注意力机制下双模态交互融合的目标跟踪网络
2022-02-23姚云翔
姚云翔, 陈 莹
(江南大学物联网工程学院, 江苏 无锡 214122)
0 引 言
目标跟踪[1]是计算机视觉领域中一项具有挑战性的任务,由于其在工业机器人、智能视觉导航[2]、智能交通[3]、战场侦察[4]等方面的广泛应用而受到越来越多的关注。尽管近年来目标跟踪领域取得很多突破[5-7],但是其仍然面临许多挑战,例如雨天、低光照度、遮挡等情况下的目标跟踪。这是由于传统目标跟踪的输入是可见光图像,而其在上述情况下能提供的信息十分有限。
为解决这一问题,红外与可见光(RGB -Themeral, RGB -T)跟踪这一目标跟踪的分支应运而生。RGB -T跟踪运用可见光(RGB)信息和红外(T)信息互补性优势以获得优秀跟踪性能,其关键在于如何有效的融合利用双模态的互补信息。
早期RGB-T跟踪算法[8-9]直接将双模态的特征级联得到融合特征,未考虑不同模态对任务的影响,易丢失对任务有效的特征信息,引入单个模态的冗余信息。目前,RGB-T跟踪算法主要关注于两个方向。一是学习各个模态的鲁棒特征表示,例如Li等人[10]提出了一种以局部图像块作为节点的协作图来表示目标,学习了基于图块的加权RGB-T特征来融合不同模态。Li等人[11]提出了一种基于图的跨模态排序算法,引入了一种软跨模态一致性,以实现模态之间一致性排序。但这类方法依赖于手工设计的特征,而手工设计的特征难以应对目标的重大形变。另一种则是采用深度网络提取各模态特征,之后融合多模态特征。最早方法只是使用两支网络提取各模态特征之后简单级联融合,例如Zhang等人[12]提出了一种基于MDNet[13]的融合思路,用两个平行卷积网络提取双模态特征,之后级联双模态特征,然后送入特定域层进行跟踪。目前大部分方法在提取双模态特征后通过网络产生反应各个模态置信度的权重来自适应融合多模态特征。例如,Li等人[14]采用重建残差来规范学习模态权重学习,Lan等人[15]用max-margin学习框架学习不同模态的权重和不同模态的分类,Zhu等人[16]用自适应融合模块,根据红外特征和可见光特征自适应学习两个模态的权重,之后根据权重融合两个模态信息,但如果模态置信度成绩不能有效反映模态可靠性,将导致方法失败。
针对上述问题,本文提出了一个的空间通道注意力下双模态交互融合跟踪网络。首先级联各层特征得到双模态特征,然后对双模态特征做空间通道自注意力,并通过交互注意力图的方式进行信息融合,级联后得到融合特征,最后将融合特征送入全连接跟踪模块实现跟踪。在目前最大的RGB-T跟踪数据集RGBT234[17]的实验结果证明,本文提出的双模态交互融合网络能有效获取鲁棒的双模态特征,跟踪性能优于当前先进算法。
1 RGB-T目标跟踪
1.1 问题分析
通过深度网络提取特征,计算两个模态特征的权重然后进行加权后级联融合的方法相比直接级联方法和传统手工特征方法相比有很大提升,但仍有一个问题,这类方法在计算模态权重时忽略了特征通道及其空间位置的差异性,导致学习到的权重无法准确反应模态的可靠性,进而严重影响跟踪精度。如图1所示,对于GTOT数据集中的BlueCar序列,RGB模态的质量明显比红外模态好,但是文献[14]中的模型计算出的RGB,红外模态重构残差分别为37.6、32.67,给予了红外模态更高权重。
1.2 空间通道注意力下双模态交互融合网络
本文提出的交互融合网络框架如图2所示,由3个模块组成,分别为分层特征提取模块、空间通道注意力下双模态交互融合模块和全连接跟踪模块。
1.2.1 分层特征提取网络
本文baseline为MDNet[13],选择视觉几何组网络模型(visual geometry group netwerk model,VGG -M)[18]网络作为支柱,使用在ImageNet上预训练的VGG -M作为预训练模型。现存网络[19]大多对两种模态采用两个不同的模型来分别提取模态特征,但这种方法忽略了两个模态之间的共享特征,因此会带入大量冗余特征,降低跟踪精度。所以本文采用参数共享的VGG -M网络作为支柱来提取2种模态特征,以减少冗余特征,同时减少参数量。
