面向变电设备金属锈蚀检测的分层嵌套标注方法
2022-02-21黄树欣张柏礼
张 昭,张 沛,曹 勇,杨 莎,黄树欣,孙 瀚,张柏礼**
(1.智能电网保护和运行控制国家重点实验室,江苏 南京 211106;2.南瑞集团,江苏 南京 211106;3.国网山东省电力公司 枣庄供电公司,山东 枣庄 277099;4.东南大学 计算机科学与工程学院,江苏 南京 211189)
变电设备因长期暴露在户外环境中,容易产生金属锈蚀.金属锈蚀是金属材料表面和内部微观结构与腐蚀环境相互作用而引起的劣化结果[1],会对变电设备安全运行和使用寿命产生不利的影响.因此,需要通过定期/不定期变电设备巡检,及时发现金属锈蚀并及时解决.除了依赖人工肉眼检测外,金属锈蚀的非破坏性无损检测技术是一种常见的解决方法,如X 射线[2]、红外热成像[3-4]以及电磁图[5]等.但上述方法均对检测环境、检测仪器、检测人员专业水平有着较高要求.目前,利用卷积神经网络(Convolutional Neural Networks,CNN)[6]对RGB 图像自动提取特征,再进行检测定位成为金属锈蚀检测的一种趋势.其中,以Faster R-CNN[7],YOLO[8-9]为代表基于区域建议目标检测算法在具有较高精度的同时,也具有很好的检测速度.
然而,金属锈蚀存在普遍的形状不规则性和可拆分性,使得训练样本标注时,标注者面临着很多歧义,难以实现标注过程标准化和标注结果一致性,标注质量不稳定,使得模型在训练中难以有效捕获金属锈蚀内在特征,直接影响目标检测模型的效果[10].针对上述问题,本文提出一种分层嵌套标注方法:首先,采用较大的矩形框对锈蚀出现范围内进行大面积标注,只要在视觉上是连续的、相邻的不能清晰划分的锈蚀都用一个较大的矩形框标注;接着,在第一步的标注框内,对那些特征非常明显并具有相对独立性的区域进行二次标注,形成第二层的内部嵌套标注.这种标注方法简单直白,可以有效保证每个训练样本标注结果的唯一性,易于标注者掌握和标准化,利于形成稳定的标注质量,而且这种标注突出了锈蚀的特征并一定程度上增加了被标注锈蚀的样本数量,实现了数据增强,使得模型在训练中更容易捕捉到锈蚀的特征.
本文的主要贡献如下:
(1)针对变电设备的金属锈蚀精准检测,提出了新的数据集标注方法——分层嵌套标注方法;
(2)在金属锈蚀检测领域,引入了检测框融合算法,实现检测结果归一化;
(3)针对金属锈蚀检测领域的特点,引入了新的查准率、召回率定义.
1 相关工作
自AlexNet[11]在ImageNet 大赛上展现优异成绩后,利用CNN 进行特征提取并进行图像分类的方式得到了快速发展,广泛应用于各种领域的图像识别、目标检测.针对金属锈蚀检测,目前以CNN为核心的目标检测模型中最具是代表性是Faster RCNN 和YOLO,它们通过预定义不同尺寸形状的anchor 来检测不同尺寸形状的目标区域,可以同时解决分类和定位的问题.
目标检测模型的训练效果高度依赖于足量的和高质量的数据集,针对目标检测任务的图片标注主要有2D 边界框/矩形框(Bounding Boxes)、3D边界框/长方体(Cuboids)、多边形(Polygons)3 种标注方法.3D 长方体标注可以显示目标的深度,用于立体图像中的识别对象,对于金属锈蚀的检测一般不涉及对象的深度,故未采用这种方法.矩形框标注相对简单而常用,但标注的矩形区域通常含有非目标对象,尤其金属锈蚀具有明显的非规则性,导致标注的矩形框内可能存在大面积的非锈蚀区域,训练的模型难以学习到有效的锈蚀内在特征,进而影响识别精准度.而采用多边形方法可以很好地吻合目标的形状,解决上述不足,但其标注非常耗时,成本非常高,因此实践中很少被用于数据集的大规模标注.
针对金属锈蚀的形状不规则性导致标注结果可能包含大面积非锈蚀区域的问题,文献[12]首先通过滑动窗口截取较小的区域,以此来降低窗口中含有的非锈蚀区域;接着,再使用小型的CNN 依次判断每个窗口是否为锈蚀区域.但是这种将一张图片切分成多个微小的窗口,使得模型只关注窗口中的局部像素数据而忽略了全局像素数据.其感受野过低导致模型学习到的特征过于局部、片面.同时,窗口的尺寸导致设计的CNN 不能太大,模型的学习能力受限.因此,该方法容易产生误判,检测效果不佳.
2 分层嵌套标注
2.1 训练样本标注方法在变电设备中,由于设备大小不一以及锈蚀蔓延等问题导致锈蚀区域的形状大小具有不规则性.同时,金属锈蚀往往又具有可拆分性,其既可以作为一整片锈蚀的组成部分,又可以看成一个个独立的锈蚀区域.针对金属锈蚀这种特性,在矩形框标注的使用方面,一般有两种不同策略的标注方法:①采用尽可能小的标注框标注锈蚀区域;②采用尽可能大的标注框标注锈蚀区域.
采用方法①可以尽可能减少矩形框中包含的非目标区域,但是金属锈蚀蔓延特性会导致一块锈蚀区域与邻近的非锈蚀区域之间存在一段锈蚀程度逐渐减轻的锈蚀蔓延区域,使得标注者面临着很多歧义,如直接忽略,往往会漏掉一些锈蚀蔓延区域,如图1 中标注结果附近存在部分未标注的锈蚀区域.然而锈蚀蔓延是金属锈蚀的一个非常重要特征,如果选择标注,标注过程则难以标准化并导致标注结果的多样性,模型训练效果不佳.

