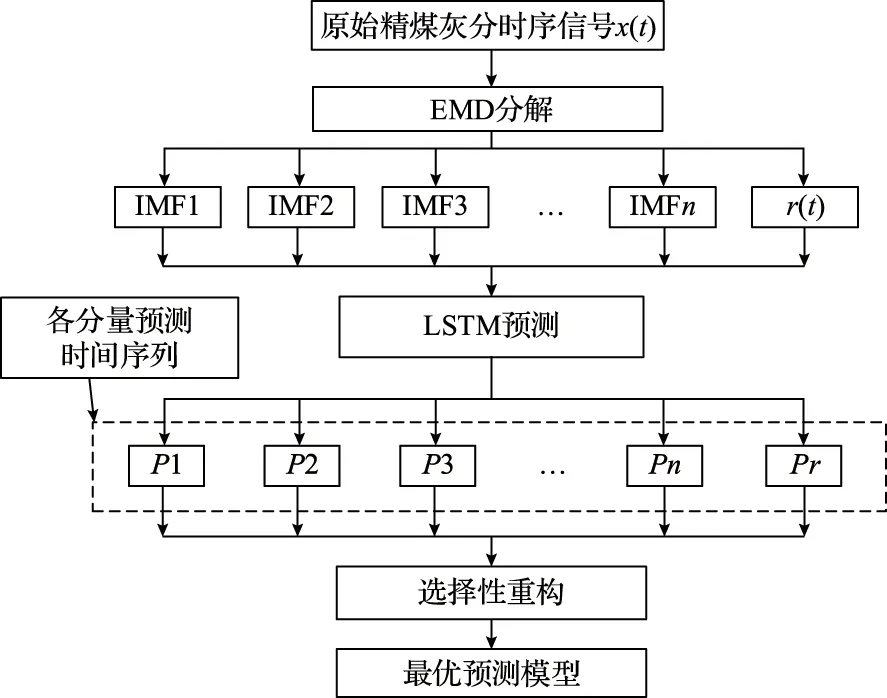
图1 灰分指标时间序列预测方法框架
首先,将原始精煤灰分时序信号x(t)进行EMD分解,得到有限个IMF分量和一个残差r(t)[10];其次,利用LSTM神经网络对各IMF分量和残差r(t)进行预测,分别得到对应的预测时间序列Pi(i=1,2,3,…,n,r);最后,根据对EMD分解后分量的分析结果进行选择性重构,剔除包含噪声的分量以达到降噪的目的。
1.3 时间序列预测方法构建基本过程
1.3.1 精煤灰分时序信号的EMD分解
原始重介精煤灰分时序信号的EMD分解有以下七个步骤:
1)根据原始精煤灰分时序信号x(t)确定上下极值点,分别画出上包络线emax(t)、下包络线emin(t)。
2)求取上包络线emax(t)、下包络线emin(t)的平均值,得到精煤灰分时间序列均值包络线m1(t)[11]。公式如下:
3)令原始精煤灰分时间序列信号x(t)减去均值包络线m1(t)得到一个去掉低频信号的新时间序列,即h1(t)[12]。公式如下:
h1(t)=x(t)-m1(t)
(2)
4)判断h1(t)是否满足IMF分量的2个判据:①IMF极值的数量(最大值和最小值的数量之和)与零穿越的数量必须相等或最多相差1;②在IMF的任意点,局部最大值定义的包络线的平均值和局部最小值定义的包络线的平均值应等于零[13]。若不满足上述2个条件,将h1(t)作为下一轮的原始数据,重复步骤1)—步骤3)直到满足判据;若满足,记c1(t)=h1(t),则c1(t)为第1个IMF分量,同时用原始精煤灰分时间序列信号x(t)减去c1(t),得到一个去掉高频的剩余分量,即r1(t)。公式如下:
r1(t)=x(t)-c1(t)
(3)
5)令r1(t)作为新的精煤灰分时间序列信号,重复上述步骤,得到x(t)的第n个IMF分量rn(t)[14]。
6)判断rn(t)是否满足给定的EMD分解终止条件(通常使rn(t)成为一个单调函数)[15],若满足,则循环结束;否则,循环分解继续。
7)由上述的一系列分解,最终可以得到n个IMF分量和一个残差rn(t)[16]。公式如下:
1.3.2 IMF分量和残差r(t)的LSTM预测
对各个IMF分量及残差r(t)时序信号利用LSTM分别进行预测,根据实际生产中选煤灰分过程控制对预测精度和预测时长的要求,确定实际灰分值与预测灰分值的差的绝对值|D|和预测时长T。预测值分别记为P1、P2、P3、……、Pn、Pr。
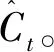
图2 细胞元状态传输过程
遗忘门:
ft=σ(Wf·[ht-1,xt]+bf)
(5)
输入门:
it=σ(Wi·[ht-1,xt]+bi)
(6)
候选信息:
新细胞状态:
输出门:
ot=σ(Wo·[ht-1,xt]+bo)
(9)
输出:
ht=ottanh(Ct)
(10)
1.3.3 各分量预测的时间序列选择性重构
为了将原始精煤灰分时序信号x(t)的噪声剔除,需要将P1、P2、P3、……、Pn、Pr进行重构,具体步骤为:
1)根据Pi(i=1,2,3,…,n,r)的频率分布将其分为高频部分、中频部分和低频部分。
