基于无锚框的红外多类别多目标实时跟踪网络
2022-02-23宋子壮杨嘉伟张东方王诗强
宋子壮, 杨嘉伟, 张东方, 王诗强, 张 硕
(北京遥感设备研究所, 北京 100854)
0 引 言
近年来,随着海洋工程技术的发展,海上目标类型日趋多样化,如货船、快艇、无人机等。日趋复杂的海上航行环境使得航行安全变得更加重要,相关海上目标的检测、识别与跟踪逐渐成为热点问题。为了有效应对各种可能的突发情况,利用智能化手段对相关可疑目标进行预先检测与跟踪显得尤为重要,而将红外探测手段用于海上目标跟踪,相较于雷达或可见光拥有抗海杂波能力强与全天候探测的优势。
传统跟踪方法通过提取目标表观特征对目标状态进行建模,然后利用模板进行后续的匹配跟踪过程,如粒子滤波、均值漂移、卡尔曼滤波,但存在计算量大、实时性差、模板更新不及时与对目标尺寸或速度变化鲁棒性差等问题。相关滤波跟踪通过提取目标特征模板并与下一帧进行相关匹配,成功跟踪后利用匹配上的图像进行模板的更新,并进行后续的跟踪,但匹配模板存在着漂移的问题,且实时性不高。随着深度卷积神经网络的不断发展,其强大的深层特征提取能力逐渐代替了传统手工设计特征提取的方法,且GPU加速了相关运算的处理过程并被应用到目标跟踪领域当中。孪生网络是其中的典型代表,通过端到端的训练使得网络学习到目标模板与待测图像块之间的相似程度,使得提取特征更加鲁棒的同时提升跟踪速度,但其始终需要特定的目标模板进行相关跟踪过程。此外,上述方法多用于单目标跟踪过程,在多目标跟踪中应用时,算法往往受到实时性的制约。
检测后跟踪是目前主流的深度学习多目标跟踪方法,现有方法通常由检测模型与识别模型组成。检测模型用于对每一帧中的多个目标进行检测定位,利用定位将识别模型中的特征向量抽取并进行帧间匹配,从而达到多目标跟踪。SORT使用卡尔曼滤波预测下一帧目标定位框的状态,并采用交并比(intersection over union,IoU)匹配的方式对当前帧与下一帧的目标利用匈牙利算法进行关联,从而进行跟踪。DeepSORT在SORT的基础上利用深度学习网络获取的表观特征进行级联匹配,同时加入了轨迹确认的过程确保跟踪的鲁棒性。Wang等将DeepSORT中的检测模型与识别模型进行了整合(joint learning of detection and embedding, JDE),极大提高整体架构运行速度,且进一步提升了跟踪精度。FairMOT注意到JDE网络基于锚框检测框架中提取的特征与锚框存在错位的问题,采用了无锚框的CenterNet网络重新设计了跟踪网络,JDE网络进一步提升了跟踪整体精度与实时性。李震霄等在DeepSORT的基础上使用更轻量级的网络模型,同时利用长短期记忆人工神经网络解决卡尔曼滤波在非线性系统中产生的预测误差。赵朵朵等利用改进后的轻量级DeepSORT进行人流统计,能够适应复杂场景并具有一定实时性。张宏鸣等设计了长短距离语义增强模块并应用于DeepSORT当中,同时使用轻量级骨干网络,进一步提升跟踪的性能。
现有深度学习检测后跟踪方法多在单类别多目标跟踪数据集中进行,如行人跟踪数据集,少有研究进行多类别多目标跟踪,且现有方法仅在算力强劲的PC端部署时拥有较好的实时性,而部署在边缘设备上时无法满足实时性要求。在相机无规则运动时,现有卡尔曼滤波预测与IoU匹配无法有效关联目标的帧间运动,跟踪表现不佳。此外,在优化识别模型的目标特征向量方面依然有很大的研究空间。为解决上述问题,本文提出了一种基于无锚框的红外多类别多目标实时跟踪网络,在确保跟踪精度的同时,极大提升了网络在边缘设备部署的实时性。
1 本文方法
1.1 基于RepVGG的无锚框跟踪网络设计
1.1.1 骨干网络
基于RepVGG的无锚框跟踪网络如图1所示。其中,骨干网络选用RepVGG-A0,其借鉴ResNet的残差结构,在传统VGG模型中引入多分支结构,从而设计了训练模式(train)的网络模型,如图2所示。相较传统VGG模型,能够显著提升精度。同时,多分支融合技术将卷积层与批归一化层进行融合,将多路不同大小的卷积核等价变形为多路3×3卷积核,并最终融合为单路3×3卷积核,设计了部署模式(deploy)的网络模型。该模型仅含有3×3卷积与ReLU激活层,因没有残差旁路的引入而拥有更小的显存消耗,且3×3卷积相较其他大小的卷积计算密度更高,更加有效。类VGG的模型结构使得网络易于拓展到其他任务中。通道系数控制着最后一层输出特征图通道数大小,通道系数控制其余每一层的通道数大小。为了更好地权衡骨干网络的参数量、计算速度与精度,同时借鉴SSD目标检测网络通道数的设计思路,本文将通道数系数,均调整为1。

