融合多种类型语法信息的属性级情感分析模型
2022-02-23肖泽管陈清亮
肖泽管,陈清亮,2+
1.暨南大学 计算机科学系,广州510632
2.云趣科技-暨南大学人工智能联合研发中心,广州510632
属性级情感分析(aspect based sentiment analysis,ABSA)是一种细粒度的情感分类任务。与识别篇章、句子的整体情感倾向的粗粒度任务不同,属性级情感分析的目标是识别句子中包含的不同属性的情感倾向。例如,给定句子“我们去吃了晚餐,虽然服务不错,但是不好吃。”,属性级情感分析要识别出句子中包含的两个属性“晚餐”和“服务”的情感倾向分别是负向和正向。
解决属性级情感分析的传统方法是结合人工设计的特征和机器学习算法,例如支持向量机、隐马尔科夫模型等。随着深度学习的发展,越来越多的深度学习模型被提出用于属性情感分析。Ruder 等人提出使用层次长短期记忆模型利用长评论里不同句子之间的情感关联来进行属性级情感分析。Tang 等人提出结合记忆网络和注意力机制的方法。近些年来,属性级情感分析的研究重点在如何利用注意力机制更好地建模属性与情感表达的关系,提出了基于不同形式注意力机制的模型。
然而,基于注意力机制的模型却忽视了使用语法信息,这会导致模型难以正确匹配属性和对应情感表达。例如,在句子“我们去吃了晚餐,虽然服务不错,但是不好吃。”中,属性“晚餐”的对应情感表达是“不好吃”,但由于缺乏句子的句法信息,基于注意力的模型可能会错将“不错”作为对应“晚餐”的情感表达。一方面,现有的属性级情感分析标注数据集较小,基于注意力的模型很难从较小的数据集中学习到通用的语法知识;另一方面,属性级情感分析往往面临多个属性、多种情感倾向的复杂语境,情感表达也随着语言的发展更加复杂。于是,引入更多的语法信息成为提高模型准确率的关键。本文提出一种融合多种类型语法信息的神经网络模型,有效解决基于注意力机制的模型在多个属性、多种情感倾向的复杂语境下的不足。首先,本文提出将预训练模型BERT(bidirectional encoder representations from transformers)作为语法信息的来源。自BERT 提出以来,大量工作使用它的最后一层的输出作为上下文相关词表示输入到模型,而忽略了使用中间层。Jawahar 等人通过实验得出结论,BERT 的不同层学习到的知识有显著偏好:低层偏向学习短语结构信息,中层偏向学习句法信息,高层偏向学习语义信息。这启发本文使用BERT 的中间层引入短语结构、句法等多种语法信息解决属性级情感分析的复杂语境问题。然后,本文使用依存句法树引入句子结构信息。