基于多通道注意力机制的人脸替换鉴别
2022-02-24贾世杰
武 茜,贾世杰
(大连交通大学电气信息工程学院,辽宁大连 116028)
0 概述
近年来,基于深度学习的人脸替换技术取得了较快的发展[1]。人脸伪造主要体现在修改身份、转移表情、生成全新人脸这3 种情况,其中,修改身份即为人脸替换,DeepFake 是人脸替换中的主要方法。DeepFake 起源于2017 年Reddit 论坛中的一个匿名代码,是基于深度学习的人脸替换方法,其简单易用且没有违和感[2]。DeepFake 以自编码器(AutoEncoder,AE)为核心结构,利用编码器提取面部图像的潜在特征,然后使用解码器重建面部图像,从而将目标人物的面部图像替换到原视频中的人物上。为了在原图像和目标图像之间交换面部,需要2 个编码器-解码器对,每个编码器-解码器对都在人物图像集上进行训练,并且编码器的参数在2 个网络之间共享。目前,人脸替换鉴别方法主要分为两类。
第一类方法利用DeepFake 视频中前后帧的时间信息进行鉴别:GÜERA[3]研究发现DeepFake 视频前后相邻帧之间包含不一致的时序性内容,其提出利用CNN 和LSTM 检测假视频的方法;LI 等[4]研究发现DeepFake 假视频的人物眨眼频率低于真实视频,因此,将裁剪后的眼部区域序列分配到长期循环卷积网络(LRCN)[5]中进行动态预测;张怡暄等[6]研究发现DeepFake 视频中人脸区域的帧间差异明显大于真实视频,其利用视频相邻帧中人脸图像的差异特征进行预测;陈鹏等[7]利用全局时序特征和局部空间特征来发现伪造人脸视频;LI 等[8]利用DeepFake 视频相邻帧上的抖动来检测视频真伪,并解决了训练不能很好收敛的问题。上述方法容易被DeepFake 技术所借鉴并进行改进,因此,方法的时效性通常较弱[9]。
第二类方法提取DeepFake 的图像特征信息进行鉴别:YANG 等[10]提出一种鉴别方法,该方法利用由头部方向和位置组成的三维头部位姿之间的差异,将提取的特征输入SVM 分类器进行分类,但是实际情况中三维头部姿态获取效率低;AFCHAR[11]利用神经网络中层语义信息,使用具有少量层的神经网络来学习真假人脸图像内在特征的不一致性;LI 等[12]针对DeepFake 会留下特殊伪影的现象,利用深度学习网络来检测DeepFake 伪影;NGUYEN 等[13]利用胶囊网络(Capsule-Net)来检测DeepFake,并在FaceForensics++数据集[14]上进行评 估。文献[11-13]方法虽然在各自的数据集上具有有效性,但泛化能力弱,对于高质量的DeepFake 图像检测效果不佳。