图1 基于RepVGG的无锚框跟踪网络Fig.1 Anchor-free tracking network based on RepVGG
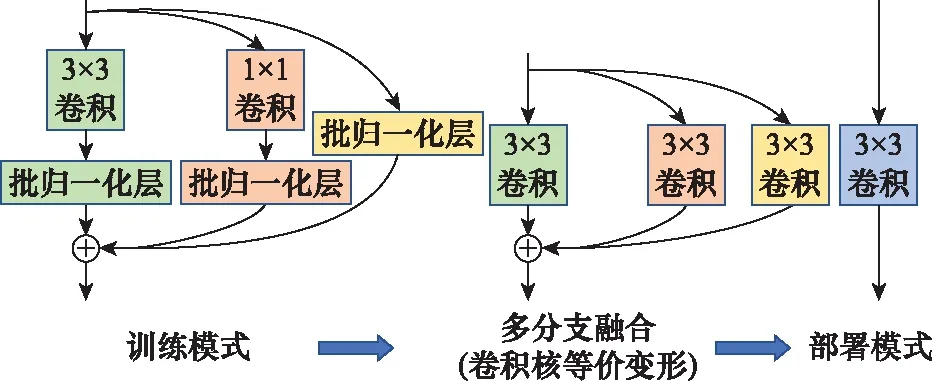
图2 RepVGG网络训练模式与部署模式结构对比Fig.2 Structure comparison between RepVGG network training mode and deployment mode
1.1.2 快速特征金字塔
原有检测后跟踪深度学习跟踪算法采用可变形卷积(deformable convolution,DCN)与逆卷积对特征图进行上采样,同时保证网络整体的实时性与精度,但特征金字塔结构(feature pyramid networks,FPN)是更加有效的精度提升方法。含有DCN的特征金字塔(DCN-FPN,DFPN)推理时间较慢,其层间融合结构如图3(a)所示,主要包括可变形卷积、逆卷积与线性相加操作。为了获得更多的精度收益同时确保跟踪网络的实时性,本文设计了快速FPN(fast-FPN,FFPN),其层间融合结构如图3(b)所示。该结构使用最少卷积操作次数进行搭建,进一步提升速度。同时,舍弃逆卷积操作与DCN操作,改为常规卷积与线性上采样,仅使用一个3×3大小的卷积核同时进行特征提取与通道数匹配调整,并消除采样混叠效应。此外,在最终用于预测的最浅层层间特征融合后追加3×3大小的卷积操作,用于消除采样混叠效应。
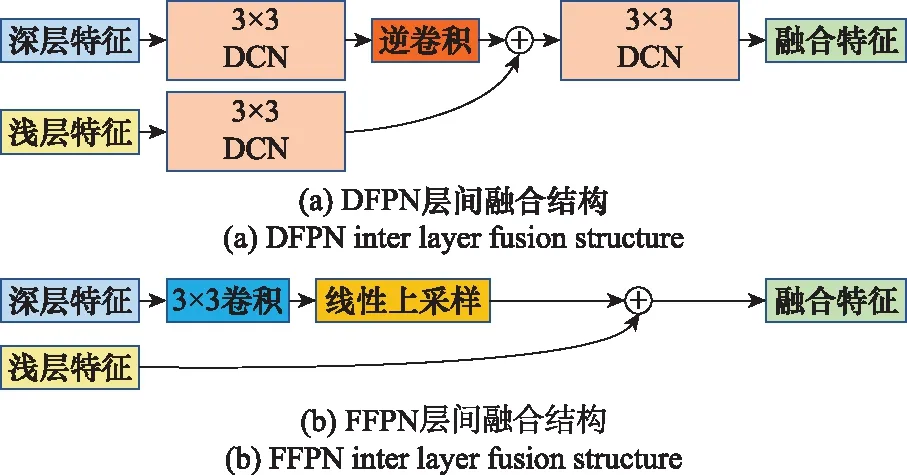
图3 DFPN与FFPN层间融合结构对比Fig.3 Comparison of DFPN and FFPN inter layer fusion structure
1.1.3 检测与识别分支
设输入图像大小为3××(与分别为图像的高与宽,3为通道数),则经FFPN输出的特征图大小为256×4×4。在此基础上,使用并行的4路卷积分支生成最终用于检测与识别的特征图。
(1) 热力图预测头:输出特征图大小为num_classes×4×/4,num_classes为跟踪目标类别数量,用于检测目标的类型。
(2) 目标中心定位补偿预测头:输出特征图大小为2×4×4,用于进一步提升目标定位的精度。
(3) 目标边框尺寸预测头:输出特征图大小为2×4×4,用于预测目标的宽高大小。
(4) 目标识别预测头:输出特征图大小为128×4×4,用于提取目标的特征向量。
1.2 识别特征向量改进
1.2.1 含有标签平滑的交叉熵损失
对于输入图像,目标识别预测头输出当前图像中所有目标的特征向量,并用输出尺度为目标种类数量的全连接层(fully connected layer,FC Layer)进行识别任务回归,原始交叉熵损失(cross entropy loss,CE Loss)计算如下:
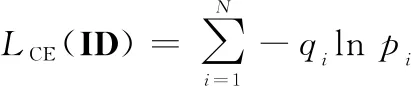
(1)
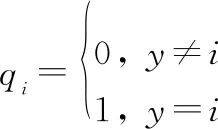
(2)
式中:为输入目标特征向量;为目标种类总数;为样本;为实际标签;为全连接层关于识别真值标签的预测值。
上述回归问题可以被认为是标签分类问题,使用标签平滑策略有助于减少目标识别预测头训练过程中的过拟合问题,即含有标签平滑的交叉熵损失(label smooth cross entropy loss, LSCE Loss):
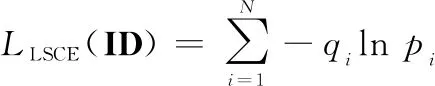
(3)