图1 方法1 的标注结果Fig.1 The annotation result by method 1
若采用方法②(尽可能大的标注框)对训练集进行标注,因为采用尽可能大的标注框以标注所有的锈蚀区域,则不存在方法①中难以标注的问题.采用方法②标注的结果如图2 所示.
但是方法②也存在一定的不足:除了增加了矩形框中包含非目标区域外,由于变电设备的器件具有可拆分性,这使得图2 中作为锈蚀区域一部分的螺帽在图3 中却作为独立的锈蚀个体并被标注.即可拆分性导致同为锈蚀的螺帽具有不同的标注结果;而在图2 中,标注框内右上角的锈蚀螺帽与右下角的非锈蚀螺帽均没有被独立标注,这意味着不同类型的螺帽存在相同的标注结果.综上所述,方法②在标注过程中存在二义性,也会导致模型训练的不稳定.

图2 方法2 的标注结果Fig.2 The annotation result by method

图3 金属锈蚀的可拆分性Fig.3 The detachability of metal corrosion
为此,本文提出一种分层嵌套标注方法作为金属锈蚀的第③种标注方法:首先,采用尽可能大的标注框对锈蚀进行大面积标注,只要在视觉上是连续的、相邻的不能清晰划分的锈蚀都用一个较大的矩形框标注,如图4 中的框GT1;然后,在第一步的标注框内,对那些特征非常明显并具有相对独立性的区域进行二次标注,形成第二层的嵌套标注,如图4 中的GT2、GT3.由此可见,分层嵌套标注不仅解决了方法①在标注过程中产生漏标的问题,而且解决了方法②在标注过程中产生歧义的问题.同时,采用分层嵌套标注方法后,大大增加了标注框数目进而达到数据增强的效果,一定程度上抵消了矩形框中包含非目标对象带来的负面影响.

图4 方法3 的标注结果Fig.4 The annotation result by method 3
2.2 检测框融合算法虽然分层嵌套标注法可以有效解决标注遗漏和标注歧义的问题,但也出现了标注框嵌套的新问题.因此,采用分层嵌套标注的方法训练得到的模型,其检测结果中也会出现检测框嵌套的新问题,如图5(a)中的检测框A、B.这对检测结果的可视化展示和模型评价指标计算都会产生干扰.虽然不影响检测的实际效果,但与主流的检测结果展示方式不符.为此,本文对检测结果进行了转换处理:依次判定任意两个检测框是否相交,如果相交则以二者的外接多边形进行替代,直至检测结果中任意两个检测框都不相交.即使用图5(b)的橘色多边形C 代替矩形框A、B 作为最终检测结果.
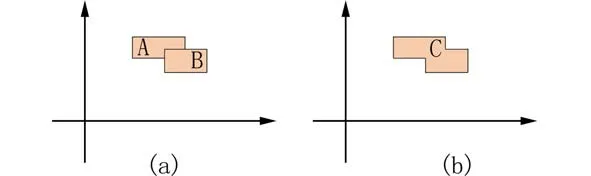
图5 矩形框融合示意图Fig.5 The diagram of merging rectangles
3 实验结果与分析
3.1 评测指标通过第2 节讨论可知,使用3 种不同方法标注同一锈蚀样本,可能会出现不同的标注结果.因此,采用方法①、方法②与方法③制作的测试集不可能相同.即3 种标注方法训练得到的模型无法采用统一的测试集以比较优劣.针对上述问题,本文以多边形标注方式对测试集进行标注,以此来制作统一的测试集.其标部分标注样本如图6所示.
图6 多边形标注的标注结果Fig.6 The annotation result by polygons
在本次实验中,采用模型的查准率和召回率作为评价指标.根据检测结果是否正确可以将分类结果划分为4 类.如表1 所示.

