基于自适应阈值的大象流检测方法
2022-02-24李建华
刘 奕,李建华,陈 玉
1.空军工程大学 信息与导航学院,西安 710077
2.空军工程大学 研究生院,西安 710038
数据中心网络[1]作为联合装备网络的核心,对战场信息进行存储和处理,实现各军种装备信息实时共享。随着武器装备和信息技术的发展,数据中心网络通信量迅速增加,容易导致链路拥塞甚至中断,此时需要对网络中的异常流量进行准确检测,实现数据中心网络流量的实时监控和有效调度,从而提高链路传输的稳定性和可靠性。
目前,针对数据中心网络流量研究显示[2-4],数据中心的流量呈现“大小流”特性:9%的流发送的视频或语音等数据占网络总数据量的90%,此类流被称为“大象流”,而数量巨大但字节小于10 KB的文本或命令字等数据流被称为“老鼠流”。大象流具有数量少、持续时间长、带宽需求大的特点;老鼠流具有数量大、持续时间短、带宽需求小的特点。而且流的到达和离开非常快,使得SDN[5](software defined network)控制器很难为每个新流均能分配资源。同时,大量的异常流量会导致控制器被频繁调用,从而降低了控制器的工作性能和可扩展性。常用大象流检测方法包括基于用户终端的检测方法和基于网络链路的检测方法两种,文献[6]通过统计终端主机的套接字缓冲区来检测大象流,并通过带内信令的方式向网络控制器发送检测信号。文献[7-8]提出了一种基于OpenFlow[9]协议的分层统计提取机制来检测大象流,通过控制器实时统计流表信息,根据IP地址计算出单个流的大小。文献[6-8]方法均属于基于用户终端的检测方法,该类方法能够有效减少网络带宽资源消耗,但在大象流检测过程中采用了静态阈值的方式,没有考虑数据中心网络特性变化,当阈值设置过高,会出现较高的漏报率,从而导致大量的大象流无法被准确检测,当阈值设置过低,会检测到过多的老鼠流,容易导致路径拥塞。文献[10]利用控制器以轮询的方式统计当前各链路网络的流量信息,当数据流量超过10%的链路带宽时,即可看作是大象流。由于数据中心的流量传输速率越来越快,导致该方法较高的丢包率和漏检率,容易造成链路拥塞。文献[11]提出一种流量采样的检测方法,通过计算采样数据的统计特征来判断链路的网络流量,该方法通过增加流量采样率可以有效提高检测正确率,但是会降低链路利用率。文献[12]利用最久未用(least recent used,LRU)机制,首先利用第一级的LRU过滤大部分老鼠流,然后通过第二级的LRU对大象流进行计数和检测,该方法可以降低老鼠流置换LRU缓存中大象流的概率,有效降低了大象流的漏检率。文献[13-14]将LRU机制和布鲁姆过滤器(bloom filter,BF)机制相结合,提出一种基于LRU.BF策略的大象流检测方法,首先利用BF方法来检测是否存在大象流,然后结合LRU方法对大象流进行过滤,通过将大象流的过滤和判断相分离方式,降低了大象流的漏检率。
综上所述,本文提出一种自适应阈值的大象流量检测方法,采用动态流量学习(dynamic traffic learning,DTL)方法实时计算更新阈值,从而完成数据中心网络中低延迟、低开销的大象流检测识别。首先通过控制器发送一组流量统计请求来获取交换机的流量统计信息,然后分析流量特征与大象流之间的关系,通过基于高斯分布加权优化的DTL方法动态学习快速变化的数据中心流量来预测检测阈值,为了提高大象流检测的准确性,防止流表发生抖动,采用差分估计的阈值平滑机制,降低检测阈值配置更新频率。最后利用控制器将检测阈值配置至触发器,当流量的测量值(如流量的大小和持续时间)超过设置的检测阈值时,触发器将其判断为大象流,从而实现大象流实时自适应检测分类。
1 算法原理
1.1 系统架构
针对数据中心网络静态阈值检测错误率高的问题,提出了一种基于DTL自适应阈值的大象流检测系统,利用DTL方法对流量进行检测,并对阈值进行实时动态自适应配置,不需要对OpenFlow协议进行额外的修改,控制平面几乎没有增加工作量,保证了方法的实用性,大象流检测系统架构如图1所示。
图1中给出本文大象流检测系统由流量统计分析模块和阈值计算配置模块组成,其中流量统计分析模块为了能够动态地满足数据中心流量特性要求,定期从交换机收集流量统计信息并在流量收集器中更新,分析器从流量收集器中收集合适的特征作为后续处理的训练数据。阈值计算配置模块首先将分析器发送的流量统计信息作为训练数据,根据流量特征建立合适的数学模型,然后利用加权优化方法对阈值进行预测,最后采用平滑机制将预测的检测阈值与已配置的检测阈值进行比较,判断是否在大象流分类的触发器中配置预测阈值。该系统的控制器不再收集流量统计信息来对大象流进行分类,而是通过分析器定期收集流量统计信息,使训练数据满足流量特性的要求,同时利用加权优化和平滑机制使预测阈值更加准确,进一步防止流表的波动,降低检测错误率。
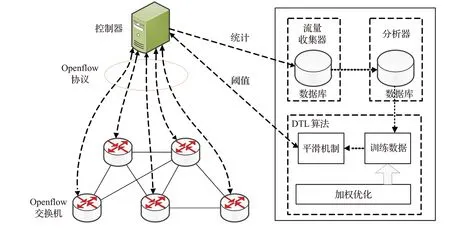
图1 自适应阈值大象流检测系统Fig.1 Adaptive threshold elephant flow detection system
1.2 DTL算法
首先定义p i为流量收集器每秒收集流量大小的流量统计数据(以字节为单位)。在Δt秒的时间内,将合适的流量特征q j定义为式(1):