浅层信息拥有丰富的细节、纹理等信息,深层信息拥有丰富的语义信息[20],都有利于跟踪任务,因此提取分层特征。为减少最大池化(MaxPooling)的信息损失,提高感受野,本文将conv2中的MaxPooling层删去,同时将conv3改为r=3的空洞卷积[21](r为空洞率)。RGB-T分支的conv1、conv2、conv3共享参数,以减少双模态中冗余特征,减少模型参数,此外每个分层输出的特征都使用1个不共享参数的1×1卷积进行降维,使RGB-T不同模态特征更有独特性。为统一conv1、conv2、conv3分层特征的分辨率,用MaxPooling将前两层特征的分辨率降至第3层特征的分辨率。为了保证输出和MDNet相同采用空间对称感兴趣区域[22]将4×4分辨率的特征变为3×3分辨率。
1.2.2 空间通道交互注意力融合模块
针对第1.1节提出的问题,受文献[23]启发,在双流跟踪网络中对双流融合机制进行设计,提出空间通道注意力下双模态交互融合模块。如图3所示,该模块由空间通道自注意力模块和跨模态交互注意力模块两部分组成,其中空间通道自注意力模块包含空间自注意力和通道自注意力两部分。
特征不同通道对于任务的重要性不同,如果平等对待各个通道的信息,势必减弱通道的表现能力,不利于有效跟踪,因此通过通道自注意力对不同通道施加不同关注度,以提高特征有效性。同样,特征不同空间位置对于任务的重要性也不同,且受感受野的限制,图3上的每个空间位置计算出的特征都只能够捕获其感受野内的局部的片面的信息,无法从图上获取一个全局特征。因此,论文设计空间自注意力对不同空间位置施加不同关注度,其关注度由全局特征计算而来,以提高特征对于跟踪任务的有效性。此外,红外与可见光信息有着很强的互补性,为了充分挖掘双模态之间的互补性完成单模态难以应对的挑战情况下的跟踪,本文设计跨模态交互注意力模块加强双模态特征的互补性同时交互双模态特征信息,使融合特征更为鲁棒以更好完成困难情况下的跟踪任务。
(1) 自注意力部分
RGB-T特征通过空间和通道自注意力部分,分别计算得到各自的空间注意力特征和通道自注意力特征。与图像分割[23]任务中设计空间自注意力时注重加强特征空间强特征不同,本文所设计的空间自注意机制更关注弱特征,以应对跟踪中的低光照、运动模糊等挑战。
① 空间自注意力部分

(1)
(2)
(3)
(4)

② 通道自注意力部分

(5)

(6)
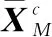
(2) 交互注意力部分
交互注意力模块本质上就是让RGB-T特征空间位置上更关注另一模态空间位置弱特征,以增强红外与可见光信息的信息互补性优势,从而让两个模态的信息能够得到交互以获得更优秀的鲁棒特征。
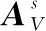
(7)
(8)
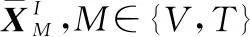
(9)
1.2.3 全连接跟踪模块
全连接跟踪模块采用和MDNet的多域学习方法以获得独立于域(跟踪或训练时每个视频段视为一个特定域)的特征表示来进行目标跟踪。该模块由3层全连接层组成,其中最后一层FC6包含K个分支,每一支对应一个特定域,最后一层是Softmax用以执行二分类来区分每个特定域中的前景(目标对象)和后景。在网络训练过程中,通过加入实例嵌入损失使网络能够学习更有判别力的目标表征。
1.3 损失函数
在训练过程中,对每个域的二分类采用二元交叉熵损失,损失计算公式为
(10)
式中:N是样本数量;pi是通过本文网络产生的第i个样本的预测值;yi是相关样本的真实标签,如果正样本,yi是1,如果是负样本,则yi是0。
除此之外,还加入了一个实例嵌入损失函数来学习具有相似语义的目标对象的更具有判别嵌入。其将每一个域当做一个分类并且只对正样本计算这个损失。通过迫使不同序列中的目标对象尽可能的远离彼此来使目标对象的嵌入更具判别性。可用描述如下:
(11)
式中:D是域的数量;yi,d是第i个样本在第d个域上的真值标签;pi,d是在第d个域上的第i个样本通过本文网络得到的预测值。
对于本文网络优化器的最终损失函数根据下式得到
L=Lcls+αLins
(12)
式中:α是控制两个损失函数平衡的超参数,本文按照文献[24]选取0.1作为α值。
2 实验结果与分析
为了验证本文提出的网络的有效性,本文在RGBT234[17]数据集和GTOT[14]数据集上进行了测试,将结果与基线网络MDNet+RGB-T[13]及其他优秀算法进行比较。
2.1 实验配置
本文提出的算法是在深度学习框架Pytorch下完成的, 实验所使用环境Ubuntu14.0, CUDA8.0.61, python3.6,硬件配置为TITAN XP。网络的初始学习率fc层初始学习率设置为0.001,其余层设置为0.000 1,冲量为0.9,权重衰减为0.000 5。
2.1.1 训练细节
整个网络采用端到端的方式训练。首先用VGG-M网络的预训练参数对conv1、conv2、conv3这3层的参数进行初始化。然后用SDG优化器训练整个网络,其中每个域分别处理。训练的具体参数细节如下,在每次迭代中最小步长由每个视频段中随机选取的8帧组成(全选完前不会重复)。然后这8帧图片中选取32正样本,96负样本。其中正样本指和真实边界框交并比超过0.7的样本,负样本指和真实边界框交并比低于0.5的样本。本文用RGBT234数据集进行训练,然后在GTOT数据集上进行测试,反之亦然。
2.1.2 跟踪设置
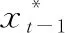
(13)
式中:N是候选区数量,为了兼顾精度和速度,N取256。和MDNet一样,本文采用边界框回归[25]来改善跟踪过程中目标尺度变化问题,提高定位精度(仅在第一帧中进行训练)。
2.2 数据集与评价指标
2.2.1 数据集
本实验使用的公开数据集是目前红外与可见光跟踪领域最大的两个数据集,GTOT数据集和 RGBT234数据集。
GTOT数据集包含50个配对的红外与可见光视频段,共有约15 000张图片。每帧图片都有真实边界框标注。RGBT234数据集是一个大规模数据集,该数据集包含有234个配对的红外与可见光视频段,共有约234 000张图片,该数据集标注有12个挑战属性。
2.2.2 评价指标
本文采用两种广为使用的评价指标,精度(precision,PR)和成功率(success rate,SR),来评价RGB-T跟踪算法的性能。PR是预测边界框中心与真实边界框中心的距离小于阈值的图片占总图片数的百分比。阈值对于GTOT数据集和RGBT234数据集分别为5像素和20像素(因为GTOT数据集的目标总体而言较小)。SR是预测边界框和真实边界框的交并比大于阈值的图片占总图片数的百分比。采用SR曲线下面积作为代表性的SR。PR和SR指标都是越高越好。
2.3 在GTOT数据集和RGBT234数据集上结果
为了证明本文所提出方法的有效性,在GTOT数据集和RGBT234数据集对算法进行了评估。本文方法的结果和其余8种方法(MDNet[13]+RGB-T,RT-MDNet[24]+RGB-T,CSR-DCF[26]+RGB-T,KCF[27]+RGB-T,DAPNet[28],CMRT[11],SiamDW[29]+RGB-T和M5L[30])比较的结果在图6中展示。其中文献[11,13,24,28,30]是基于RGB-T的跟踪算法,其余算法则是基于RGB的。通过图6可以看到在GTOT数据集和RGBT234数据集上本文算法的PR/SR分别比基线MDNet高了7.8%/7.8%和5.3%/4.2%,证明了本文提出的模块有显著效果。所提方法在两个数据集上与M5L、DAPNet等5个SOTA算法比较,可以看到,和DAPNet相比,所提算法在RGBT234数据集上PR高0.9%,GTOT数据集上SR低0.4%,PR高0.7%,和M5L相比,所提算法在RGBT234数据集上PR和SR分别比M5L高了0.5%和1.6%,GTOT数据集上本文算法PR低1.6%,SR高0.5%,同时PR, SR在两个数据集上远超其余算法。本文网络增强空间弱特征以提高例如遮挡,运动模糊等挑战情况下跟踪性能,但模糊了特征空间位置差异,导致其在目标大多较小且挑战难度较低的GTOT数据集上PR较低。