表1 二分问题混淆矩阵Tab.1 Confusion matrix for binary classification
在目标检测中,通常采用交并比对检测结果正确与否进行判断.交并比计算的是“检测的边框”和“真实的边框”的交集和并集的比值.通常在实际工程项目中,设定交并比的阈值为0.5,即交并比大于0.5 时,可以认为机器检测到了目标.对于本文而言,由于测试集是以多边形的方式进行标注,一个检测框与标注框之间的交并比往往很低,如图7所示,检测框与任意一个标注框的交并比都低于0.5,因此不适合直接采用交并比来判断检测结果是否正确.

图7 检测结果中含有大量的非锈蚀区域Fig.7 Existing a large non-corroded area in detection result
为此,本文根据锈蚀检测的特点,通过以下标准来计算模型的查准率和召回率.
(1)为了降低图片尺寸的影响,在计算之前将所有图片尺寸进行归一化处理.召回率的计算公式如下:

(2)如图7 所示,即使模型很好地检测到了锈蚀区域,但检测结果中仍含有大量的非锈蚀区域.因此,将检测正确的总锈蚀面积与检测的总面积之比作为查准率计算公式,得到的查准率往往很低,无法真实描述模型的优劣.针对上述问题,本文将从检测数目的角度出发来计算查准率,即将含有锈蚀的检测结果视为检测正确,并以检测数目来计算模型查准率.因此,查准率计算公式如下:

最终,本文通过制作统一的测试集,保证了3种标注方法可以在同一个测试集中进行横向对比.通过上述两种计算公式,使得其能够更加真实地描述模型的检测效果.
3.2 实验环境本文的硬件平台是AMAX GPU 服务器(I7-9800,32GBRAM,RTX2080Ti),以PyTorch为深度学习框架,以Faster R-CNN,YOLOv5[13]为实验的检测模型,以查准率、召回率为训练模型的评价指标.
3.3 实验实验采用以大规模训练集训练得到的骨干网进行模型参数初始化,再通过迁移学习微调的方式训练锈蚀检测模型[14-15].
首先,本文采用多边形标注的方式标注了199张图片作为测试集,使用3 种标注方法分别标注了1 180 张图片作为训练集;接着,分别以VGG16[16],Res101[17]为骨干网,SGD 为优化器,训练了Faster R-CNN 检测模型、以DarkNet53[9]为骨干网,SGD为优化器,训练了YOLOv5 检测模型.最后采用检测框融合算法将检测结果中的相交检测框融合处理后,再计算检测模型的查准率、召回率.训练中采用的超参数如表2 所示.
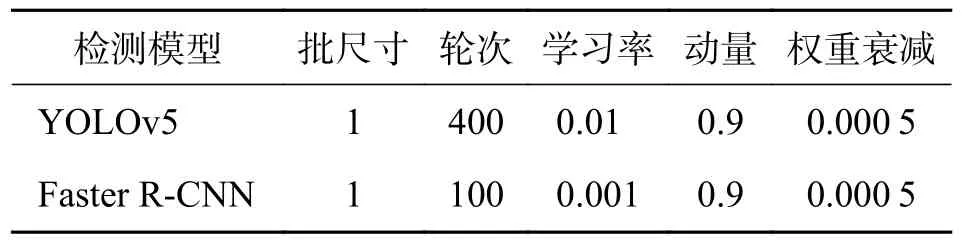
表2 模型的超参数Tab.2 Hyper-parameters of these models
3.4 实验结果分析每个模型在不同标注方法下的实验结果如表3 所示.通过实验结果发现:Faster R-CNN 相较于YOLOv5 具有更高的召回率,但其查准率也更低;而在Faster R-CNN 模型中,相较于VGG16,以Res101 为骨干网具有更高的召回率,而查准率则略微下降;用分层嵌套标注的样本进行训练后,YOLOv5 和Faster R-CNN 在查准率几乎不变的同时提高了模型的召回率;而Faster R-CNN+Res101 的召回率达到了所有实验的最大值,84.61%.
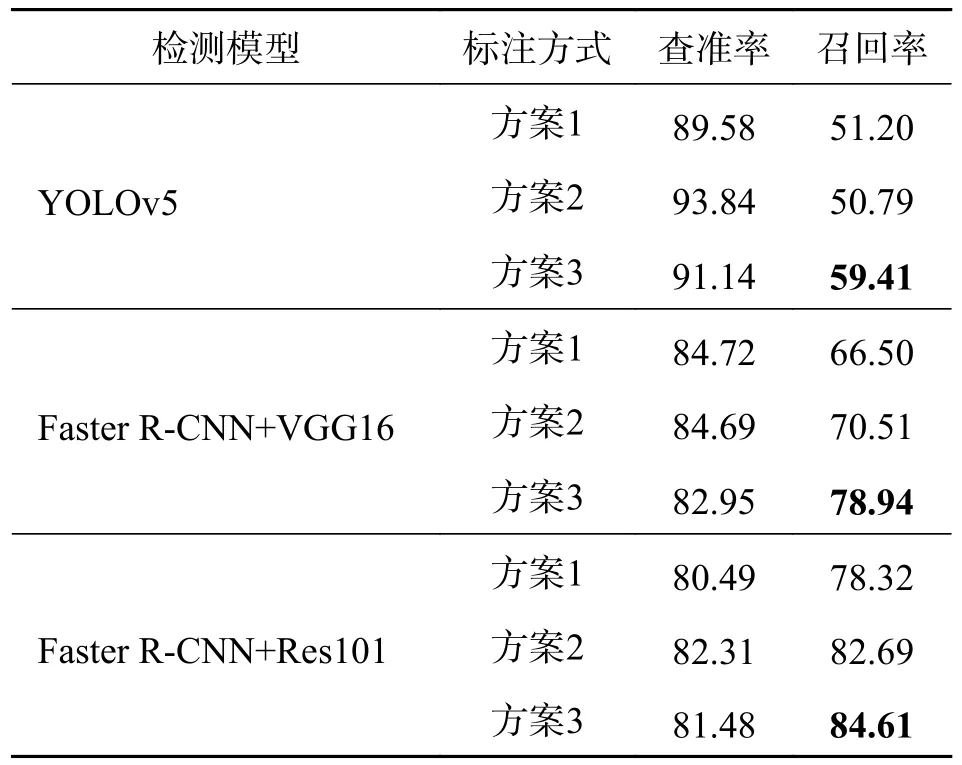
表3 不同标注方法下不同模型的实验结果Tab.3 Experimental results of different models with different annotation methods %
结合实际中变电站对金属锈蚀检测需求和处理流程,对实验结果做进一步分析:
(1)YOLOv5 模型虽然具有最高的查准率,但同时也具有最低的召回率.而在实际应用中,往往需要对模型的检测结果进行人工复核.因此,相较于拥有更高的查准率,实际应用中更倾向于锈蚀检测模型能够拥有更高的召回率,尽可能不要出现锈蚀的遗漏.
(2)在Faster R-CNN 中,Res101 在查准率略低于VGG16 的情况下,其召回率却更高.因为Res101 模型结构相较于VGG16 拥有更多的卷积层,也更加复杂,因此也能学习到更多的特征.因此,在同一检测框架中,骨干网的特征提取能力越强,锈蚀检测效果则越好.
(3)采用分层嵌套标注后,各个模型的召回率相较其他两个方案都得到了提高,如图8 所示.
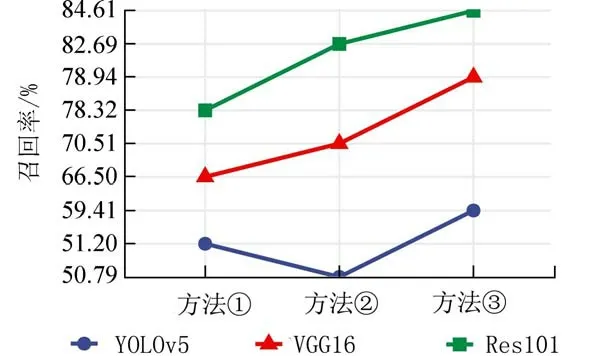
图8 不同标注方法下不同模型的召回率Fig.8 The recall of each model with different annotation method
实验中使用的模型都是基于区域建议的目标检测模型,即通过预定义不同形状尺寸的anchor来检测不同形状尺寸的目标.因此,相较于方法①(尽可能使用小的标注框),分层嵌套标注法增加了较大标注框的数量.其在不影响小尺寸anchor 的检测能力的同时,提高了大尺寸anchor 的检测能力,进而提高了模型的综合检测能力.相较于方法②同理.最终,采用分层嵌套标注后,模型的检测效果会得到提升.综上所示,采用分层嵌套标注方法的Faster R-CNN+Res101 模型检测效果最好,其部分锈蚀检测结果如图9 所示.

图9 Faster R-CNN+Res101 检测结果Fig.9 Outputs results of Faster R-CNN+Res101
4 结语
本文提出了一种新型的分层嵌套标注方法,确定了锈蚀样本的标注标准并解决了标注结果不一致的问题.同时,针对检测结果嵌套的现象,仅需要对其进行简单后处理即可解决.采用该方法后,各模型的锈蚀检测能力均得到了提高,为锈蚀等其他不规则样本的数据标注提供了新思路,下一步可以应用于变电站巡检机器人平台,实现对锈蚀等变电设备缺陷的智能检测.