句子的依存句法树含有显性的结构信息,如图1 所示,属性“晚餐”在依存句法树中离与它相关的情感表达“不好吃”更近,而在句子的线性形式中,“不错”比“不好吃”更靠近属性“晚餐”。在这种情况下,基于注意力机制的模型难以正确匹配属性和情感表达的关系,尤其是模型使用基于词和属性的距离的位置编码时,正确的情感表达“不好吃”的重要性会进一步减小。为了有效利用这种显性的结构信息,本文利用基于依存句法树的多层图卷积神经网络学习属性的向量表示。为了同时利用BERT 中间层的语法信息和依存句法树的句法结构信息,本文提出一种利用多种类型语法信息的模型,将BERT 中间层的输出作为指导信息,每一层图卷积神经网络(graph convolutional networks,GCN)的输入由上一层GCN 的输出和该层指导信息结合而成,然后再进行图卷积操作。属性在最后一层GCN 的输出作为最终的特征,进行情感倾向分类。
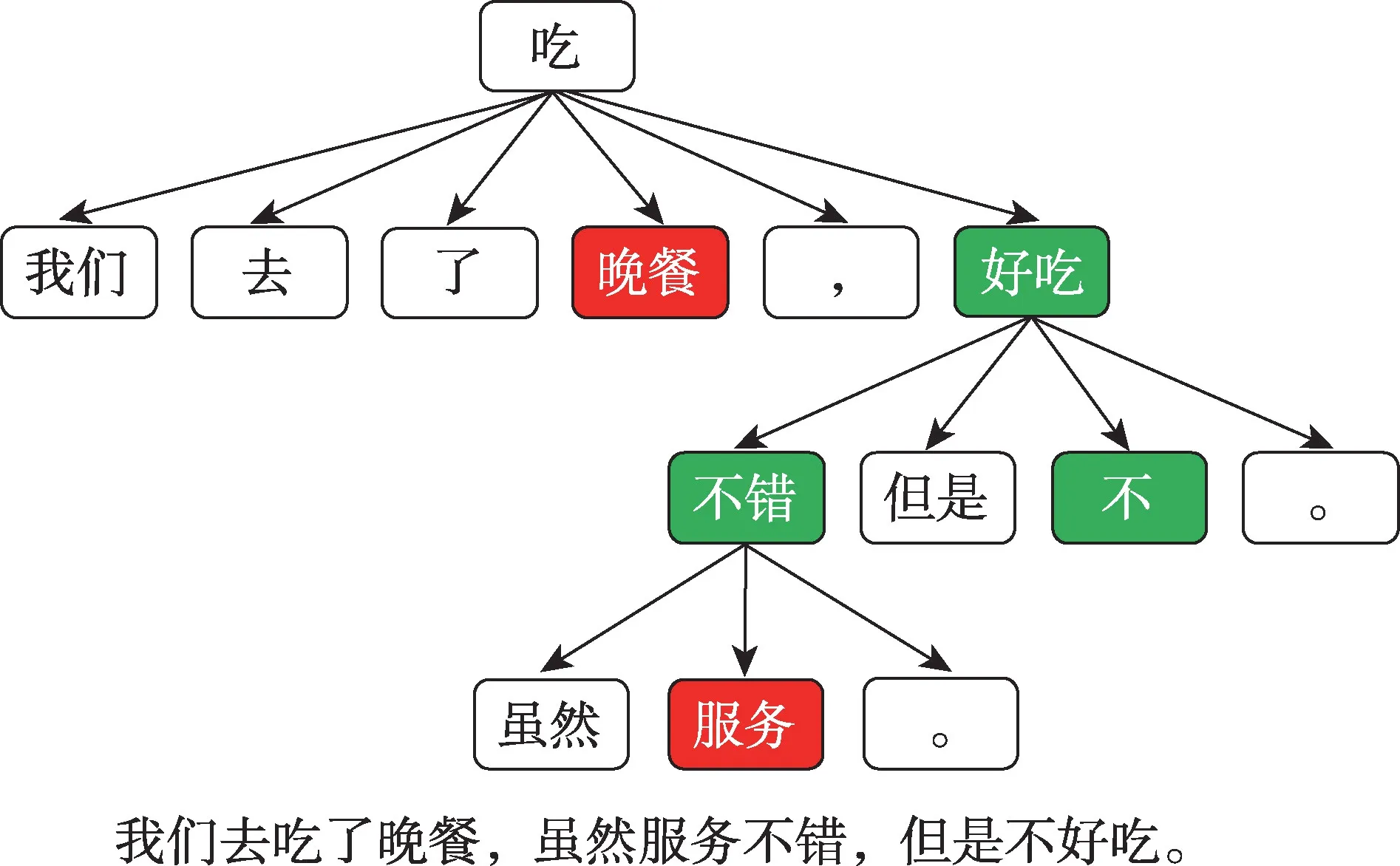
图1 依存句法树例子Fig.1 Example of dependency tree
本文的贡献可以总结为以下三点:
(1)提出使用BERT 的中间层输出,引入多种类型语法信息,能够更好地自动抽取特征。
(2)提出一种同时利用BERT 和依存句法树两种语法信息来源的模型,将BERT 中间层的语法信息作为指导信息,指导每层GCN。
(3)在SemEval 2014 Task4 Restaurant、Laptop 和Twitter 三个数据集上的实验结果表明,本文方法超越了很多基准模型。
1 相关工作
1.1 BERT
BERT是在大规模无标注文本上预训练的语言模型,基于它的微调模型在句子级情感分类、词性标注等自然语言处理问题上都取得了非常好的效果。BERT 由多层Transformer Encoder叠加组成,每层Transformer Encoder 的输出都作为下一层Transformer Encoder 的输入。一般认为BERT 最后一层的输出拥有丰富的上下文词相关信息,因此通常把它用来代替Word2vec、Glove作为模型的输入词向量。Jawahar等人通过大量实验发现,BERT 的不同层学习到的知识有显著偏好。BERT 的低层倾向于学习短语语法和句子长度等信息,中层倾向于学习主谓一致、词序是否正确等语法信息,而高层倾向于学习上下文相关语义信息。
1.2 图卷积神经网络GCN
