基于多对多生成对抗网络的非对称跨域迁移行人再识别
2022-02-17梁文琦王广聪赖剑煌
梁文琦 王广聪 赖剑煌 ,
行人再识别[1−7]是指在非重叠的摄像头视角下检索特定的目标行人图片或视频片段,它是多摄像机跟踪、搜索取证等重要应用中的关键技术,广泛应用于智能视频监控网络中[8].行人再识别最初的研究方法是先设计一种能够描述行人图片的手工视觉特征,再建立一个鲁棒的距离度量模型来度量视觉特征之间的相似性[9−15].近年来,随着深度学习的发展,大部分研究者转向使用深度学习来处理行人再识别问题.文献[16−18]分别提出了基于分类损失、验证损失、三元组损失的行人再识别基本框架.为了处理行人图像不对齐的问题,文献[19−20]分别提出全局区域和局部区域的对齐方法,文献[21]提出动态的特征对齐方法.为了处理摄像头之间的差异,文献[22]提出使用多组生成对抗网络在同域内的多个视角之间进行迁移,以此缩小域内不同视角之间的差别.为了进一步提高识别准确率,最近有很多文献尝试使用额外的标注信息作为辅助.例如文献[23]提出人体姿势驱动的深度卷积模型,文献[24]引入行人属性标记,文献[25−26]加入了人体掩模,文献[27]提出在检索过程中加入时空约束.
得益于深度学习的发展,如今行人再识别任务在大规模数据集上已经取得了良好的效果,但需要大量带标注的训练数据.然而,与其他检索任务不同,收集带标注的行人再识别训练数据更加困难.标注数据的难点在于,行人再识别数据集没有固定的类别,多人合作标注很困难;而且图像分辨率低,不容易辨别.为了更符合实际场景的应用需求,科研人员开始研究如何在目标数据集没有标注信息的前提下实现行人再识别.在这种背景下,非监督行人再识别(Unsupervised person re-identification)成为新的研究热点.
目前,非监督行人再识别有两类主要的研究方法.第1 类是基于聚类的非监督学习方法.文献[28]提出一种基于聚类的非对称度量学习方法,利用非对称聚类学习把不同视角的数据投影到共享空间中.文献[29]提出基于聚类和微调的非监督深度学习框架.该方法先使用预训练的神经网络模型提取目标数据集的特征,然后通过聚类算法得到目标数据集的伪标签,再利用伪标签对预训练的网络进行微调(Fine-tune).文献[30]在文献[29]的框架上再进行改进,提出一种自底向上逐层合并最相近簇的聚类方法.
非监督行人再识别的第2 类研究方法是跨域迁移学习方法(Cross-domain transfer learning).这类方法通常都有带标注的行人再识别数据集作为辅助,这个辅助的数据集称为源数据集或源域(Source domain),实际应用场景对应的无标注数据集称为目标数据集或目标域(Target domain).由于只有源域是有标注的,所以这类方法的关键之处在于尽可能地把从源域中学习到的知识迁移到目标域中.文献[31]通过添加域分类器和梯度反传网络层来实现域适应.文献[32] 提出一种跨域自适应的Ranking SVM (Support vector machine)方法,利用了源域的正负样本、目标域的负样本和目标域估计的正样本均值来训练.文献[33−34]则提出两阶段的跨域迁移学习方法:首先利用生成对抗网络实现源域数据分布到目标域数据分布的变换,根据变换前源域数据的标签对变换后的图片进行标注;然后使用变换后的图片及其对应的标注进行有监督训练.
跨域迁移学习方法对目标域训练集(无标注数据)的数据分布限制更少,应用范围更广泛,更加适合实际的行人再识别应用场景.但是现有的跨域迁移学习方法没有考虑视角偏差(View-specific bias)问题,源域中不同视角(摄像机)的数据以完全相同的迁移方式变换到目标域中.也就是说,目前的迁移方式都是对称的(对称迁移).然而在智能监控视频网络中,不同拍摄地点的光照条件、拍摄角度以及摄像机本身的参数都可能存在明显的差别,不同摄像头拍摄到的图片往往服从不同的分布.在跨域迁移学习时,忽略摄像头的分布差异一方面会导致迁移效果不佳,另一方面会导致迁移后的数据无法体现出目标域多个视角子分布的情况,从而不利于训练跨视角匹配模型.
