一种基于融合决策TOPSIS模型的NILM算法评价
2022-02-17王雅倩周东国胡文山
王雅倩,周东国,胡文山
(武汉大学 电气与自动化学院, 武汉 430072)
0 引 言
非侵入式电力负荷监测(Non-intrusive Load Monitoring)技术的核心是辨识算法,主要包括优化方法[1]、监督学习方法[2-4]、非监督学习方法[5-6]三类。优化方法以整数规划为依据,建立负荷辨识模型;而监督学习和非监督学习以模式识别为理论支撑,其性能在一定程度上各具优势,成为目前研究的热点。随着国家电网、南方电网等电力单位的大力推进,如何开发和利用现有算法成为关注的焦点。为此,研究人员提出了各种性能评价测度来评估分解方法的性能。文献[7]提出将准确识别电器负荷、开关事件的比例作为性能评价测度。文献[8]根据精确度和召回率提出了F1度量的评价测度,精度是分解后的相关设备的功率值与分解后设备总的功率值的比率,召回率是分解后的相关设备的功率值与实际中设备的相关功率值的比率。文献[9]用ROC曲线对非侵入式电力负荷分解算法进行性能评估。文献[10]对该问题进行了较为系统的研究,建议分别考虑检测准确度和分类准确度,提出了总体和个体负荷的误检率和漏检率两个测度,并给出了相应的检测准确度、分解准确度和总体检测度的计算公式。近年来,文献[11]在2014年建立了ECO负荷数据库,其采用召回率、准确率、精确率、总能耗相对误差、均方绝对误差等五项评价指标对各个非侵入式负荷算法模型在同一负荷数据集中进行评价。文献[12]介绍了包括召回率、准确率、精确率、F1分数、NDE(Normalized Disaggregation Error)分数以及实时噪音等在内的多种评价指标,并简单阐述了各指标优缺点和应用。
目前,准确率等直观的单一效益性指标仍是衡量和验证算法可行性和可靠性的主流方案,但是非侵入式负荷辨识易受训练数据等因素的影响,单一的准确率等指标并不足以说明问题,甚至出现识别准确率畸高而实际辨识效果很差的情况。此时利用单一的准确率指标会出现决策失误,不足以反映识别效果。此外,在实际应用中往往需要同时兼顾算法的多种性能,而同一算法在不同指标下的性能表现并不相同,因此,如何针对实际情况和侧重需求建立综合的评价体系也成为待解决的问题之一。
为此,文章提出一种基于融合决策的TOPSIS[13](Technique for Order Preference by Similarity to an Ideal Solution)模型评价非侵入式算法。它在传统的TOPSIS模型上利用组合赋权法集AHP主观赋权和变异系数法客观赋权的优点于一体,兼顾专家经验、工程实际以及客观指标数据价值,避免了传统TOPSIS模型中存在的权重确定单一易造成评价失真等问题。该模型基于TOPSIS方法集成其他方法的强大能力[15-17],采用融合权重为各指标赋权再通过TOPSIS法对有限负荷辨识算法进行决策排序,择优选择,并将该方法应用于实际工程,为负荷辨识算法的综合评价提供一种新的解决方案。
1 TOPSIS法