(4)
式中:为一个很小的常数。鼓励模型减少对训练集标签的信任度,从而减少训练过程中的过拟合问题,提高模型在测试集中的泛化能力。
122 中心损失
对于三元组损失有公式:
=max(-+,0)
(5)
式中:为正样本对的特征距离;为负样本对的特征距离;为边缘阈值。
三元组损失仅对正负样本对之间的距离-的大小进行了限制,但没有对正样本与负样本类内距离与的大小进行限制。中心损失被用于解决上述问题,针对训练时批量样本中的每个样本的特征,希望甚至类内特征中心的距离越小越好,使类内距离变得更加紧凑,进一步提升识别效果。中心损失表达式如下:

(6)
式中:为第个类别的特征向量中心;表示样本特征向量;为训练批量的大小。
123 特征向量归一化层
特征向量归一化层(batch normalization neck,BNNeck)结构使得类间特征在超球面附近成高斯分布,使得与更容易收敛,同时保持了属于同类特征的紧凑分布,其结构如图4所示。在训练阶段,使用归一化前的特征向量计算与,使用归一化后的特征向量计算。在推理阶段,仅使用特征向量用于目标识别任务。

图4 BNNeck结构Fig.4 BNNeck structure
1.3 跟踪处理改进
跟踪处理主要含3个部分:特征向量匹配、卡尔曼滤波目标运动预测、IoU匹配。与公开数据集不同,所采集的红外跟踪数据集存在相机无规则运动,导致目标帧间位置变化较大。当目标在视场中无规则运动时,卡尔曼滤波无法对目标的下一帧位置准确估计,如图5(a)所示,其中矩形框内为目标当前帧所在位置,圆点为目标下一帧运动位置。结合圆点位置,卡尔曼滤波预估目标运动位置如图中菱形所示,明显与图中三角形所示的真实位置存在较大偏差。当目标在图中成像大小较小时,如图5(b)所示,箭头代表目标帧间运动轨迹,相机的无规则运动导致目标帧间运动位置变化较大,目标框无法有效交叠,IoU无法准确匹配。上述问题致使原有卡尔曼滤波目标运动预测与IoU匹配过程无法达到预期效果,故舍弃上述过程换取速度。

图5 卡尔曼滤波目标运动预测与IoU匹配过程失效Fig.5 Kalman filter target motion prediction and IoU matching process failure
为引入卡尔曼滤波与IoU匹配过程相似的位置关联效果,在原有计算特征向量间余弦距离的基础上,加入目标帧间运动距离的惩罚项,对特征向量赋予帧间运动距离信息,进一步提升跟踪处理的效果。
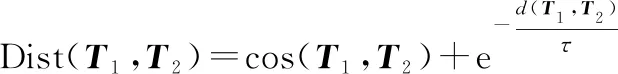