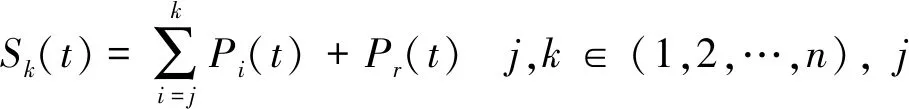
(11)
3)将得到的多个预测信号Sk(t)和原始精煤灰分时序信号x(t)进行比较,通过数据显示得出最优的预测模型。
1.4 时间序列预测方法结构原理图
基于EMD-LSTM的重介精煤灰分时间序列预测方法结构原理如图3所示,左侧框图内为EMD分解步骤;右侧框图内为LSTM预测步骤,其中需要对LSTM参数寻优,根据20min的预测时长确定训练数据的占比。
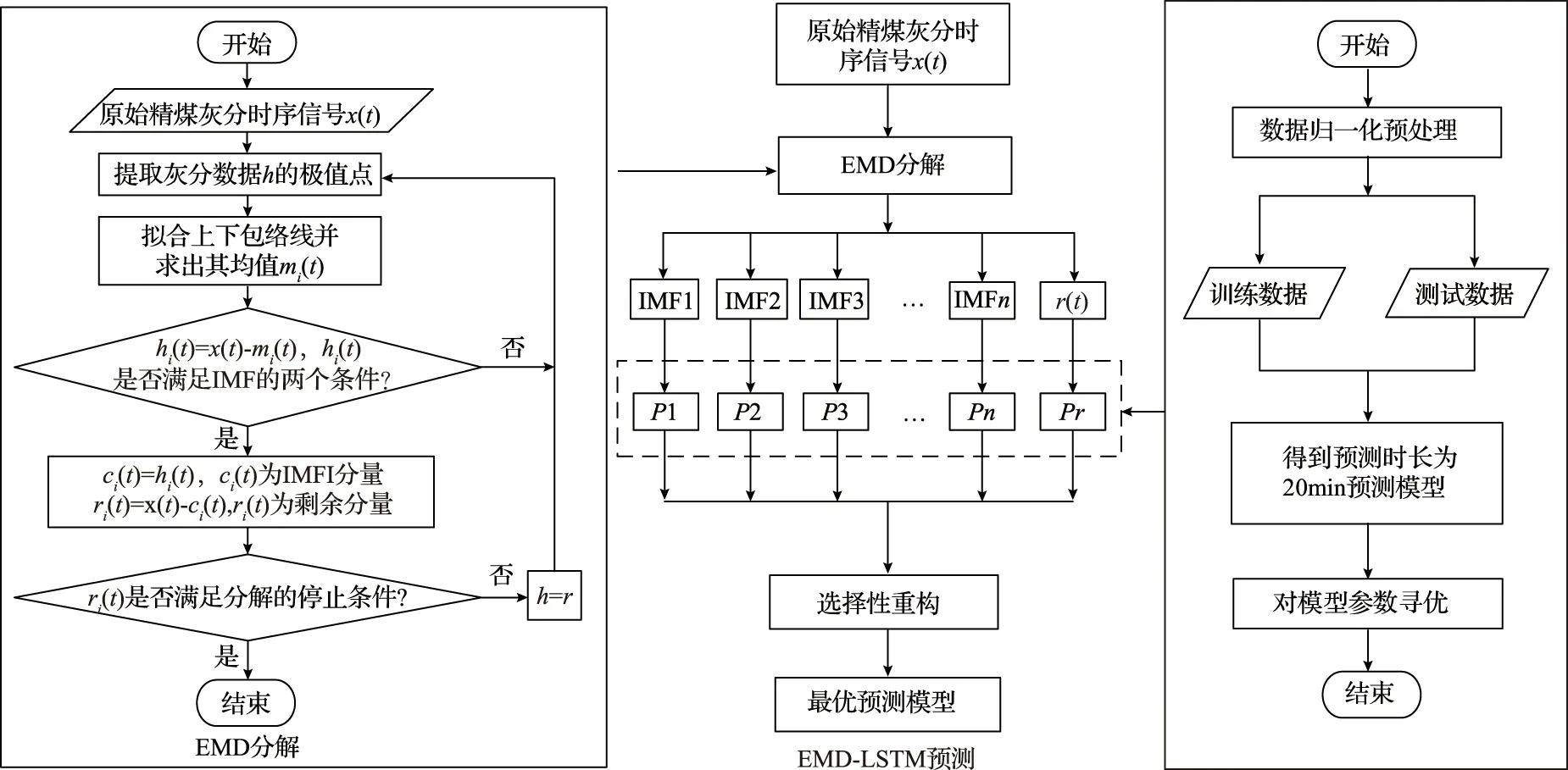
图3 EMD-LSTM预测模型结构原理图
2 重介精煤灰分数据分析
本文使用了一组中兴选煤厂持续时长为8h自动控制生产下的重介精煤灰分数据,根据EMD-LSTM预测模型进行实验。
2.1 EMD分解精煤灰分数据结果
重介精煤灰分数据分解结果如图4所示。原始数据共分解为8个IMF分量和一个残差r(t),其中IMF1、IMF2为高频分量,IMF3、IMF4为中频分量,IMF5、IMF6、IMF7、IMF8为低频分量,残差r(t)表明了灰分变化的总体趋势。通过对各分量的分析可知:原始数据的噪声主要来自高频分量,灰分变化趋势主要取决于中低频分量。频率阈值设定见表1。
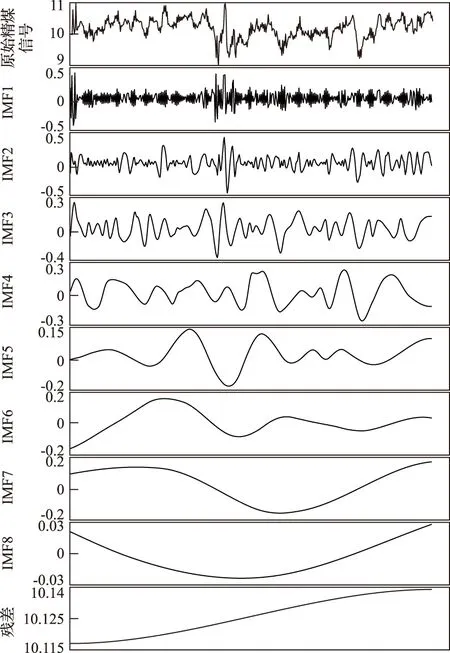
图4 精煤灰分EMD分解
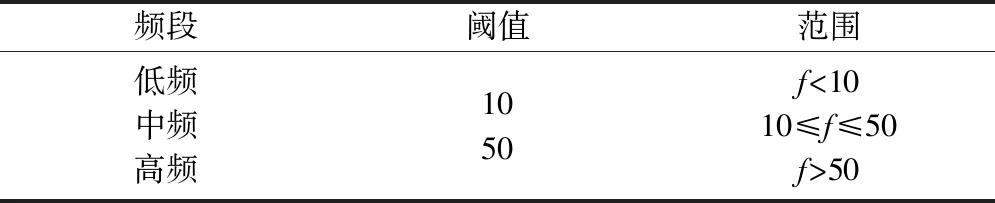
表1 频率阈值设定
2.2 时序分量LSTM预测分析
2.2.1 评价指标
1)误差(Deviation):通过误差大小可以判断实际值与预测值的一致性,公式如下:
D=pi-xi
(12)
式中,pi为预测值;xi为真实值。
2)标准差(Standard Deviation,SD):标准差能反映实际值与预测值差值的离散程度,公式如下:

3)平均绝对误差(Mean Absolute Deviation,MAD):平均绝对误差可以准确反映实际值与预测值误差的大小[19],公式如下:
4)变异系数(Coefficient of Variation,CV):变异系数可以反映两组数据离散程度的大小,公式如下:
2.2.2 实验设置
本文实验使用的数据样本时长为480min,采样频率为分钟取样,根据预测时长T为20min得训练数据占比为95.83%,测试数据占比为4.17%。根据实际生产中选煤灰分过程控制对预测精度的要求,本文设定|D|≤0.5为合格误差。
LSTM神经网络在不同隐含层数和学习率下降因子情况下将原始信号进行预测得到标准差σ、平均绝对误差λ和变异系数CV的值见表2。当LSTM神经网络的隐含层数为32,学习率下降因子为0.15时有最佳的综合效果。LSTM神经网络的其他参数有初始学习率、学习率下降周期等为默认参数,迭代次数为1000。

表2 不同隐含层数和学习率下降因子下的评价指标
2.2.3 实验结果
根据优化参数后的EMD-LSTM模型对各IMF分量和残差r(t)进行预测,选择性重构后的结果如图5—图8所示,标准差σ、平均绝对误差λ和变异系数CV评价指标结果见表3。
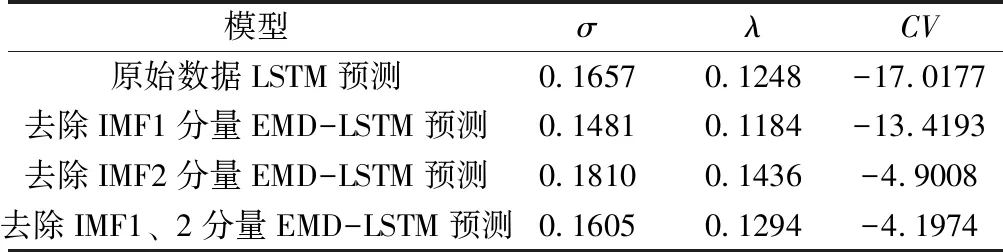
表3 不同模型下σ、λ、CV评价指标结果