TOPSIS法[13-14]最初是由Hwang和Yoon在1981年提出,全称为逼近于理想解的排序方法,其主要思想是通过计算评价对象与理想化目标和负理想化目标的接近程度对评价对象进行排序以确定其相对优劣程度,从而选择最佳方案。具体步骤如下:
(1)设某决策问题有M个评价对象构成决策方案集{X1,X2,…,Xm};衡量方案属性优劣的n个评价指标,则M个评价对象的n个原始评价指标数据构成矩阵X。
(1)
(2)将原始指标进行规范化处理得到规范化矩阵F。设xij为X矩阵中i个方案中第j个指标的值,其规范化后的值记为fij。
(3)
(3)构造加权规范化矩阵。设由决策者给定的权重向量ω=[ω1,ω2,…,ωn]T,利用各指标权值和规范化矩阵F构造加权规范化矩阵R。其中,rij为加权规范矩阵R中第i个方案中第j个指标的值。
rij=ωjfij(i=1,2,…,m;j=1,2,…,n)
(4)
(4)确定正、负理想解的集合R+、R-。指标中越大越好的为效益型指标,越小越好的为成本型指标。以效益型指标的最大值和成本性指标的最小值构造R+、R-。
(5)
(5)计算各个方案分别与正、负理想解的距离D+、D-。
(6)
(6)计算各个方案与理想解的贴近度Wi,Wi值越大,该方案评价越优,反之越劣。
(7)
非侵入式算法评价过程实质也是一个多指标综合决策问题,TOPSIS方法对数据分布及样本量、指标数无严格限制,原始数据的利用较充分,信息损失少且计算适中,是多目标决策分析中一种科学、常用的有效方法。TOPSIS法的重点是用于衡量方案的指标属性权值的分配。现有的权值确定方案有很多,主要包括两类:主观赋权法和客观赋权法,但是单一权重都会造成评价结果失真。文献[17]研究对比了TOPSIS与不同的权重确定方法进行集成组合后的优劣性和原始数据的影响,建议集成TOPSIS与AHP两种方法。AHP法允许人为决策,充分吸收专家经验,但主观因素过强,很难直接应用于非侵入式算法评价。因此,为了保留评价指标的客观信息,同时减低客观赋权法对样本数据的强依赖性,文章提出一种基于AHP和变异系数法的融合权重。
2 集成融合权重的TOPSIS模型
为了保留评价指标的客观信息,同时减低客观赋权法对样本数据的强依赖性,文中提出一种基于AHP和变异系数法的融合权重。
2.1 基于AHP和变异系数法的融合权重
(1)AHP
层次分析法[18-19](Analytic Hierarchy Process,简称AHP)由美国运筹学家T. L. Saaty教授于20世纪70年代初期提出。主要通过构建递阶层次模型明确多指标之间的隶属度关系,保证不同层元素的类别相似性和指标体系的排序合理性,非常适用于分析包含主观信息的不确定性问题,是一种比较科学的确定权重的方法。其核心步骤为:
第一步:构建递阶层次模型,划分不同指标层次,确定隶属关系;
第二步:明确下层元素对上层元素的相对重要性,利用二元对比法确定同层元素的比较矩阵;
第三步:通过归一化确定下层指标对其上层指标的相对权重,逐层关联递进得到层次总权重。
设下层n个元素C1,C2,…,Cn对于上层某一元素的判断矩阵为A:
(8)
式中cij表示元素i与元素j相对于上一层次因素重要性的比例标度值。采用二元对比法对同层指标两两比较,赋值依据为文献[21]中T.L.Saaty提出的比例标度表,如表1所示。

