不同插值方法在断层检测模型中的应用效果对比分析
2022-02-21杨梦琼王泽峰许辉群李欣怡魏文斋
杨梦琼,王泽峰,许辉群,李欣怡,魏文斋
(1.长江大学 地球物理与石油资源学院,湖北 武汉 430100;2.中国石油辽河油田公司锦州采油厂,辽宁 凌海 121209)
1 引 言
断层是地壳因受到一定强度的作用力发生破裂,且沿破裂面有明显相对移动的构造,它是一种非常常见的地质现象,目前我国大部分含油盆地内的含油构造都含有断层,能否准确识别断层对油气的开采有着非常重要的影响[1]。利用地震资料的断层探测发展到如今,已经出现了许多方法,常规的断层探测方法主要有:Colorni提出的蚂蚁体技术[2],Gersztenkorn等提出的C3相干体技术[3],Marfurt K J等提出的平面多属性分析技术[4],Randen T等提出的边缘探测技术[5],刘志远等提出的浅层地震反射波法[6],吴永辉等提出的三维地震小断层精细解释方法[7],上述技术方法在实际运用中都取得了不错的效果。随着人工智能技术的发展,先后出现了用BP人工神经网络自动识别小断层[8],该方法的参数选择受人为因素影响较大,而分形技术与神经网络结合[9]可以实现参数选择的自动化。上述机器学习的方法与传统方法结合,如蚂蚁追踪算法和神经网络结合[10]可以解决断层的样本问题,但现实的标签获取中无论是通过相干体、边缘探测还是蚂蚁体技术,仍然有一些断层标签无法获取,通过竞争学习的方法[11]可以解决上述问题。为了进一步提高断层的探测精度,通过深度神经网络模型学习地震数据和断层标签之间的关系[12],从地震数据中提取特征,训练卷积神经网络等技术来进行断层探测[13]。MLP、SVM、VGG分别是上述技术中用到的典型模型,本文将对这三种模型断层探测的性能进行分析,找出最佳模型,并分析不同插值方式的影响。
2 原 理
2.1 单隐层MLP模型结构
单隐层MLP[14]包含三层:一层是由感知单元组成的输入层,一层是计算节点的隐含层,一层是输出层。输入层的激活函数是对数s形函数,隐含层激活函数是线性函数。
2.2 SVM模型结构
SVM[15]的准则是结构风险最小化。对于线性可分的二分类问题,目标是寻找最优线性分界面,使两类模式向量分开的间隔最大,对于线性不可分的二分类问题,寻找一个核函数,通过某种非线性映射将样本映射到一个特征空间,在这个特征空间中构造最优分类超平面,不同的核函数会形成不同的算法,多项式核函数、径向基函数都是最常用的核函数。