(7)

1.4 边缘设备部署
141 融合卷积层与批归一化层
为了进一步提高网络在边缘设备部署时的推理速度,对网络中卷积层与批归一化层进行融合。卷积层可表示为
=·+
(8)
式中:为卷积层权重;为卷积层偏置。
融合卷积层后的批归一化层可表示为
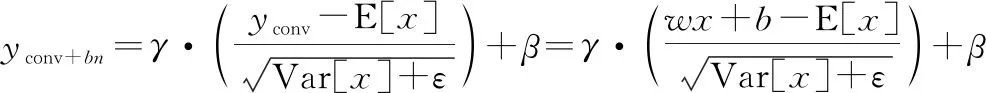
(9)
式中:E[·]为计算训练批量样本均值;Var[·]为计算训练批量样本方差;与为可学习参数。
令
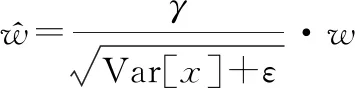
(10)

(11)
则融合后的卷积层与批归一化层可表示为
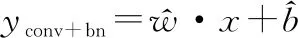
(12)
1.4.2 GPU与CPU的选取
为解决跟踪网络在边缘设备中部署实时性较差的问题,对训练后的网络在NVIDIA Jetson Xavier NX中的处理时间进行了分析,主要过程有三部分:GPU中运行的前向传播(forward propagation,FP)时间,GPU与CPU中运行的结果解码(result decoding,RD)时间与CPU中运行的跟踪时间(tracking time,TT)。其中,RD部分耗时最多,其次为跟踪处理,最快为FP,总时间消耗为116.74 ms,无法满足实时性需求。为进一步提高整体运行速度,将所有CPU中执行的运算全部移植到GPU中运行,对比结果如表1所示。

表1 边缘设备运算耗时统计
全部移植到GPU运行发现解码部分速度有所提升,但跟踪处理部分却比原先慢很多,总耗时略微下降。分析认为,RD涉及到大型矩阵运算,如:特征热力图的解码、目标定位解码等,更适宜在GPU中运行,而跟踪处理中多涉及逻辑运算与小型矩阵运算,如:特征向量间距离计算、卡尔曼滤波、轨迹判定等,在GPU中运行速度反而严重降低,且Python的字典拖慢了处理跟踪目标队列的运行效率。鉴于此,使用TensorRT对GPU运算部分的FP进行加速。考虑到TensorRT输出的结果在CPU中且为特征图拉伸后的一维向量,为了减少不必要的矩阵维度变换与GPU与CPU间的交互,采用C++完成RD与跟踪处理过程,进一步提速。
1.5 损失函数
对于检测任务包括热力图损失,目标中心定位补偿损失以及目标边框尺寸预测损失。热力图损失使用含有焦点损失的像素逻辑回归,其表达式如下:
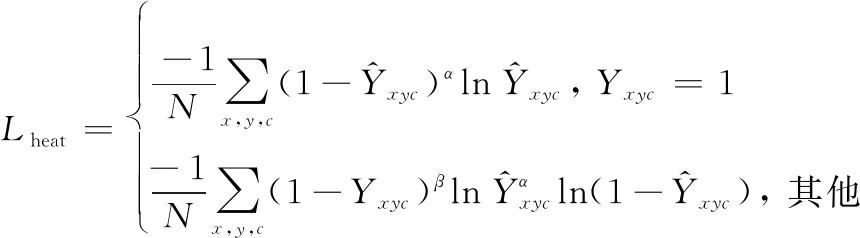
(13)