基于以上分析,本文提出基于多视角(摄像机)的非对称跨域迁移学习方法.在基于生成对抗网络的两阶段跨域迁移学习方法[33−34]基础上,本文针对视角之间的差异问题进行建模.为了对每种源域−目标域视角组合使用不同的迁移方式(称为非对称迁移),一个最简单直观的想法是把每个视角的数据看成是各自独立的,然后训练多组互不相干的生成对抗网络模型,每个模型分别把知识从源域的某个视角迁移到目标域的某个视角.然而,这种不同视角组合使用不同网络参数的非对称迁移方式非常消耗训练时间和存储空间.假如源域有M个视角,目标域有N个视角,则一共需要训练M ×N组生成对抗网络.大型智能监控网络涉及的摄像头数目非常多,显然这种方法是不切实际的.除此之外,单独使用每对视角的数据来训练生成对抗网络无法利用数据集内不同视角数据之间的相关性.为了解决独立训练而造成成本太高的问题,并尽可能地利用不同视角数据的相关性,本文提出把非对称迁移学习嵌入到一组生成对抗网络中.为此,我们设计了一个多对多生成对抗网络(Many-to-many generative adversarial network,M2M-GAN),同时实现源域任意视角子分布到目标域任意视角子分布的转换.实验表明,与现有的对称迁移方法(不考虑视角差异,且仅有一组生成对抗网络网络)相比,我们的方法只需增加少量训练时间和空间成本就能有效提升识别准确率.与单独训练多组生成对抗网络这种简单的建模方式(考虑视角差异,但需M ×N组生成对抗网络)相比,我们的方法在训练成本和识别准确率两方面都取得更优的性能.
本文的主要贡献:1)针对源域或者目标域存在多个具有差异性的子分布问题,本文提出一种多对多的跨域迁移模型来区别对待源域不同的子分布到目标域不同的子分布的迁移.本文将这种区分性的迁移模式称为非对称迁移.为了更好地优化非对称迁移学习模型,本文提出了一种基于多对多生成对抗网络(M2M-GAN)的迁移学习方法,同时实现把源域任意子分布的图像风格转变成目标域任意子分布的图像风格.2)视角偏差或摄像机差异是跨域迁移行人再识别领域被忽略的一个关键问题.本文将M2M-GAN 方法应用于该领域,生成了具有视角差异且服从目标域各个视角子分布的行人图片,进而使得模型学习到的特征具有视角偏差不变性,有效提升了无监督跨域迁移行人再识别的准确率.3)在Market-1501,DukeMTMC-reID 和MSMT17 三个大规模多摄像头行人再识别基准数据集上,实验结果验证了M2M-GAN 的有效性.
1 生成对抗网络和跨域迁移学习行人再识别
1.1 循环生成对抗网络
生成对抗网络(Generative adversarial network,GAN)[35]主要用于图像风格转换,例如把照片变成油画、把马变成斑马等.它由生成器和鉴别器两部分组成,利用博弈论观点来训练.生成器试图生成能够以假乱真的图片来“欺骗”鉴别器,而鉴别器则尽可能地把生成器生成的“假冒”图片鉴别出来.生成器和鉴别器相互对抗,交替训练,直到鉴别器无法判断生成器生成图片的真假,这个过程可以用对抗损失表示.
用于图片风格转换的生成对抗网络一般需要成对的训练样本,但实际应用中很难收集到足够的成对样本.循环生成对抗网络(Cycle-GAN)[36]通过在普通生成对抗网络的基础上添加循环一致约束来实现非配对图像之间的转换.假设需要在两个域X和Y之间转换,循环一致约束要求对于域X的一张真实的图片x,通过生成器G生成图片G(x),G(x) 再经过生成器生成重构图片(G(x)),这个重构图片需要和原始的真实图片x保持像素级别的一致.同理,对于域Y也是如此.