表1 重要性比例标度表Tab.1 Scale of importance ratio
由矩阵A的数学性质可知其为正定互反矩阵,存在最大特征根且唯一,因此,采用特征根法计算同层元素的相对权重。
AW=λmaxW
(9)
式中λmax是A的最大特征根;W是对应的特征向量,对W进行归一化后即可作为权重向量ωA。
标准值2、4、6、8分别表示1、3、5、7、9之间的重要度赋值;且Wij=1/Wji,若矩阵A满足:
cij×cjk=cik,i,j=1,2,…,n
(10)
称矩阵A为一致阵。在判断矩阵的构造中,由于客观事物的复杂性和主观认识的多样性,式(10)并不要求一定严格成立,但为了避免出现“元素甲比元素乙极端重要,元素乙比元素丙极端重要,而元素丙又比元素甲极端重要”的错误决策,对判断矩阵进行一致性检验,计算一致性比率C.R.为:
(11)
式中R.I.表示平均随机一致性指标,表2列出了1~14阶矩阵计算1 000次得到的平均随机一致性指标值;C.I.为一致性指标:C.I.=(λmax-n)/(n-1),n为矩阵A的阶数。

表2 平均随机一致性指标R.I.Tab.2 Average random consistency indicator R.I.
当C.R.小于阈值0.1[18,20]时,认为该判断矩阵具有整体满意的一致性,否则,需对判断矩阵做出修正,如式(10)所示。
(2)变异系数法
变异系数法作为一种客观赋权法主要通过评价指标的对比强度和变化幅度来衡量权值。在多指标决策过程中,若某一指标的值在不同待评价对象之间差异较大,说明该指标对待评价对象排序的贡献较大,应当赋予相对更高的权值。

(12)
式中xij表示第j个评价对象的第i评价指标值。则指标变异系数Gi为:
(13)
归一化后即可求得指标客观赋权:
(14)
2.2 融合权重和评价模型
采用基于理想点法的组合赋权法融合主观权值ωA客观权值ωB,使得指标赋权既能反应指标客观规律,又能兼顾决策者的主观需求和实际工程经验。

(15)
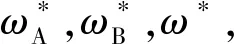
(16)

(17)
则融合权重:
(18)
由以上步骤得到非侵入式算法评价模型如图1所示。
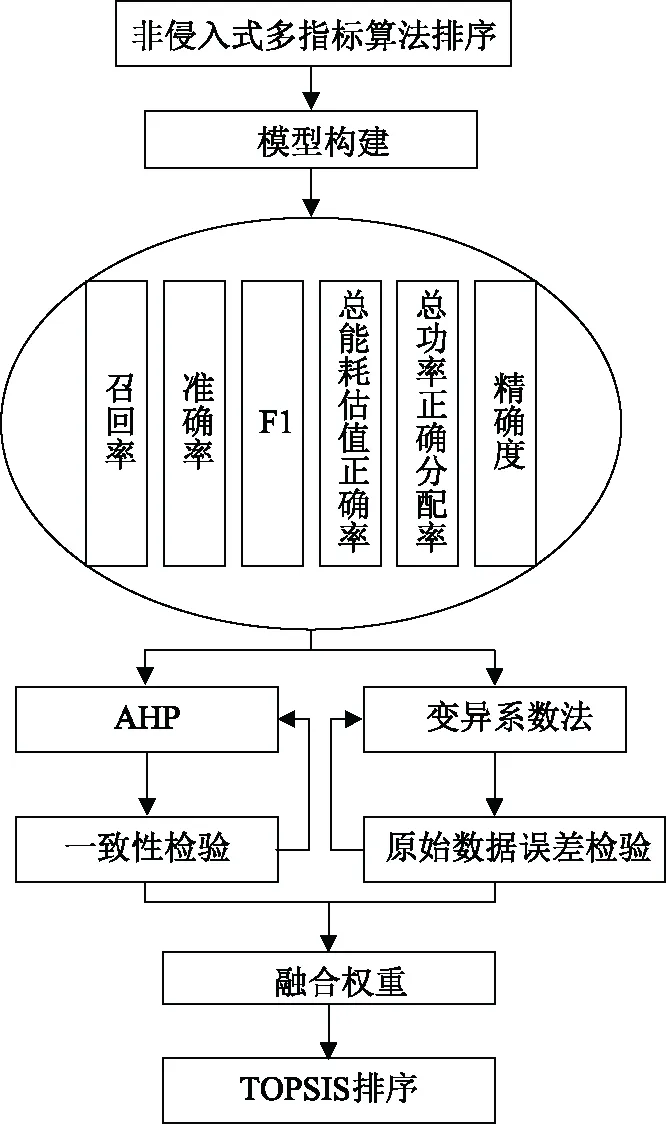
图1 非侵入式算法评价模型Fig.1 Evaluation model of non-intrusive algorithm
2.3 非侵入式负荷辨识算法评价指标
针对现有单一准确率指标,精确度(pc)和召回率(rc)在样本分布不均时可以提供补充的识别性能分析依据;F1得分是pc和rc的调和均值,当两者差距过大无法比较时,F1量度可以提供判断依据;此外,常用的能耗估值相对误差等三个度量均是对功耗估值的误差量度,都较为直观。
在非侵入式负荷辨识算法中,效益型指标更为人们所关注。因此,结合实际工程应用的侧重点,文章从负荷辨识结果和能耗分配过程两个方面选择六个效益型评价指标构建评价模型,如表3所示。