目标中心定位补偿损失使用一维欧式距离损失,具体公式为
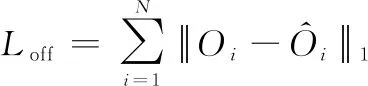
(14)

目标边框尺寸预测损失公式同样使用一维欧式距离损失,具体公式为

(15)
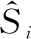
综上,检测任务损失函数可表示为
=++
(16)
式中:,,分别为不同部分的损失权重。
对于识别任务损失函数包括带有标签平滑的交叉熵损失、三元组损失、中心损失,如式(3)~式(6)所示,则识别任务损失函数可表示为
=++
(17)
式中:,,分别为不同部分的损失权重。
使用文献[31]中的多任务联合学习损失函数对检测和识别任务进行训练,总损失函数可表示为
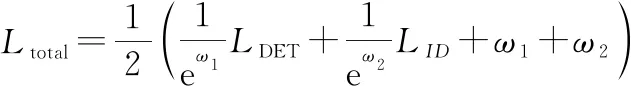
(18)
式中:与为可学习常参数,用于平衡分类任务与检测任务的权重。
2 数据集与评估准则
深度学习作为一种数据驱动的方法,需要大量数据进行训练,以达到预期效果。对此,建立低空海面背景下的无人机与船只数据集来验证算法的有效性。所有图像均来源于放置于岸边的红外图像采集设备,共78段视频(136 846张图像),包含顺光与逆光拍摄的早中晚各个时段的212种类的船只与3种类的无人机。相机架设在转台之上,随转台转动存在着无规则运动,相关训练数据集图像如图6所示。

图6 红外海上目标跟踪数据集展示Fig.6 Display of infrared sea target tracking dataset
使用TXT文本文档对每一段视频进行标注,每行标注内容为当前帧号、当前帧图像内总目标个数以及每个目标的种类编号、中心点坐标、宽高与类别。进一步对数据集进行划分,得到训练集共55段视频(103 101张图片),测试集23段视频(共33 745张图片)。
在评估准则方面,共有MOTA,IDF1,MT,ML 4个指标。MOTA为多目标跟踪的准确度,体现在跟踪确定目标的个数,以及有关目标的相关属性方面的准确度,用于统计在跟踪中的误差累计情况。
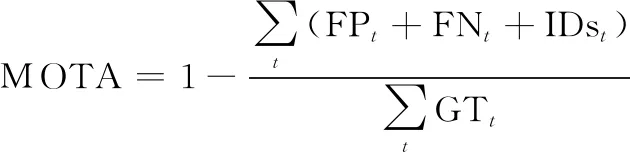
(19)
式中:为视频中的第帧;FP为假阳目标数量;FN为假阴目标数量;IDs为目标编号切换次数;GT为目标真值个数。
IDF1为目标识别准确率和召回率的调和平均数,用于衡量识别的精确程度。
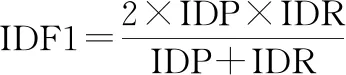
(20)
式中:IDP为目标识别准确率;IDR为目标识别召回率。
MT为预测的目标轨迹占真值总轨迹比例大于80%的个数,ML为预测的目标轨迹占真值总轨迹比例小于20%的个数。
本文使用MOTA、IDF1、MT、ML 4个指标得到的分数对算法性能进行综合评估,评分(Score)计算公式为