1.2 基于循环生成对抗网络的跨域迁移行人再识别
跨域迁移学习方法是当前在目标数据集无标注的情况下解决行人再识别最常用的方法.除了没有标注信息的目标数据集外,这类方法还会使用其他场景下有标注的行人再识别数据集作为辅助.跨域迁移学习方法的关键之处在于尽可能地把有标注的辅助数据集(即源域 (Source domain))的知识迁移到无标注的目标数据集(即目标域 (Target domain)).跨域行人再识别方法的难点在于不同的行人再识别数据集之间存在较大的差异(Dataset bias),因而极大增加了从源域到目标域知识迁移的难度.这些数据集差异包括图像背景、光照、拍摄角度、图像分辨率等.如果能减小这种数据集之间的差异,那么在有标注数据集上训练的模型就可以适用于无标注的目标数据集.而循环生成对抗网络恰好适合用于减小数据集之间的差异.如第1.1 节所述,循环生成对抗网络可以把一种风格的图片变成另一种风格的图片,并且不需要使用两个域中配对的数据来训练.利用循环生成对抗网络,可以把源域的图片风格转变成目标域的图片风格.因此,基于循环生成对抗网络的跨域迁移行人再识别可分为两阶段:第1 阶段是训练循环生成对抗网络,用源域图片生成具有目标域图片风格的新数据集,新数据集使用源域的身份标注;第2 阶段是利用新数据集及对应的身份标注进行有监督的行人再识别.
2 基于多对多生成对抗网络的非对称跨域迁移行人再识别
目前跨域迁移行人再识别的课题研究忽略了域内不同视角的数据分布差异问题,对于所有的视角数据采用完全相同的迁移方式.我们重点研究了多个视角子分布的差异在迁移学习中的重要性,并提出了非对称跨域迁移行人再识别问题.为了能高效地实现非对称迁移,我们设计了多对多生成对抗网络(M2M-GAN).本节将详细介绍我们提出的方法.
2.1 非对称跨域迁移行人再识别问题
在智能视频监控网络中,不同摄像头被布置在光照条件、拍摄角度不同的位置,再加上摄像头自身参数的差异,所以实际应用中不同摄像头拍摄得到的行人图片数据会呈现不同的分布情况.图1 列出了4 个常见的行人再识别数据集的例子,其中每张子图的不同列代表该数据集内不同摄像头拍摄得到的行人图片.从图1 可以看出,摄像头分布差异在行人再识别任务中是普遍存在的.

图1 摄像机分布差异举例Fig.1 Examples of distribution differences between different views
然而,现有的行人跨域迁移框架忽略了这种摄像头分布差异性,会造成精度的损失.我们用图2对此进行直观的解释.图2(a)和2(b)两幅图描述了源数据集和目标数据集整体上存在较大差异,每个数据集内部也存在一定的子分布差异的现象.每幅图内不同的曲线分别代表了数据集内某个特定视角的分布.不同的视角子分布都近似于整体分布,具有相似性,但是各自又存在一定的偏差.图2(c)和2(d)分别是图2(a)和2(b)中各个数据集内所有视角子分布的平均值,图2(c)和2(d)两幅图只描述了源数据集和目标数据集差异.现有的迁移框架主要研究如何减小数据集差异,在迁移过程中把源域和目标域都分别看作一个整体,即从图2(c)到2(d)的迁移.但是,使用平均分布来估计具有多子分布的真实数据集,即用图2(c)和2(d)来估计图2(a)和2(b),会带来精度的损失.所以我们重点研究迁移过程中的视角差异问题,提出用源数据集多视角到目标数据集多视角迁移(即(a)→(b))代替传统的整体迁移(即(c)→(d))方式.