如果在Δt秒内的流量大小占总流量的比例远大于θ,就将该流量视为大象流。因此,可用q j来预测触发器的阈值Th k。为了满足数据中心流量特性要求,预测阈值Th k定义如式(2)所示:

其中,α表示连接Th k和q j的协同参数,k表示当前时刻,N表示选择q j的移动窗口,ψ表示预测阈值函数。在式(2)中,关键是如何找到协同参数α,为了解决此问题,本文将[qk-1,q k-2,…,q k-N] 视为数据组[Xn,Yn],n=k-1,k-2,…,k-N,可假设在函数ψ中能够找到类似ψ(X,α)∈ψ的解来使得E2最小,从而得到Thk=ψ(X k,α),其中E2可表示为:

因此,可以将问题转化为用N个数据估计使得E2最小的最优化问题。采用最小二乘法对式(4)进行求解,如式(5)所示:

其中,M表示ψ(X,α)的阶数。为了提高预测阈值Th k的准确性,利用加权优化方法来优化机器学习过程。引入参数ω来表示不同时间的重要性,ωk-1>ωk-2>…>ωk-N,ω服从高斯分布。可将式(5)的最小化问题转化为式(9)形式:

为了降低机器学习方法的复杂度,采用正交三角(QR)分解法对其进行分解简化,QR分解定义如式(10)所示:


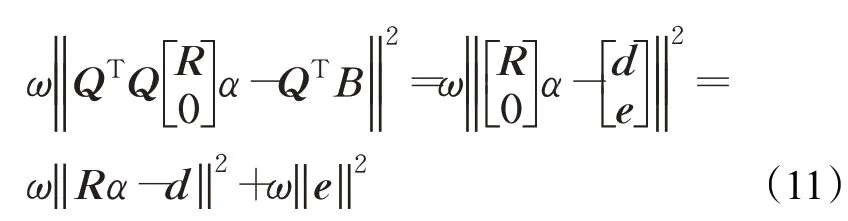

考虑到数据中心网络信息流转过程中流量特性要求,需要频繁地更新预测阈值来实时、自适应地识别大象流。当控制器配置一个新的阈值触发器时,将到达的流识别为大象流,并请求控制器计算非拥塞路径。在控制器完成调度之后,交换器会分配一个新的流表来对该大象流进行重新路由分配。下一时刻,如果最新的阈值将这个大象流识别为老鼠流,会立即删除新分配的流表。这种情况不仅会导致大量的虚报率、漏报率和误报率,而且会使流表产生剧烈抖动。
针对这一问题,本文引入流量检测平滑机制。当模块接收到新的预测阈值时,首先根据差分估计来决定是否替换之前的阈值。
定义振幅比β如式(13)所示:

设置ε为平滑参数,τ为平滑时间。如果β≤ε,则认为预测阈值将使流表产生抖动,以阻止控制器配置交换机。直到β>ε的时间为τ时,预测阈值才被配置到交换机中。
根据上述分析,本文提出的DTL算法具体流程如下所示:


其中Thpre表示当前配置的阈值,q表示式(1)中收集的训练值,Updata_threshold表示阈值更新主函数,Least_square_method表示本文简化的最小二乘函数,Smooth_mechanism表示平滑机制函数。
2 实验结果与分析
2.1 实验环境设置
为了有效检验本文大象流检测算法的可行性和有效性,实验采用OMnet++网络仿真软件,主要包括客户端、交换机和与SDN兼容的控制器。在性能模拟中生成的TCP流的持续时间和大小的依据是在2018年9月16日从CAIDA网站(https://www.caida.org/data)下载的第一级链路的2个路由器中收集的真实数据轨迹,使用分布式网络流量生成器生成流量,OMnet++中配置的数据中心网络拓扑为fat-tree结构。
实验运行平台的操作系统版本:Windows 2012 R2,CPU:Quad 3.47 GHz Intel Xeon®X5690,内存:16 GB。
2.2 系统性能分析
首先分析检测错误率与预测阈值函数阶数M之间的关系,如图2所示,错误率定义由式(14)所示:

其中,Thpredict表示预测阈值,Thstatistic表示统计的最优阈值。由图2可知,当阶数M≤2时,移动窗口数量对错误率影响较小,错误率小于20%。当阶数M>2时,移动窗口数量对错误率影响较大。当移动窗口数量N≤7时,错误率较高,随着N继续增加,错误率逐渐降低。当移动窗口数N=7时,与M=3和M=4相比,M=2的错误率分别小于4.71%和15.34%,因此本文选取的预测阈值函数阶数M=2。
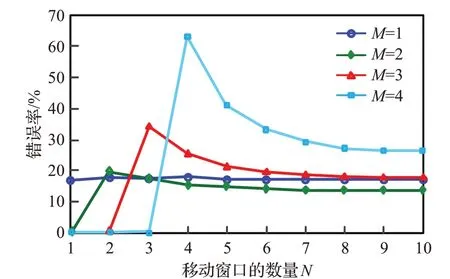
图2 基于不同M值的错误率Fig.2 Error rate based on different M values
图3 是在M=2时,不同移动窗口数量条件下加权优化的检测错误率情况。由图3可知,本文的加权优化算法可以有效降低检测错误率。随着移动窗口数量N增加,检测错误率逐渐降低,当N≥7时,检测错误率基本保持不变,相比N=2时最高检测错误率相差大约5.62%,从图2和3可以看出,设置M=2和N=7进行加权优化可以显著降低错误率。

