HLMGAN:分层学习的多奖励文本生成对抗网络
2022-02-21孟祥福张霄雁朱金侠王丹丹
薛 琪,孟祥福,张 峰,张霄雁,朱金侠,朱 尧,王丹丹
(辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛 125105)
文本生成任务即生成连贯且有意义的文本,为机器翻译、自动对话生成、人工智能写作、文本分类等应用奠定了基础[1],是自然语言处理(Natural Language Processing,NLP)中的一项重要任务[2].为了使生成的文本更接近真实文本,生成对抗网络(Generative Adversarial Net,GAN)成为最佳选择.GAN 是近年来提出的一种深度学习网络模型,在深度学习领域中颇受关注[3].Wang 等[4]合并对象实例分割信息并提出了一种方法,允许用户交互式地编辑对象外观,提高了深度图像合成和编辑的质量和效果.Ma 等[5]提出并解决了将样本从两个独立集合转换分解为高度结构化潜在空间中的翻译实例的任务.Li 等[6]进一步扩展了文本生成图像任务,提出的StoryGAN 可以实现根据一段连续的描述文本生成对应图像的序列.生成对抗网络的本质是寻找两个不同分布之间的映射[7],这两个分布通常为先验噪声分布和真实数据样本分布,这种特质导致它在图像生成领域具有天然的优势,在图像和视觉领域取得广泛的研究和应用.但是因为生成器生成的文本数据是离散的,不可微,所以把它应用在文本生成时却遇到了困难[8];同时GAN 自动生成的文本缺乏多样性,而部分研究在解决生成文本缺乏多样性的问题的同时,忽略了生成文本的质量,即句子的准确性和流畅性.
针对上述问题,本文提出一种多奖励文本生成对抗网络(Generation Adversarial Network Based on Hierarchical Learning with Multi-reward Text,HLMGAN)模型用于生成文本任务,研究的重点是在提高文本的准确性和流畅性的同时,满足生成文本的多样性.本文工作的主要贡献如下:
(1)提出了一种HLMGAN 模型,设计了生成器的层次结构,包括传递特征向量训练模块和生成向量训练模块;
(2)在HLMGAN 模型中,判别器在给出当前生成的单词序列的情况下提取的高级特征将发送到传递特征向量训练模块,从而更好地引导生成器生成高质量的文本;
(3)将关系存储核心(Relational Memory Core,RMC)用作生成器,提高了生成器的表达能力和捕获信息能力;
(4)在HLMGAN 模型中,奖励机制舍弃黑匣子,对于重复文本分配低奖励,而对新颖流畅的文本分配高奖励,从而进一步提高了文本生成质量.
1 相关工作
生成模型提供了获取底层数据和统计信息的方法.这些模型在许多NLP 任务中起着中枢作用,例如语言建模、机器翻译和对话生成,但生成的句子往往不尽人意,例如,它们在长期语义上往往缺乏一致性,在高级主题和句法上一致性较差等.有研究通过Teacher Forcing 训练自回归模型[9].然而,该模型可能会导致暴露偏差问题即解码的行为不一致可能会导致偏差.训练自回归模型的另一种有效的解决方案是使用GAN.如果生成模型能够在训练过程中访问其自己的预测并对生成的序列具有整体视图,则可以避免上述问题.然而在生成离散序列时,生成模型的离散输出使得难以将梯度更新从判别模型传递到生成模型.Yu 等[10]在增强学习(Reinforcement Learning,RL)中将数据生成器建模为随机策略,提出SeqGAN 通过直接执行梯度策略更新来绕过生成器区分问题并使用蒙特卡洛搜索传递回中间状态.Che 等[11]提出了最大似然增强离散生成对抗网络取代直接优化GAN 目标的方法,使用随后的判别器输出对应对数似然的方法来推导新颖而低方差的目标.Guo 等[12]允许判别网络将其高级提取特征传递给生成网络,以进一步帮助指导文本生成.通过图灵测试对合成数据和各种现实世界任务进行的广泛实验表明,LeakGAN 在长文本生成中非常有效,并且在短文本生成场景中也可以提高性能.Liu 等[13]提出了一种类别感知CatGAN,用于类别文本生成的有效类别感知模型和用于训练模型的分层进化学习算法组成,直接测量实际样本与每个类别上生成的样本之间的差距,然后减小该差距将指导模型生成高质量的类别样本.
以上的方法都在改善梯度更新所带来的问题,但解决问题的同时对于生成文本的多样性考虑较少.本文提出的HLMGAN 的模型,在增加判别器的层次结构、将RMC 用作生成器的同时改进了奖励机制,提高了生成文本的多样性和质量.
2 相关概念
2.1 生成对抗网络模型生成对抗网络并不是一个完整的模型,而是一个框架,其基本结构包含一个负责生成文本的生成器G 和一个区分生成文本和真实文本的判别器D,整体模型如图1 所示.