在RGBT234数据集上有12种挑战属性,包括背景(BC)、相机位移(CM)、形变(DEF)、快速移动(FM)、严重遮挡(HO)、低光照(LI)、低分辨率(LR)、运动模糊(MB)、无遮挡(NO)、部分遮挡(PO)、尺度变化(SV)、热交叉(TC)。其他顶尖算法(包括RT-MDNet+RGB-T、MDNet+RGB-T、CSC-DCF+RGB-T、MEEM+RGB-T、DAPNet、M5L、CFNet+RGB-T)的比较结果列于表1中,其中每种属性PR和SR评价的最优结果红色加粗,次优结果蓝色加粗。从表1中可以看出,所提算法的全部表现都好于基线MDNet+RGB-T以及大部分SOTA网络,LR、 MB、FM表现超过所有算法,证明通过高低层特征聚集,空间通道注意力下双模态交互融合,同时获得丰富的语义和细节信息,可以有效应对低分辨率,运动模糊,快速位移等导致的目标模糊情况。此外本文算法在HO,PO上PR成绩最好,SR成绩分别只比第一低了0.1%和0.2%, LI、SV上SR成绩最好,PR成绩居于第二,说明所提网络可以通过通道时空交互融合来获得一个鲁棒的特征。但同时,由于空间自注意力更关注全局而非细节,导致如果在NO下,即无任何遮挡等挑战属性,目标特点清晰的情况下,使得特征变得模糊导致定位不够准确。总体而言,所提方法中的SR最优率为各种方法中的最高,所提方法的PR最优率与M5L持平,同样为最高。
图7列出了所提算法与其他3种算法在4个视频段的比较,可以明显看出所提算法在面对低光照,遮挡等困难条件下时表现优异。在Bus6序列中当大车遮挡小车后,除了所提算法以外其他3种算法都发生了跟踪偏移,只有所提算法红框仍然跟踪到了小车。Car41序列中由于光照变化,除了所提算法外其他算法都难以准确框出目标。Diamond序列中当树木遮挡,人重叠发生后之后本文算法能够继续跟踪到目标。Elecbike序列中光照不足且中途目标被车辆完全遮挡,两种算法无法在低光照情况下实现有效目标跟踪,另一种算法在目标被完全遮挡无法实现跟踪,所提算法在低光照和完全遮挡情况下仍然实现了有效跟踪。

表1 多种算法在RGBT234不同挑战属性下的PR/SR结果比较
2.4 消融实验
为了公平地比较本文提出网络的主要部分,本文在GTOT数据集上进行了消融实验。网络变体如下:
(1) Our-AGG:仅使用空间通道自注意力下跨模态融合模块,移除分层特征提取模块。
(2) Our-SCIF:仅使用分层特征提取模块,移除空间通道自注意力下跨模态融合模块。
(3) Our-AGGS:只有第3层卷积共享参数,前两层卷积不共享参数。
(4) Our-SC:移除了在空间通道注意力下跨模态融合模块中的交互通道注意力部分。
表2为GTOT数据集上消融实验结果,图8为GTOT数据集上消融实验PR/SR结果。Our-AGG和Our-SCIF的结果都高出基线网络MDNet+RGB-T,表明两个模块的有效性。Our-SC,Our-AGGS结果低于Our表明了交互空间注意力的融合方式的有效性,以及前三层共享参数减少冗余思路的有效性。

表2 GTOT数据集上消融实验结果
3 结 论
本文目标跟踪能够适应不同天气,有效应对诸如目标遮挡、低光照等各种挑战的要求,提出了一个基于RGB-T双模态的空间通道注意力下双模态交互融合网络。实验结果证明,在目前最大的RGB-T跟踪数据集上所提算法相较于其他算法获得了更高的PR/SR率,能为目标跟踪提供RGB-T互补的模态信息,以应对目标跟踪全天候及困难情况下的跟踪。在未来考虑通过改进网络架构来解决当前网络对细节捕捉不足导致某些情况下(尤其是无任何挑战情况下)跟踪偏移的问题。