表3 非侵入式算法评价指标Tab.3 Non-intrusive algorithm evaluation index
3 案例分析
3.1 案例一
为了验证文章方法的有效性,实验一测试了DAE算法、RNN算法和DAE-RNN优化算法在UK-DALE[22]公共数据集上对洗衣机、洗碗机、水壶、微波炉、冰箱共5种常用的电器设备的辨识,且只考虑单一状态识别。表4列出了三种辨识方法对单一状态设备的辨识分析结果[23-25],可以发现,三种算法在不同的单一评价指标下排序差异较大,为了避免单一评价值的误差干扰,综合考虑多方评价因素,采用基于融合权重的TOPSIS法对算法进行优劣排序。

表4 算法辨识结果Tab.4 Algorithm identification result
(1)AHP法:根据专家经验和实际侧重,由表4得到判断矩阵A,C1,C2,…,C6依次表示表4中的六种指标。由式(9)~式(11)计算得到一致性比率C.R.为0.004 6,经验证C.R.<0.1,通过一致性检验,求得主观权重如表5所示。

(19)
(2)由式(12)~式(14)求得客观权重ωB,由式(15)~式(18)组合赋权求得融合权重ω,如表5所示。
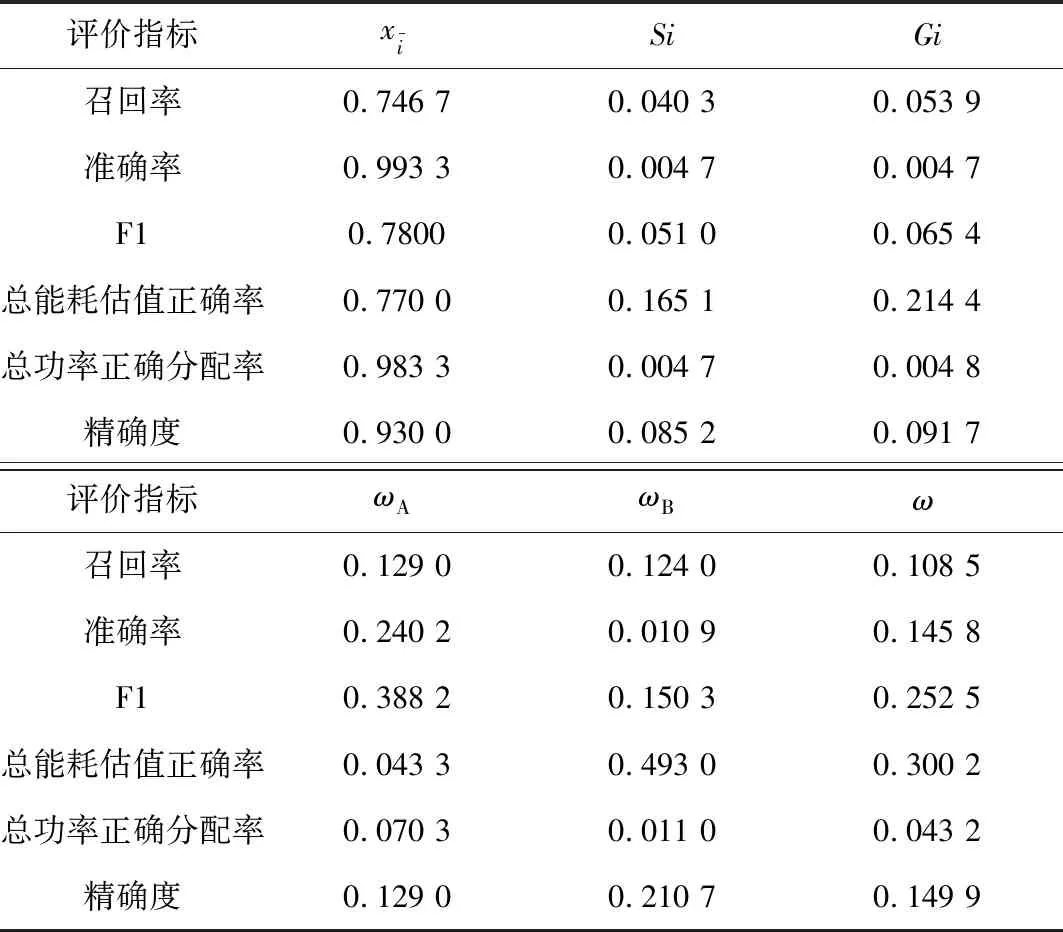
表5 融合权重Tab.5 Fusion weight