GCN可以看作卷积神经网络(convolutional neural networks,CNN)在图数据上的迁移。对于一张图,图中的每个节点都能用一个向量来表示,GCN用图中每个节点的一跳邻居节点来更新所有节点的表示。在开始时,每个节点被初始化为初始状态,而后GCN 对图中每个节点的表示进行更新,这时图中每个节点即可获得它们所有一跳邻居节点的信息。叠加使用层GCN,则每个节点可以获得跳邻居节点的信息。经典的GCN 结构和流程如图2所示。使用基于依存句法树的GCN 可以直接匹配属性和情感表达,缓解冗余信息的干扰。
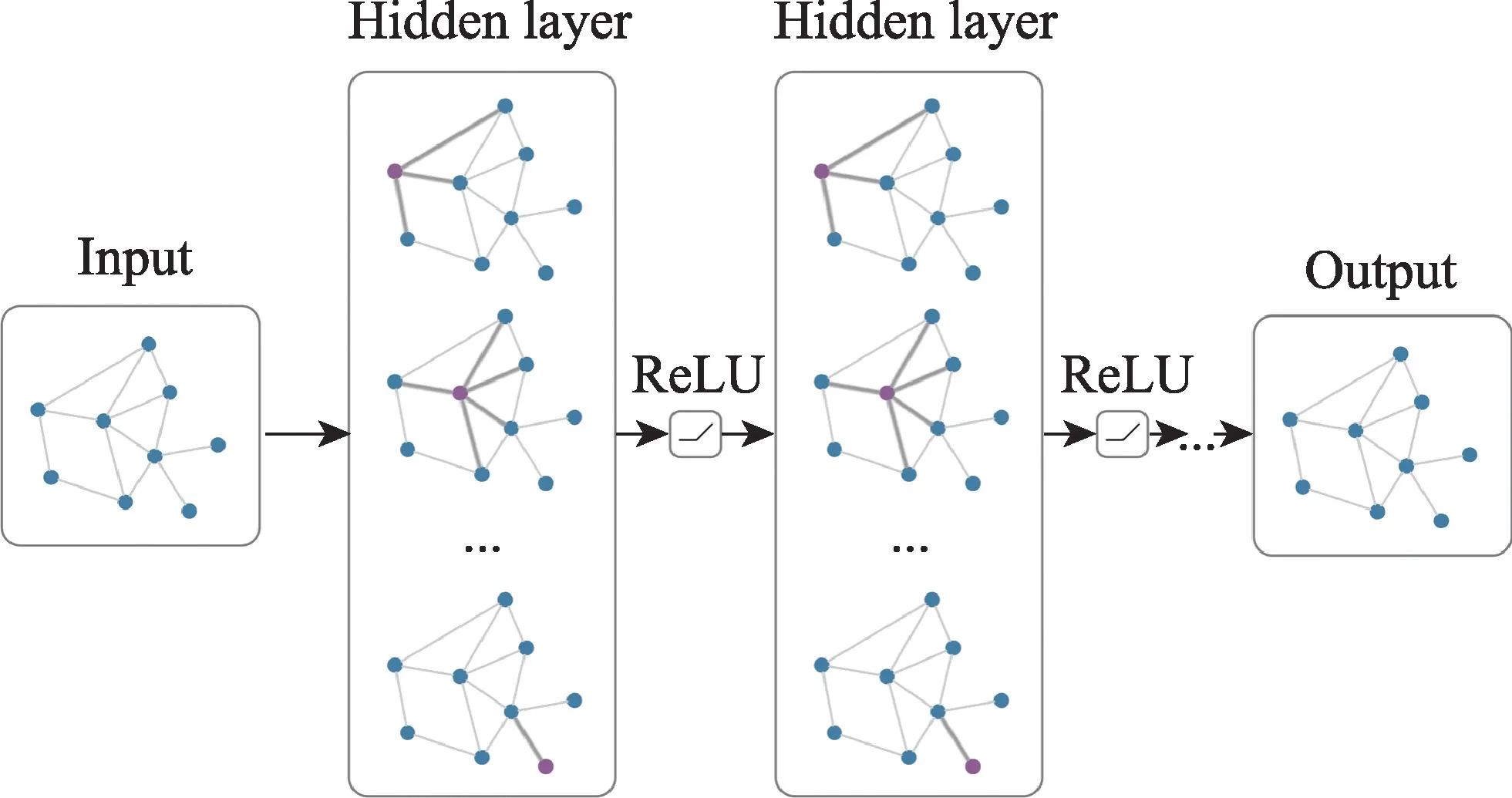
图2 图卷积网络Fig.2 Graph convolutional network
1.3 依存句法树在属性级情感分析的应用
依存句法树是一种把句子按照词语之间依存关系重新组织的树形结构。词语之间用有向边相连,有向边的头称为支配词,有向边的尾代表从属词,它们之间的关系叫作依存关系。图1 是句子“我们去吃了晚餐,虽然服务不错,但是不好吃。”省略了依存关系的依存句法树。
属性级情感分析需要精准匹配句子中属性与其对应的情感表达,因此正确建模句法信息非常重要。早期,研究人员提出使用依存句法树直接获得句法信息,并使用递归神经网络建模节点的情感信息流动。近些年,随着图神经网络(graph neural networks,GNN)的发展,研究人员开始探索将依存句法树和GNN 结合解决属性级情感分析。Huang 等人提出使用基于依存句法树的多层图注意力网络(graph attention network,GAT)学习属性表示,同时利用长短期记忆模型(long short-term memory,LSTM)跟踪不同GAT 层的属性表示。Sun 等人提出在使用双向LSTM(bi-directional LSTM,BiLSTM)得到上下文相关词表示的基础上使用基于依存句法树的图卷积神经网络(GCN)学习属性的表示。在此基础上,Zhang等人利用注意力机制匹配GCN 学习到的属性表示和相关的情感表达。
2 利用多种类型语法信息增强的模型
2.1 问题定义和符号说明
给定一个句子={,,…,w},其中含有个词和一个由个连续词组成的代表属性的子字符串={w,w,…,w}。属性级情感分析的目标是识别出该属性在句子中的情感倾向。
本文提出的融合多种语法类型信息的模型架构如图3 所示。

图3 模型结构Fig.3 Model architecture
2.2 BERT 的使用