2.3 VGG模型
VGG[16]相比AlexNet的一个改进是采用连续的几个3×3的卷积核代替AlexNet中的较大卷积核(11×11,7×7,5×5)。对于给定的感受野,采用堆积的小卷积核优于采用大的卷积核,因为多层非线性层可以通过增加网络深度来保证学习更复杂的模式,而且参数更少。
模型的训练过程由两部分组成。一部分通过自下向上的无监督学习:采用无标签数据分层训练各层参数,这是一个无监督训练(也是一个特征学习)过程,是和传统神经网络区别最大的部分。具体是:用无标签数据去训练第一层,这样就可以学习到第一层的参数,在学习得到第n-1层后,再将第n-1层的输出作为第n层的输入,训练第n层,进而分别得到各层的参数。这称为网络的预训练。另一部分进行自顶向下的监督学习:在预训练后,采用有标签的数据来对网络进行区分性训练,此时误差自顶向下传输[17]。预训练类似传统神经网络的随机初始化,但由于深度学习的第一步不是随机初始化而是通过学习无标签数据得到的,因此这个初值比较接近全局最优,所以深度学习效果好很多,程序上应归功于第一步的特征学习过程。断层探测的方法一般分为三步,第一步是数据的获取与预处理,预处理主要是为了减轻数据本身的质量缺陷对探测结果的影响而采取的转置、翻转、高斯平滑、标准化等操作;第二步是数据切分,提取数据的特征信息,这也是样本构建的关键,处理效果直接关系到模型最后的探测准确度;第三步就是数据后处理部分,确定断层位置和形状[18]。深度学习本质上是构建一个复杂函数进行分类和预测。而断层探测本质上是一个二分类问题,即有断层的地方为1,无断层的地方为0,因此基于深度学习的断层探测原理就是将各个位置的地震数据放入构建的函数中,根据得到的结果进行是否为断层的判断[19]
3 模型训练及测试
3.1 断层样本的构建
首先读取地震数据并转换为矩阵,将矩阵转置翻转实现数据增强,数据增强可以避免过拟合。当数据集具有某种明显的特征,使用Cutout方法和风格迁移变化等相关方法可避免模型学到跟目标无关的信息。此外还可以提升模型的稳定性,降低模型对数据的敏感度[20]。