W3>W1>W2,即单状态设备辨识中,DAE-RNN算法最优,DAE算法次之,RNN算法性能最差。根据训练期间电器可见的数据和使用训练期电器不可见的数据训练优化网络的识别结果。DAE神经网络对单状态负荷辨识性能优于RNN网络,在保持准确率和精确度优势上,能耗分配准确率也相对较高。DAE-RNN优化结构总体应用性能都在其他两者之上,在保留了DAE网络单状态电器识别准确率优势的基础上提高了F1得分,保证算法能更好地处理数据分布不均的情况,是辨识算法更加稳定可靠,证明了基于融合权重的改进TOPSIS模型评价结果与实际工程性能相符,证明文章方法实际有效可行。
3.1.1 指标赋权对比分析
对比分析由主观赋权AHP法、客观赋权变异系数法、组合优化赋权法所得的指标权重结果,如图2所示。采用AHP赋权时能耗估值正确率和总功率正确分配率重要性相近,但原始数据中三种算法的能耗估值正确率差异较大;而单独采用客观赋权时会过分夸大数据波动性,对样本数据依赖性较大,容易忽略实际工程需求,不能体现评估指标自身价值的重要性。基于最优组合赋权的融合权重可以对两者进行适当调节,实现优势互补,得到更为合理科学的评价结果。
3.1.2 指标个数及选择对评价结果的影响
考虑到多指标决策过程中指标个数及选取对评价结果的影响,实验测试了四个指标、五个指标共21种组合方式下上述三种算法的评价结果,所有实验数据均相同,实验结果如表6所示,其中F1,F2,F3依次从左至右表示表4中三种算法,C1、C2、C3、C4、C5、C6依次从上至下表示表4中6种评价指标。分析测试结果得到如下结论:

表6 指标组合与评价结果Tab.6 Indicator combination and evaluation results
(1)四个指标组合中排序正确率为2/3;五个指标组合中排序正确率为5/6,由于篇幅限制和文章旨在多指标评价,因此一、二、三个指标组合排序实验并未在此列出。随着指标的增加,排序正确率逐渐增大且趋近于正确排序;
(2)通过分析,主观赋权权重最大的指标和不同方案间实际数据差异最大的指标会对评价结果产生一定影响;
(3)实际应用中可以通过统计学方法测试不同指标组合的评价结果确定适合的指标个数并判断最终正确排序。
3.2 案例二
实验二在某家庭用户场景下测试了关联RNN算法、LSTM以及Bi-LSTM(双向长短期记忆网络)算法对电采暖1,2,3档、电炖锅、泡脚桶、电吹风冷风、热风档、电磁炉、高压锅、打印机、电饭锅、豆浆机、电视共13种用电状态的辨识结果,如表7所示。按照案例一的评价步骤对三种算法进行排序,结果如表8所示。

表7 算法辨识结果Tab.7 Algorithm identification result

表8 融合权重Tab.8 Fusion weight
4 结束语
为了综合评估电力负荷辨识算法的可靠性和可行性,避免单一评价指标造成辨识失误等问题,选取六种互补的效益型评价指标,采用基于AHP和变异系数法融合赋权的TOPSIS模型,兼顾客观数据信息和专家经验主观决策,利用逼近于理想解的排序方法计算评价对象与正负理想解的接近程度,实现对非侵入式算法的评价。最后通过实际案例验证文中方法有效性和可行性,为研究非侵入式电力负荷辨识领域算法的分类、评价及选取提供一种新的解决方案。