本文将BERT当作一个语法知识的提取器,将BERT 学习到的语法知识当作指导信息,与每一层GCN 的输入结合。BERT 的输入采用了双句的形式:“[CLS]句子[SEP]属性[SEP]”。BERT 不同层学习到的语法知识有区别但相邻层区别不大,为了充分利用BERT 又使每一层GCN 的指导信息有差异化,本文选取BERT的第1、5、9和12共4层的输出作为GCN 的指导信息。当输入的某个词被分解为多个子词时,只使用它的第一个子词对应的输出。于是BERT 产生的指导信息为:

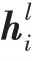
2.3 词嵌入层和双向LSTM 层
给定句子=[,,…,w],本文使用Glove 将其映射到对应的词向量:

接着将词向量输入到双向LSTM 中,得到上下文相关词表示H:

其中,H∈R是双向LSTM 的输出。
2.4 GCN 层
为了能够利用来自依存句法树的句法结构信息,本文使用基于依存句法树的多层GCN。句子的依存句法树被当作无向图,并给图中每个节点增加了连接到自己的边。第一层GCN 的节点表示初始化为双向LSTM 的隐藏状态与其对应的BERT 指导信息的结合,其后每一层GCN 的输入由前一层GCN的输出和相应BERT 指导信息结合。而后,节点表示经过卷积操作进行更新:
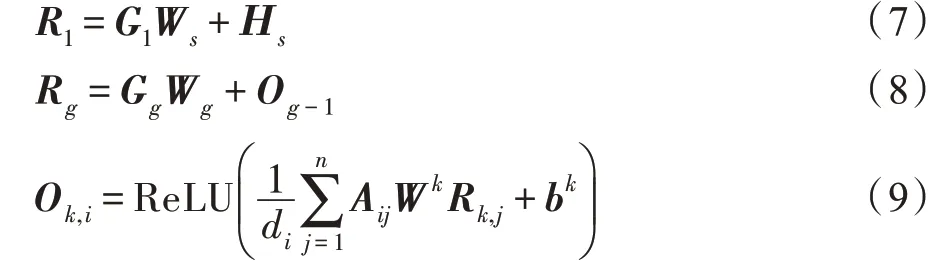
其中,∈{2 ,3,4},∈{1 ,2,3,4},G表示第层GCN的指导信息,W、W是可学习的参数。 d是第个节点的度,是图的邻接矩阵,W和b是可学习的参数。由于选取了BERT 中的四层作为指导信息,GCN 的层数也有四层。把属性=[w,w,…,w]在最后一层GCN 的输出表示求平均作为属性的最终表示,然后输出到情感分类层。

2.5 情感分类层
将GCN 层得到的属性表示h经过全连接层映射到与情感类别个数相同的维度,再使用Softmax 将全连接层的输出正则化,得到模型对每个类别的分类概率:
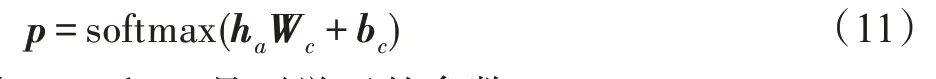
其中,W和b是可学习的参数。
2.6 模型训练
模型使用带L2 正则化的交叉熵作为损失函数,使用随机梯度下降法进行优化:

其中,表示训练数据集,表示训练样本,代表样本真实标签。代表L2 正则化系数,代表整个模型的参数。
3 实验结果及分析
3.1 实验数据
本文提出的模型在三个数据集上进行了实验,包 括SemEval 2014 Task4 Restaurant、Laptop和Twitter 数据集。所有的实验都剔除了数据集中标签为“冲突”的样本,只使用标签为“正向”“中性”“负向”三类样本。表1 显示三个数据集的样本划分情况,采用了和开源数据集的原始论文相同的划分。