由于地震数据振幅值变化范围很大,且含有异常值,对矩阵进行高斯平滑和标准化处理。接着读取标签文件,将其转换为矩阵,根据公式(1)和公式(2)计算断层线的坐标,创建空白图片,并根据坐标绘制断层线。
式(1)、式(2)中,x为断层线端点横坐标;y为断层线端点的纵坐标;l为道号;m为起始道号;c为道号间隔;t为采样时间,单位为ms;s为采样起始时间,单位为ms;z为采样间隔。其中原始数据和样本如图1所示。最后将标签数据和地震数据切分为若干个方阵,这是因为计算机在识别图像信息的过程中,机器需要将图片切分成很多个小块,然后从每一个小块中提取某些低级特征,这个过程类似于卷积,切分的大小代表感受野的大小,移动的步长代表提取的精度。移动步长为1时,相邻步感受野会有重复的区域,随着步长增大,相邻感受野会减少甚至没有,且步长为1提取的特征较多,遗漏的特征少。步长增加会遗漏许多特征,因此本文在切分过程中将移动步长设为1。切分完之后对切分图像的大小进行Resize操作,Resize后根据切分得到的标签方阵中0的数量来判定其是否含有断层线,将含有断层线的方阵放入断层列表,无断层线的放入非断层列表,将断层列表和非断层列表合并组成数据列表,生成与断层列表数量一致的全为1的列表,与非断层数量一致的全为0的列表,两列表合并组成标签列表。
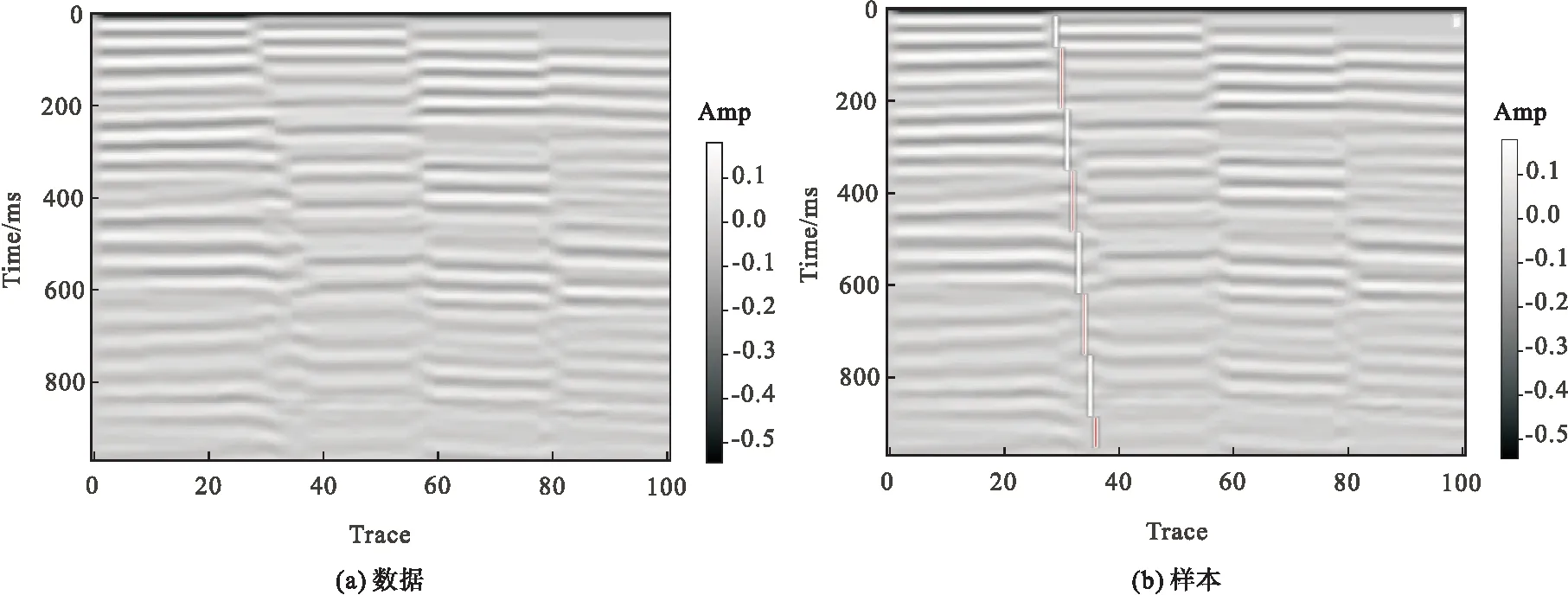
图1 样本对Fig.1 Sample pair
3.2 断层模型测试及分析
创建模型,包括VGG模型、MLP模型、SVM模型,训练数据采用合成地震数据,将5个484道,76个采样点的地震剖面放入模型中进行训练,训练结束后保存模型结构文件(json)和模型权重文件(h5),加载训练好的模型,测试数据由Tessaral软件正演得出一个101道,971个采样点的地震剖面,放入模型后,对其进行预测。其预测结果含有Accuracy、Sensitivity、Specificity、F1-Score、AUC五个评价指标,其中,Accuracy为准确率,是分类正确的断层和非断层占全部数据的比例;Sensitivity为敏感性,是指正确判断非断层的概率;Specificity为特异性,是指正确判断断层的概率;F1-Score为平衡F分数,其取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。由于数据集不平衡,特异性和准确性分数不能很好地表示这些指标的含义[21],AUC值是一个用来评价二分类模型优劣的常用指标,AUC值越高,通常表明模型的效果越好。各个模型指标得分如表1所示,预测结果如图2所示。