(21)
其中,上述指标均为百分比大小,MT与ML为利用总轨迹个数归一化后的百分比大小,评分的取值范围为负无穷到100。
3 实验分析
3.1 实验设置
对于训练过程使用PC机完成训练,CPU为Intel core i9-10900K,GPU为Quadro RTX 8000(48 GB),CUDA 11.0,CUDNN 8.0,操作系统为Ubuntu 20.04LTS,采用Pytorch1.6深度学习架构。使用随机梯度下降优化算法(stochastic gradient descent, SGD),初始学习率为10,总训练为30个epoch,每训练10个epoch学习率调整为原来的十分之一。训练批量大小为16,输入图像分辨率为640×512,损失函数权重设置分别为=1,=1,=01,=1,=1,=01。
对于实时性验证过程使用NVIDIA Jetson Xavier NX边缘计算设备进行,CPU为6-core NVIDIA Carmel ARMv8.2 64-bit,GPU为NVIDIA Volta架构,搭载384 NVIDIA CUDA cores和48 Tensor cores(8 GB),CUDA 10.2,CUDNN 8.0,操作系统为Ubuntu 18.04LTS,采用Pytorch1.6深度学习架构。
3.2 消融试验
3.2.1 基于RepVGG的跟踪网络与其他轻量级网络对比
本文基于RepVGG骨干网络设计了无锚框跟踪网络结构,从评分、推理时间、模型计算复杂度3个方面与其他轻量级网络进行对比,并对DCN、DFPN、与本文设计的FFPN的跟踪性能进行了对比,结果如表2和表3所示。

表2 基于RepVGG的跟踪网络与其他轻量级网络跟踪精度对比
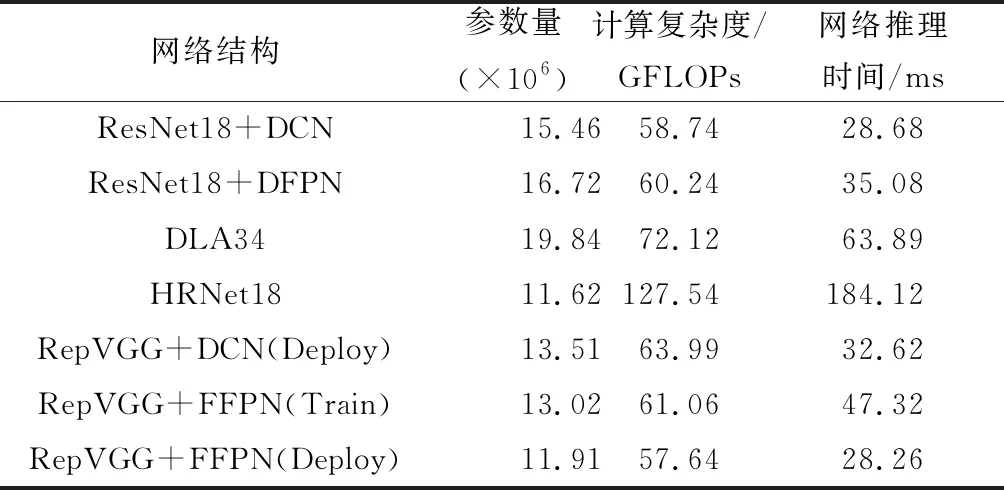
表3 基于RepVGG的跟踪网络与其他轻量级网络推理速度对比
从表2与表3中的结果可以看出基于RepVGG的FFPN更好地融合了网络的深层语义信息与浅层细节信息,相较于DCN能够带来更多的精度收益,评分增长2.78,网络推理时间快4.36 ms。此外,FFPN较含有DFPN省去了卷积采样点变形的计算过程,并使用次数最少的卷积运算操作完成特征金字塔搭建,网络推理时间快10.76 ms。Deploy模式能够在评分不变的情况下对模型有效提速,网络推理时间减少19.06 ms。相较于ResNet18、HRNet18、DLA34轻量级网络,所设计的网络拥有较小的参数量与最小的模型计算复杂度,以及最低的推理延迟,评分略低于DLA34等高推理延迟网络。
3.2.2 识别特征向量改进
本文引入重识别领域相关改进对目标识别预测头生成的目标特征向量进行改进,结果如表4所示。从表中可以看出,含有标签平滑的交叉熵损失有效减少了目标识别预测头训练中的过拟合问题,提高特征向量在测试集中的泛化能力。中心损失在三元组损失的基础上学习每类特征的中心并惩罚类内样本关于中心的距离,对类内距离进行限制,进一步提高识别过程的精确度。BNNeck的加入使得目标编号切换次数进一步降低,同时拥有最高识别精确度与评分。