表1 数据集样本划分Table 1 Statistics of datasets
3.2 基线模型
为了全面评估本文提出的模型,本文将其与多个基线模型进行对比。IAN(interactive attention networks)分别用两个LSTM 生成句子和属性的初始表示,然后使用从句子到属性的注意力机制和从属性到句子的注意力机制得到上下文相关的属性和句子表示,最后将两个表示进行拼接作为特征得到最后的分类结果。AOA(attention over attention)用行Softmax 和列Softmax 建模句子和属性交互关系。AEN-BERT使用多头自注意力机制生成句子和属性的表示,并使用标签平滑处理中立样本。CDT(convolution over a dependency tree)用BiLSTM 得到上下文相关词表示后使用一层图卷积神经网络,最后将属性的表示作为特征分类。TD-GAT-BERT(target-dependent graph attention network)用多层GCN 学习属性表示,并使用LSTM 建模多层GCN 的属性表示。ASGCN(aspect-specific graph convolutional network)和ASGCN-BERT在CDT 的基础上使用从属性表示到句子的注意力机制。ASGCN-BERT 模型用BERT 最后一层代替ASGCN 模型的输入层和双向LSTM 层。BERT-SPC 模型用“[CLS]”字符在BERT最后一层的输出作为特征微调的模型。
3.3 实验设置
本文使用开源工具spaCy(https://github.com/explosion/spaCy)生成依存句法树,将生成的依存句法树作为图,忽略边的类型。BERT模型使用开源工具Transformers(https://github.com/huggingface/transformers)实现。实验中,Glove词向量的维度d为300,双向LSTM的隐藏状态维度d为300。BERT使用uncased BERTbase模型,隐藏状态维度为768,共有12层。Batch大小设置为32,BERT 模型学习率设为0.000 02,其他模块学习率为0.001。学习率随训练步数线性逐渐增加,在第3 个epoch 达到顶峰,然后线性逐渐下降。使用0.02 的权重衰减系数和0.2 的dropout 概率。模型参数用Xavier 方法初始化为均匀分布,然后用Adam优化算法训练模型。本文使用了和Zhang 等人相似的实验设置,实验结果取随机抽取的10 个随机种子的平均结果,每次实验最多训练30 个epoch,并使用早停法,当连续3 次验证准确率不增加时,提前结束训练(early stopping)。