表1 各模型指标得分
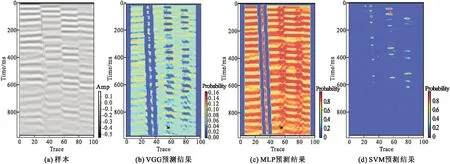
图2 预测结果Fig.2 Prediction results
数据输入到网络模型中是转为向量(矩阵)输入的。由于网络结构的限制,进入全连接层的输入维度必须是固定的,因此需要进行大小调整,使输入向量维数等于输入层节点数。数据尺寸变化需要进行插值,nearest(最近邻插值)、linear(双线性插值)和cubic(双三次插值)是最常见的三种方式,其中双三次插值计算量最大,其不仅考虑到周围四个直接相邻像素点灰度值的影响,还考虑到它们灰度值变化率的影响[22]。上述三种插值方式在图像处理中的作用已经有许多学者对其进行了分析和比较,而area(使用像素区域关系重采样)大都语焉不详,想要对比这四种插值效果的优劣。同一模型中不同插值方法预测结果分别如图3、图4、图5所示。
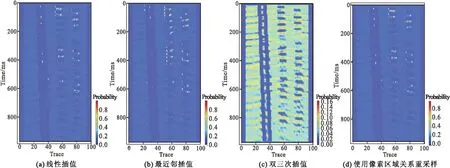
图3 VGG模型Fig.3 VGG model
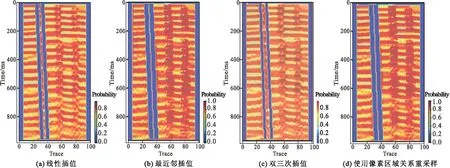
图4 MLP模型Fig.4 MLP model
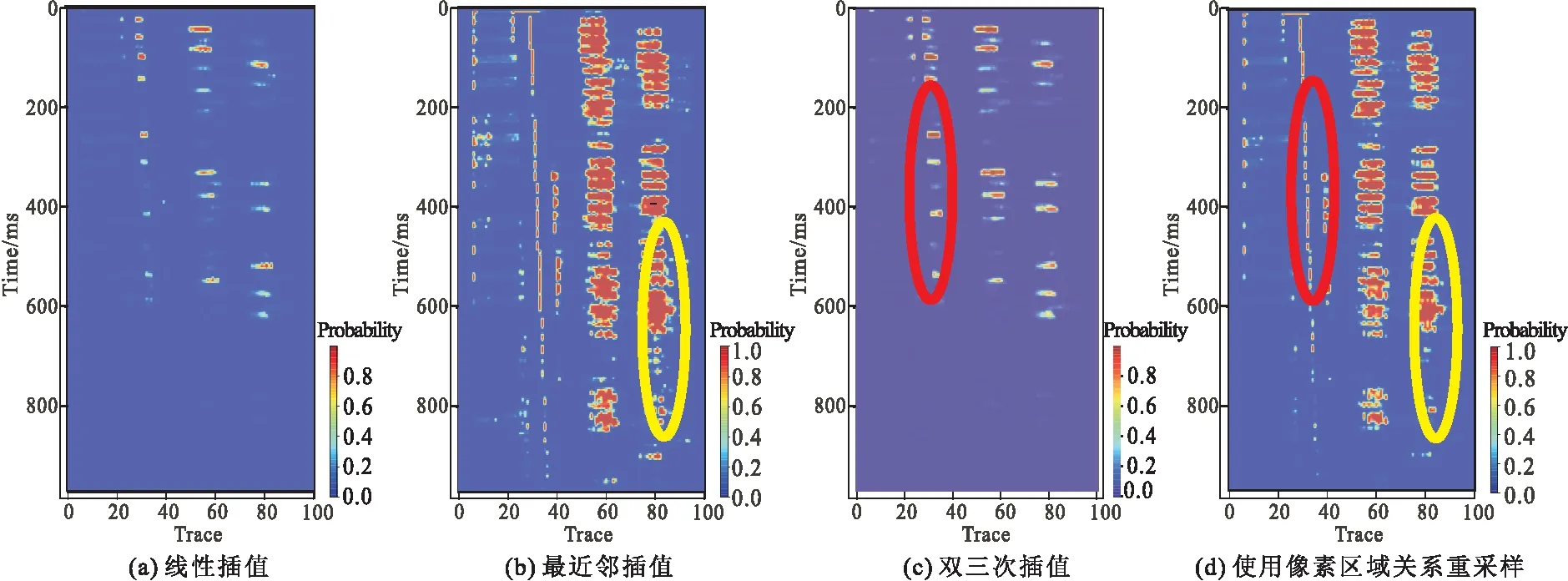
图5 SVM模型Fig.5 SVM model
4 结 论
1)相同插值条件下,根据AUC值得分和预测结果对比,SVM模型预测效果最好。
2)在数据前期处理中,改变切分图片RESIZE时的插值方式,同一模型中INTER-AREA插值法与INTER-CUBIC、INTER-LINEAR插值法相比预测结果更精细,INTER-AREA插值法与INTER-NEAREST插值法相比预测结果更纯净,即同一模型中INTER-AREA插值法下检测效果最好。
由于训练采用的是合成地震数据,无法复现所有类型真实的地质构造,断层形状是被简化过的,只有直断层,所以上述结论只适用于地质构造较为简单,断层弯曲程度较小的地区。