我们从两方面详细地分析多对多迁移的好处.一方面,在迁移过程中加入视角信息可以提高生成图片质量.假设生成器G用于从源域到目标域迁移,鉴别器D用于鉴别输入图片是否属于目标域.生成器G的输入是具有多个子分布的图片(图2(a)),假如忽略视角差异,那么生成器就需要针对所有视角子分布采用相同的生成方式.但是同一种映射方式很难同时适用于多种视角分布.而如果在生成器中引入视角信息,使生成器针对不同的子分布选择不同的生成方式,就可以提高生成图片的质量.同样地,鉴别器的输入也是具有多个视角子分布的真实图片或生成图片.如果在鉴别器中融入视角信息,使鉴别器针对不同视角子分布采取不同的鉴别方式,就可以提高鉴别器的鉴别能力,从而间接提高生成器的效果.

图2 本文提出的多视角对多视角迁移方式与现有迁移方式的比较Fig.2 Comparison of our M2M transferring way and the existing methods
另一方面,强调视角子分布可以使生成的数据更好地模拟出目标域多视角分布的现实情况,更有利于解决目标域跨视角匹配问题.假如在迁移时不区分视角,那么迁移的结果只包含了目标域的总体统计特性(图2(d)),没有包含目标域各个视角的统计特性(图2(b)).而目标域行人再识别的一个关键问题是要实现跨视角行人图片匹配,即要训练一个对视角鲁棒的行人再识别模型.为了训练对视角鲁棒的行人再识别模型,就需要具有不同视角分布风格的训练图片.所以,如果能生成服从目标域不同视角子分布的图片(图2(b))作为训练数据,而不仅仅生成服从目标域平均分布(图2(d))的图片,将会大大提升模型对视角的鲁棒性.
以上分析体现了迁移过程中结合视角信息的重要性.因此,我们提出了非对称跨域迁移行人再识别问题,强调针对源域的不同视角或目标域的不同视角采取不同的迁移方式.
具体地,非对称跨域迁移行人再识别问题可以描述为:令S表示一个有标注的源域,T表示一个没有标注的目标域.S包含M个视角,记为S1,S2,···,Si,···,SM.T包含N个视角,记为T1,T2,···,Tj,···,TN.每张图片来自哪个摄像头是容易收集的标注信息,所以每张图片的视角标记Si或Tj可视为已知信息.非对称跨域迁移行人再识别的目标是把源域的多个子域分别迁移到目标域的多个子域.即对于任意的i ∈[1,M],j ∈[1,N],要实现从Si到Tj的迁移.给定源域视角Si的一张真实图片xsi和相应的身份标注ysi,利用生成具有目标域视角Tj风格的图片然后,使用生成图片和身份标注训练行人再识别模型.
2.2 多对多生成对抗网络
由于同一个行人不会同时出现在源域和目标域中,我们无法获取配对的训练样本用于源域−目标域行人图片风格迁移.而循环生成对抗网络恰好不需要成对训练样本,所以目前的研究方法通常采用循环生成对抗网络来实现源域−目标域行人图片风格迁移.但是直接应用循环生成对抗网络,只能实现源域整体与目标域整体风格之间的迁移.
想要实现源域多视角与目标域多视角之间的非对称迁移,一种简单的方案是针对每对源域−目标域视角组合 (Si,Tj) 分别训练一组循环生成对抗网络,共需M ×N组循环生成对抗网络用于实现源域M个视角和目标域N个视角之间的迁移.显然这种方法是不切实际的,因为在一个大型智能视频监控网络中可能存在成百上千个摄像头,训练M ×N组深度网络会带来巨大的训练时间和存储空间损耗.我们希望只用一组生成对抗网络实现源域多个视角和目标域多个视角图片风格迁移.因此,我们在循环生成对抗网络基础上进行改进,设计了多对多生成对抗网络,使得模型不仅局限于两个域整体风格的迁移,还能细化到多个视角的图像风格迁移.
为了实现两个域的不同视角之间的图片风格迁移,首先我们需要把视角信息输入到模型中.假如没有子视角信息,模型就无法针对不同的视角组合采取不同的迁移方式.为此,我们设计了视角嵌入模块(第2.2.2 节),把原始输入图片、源域视角标记、目标域视角标记整合在一起,形成新的“嵌入图”作为生成器的输入,为生成器提供视角信息.