3.4 实验结果
本文使用准确率(Accuracy)和Macro-F1 值来评估模型。表2 给出了8 个基线模型和本文提出的模型在3 个数据集上的实验结果,“—”代表原始论文中缺少结果。模型后标有“*”表示实验结果引用自原始论文。
从表2 中可以看出,本文提出的模型在3 个领域的数据集上都取得了很好的效果。在Restaurant 数据集和Twitter 数据集上,本文方法比所有基线模型都好,准确率分别比次优模型提高了0.1%和1.4%,Macro-F1 分别提高了1.8%和1.6%。在Laptop 数据集上,本文方法也取得了相当好的效果,准确率比最好的TD-GAT-BERT 模型低1%,而Macro-F1 则达到了最好。

表2 实验结果Table 2 Experimental results %
对比4 个使用了BERT 的基线模型,本文提出的模型比其他模型有更好的效果,表明同时使用BERT中间层具有的短语结构信息、语法信息和依存句法树的句法结构信息等多种语法信息可以更好地帮助解决属性级情感分析问题。
为了分析来自BERT 不同层的语法信息和来自依存句法树的句法结构信息对模型效果的影响,本文对模型的两个变种模型进行了实验,结果如表2 所示。模型名字的下标表示使用的层数,Ours代表该模型使用BERT 的第1,5,9 层作为指导信息,并且使用了三层GCN;Ours代表该模型仅使用BERT 的第12 层作为指导信息,并使用一层GCN。
基线模型CDT 可以看作没有使用任何BERT 指导信息的本文提出的模型的变种。从表2 可以看到,在多个数据集上Ours和Ours的效果都远远好于没有使用任何BERT 指导信息的CDT。Ours相比BERT-SPC 在所有数据集上效果都有提升,说明使用依存句法树具有的句法结构信息可以一定程度增强模型的效果。而Ours在与Ours 对比时,它在所有数据集上的效果都稍差,这显示了BERT 低层和中层的语法信息也能够有效提升分类效果。只使用BERT低层和中层作为指导信息的Ours也能取得不错的效果,但是在所有实验中效果都比Ours差一些。分析认为有以下几点原因:第一,虽然BERT 的低层相较于高层捕获了更多的短语结构信息,但是它的12层输出作为上下文相关的词向量,仍然具有一定的感知短语结构信息的能力,这一点从Jawahar 等人的工作的图1 可以看出;第二,由于模型使用了依存句法树,Ours可以一定程度上弥补没有使用BERT的中层的句法信息的不足;第三,BERT 高层学习到的语义信息在该问题中相比于其他层更重要。从实验结果可以看出,没有使用基于依存句法树的GCN和BERT 中间层作为指导信息的BERT-SPC 模型也取得了相当好的效果。