图1 生成对抗网络结构图Fig.1 Structure diagram of generated adversarial net
GAN 中的生成器G 主要是负责生成类似于真实文本的样本给判别器D 进行验证.D 的输入由真实样本和生成样本组成,目标是判断输入的数据是来自真实样本还是生成样本.G 和D 经过对抗训练达到一个纳什平衡状态,即D 判断不出输入是来自于真实样本还是生成的样本,此时 G 能够生成与真实数据极其相似的文本.
2.1.1 生成器 生成器可以是任意能够输出样本的模型,如卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Networks,RNN)等.数据x的真实分布为Preal(x),所有数据的真实分布集合即为Preal,生成器的作用就是生成包含在Preal中的样本.假设从真实数据中取一些样本(x1,···,xi,···,xn),生成模型会根据PG(xi,θ)计算一个似然

生成模型要最大化这个似然L,这就要求模型寻找到一个最优的 θ∗,让PG最接近Preal.
2.1.2 判别器 判别器可以分解为特征提取层(包括输入层、卷积层、池化层,主要完成生成文本序列的高维特征提取)和一个分类器.判别器的训练属于有监督学习,在固定生成器后,采用训练数据作为正样例,生成数据作为负样例,进行标准化处理,混合后的数据通过判别器得到输出值,求出输出值和目标值的误差,使用交叉熵来优化判别器的参数.
2.2 基于生成对抗网络的文本生成模型基于生成对抗网络的文本生成模型整体流程如下:生成模型以噪声输入,经过一系列非线性变换获得了文本向量特征,再将特征转化为文本,使用判别器的判断作为生成器调整参数的依据.
假设输入的文本是“路边的花真漂亮”,经过词嵌入之后,变成形如[−0.269 9,−0.4,0.740 1,…,−0.090 2]的真实向量.算法目的是生成与输入向量意思一致但是形式多样的文本,如“这朵开在路边的花真鲜艳”.将真实向量[−0.269 9,−0.4,0.740 1,…,−0.090 2]输入到生成器后,输出生成向量[−0.5,−0.25,0.6,…,−0.3].将生成向量输入进判别器与真实向量进行比较.通过卷积层、池化层等操作,向生成器回传生成模型存在的偏差.生成器再对向量值 [−0.5,−0.25,0.6,…,−0.3]进行微调,从而生成新的生成向量[−0.37,−0.32,0.69,…,−0.15].这样反复执行达到判别器分辨不出传入的序列是生成器生成的文本还是真实文本,基于生成对抗网络的文本生成模型结构如图2 所示,其中本文的激活函数采用softmax 函数,该函数可以将输出映射到(0,1)区间内.