表4 识别特征向量改进效果对比
3.2.3 跟踪处理的精简与改进
为证明所提跟踪处理的精简与改进的有效性,从评分与跟踪耗时两方面进行对比,结果如表5所示。从结果中可以看出,在相机无规则运动的情况下,卡尔曼滤波目标运动预测不具有可行性,各项跟踪指标严重降低,而处理错误跟踪轨迹引入了大量额外计算,导致TT明显提升,达到25.65 ms。在去除卡尔曼滤波目标运动预测后,消除了其对跟踪过程带来的负面影响,跟踪各项指标极大提升,跟踪处理时间为7.09 ms。当目标较小且视场运动较为剧烈时,目标帧间运动的像素距离较大,IoU往往不能进行准确匹配,将IoU匹配过程去除可以缓解上述问题,MT、ML指标有所提升。同时,仅靠特征向量匹配导致跟踪编号不稳定,编号切换次数增多,IDF1指标降低。对此,采用含有目标帧间运动距离信息的特征向量弥补IoU匹配缺失带来的影响,MT指标进一步提升,同时改善了IDF1与IDs指标。改进后的跟踪处理省去了卡尔曼滤波与IoU匹配的计算过程,引入目标帧间运动信息对原有目标特征向量进行改进。同时,使用C++改善了使用Python字典处理跟踪目标队列运行效率低下的问题,跟踪处理时间为1.29 ms。

表5 跟踪过程的精简与改进
3.2.4 边缘设备部署
使用本文所设计的基于RepVGG的无锚框跟踪网络与改进后的跟踪方法,在NVIDIA Jetson Xavier NX边缘设备上进行实验。通过对Deploy网络中的快速特征金字塔结构的批归一化层与卷积层进行合并,最终Deploy网络仅含有卷积层与激活层,不含有批归一化层。所统计的时间包含图像载入(load image,LI)、图像预处理(image preprocessing,IP)、FP、RD、TT。在FP方面,从表6中可以看出TensorRT有效地加速了网络FP的运算速度,速度提升2.65倍。同时,通过简化与改进后的跟踪部分时间降低4.52倍。在实验中发现,使用Pytorch进行RD时间最慢,为83.29 ms,而使用Numpy进行RD速度有所提升,为32.26 ms,使用C++进行解码速度最快,为2.73 ms。本文所提出的算法整体跟踪处理帧率为52.37,满足边缘设备部署实时运行需求。跟踪精度方面,从表7中可以看出,Deploy模式并没有影响跟踪精度,TensorRT(FP16)的使用使得计算结果出现一定舍入误差,出现精度损失,尤其体现在MOTA与IDF1指标上。通过改进跟踪处理算法,使得本文方法评分最高,IDF1与IDs指标有所下降,但与所换取的速度提升相比是可以接受的,相关海上多类别多目标跟踪结果如图7所示。

表6 不同部署方法的跟踪速度对比

表7 不同部署方法的跟踪精度对比

图7 海上多类别多目标跟踪结果Fig.7 Display of multi-category and multi-target tracking results on the sea
4 结 论
本文结合RepVGG骨干网络设计快速特征金字塔结构,提出了一种基于无锚框的红外多类别多目标实时跟踪网络。通过引入重识别领域相关改进方法,对目标识别预测头的特征向量进一步优化,提升识别的精确程度。针对转台造成的相机无规则运动所建立的数据集,简化了跟踪处理流程,对目标特征向量赋予帧间运动距离信息,有效改善了相机无规则运动对跟踪带来的影响。同时,细化并分析了多目标跟踪网络在边缘设备中的整体时间消耗,选用GPU与CPU分别执行最优运算,进一步提升整体跟踪速度。最后,将深度学习单类别多目标跟踪网络扩展至多类别多目标跟踪任务当中,对海上多类别目标进行多目标跟踪。结果表明,本文所提相关方法在NVIDIA Jetson Xavier NX边缘设备中运行帧率达到52.37 FPS,满足边缘端实时运行需求。在本文所提的综合评价指标下,所设计的网络相较其他轻量级网络评分提高1.78,能够更好地权衡跟踪精度与推理速度,在边缘端拥有更好的性能。未来,在保证实时性的基础上,我们将注重改进现有方法跟踪处理中IDF1与IDs指标不佳的问题。