BONETTINI 等[15]将简单的注意力机制引入卷积神经网络中,在FaceForensics++和DFDC 数据集上进行评估,结果表明,注意力机制对于鉴别DeepFake 具有有效性。因此,本文提出一种基于多通道注意力机制的人脸替换鉴别方法。对现有的注意力模型进行扩展,设计一种多通道注意力模块,根据矩阵相乘的思想融合全局和局部的注意力表示,在注意力模块连接主网络的方式上借鉴残差神经网络(ResNet)[16]的跳跃连接方法,以减少重要信息损失。在训练过程中,通过由多通道模块生成的注意力图来引导图像裁剪和去除,从而实现数据增强。
1 本文方法
1.1 网络结构
本文方法的整体网络框架如图1 所示。将图片I输入特征提取器,得到特征F,通过多通道注意力模块得到注意力图A,特征图F与每个通道的注意力图A按元素相乘得到特征矩阵T,然后通过全连接层得到概率P,从而区分输入图片是否为DeepFake 所生成。
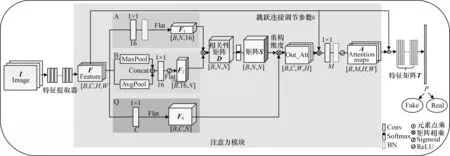
图1 整体网络框架Fig.1 Overall network framework
1.1.1 特征提取器
本文利用Xception[17]网络作为特征提取器。与常规网络卷积操作相比,Xception 的参数量和运算成本较低,且其可以更好地提升网络训练效率,在同等参数量以及大规模数据集上,效果优于Inception-v3。此外,在给定硬件资源的情况下,Xception 可以有效提高网络效率和性能。
1.1.2 多通道注意力模块
本文多通道注意力模块以矩阵相乘的方式融合全局和局部注意力表示,再以跳跃连接的方法与主网络连接。具体的注意力模块结构如图1 中的浅色阴影区域所示,整个注意力模块分为A、B、Q 这3 个分支:
1)A 分支为全局注意力表示。注意力表示方法将特征图通过16 个1×1 卷积核的卷积层,获得全局注意力表示,此时更加突出重要的权重,最终得到注意力特征图F1。
2)B 分支为局部注意力表示。该分支采用CBAM[18]空间注意力表示,空间特征图F2(F)的计算过程如下:
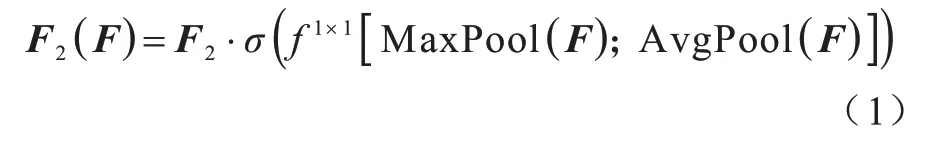