图2 基于生成对抗网络的文本生成模型结构Fig.2 Text generation model structure based on generative confrontation network
2.3 关系存储核心关系存储核心(Relational Memory Core,RMC)的基本概念是考虑一组固定的内存插槽(例如内存矩阵),并允许自我关注机制[14]在这些内存中进行交互.存储容量的增加提高表达能力和捕获信息的能力.在状态t给定一个新的词汇xt,由嵌入向量Ext表示.生成器中输入向量xt由Ext与Wx线性变化组成:

考虑存储器矩阵Mt,图3 给出了如何在状态t通过xt从Mt更新到Mt+1.其中Multi-Head Attetion(MHA)表示多头注意力机制,Multi-Layer Perception(MLP)表示多层感知机,Ot表示生成器G 的输出.

图3 RMC 结构图Fig.3 RMC structure diagram
3 问题定义和解决方法
3.1 问题定义本文将文本生成问题形式化为顺序决策过程.具体来说,在每个状态t,模型将先前生成的单词集合作为其当前状态,表示为St=(x1,···,xi,···,xt),其中xi表示给定词汇表V 中的单词.本文使用一个采用随机策略的生成器G,经过训练得到下一个单词xt+1,同时还训练判别模型D,通过比对生成向量与真实向量得到引导信号,将引导信号回传给生成器调整生成整个句子St时的参数.最终得到的St与输入文本意思一致的多样性且具有高质量.
3.2 解决方法为了解决句子过长导致引导信号信息量较少的问题,本文提出HLMGAN 框架,使判别器D 向生成器G 提供当前句子St在判别模型D 中的附加信息ft.在HLMGAN 模型中,使用分层结构作为一种可以将真实文本信息传递到G生成过程中的有效机制.此外,因RMC 保证了更大的存储容量和更好的捕捉长期以来关系的能力[13],故使用RMC 模型用做生成器中传递特征向量训练模块和生成向量训练模块的训练.奖励部分由句子级别奖励和单词级别奖励组成,可以实现对高级的句子给予较高的奖励,对于正确但并不新颖的句子给予非零但是较低的奖励.
4 HLMGAN 模型具体实现
本文对生成对抗网络基本结构进行了改进,HLMGAN 的示意图如图4 所示.其中M(·;Qm)表示传递特征向量训练模块由参数为θm的RMC 实现,W(·;Qw)表示传递特征向量训练模块由参数为θw的RMC 实现.

图4 HLMGAN 结构图Fig.4 Schematic diagram of HLMGAN structure
4.1 判别器使用参数ϕ为Dϕ作为学习奖励函数,可以分解为特征提取层F(·;ϕf)和一个具有权重向量ϕl的sigmoid 分类器.即给定一个生成序列s作为输入,可以使用

其中,ϕ=(ϕf,ϕl),sigmoid(z)=1/(1+e−z),T 表示 转置,f=F(s;ϕf)表示特征提取层得到输出的高维特征向量.
当生成器G 准备生成下一个词的时候,生成器会补充当前生成的部分序列,形成完整的输入序列s,并传递给判别器D.判别器D 获取到s后,经过特征提取层得到输出的高维特征向量f,把它传递到下一步的分类层和生成器G 中的传递特征向量训练模块用来指导文本生成.
具体来讲,当向判别器输入“路边的花真漂亮”,经过词嵌入之后,将输入序列中每个词转化为向量表示,变成形如[−0.269 9,−0.4,0.740 1,···,−0.090 2]的真实向量.输入矩阵会进入卷积核提取短语的语义信息.然后进入池化层,通过对特征向量做最大池化处理,把最后的结果拼接在一起,大小为所有卷积核数量的总和.接着将得到的特征向量传递给分类层,在对抗训练中,这个特征向量会作为反馈信息指导生成器生成文本.最后的分类层把传递来的特征向量做softmax 分类,得到的结果作为奖励值传递给生成器.
4.2 生成器在生成过程每个步骤t中,为利用从判别器D 中传递的特征向量f,把生成器G 分成传递特征向量训练模块和生成向量训练模块两个层次结构.具体来说,引入一个传递特征向量训练模块,在每个状态t都将提取的特征向量ft作为其输入,并输出目标向量gt,然后将其输入到生成向量训练模块中,指导下一个单词的生成,以便接近F(s;ϕf)中的较高奖励区域.接下来,本文将在HLMGAN 中描述详细的生成器模型,然后说明如何使用D 的引导信号训练传递特征向量训练模块和生成向量训练模块.
4.2.1 生成过程 传递特征向量训练模块和生成向量训练模块从全零隐藏状态开始,分别表示为由于基于长短期记忆循环神经网络模型(Long Short Term Memory,LSTM)的生成器可能缺少用于文本生成的足够的表达能力,而RMC 如上文提到采用MHA 允许记忆交互的特点,能够更好地表示记忆间的联系,从而使模型具有在时间域上进行关系推理的能力,可以改进这种缺陷,因此传递特征向量训练模块和生成向量训练模块采用RMC 代替传统的LSTM.
在每个步骤中,传递特征向量训练模块都会从判别器D 接收传递的特征向量ft,并将其与传递特征向量训练模块的当前隐藏状态进一步结合以生成目标向量gt:

其中,M(·;θm)表示传递特征向量训练模块由参数为 θm的RMC 实现,是RMC 的递归隐藏向量.为了合并传递特征向量训练模块产生的目标,对最近的c个目标求和后执行权重矩阵为Wψ的线性变换ψ,生成k维目标嵌入向量:

给定目标嵌入向量wt,传递特征向量训练模块将xt设置为输入,输出矩阵Ot,将其与wt通过矩阵乘积进一步组合,通过softmax 以确定当前状态下:

其中,W(·;θw)表示传递特征向量训练模块由参数为 θw的RMC 实现.Ot,wt矩阵表示所有单词的当前向量,因此Ot,wt得出所有单词的计算对数,α是控制生成熵的温度参数.
4.2.2 生成器的训练过程 使用策略梯度算法端到端的方式训练G.本文目标是在HLMGAN 中传递特征向量训练模块能够捕获一些有意义的模式.因此,分别训练传递特征向量训练模块和生成向量训练模块,其中传递特征向量训练模块被训练来预测区别特征空间中的有利方向,而生成向量训练模块本质上奖励遵循这样的方向.在训练过程中,生成器G 和判别器D 交替训练.同时在生成器中,传递特征向量训练模块M(·;θm)和生成向量训练模块W(·;θw)交替训练.
4.3 奖励机制在奖励机制方面,本文舍弃了传统的蒙特卡洛搜索奖励机制,采用Sentences and Words(SW)奖励机制,包括句子级别奖励和词级别奖励两部分[15],分别说明如下.
4.3.1 单词级别的奖励 由于句子中不同单词的奖励应该不同,本文首先使用单词级别的奖励,公式如下:

即输入生成向量和真实向量,对应相乘完成交叉熵计 算.输入形 如[[0.66,0.057,0.283],[…],[0.454 2,0.216 9,0.329]]的3×3 矩阵,每一行加和为1.对softmax 的结果取自然对数,输出形如[[−0.415 5,−2.864 8,−1.262 3],[ …],[−0.789 3,−1.528 5,−1.111 7]的3×3 矩阵.结果是把上面的输出与Label 对应的值取出,取负,再求均值.设Target 是[0,2,1],即第一行取第0 个元素,第二行取第2 个,第三行取第1 个,去掉负号,结果是:[0.415 5,1.094 5,1.528 5].再求均值,则输出结果为1.012 833.
4.3.2 句子级别的奖励 对于一个有K个字的句子yt而言,句子级别的奖励是每个单词奖励的平均值:

现有给予判别器奖励主要问题是奖励不能准确反映文本的新颖性.首先,对于高新颖性文本的奖励很容易达到饱和,这几乎无法区分新颖文本之间的区别.其次,判别器在识别生成的文本时可以很容易地达到很高的准确性,表明分类器仍然无法分辨新颖度较低的文本之间的区别.根据实验结果分析表明,SW 奖励机制可以更好地区分新颖性文本和低端性文本,而且不会出现饱和问题.即高新颖性文本的奖励很高且不会饱和,低新颖性文本的奖励很小但是具有区分性.
该奖励机制使用O(T)的时间复杂度来计算所有单词的奖励,与时间复杂度为O(T2)的蒙特卡洛搜索奖励机制相比,更有效率.
4.4 算法流程在确定了判别器,生成器、目标函数和奖励机制后,本文通过算法1 来训练HLMGAN.
算法1
输入预处理后的真实文本.
输出跟预处理后文本意思相近但又不完全一致的文本.
步骤 1使用随机权重θm,θw,ϕ初始化Gθm,θw,Dϕ;
步骤 2预训练Dϕ使用S作 为正样本,Gθm,θw作为负样本,并使用Dϕ的传递信息进行预训练,交错执行两次预训练,直到收敛为止;
步骤 3产生序列Y1:T=(y1,…,yT)~Gθ,从Dϕ存储传递信息ft,并从SW 奖励中获得Q(ft,gt),同时从传递特征向量训练模块中获得生成目标向量gt,并更新两个训练模块参数;
步骤 4使用当前Gθm,θw生成负样本并与给定的正样本S组合,通过公式对k个epochs 进行判别器Dϕ的训练.
5 实验及评价
为了验证所提算法的有效性,在两个离散序列生成任务上进行了实验,并将其与其他先进的方法进行比较.
5.1 比较模型及评价方法实验阶段,与HLMGAN进行比较的基本模型有以下几种:MLE 训练的LSTM,SeqGAN,LeakGAN 和MaliGAN.
对于文本质量方面,本文在合成数据集采用的评价标准是负对数似然度(Negative log-likelihood,N),在EMNLP2017 WMT 数据集采用的评价标准是双语互译质量评估辅助工具(Bilingual evaluation understudy,BLEU).
本文实验采用两个评价标准如下:
(1)负对数似然度 因为合成数据集是模拟的生成序列,所以使用的评价标准是负对数似然度Noracle,评价标准公式如下:

其中,Goracle表示真实数据分布,q 表示生成的近似文本.在合成数据实验中,假设随机初始化的RMC 模型已经学到了真实的自然语言的数据分布,那么Noracle表示真实数据和生成数据之间的交叉熵,即HLMGAN 网络中生成器生成的数据分布与真实自然语言的数据分布的差距,值越小表明生成的数据分布越接近真实分布,生成的文本质量越高.
由于Noracle不能评价真实世界的数据实验,所以采用BLEU 进行评分[16].
(2)双语互译质量评估辅助工具(BLEU)对于EMNLP2017 WMT 数据集采用的评价标准是BLEU.该可以衡量机器翻译文本和参照文本两者的相似程度,取值范围在0 到1,取值越大机器翻译的质量越高.
在文本多样性方面,参考文献[16],采用Backward BLEU(BBL)来衡量.它以生成的样本为参照,由BLEU 对每个测试样本进行评价.
5.2 实验结果不同学习率的影响.本文分别更改生成器和判别器的学习率,设置生成器学习率(gen_lr)为0.000 5 至0.01 和判别器学习率(dis_lr)为1×10−4~5×10−5进行实验对比,部分实验结果如表1 所示(表格顺序由Noracle从小到大排序得出).最终设置gen_lr=0.005,dis_lr=5×10−5和epoch=200进行实验.