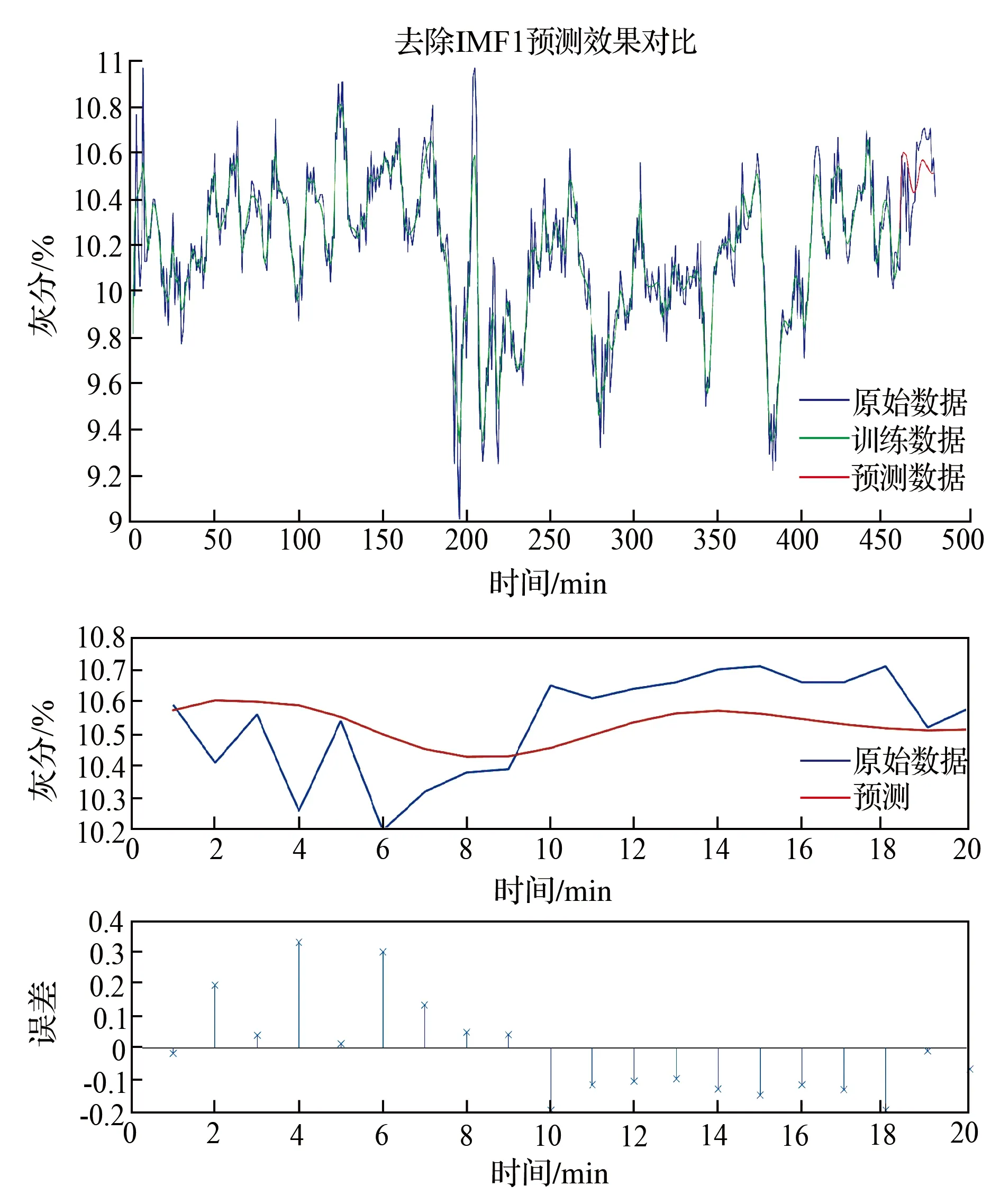
图6 去除IMF1分量EMD-LSTM预测结果

图7 去除IMF2分量EMD-LSTM预测结果

图8 去除IMF1、2分量EMD-LSTM预测结果
根据图5—图8比较可以直观看出,原始数据噪声主要存在于IMF1分量,去除IMF1分量后的预测曲线最逼近真实数据,变化趋势与真实数据保持很好的一致性,误差值范围D也控制在±0.4之内;而原始数据LSTM预测和去除IMF2分量EMD-LSTM预测误差虽然在合格范围之内,但是波动性较大,不利于作为重介精煤灰分闭环自动控制系统的输入量;去除IMF1、2分量EMD-LSTM预测虽然误差在合格范围之内,曲线也比较光滑,但变化趋势与真实值没有很好的一致性。
实验结果表明,去除IMF1分量后的EMD-LSTM预测模型的评价指标综合效果最佳,对重介分选精煤灰分具有良好的预测效果,符合实际生产中选煤灰分过程控制对预测精度和预测时长的要求。
3 结 论
1)实验结果表明,基于EMD-LSTM方法的重介分选精煤灰分时间序列预测中,去除IMF1分量的模型具有最佳的预测效果,符合实际生产中选煤灰分过程控制对预测精度和预测时长的要求。
2)EMD分解结果表示,影响重介精煤灰分预测准确性的噪声主要存在于高频分量IMF1,去除IMF1分量后既不会影响原始数据的整体变化趋势,还能对数据起到降噪处理;LSTM神经网络需要进行参数寻优,参数的变化对预测结果的准确性有很大的影响。
3)良好的重介分选精煤灰分指标时间序列预测方法对于灰分自动控制系统的完善具有重大的意义,对智能分选甚至是智能煤矿的发展具有巨大的推进作用。