其中:F为输入的特征 图;MaxPool 和AvgPool 分别为最大和平均池化层;f1×1为1×1 大小的卷积核;σ为Sigmoid 激活函数。
对特征图分别进行基于通道的最大池化和平均池化,在通道上做拼接操作,再经过Sigmoid 激活函数得到特征图F2。因为最大和平均池化会造成一定的信息损失,所以这里将其称为局部注意力表示。
3)Q 分支得到经过2 048 个1×1 卷积核卷积后的特征图F0,其对Feature 多增加一层卷积映射,使网络学到更多的参数。将Si,j权重应用到F0上,即每一个元素点都与整个Feature 相关,相关性来自于D矩阵。Q 分支的输出O计算公式如下:

其中:F0(xi)为Q 分支的卷积操作表示。
如图2 所示,将F0[C×N]矩阵与S[N×N]矩阵的转置相乘,得到输出O[C×N]。输出O中的第i行第j列的元素表示被矩阵S对应第j列元素加权之后的Feature 在第i个通道的值。然后对输出O进行维度重构,使输出O恢复为C×W×H尺寸。为了减少训练时间,在输出后再加一个简单的卷积层,最终得到A。
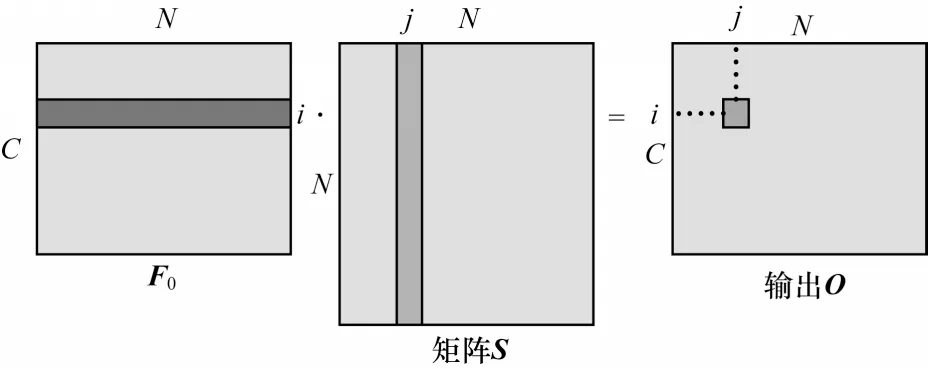
图2 输出O 的计算过程示意图Fig.2 Schematic diagram of calculation process of output O
本文方法使用矩阵相乘的方式来结合全局和局部注意力表示。为了满足矩阵相乘的条件,将F1和F2的尺寸从2 个维度(H×W维)压缩为1 个维度(N维),使尺寸从[B×16×H×W]分别变为[B×N×16]和[B×16×N],其中,N=H×W,H和W分别为Feature的长和宽。F1和F2矩阵相乘后得到D矩阵,大小为[B,N,N],其可以看作一个相关性矩阵,即F上各个元素点之间的相关性表示。通过上述过程,既突出了重要权重又避免了重要信息的损失。矩阵D的计算公式如下:

其中:f1和f2分别为由分支A 和B 进行的卷积操作;Di,j可以理解为矩阵D中第i行第j列的元素值,表示F2中第j个元素对F1中第i个元素的影响。
为了防止梯度爆炸问题,将D矩阵逐行通过Softmax 函数得到S矩阵。矩阵S的计算公式如下:

其中:Si,j各行元素之和为1;S矩阵中第i行元素代表Feature 中所有位置的元素对第i个元素的影响,这种影响即为权重。
在连接主网络的方式上,本文借鉴残差神经网络的跳跃连接,引入调节参数ε,使输出O的权重需要通过反向传播来更新,具体计算公式如下:

在初始阶段,ε为0,输出y直接返回输入的F,随着训练的进行,输出y逐渐学习到要将经过注意力机制的F加在原始F上,从而强调了需要施加注意力的部分F。
1.1.3 输出层
将特征图F与每个通道的注意力图按元素相乘,具体计算公式如下:
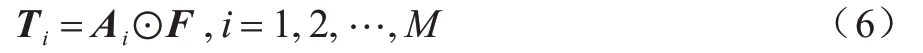
其中:Ai为注意力图;M为注意力图的个数。
相乘之后以拼接的方式得到特征矩阵T,T中的每一行代表一张图像的所有特征,然后将T特征矩阵输入线性分类层进行二分类,最终得到概率P从而判断输入图像的真假。
1.2 损失函数设置
本文方法的损失函数表达式如下:

其中:Le为交叉熵损失;Lc为中心损失。
Le的计算方式如下:
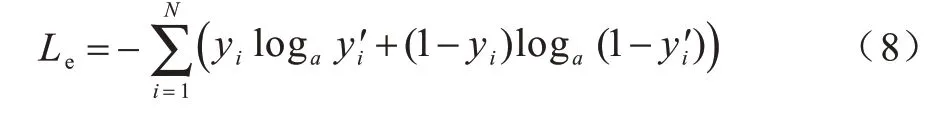
其中:yi为真实标签值为预测标签值。
Lc借鉴了中心损失[19]的原理,将原来中心损失的类中心替换成不同特征的特征中心,使同一类别中同一部分的特征尽可能地接近。Lc的计算方式如下:


其中:δ在实验中初始值取0.05。
1.3 训练过程
本文网络的训练过程使用迁移学习中的微调(Fine-tuning)技术。使用Xception 网络在ImageNet数据集上的预训练模型,去掉原来的全连接层,添加新的模块和全连接层,在原有参数的基础上训练整个网络,从而提高实验效率。同时,本文利用细粒度分类WSDAN 网络[20]中的训练方式,通过每一个轮次训练好的注意力图来引导一个轮次图像的裁剪和去除,然后进入网络进行训练,从而实现数据增强。具体过程如下:
输入图像经过特征提取和注意力网络后输出A,尺寸为B×M×W×H,选取M张图像中权重较高的2 张图像分别用作图像裁剪和图像去除,经过归一化处理得到A'1和A'2。归一化计算公式为:
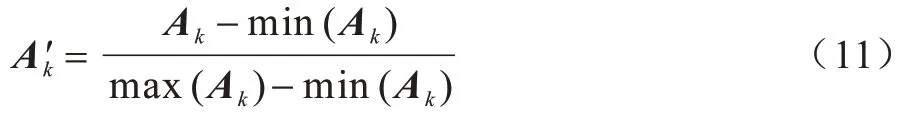
当k=1 时,A1用作裁剪得到mask,计算公式如下:
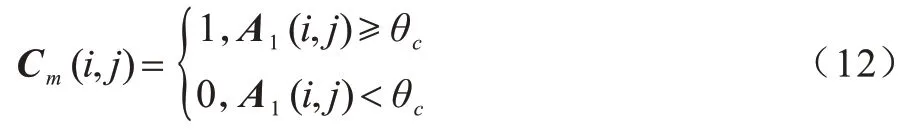
其中:Cm为得到的mask;θc为设定的裁剪阈值。Cm为不规则形状的mask,取能包含该mask 的最小的矩形边界(bounding box),将该矩形边界坐标覆盖至原图,并将该边界区域放大至原图大小,即放大已经受到关注的区域,就可得到裁剪图片以继续参与训练。
当k=2 时,A2用作去除得到mask,计算公式如下:
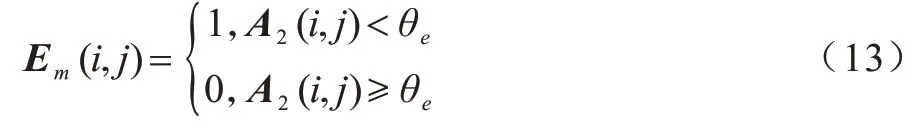