图3 加权优化后的错误率Fig.3 Error rate after weighted optimization
图4 是不同计算方式下,四种阈值结果随流量变化情况。由图4可知,统计结果与训练结果相差不大,当分析周期T=100和T=260时,网络流量变化较快,与训练结果相比,固定阈值下满足流量特性要求的结果相差较多。考虑到如果控制器将每个训练结果均配置为触发器来识别大象流,可能会增加控制平面上的开销,同时频繁的阈值配置会导致流表抖动。而经过本文平滑处理之后的阈值不仅满足了网络中流量特征要求,而且也相应地保持了阈值的不变性,有效减少了流表抖动。

图4 平滑前后的动态阈值结果Fig.4 Dynamic threshold results before and after smoothing
图5 是不同阈值计算方式下,错误率随流量变化情况。由图5可知,训练结果的错误率最低。在T≤100时平滑结果和固定值的错误率相同,在T≥100时由于流量的变化,固定阈值造成的错误率迅速增加,而平滑结果的错误率仍然保持在较低水平,训练结果与平滑结果之间的差异较小。

图5 基于不同结果的错误率分析Fig.5 Error rate analysis based on different results
图6 是不同检测方法下,发送给控制器流转信息流的最大数量情况。由图6可知,由于OpenFlow协议需要每个信息流的状态,所以发送的信息流数量最高。当T=50时,流量变化较小,Mahout、Deveflow[15]和本文检测系统发送给控制器的流转信息流数量大约均为100,随着网络流量增加,Mahout和Deveflow两种方法的流转信息流数量迅速增加,而本文检测系统的流转信息流数量变化相对较少,几乎保持不变。

图6 流转信息流的最大值Fig.6 Maximum value of information flow
2.3 系统开销分析
针对数据中心网络的流量特性要求,本文采用动态配置预测阈值的机器学习方法,并通过差分平滑机制减少阈值更新次数,降低了流表抖动,但该方法是否会增加控制平面的工作量及检测时延决定了其可行性和实用性。
表1是三种方法在控制平面上更新触发器的配置信息数量。由表1可知,随着流量的快速变化,固定阈值方法更新的配置信息数量增长较为缓慢。在没有平滑机制的条件下,使用训练结果会导致配置信息数量迅速增长,此时控制平面的开销也会明显增加,而在本文的平滑机制作用下,配置信息数量下降明显,虽然略高于固定阈值的配置信息数量,但在可接受范围内。

表1 配置信息Table 1 Configuration information
图7是三种方法的大象流检测平均时间。其中检测时延包括检测器中的流分类时延、数据库中的数据匹配时延和系统中的训练学习时延。由图7可知,Mahout方法大约6 ms时延,主要是由于该检测方法是在终端主机上运行的。Deveflow方法采用随机抽样的方法,用大约25 ms的时间识别收集器中的大象流。本文流量检测系统可以在35 ms内检测到大象流,而大象流的平均持续时间约为几秒,本文流量检测系统的检测时延所占大象流总生存时间的比例较小。因此,本文提出的大象流检测系统具有实际可行性,并且检测的开销和时延相对较低。
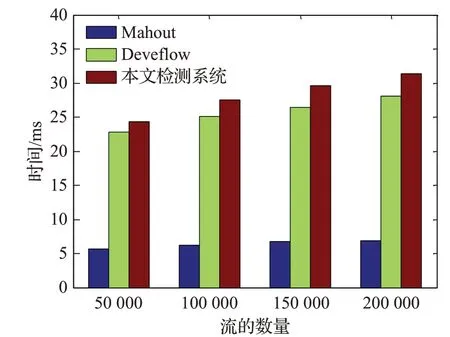
图7 大象流检测的平均时间Fig.7 Average time for elephant flow detection
3 结语
针对数据中心网络大象流的检测问题,提出一种基于动态流量学习自适应阈值的大象流检测系统,首先利用加权优化方法对训练数据进行阈值预测,然后通过差分估计的平滑机制减少阈值配置次数,降低了流表抖动。通过仿真实验表明:本系统能够有效捕获数据中心网络信息流转中快速变化的大象流,显著降低了控制平面开销,具有一定的可行性和有效性。