表1 参数设置结果展示Tab.1 Display of parameter setting result
5.2.1 合成实验 为了模拟真实世界的结构化序列,我们遵循Guo 等[12]考虑了一种语言模型来捕捉标记的依赖关系.使用遵循正态分布N(0,1)的随机初始化的RMC 作为真实模型来生成实际数据分布Goracle(xt|x1,···,xt−1),用它生成10 000 个长度为20 的序列作为生成模型的训练集S,用于实验.图5 给出了训练曲线,表2 给出了整体实验结果.从结果可以得出,虽然在预训练阶段,HLMGAN 并没有太大的性能优势,但是在对抗阶段,HLMGAN 表现出非常好的收敛速度,最小值低于以往的结果.并且epoch 在160 之后的阶段,HLMGAN 的波动相比于HLMGAN 基本模型LeakGAN 较为平稳.实验结果表明基于分层学习和SW 奖励机制的框架在生成文本方面的有效性.
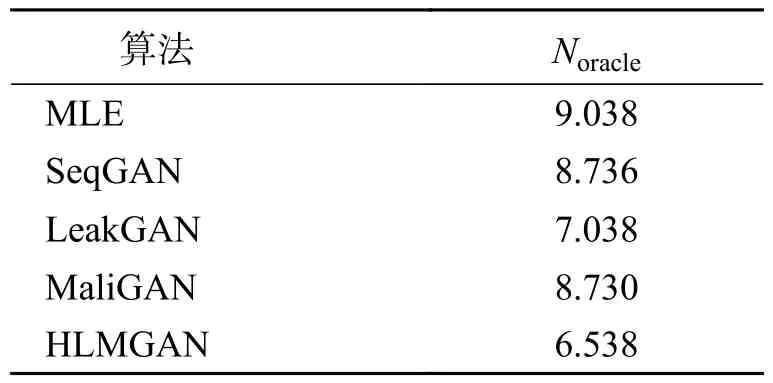
表2 不同算法的N oracle 性能Tab.2 Comparison ofN oracle performance of different algorithms

图5 4 种文本生成模型训练曲线Fig.5 Training curves of four text generation models
5.2.2 EMNLP2017 WMT 新闻该 实验选 择EMNLP2017 数据集作为长文本语料库.从原始数据集中选取新闻部分.新闻数据集由646 459 个单词和397 726 个句子组成.在此基础上,通过删除频率低于4 050 的单词、包含这些低频单词的句子及长度小于20 的句子来预处理数据.然后随机抽取20 万句作为训练集,另外1 万句作为测试集.同时,为保证实验的准确性,增加DGSAN[17]和CoTGAN[18]与模型的比较.表3 给出训练结果.在所有测试指标中,HLMGAN 表现出良好的性能提升.BLEU 指标高于对比模型.在保证BLEU 分数高的前提下,Ngen(越低越好)和Ndiv(越高越好)与对比模型(SeqGAN 和LeakGAN)相比,最高分别提升了约0.344 和0.715,说明HLMGAN 在文本生成多样性和文本生成质量方面有所提高.

表3 EMNLP 数据集的BLEU 评分表现Tab.3 BLEU scores performance on EMNLP data set
为了说明RMC 替换LSTM 和使用SW 奖励机制的有效性,对算法HLMGAN 进行了消融实验.将HLMGAN 中RMC 去掉,使用LSTM,生成HLMGAN_RMC;将HLMGAN 中SW 奖励机制替换掉,生成HLMGAN_SW.结果如表4 所示.与LeakGAN 模型相比,两个改进部分均有所提高,说明RMC 和SW 奖励机制对模型的改进有所帮助.

表4 HLMGAN 以及分解算法在EMNLP 数据集的BLEU评分表现Tab.4 BLEU scores performance of HLMGAN and decomposition algorithm on EMNLP data set
6 结语
本文提出了一种HLMGAN 模型,在此模型中通过传递判别器提取的特征作为逐步指导信号并采用SW 奖励机制,对于重复文本分配低奖励,而对新颖流畅的文本分配高奖励,以指导发生器更好地生成文本.在合成数据和真实世界数据的实验中,HLMGAN 在BLEU 得分比以前的解决方案有明显提升并且BBL 得分也有所进步,即在生成文本多样性上有所改进.接下来将使用HLMGAN 模型结合医学领域数据,尝试改善医学领域部分数据缺少而在深度学习训练效果不好的问题.