其中:Em为得到的mask;θe为设定的去除阈值。Em与原图进行对应元素相乘,得到去除后的图片,使得已经受到关注的区域被消除,保留没有受到关注的区域,且去除后的图片继续参与训练。
2 实验结果与分析
2.1 实验设置
2.1.1 环境设置
本文实验在单机PC端训练完成,实验环境设置如下:处理器为Intel®CoreTMi7-6700HQ CPU@2.60 GHz,显卡为NVIDIA GeForce GTX 950 M 4 G,操作平台为Windows 10,软件平台为Python3.6,主要依赖库为CUDA 9.0、cuDNN 7.6。
2.1.2 数据集构成
本文实验只针对由自编码器生成的换脸视频(以下称为DeepFake)。目前关于鉴别DeepFake 的数据集质量不统一,FaceForensics++(以下简写为FF++)的DeepFake 数据集中有些视频生成效果不佳,人眼就能识别出DeepFake 视频,因此,本文对FF++(c40)中DeepFake 数据集进行重新人工筛选,将有明显生成痕迹的假视频剔除,并在此基础上扩增数据集,分别由Celeb-DF 数据集[21]、DFD(DeepFake-Detection)数据集[14]、网络收集构成。为了降低原始数据的复杂度,提升模型训练稳定性,本文对原视频做预处理,利用MTCNN[22]进行人脸检测,把裁剪出的人脸作为输入图片,最终数据集中训练集总共有17 200 张图片,真假图片各占一半,为8 600 张,测试集总共有4 300 张,真假图片各占一半,都为2 150 张。具体的训练集、测试集构成如表1所示。

表1 数据集信息Table 1 Datasets information
2.1.3 实验参数设置
模型基于Pytorch 1.1.0 深度学习框架搭建网络架构,训练方法为随机梯度下降法(SGD),初始学习率设为0.001,动量设置为0.95,权重衰减为0.000 01,batch size 为8,输入图像大小为300×300,总共进行30 轮的训练,θc∈(0.4,0.6),θe∈(0.4,0.7)。在训练过程中,采用微调的训练方式,提取Xception 除全连接层外的最后一层,即得到的特征图数量为2 048。
2.1.4 评估标准
本文实验采用的评估标准为精度(Accuracy),其定义如下:
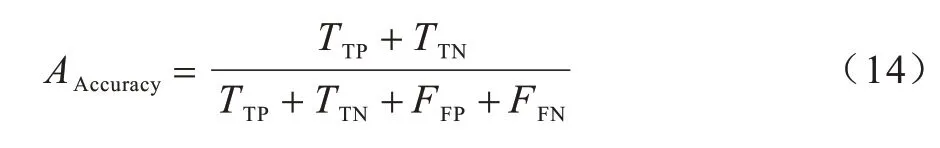