视角嵌入模块明确告诉生成器需要从源域的哪一个视角迁移到目标域的哪一个视角,但只有信息嵌入并不足以引导生成器按照期望的方向生成图片.除了视角信息输入,我们还需要为生成器提供监督信号,引导生成器利用输入的视角信息.也就是说,我们需要判断生成图片与期望视角的差别有多大,这样才能把缩小差距作为训练目标来优化生成器的参数.为此,我们设计了视角分类模块(第2.2.3 节),该模块利用一个视角分类器来预测生成图片与期望视角的差距,然后用预测的结果监督生成器,引导生成器生成与期望视角差异尽可能小的图片,如图3 所示.
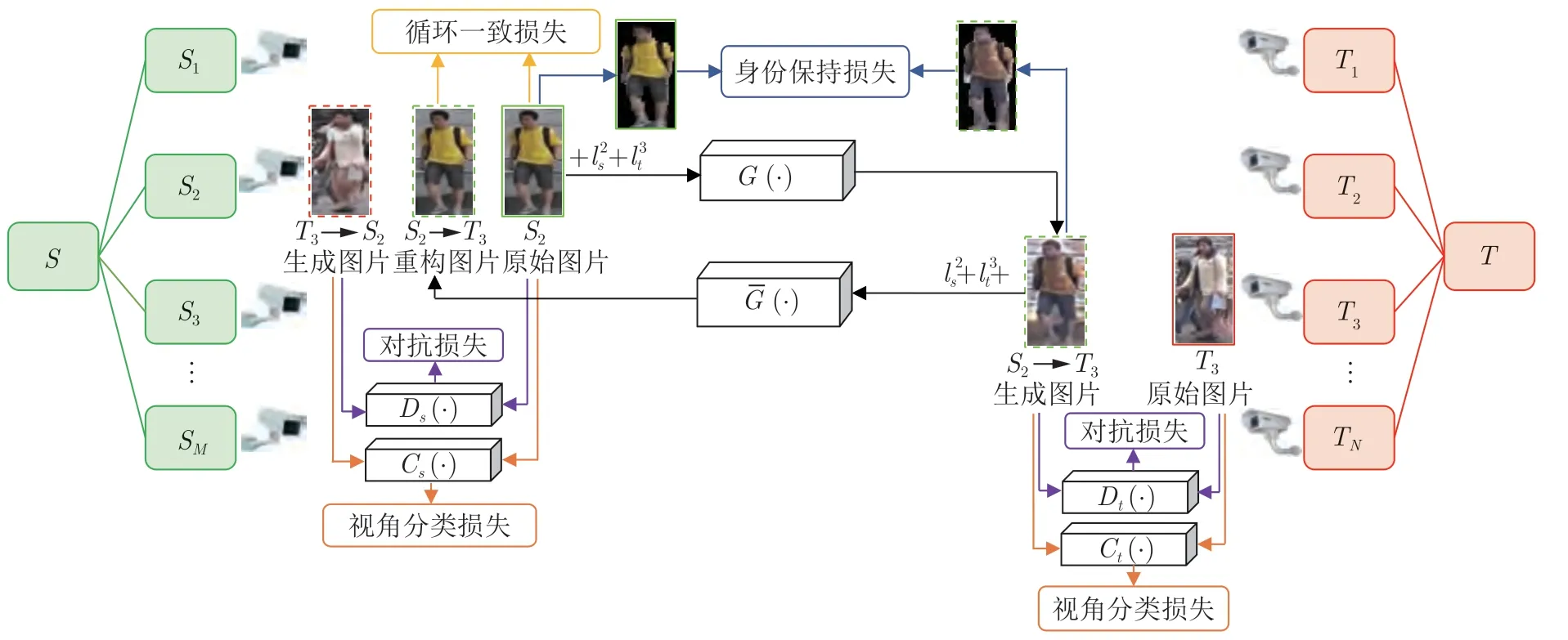
图3 多对多生成对抗网络框架(省略了目标域 → 源域的生成过程、循环一致损失和身份保持损失)Fig.3 Framework of our M2M-GAN (The generation process,the cycle consistency loss,and the identity preserve loss of target domain → source domain are omitted)
视角嵌入和视角分类两个模块,前者为生成器提供了视角信息,后者监督生成器充分地利用输入的视角信息.这两个模块配合使用,就可以在同一个网络中实现两个域多个视角组合的图片风格迁移.