3.5 实例分析
为了验证本文提出的模型在处理复杂语境和复杂情感表达方面更有优势,分析了6 个样本实例,结果如表3 所示。每个句子中,当前分类的属性被方括号括起来并加粗,其后给出了实例的真实标签、AENBERT 分类结果和本文提出的模型的分类结果。
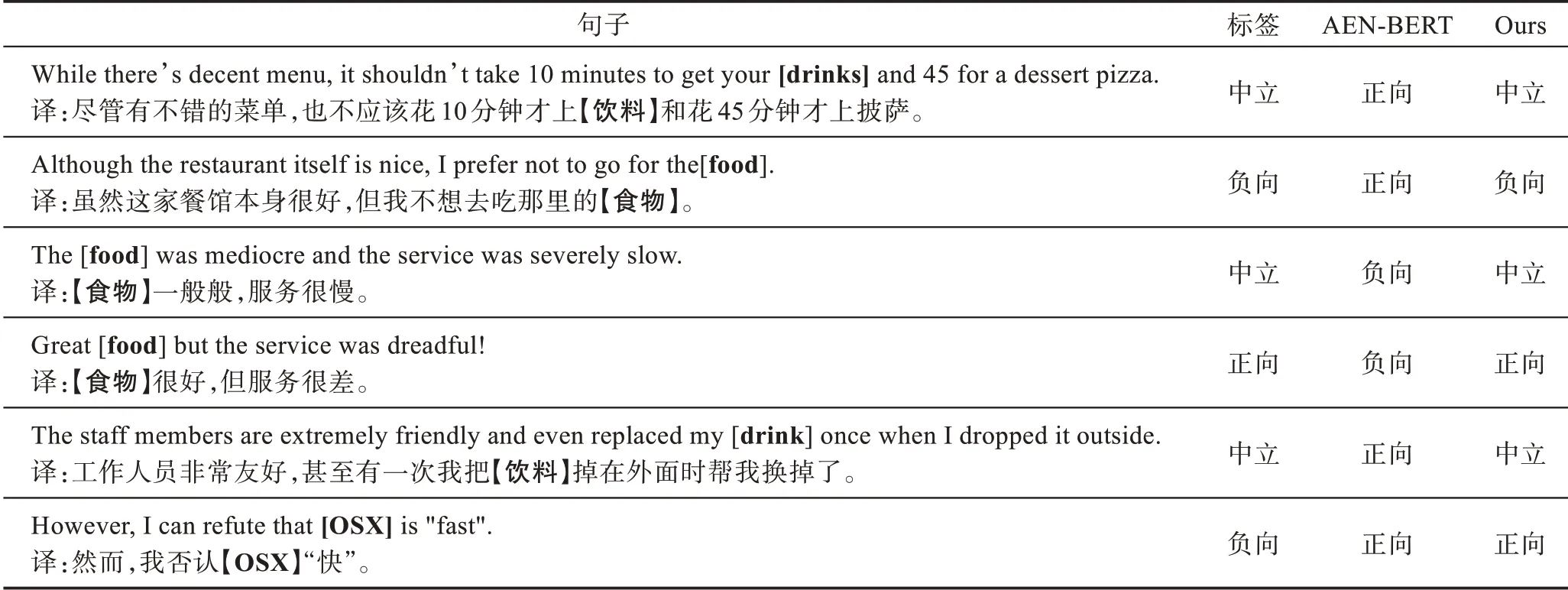
表3 实例分析Table 3 Case study
可以看出,在多属性、多情感的复杂语境下AEN-BERT 无法准确匹配当前属性与其对应情感表达的关系,而误把其他属性的情感表达当作分类依据。比如,在第一个句子中,AEN-BERT 将“饮料”的情感倾向误分类为正向,而真正为正向情感倾向的属性是“菜单”;同样的,在第二个句子中,AEN-BERT把属性“餐馆”的情感表达当作了“食物”的情感表达,因此将“食物”的情感倾向误分类为正向。在第三、第四和第五个句子中,AEN-BERT 也犯了同样的错误。而本文提出的模型在面对这种复杂语境时可以匹配不同属性对应的情感表达,因此表现比AENBERT 更好。例如,在第三和第四个句子中即使有“很慢”和“很差”这种强烈情感倾向,本文提出的模型也没有被干扰,最终做出了正确的判断。值得注意的是,由于模型具有短语结构信息,在第二个句子中,它可以判断复杂情感表达“prefer not”的情感倾向为负向。在对第六个样本分类时,两个模型都将情感误分类为正向。句子中包含一个宾语从句,属于复杂句型。经过检查,句子的依存句法树解析基本正确,因此导致误分类可能的原因是GCN 层数较多,使得“fast”的信息最终传递到了属性,影响了最后的分类。
4 结束语
针对属性级情感分析现有方法的不足,本文提出了利用多种类型语法信息的模型,同时利用了BERT 中间层语法信息和依存句法树的句法结构信息。首先,将句子输入BERT 以获得指导信息。然后,将经过词嵌入层和双向LSTM 的词表示与指导信息结合,再输入到基于依存句法树的GCN 层。经过多层具有指导信息的GCN,最后将属性的向量表示作为特征进行情感倾向分类。实验结果表明本文提出的模型可以很好地解决属性级情感分析任务。
本文提出的模型使用了依存句法树,但没有解决生成的依存句法树有错误的问题,这会导致模型把与属性的情感倾向不相关信息考虑到最终的分类决策中,这会对模型的效果造成一定影响。将来的工作将重点集中在通过修补或变形依存句法树来缓解错误带来的影响。