其中:TTP为真阳性;TTN为真阴性;FFP为假阳性;FFN为假阴性。本文实验中将人脸真图定义为正类,人脸假图定义为负类。
2.2 对比实验结果
本文方法和其他鉴别方法在测试集上的测试精度对比如表2 所示。从表2 可以看出,与其他基于深度学习的检测方法相比,本文方法测试精度最高,测试精度相 比Xception[14]方法提高了2.63 个百分点,相比B4Att[15]方法提高了1.35 个百分点,充分验证了本文方法的有效性。

表2 6 种方法的测试精度对比Table 2 Comparison of test accuracy of six methods %
在FF++(c40)、Celeb-DF、DFD[23]数据集上分别进行测试对比,结果如表3 所示。从表3 可以看出:各方法在Celeb-DF 和DFD 数据集上的测试精度均低于FF++数据集;本文方法在Celeb-DF 和DFD 数据集上的测试精度能达到97.85%和92.17%,且在FF++数据集上,本文方法的测试精度相比B4Att[15]提高了0.45 个百分点,在挑战性相对较高的Celeb-DF 和DFD 数据集上,测试精度分别提高4.68 和3.59 个百分点,本文方法整体性能优于其他对比方法,泛化能力更强;S-MIL-T 是基于视频的检测方法,相比其余基于图片的检测方法,其只在Celeb-DF数据集上表现突出。
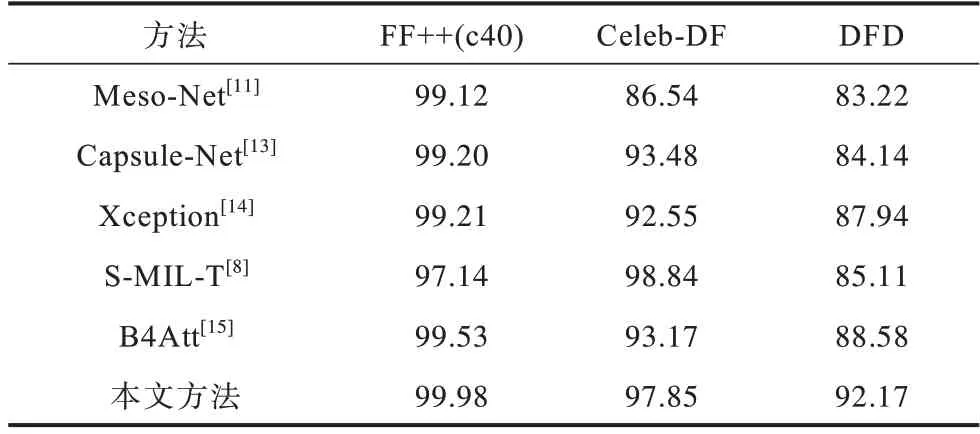
表3 在FF++、Celeb-DF、DFD 数据集上的测试精度对比Table 3 Comparison of test accuracy on FF++,Celeb-DF and DFD datasets %
本文还在具有代表性的测试图例上进行实验对比,结果如表4 所示,其中,第一、第二幅图为FF++数据集,第三、第四、第五幅图为Celeb-DF 数据集,最后一幅图为DFD 数据集,表格内“√”代表该网络能正确判断该图为DeepFake 图片,“×”代表网络将图片误判为真图。表4 中给出的例子实际均为DeepFake图片,从第一幅图片的测试结果可以看出,生成效果不佳的DeepFake 图片有明显的伪影边界,表中方法均能鉴别出该图为DeepFake 图片,但随着DeepFake图片质量的提升,其他方法会出现误判的情况,而本文方法仍然能够正确地鉴别出该图为DeepFake图片。
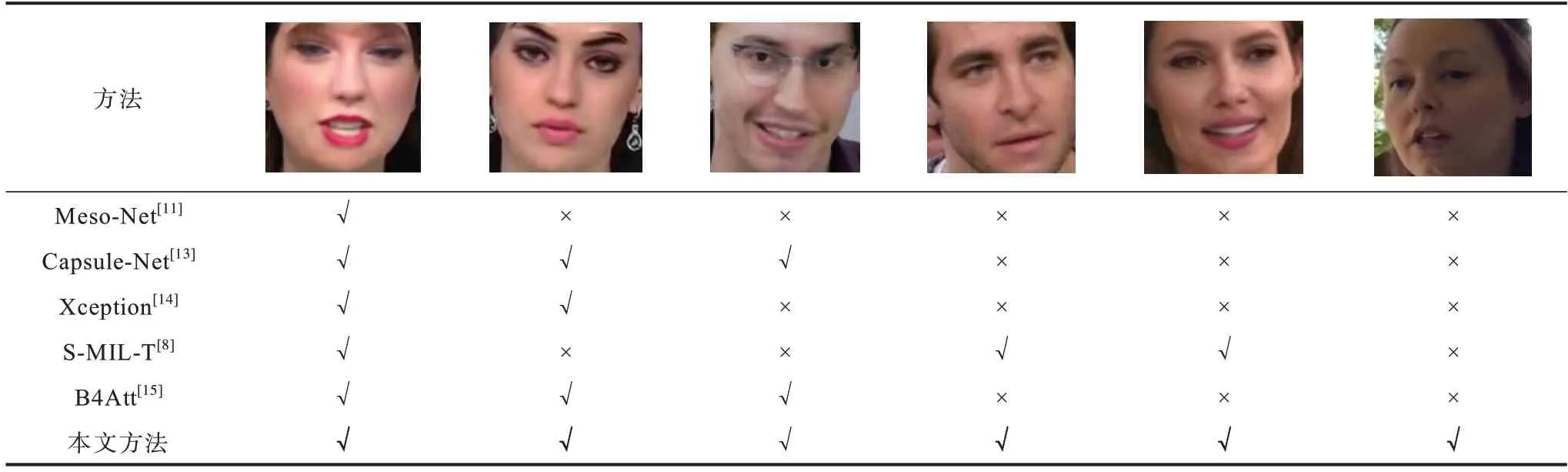
表4 DeepFake 图片的鉴别结果Table 4 Identification results of DeepFake pictures
2.3 消融实验结果
对本文所设计的模型进行消融实验,测试精度对比情况如表5 所示。其中:Base model 为直接使用Xception 网络进行分类鉴别的模型;+Attention 为在Base model 上添加本文注意力机制的模型;eraser mask、crop mask 分别为注意力引导的图像去除、裁剪的模型;最后4 行All 代表本文模型在不同的预训练模型(ResNet101[16]、VGG19[24]、Inception-v3[25]、Xception)上进行测试。从表5 可以得出:
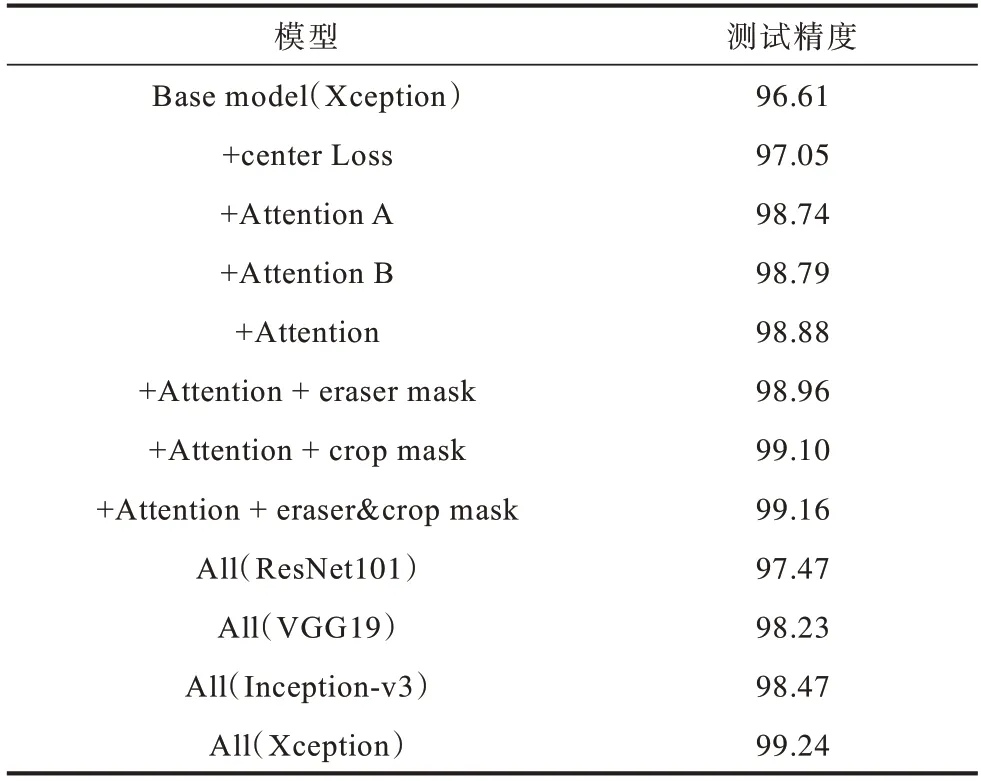
表5 消融实验结果Table 5 Results of ablation experiment %
1)在Xception 网络的基础上加入本文设计的Attention 模块,测试精度有2.27 个百分点的提升;在基础模型上添加中心损失,测试精度也有0.44 个百分点的提升;添加A、B 不同分支的注意力表示,对基础模型的测试精度分别有2.13 和2.18 个百分点的提升,即局部和全局注意力表示均能发挥一定作用,将它们相结合后精度能够进一步提升。
2)在多通道注意力模块的基础上引入注意力引导的图像裁剪和去除,测试精度能够提升0.28 个百分点;裁剪的作用(提升0.22 个百分点)比去除的作用(提升0.08 个百分点)更明显,即对于鉴别DeepFake,裁剪的图像有利于网络提取到更细节的特征。
3)在不同的特征提取网络的基础上,本文设计的多通道注意力模块的测试精度都能达到97%以上,其中Xception 网络效果最好。
3 结束语
本文针对DeepFake 图片鉴别问题,建立一种基于多通道注意力模块的鉴别网络模型。将注意力模块添加到现有的预训练模型中,融合全局和局部注意力表示以避免重要信息损失。在训练过程中使用注意力引导的图像裁剪和去除的训练方式,从而起到数据增强的作用。在FF++、Celeb-DF 和DFD 数据集上的实验结果表明,该模型泛化能力较强,测试精度优于B4Att、S-MIL-T 等方法。但是,本文模型难以直接对输入视频进行鉴别,也未利用视频中各帧之间的相关性信息,对以上问题进行研究以提升模型的检测性能将是下一步的研究方向。