下面将详细介绍多对多生成对抗网络,先回顾循环生成对抗网络(第2.2.1 节),然后介绍视角嵌入模块(第2.2.2 节)和视角分类模块(第2.2.3 节),最后给出总目标函数(第2.2.4 节)并说明模型结构设计和训练的细节(第2.2.5 节).
2.2.1 循环生成对抗网络
多对多生成对抗网络在循环生成对抗网络基础上进行改进,本节简要描述循环生成对抗网络算法.循环生成对抗网络[36]由两个生成器和两个鉴别器组成.其中两个生成器(G和)分别用于源域迁移到目标域和目标域迁移到源域的图片生成,两个鉴别器(Dt和Ds)分别用于判断生成图片是否属于源域和目标域的真实分布.循环生成对抗网络包含对抗损失和循环一致损失.为了统一符号,我们把对抗损失和循环一致损失改写成多视角形式,与原本的循环生成对抗网络略有不同.
1) 对抗损失.源域视角Si迁移到目标域视角Tj的对抗损失可以表示为


源域S迁移到目标域T的对抗损失是所有源域−目标域视角组合的对抗损失的平均值

由式(1)和式(2)得:

其他损失函数与此类似,两个域之间的损失等于源域−目标域所有视角组合损失的平均值,不再对此详细说明.
类似地,目标域T迁移到源域S的对抗损失为


2.2.2 源域和目标域视角嵌入
为了让生成器能明确当前迁移方向是从源域(或目标域)的哪个视角迁移至目标域(或源域)的哪个视角,生成器的输入应包含视角标记.我们把视角标记作为额外的输入通道(Channel),这样就可以把视角信息输入到生成器神经网络中.但是图像和视角标签的维度不一致,无法直接结合,要对视角标记进行转换,转换过程如图4 所示.我们先用one-hot 编码方式对视角标记进行编码.然后对每一位one-hot 编码值,如果其值为1,就生成一张值全为1 的二维图;如果其值为0,就生成一张值全为0 的二维图.通过这种方式,视角标记可以转换为与输入图片具有相同图片尺寸的多通道图片.于是输入图片、输入图片对应的视角标记、期望输出图片对应的视角标记三者就可以依次叠加,一起输入到生成器中.



图4 视角嵌入Fig.4 View embedding
2.2.3 视角分类器
通过视角嵌入模块,视角信息被输入到生成器中.但是仅仅增加输入信息并不能约束生成器,还需要为生成器提供监督信号,引导生成器利用输入的视角信息.生成器的目标是尽可能缩小生成图片与期望视角的差距,所以我们可以把生成图片属于期望视角的概率值作为监督信号.假如生成器生成的图片偏离期望的视角分布,就需要惩罚生成器.

接下来,我们将叙述如何计算生成图片与期望视角的差距(视角类别估计),以及如何利用这一信息监督生成器.
1) 估计视角类别.估计生成图片属于域内某个视角的概率,其实就是视角分类任务.所以,我们可以训练视角分类器,然后利用视角分类器来预测生成图片属于域内各个视角的概率.
源域视角分类和目标域视角分类是两个独立的任务,我们设计了视角分类器Cs和Ct,分别用于源域M个视角和目标域N个视角分类.训练视角分类需要训练样本和样本对应的视角标记,我们利用了数据集中真实的图片和真实的视角标记作为训练样本.训练Cs时,使用源域真实的训练图片和视角标记.训练Ct时,使用目标域真实的训练图片和视角标记.值得一提的是,这里只使用了视角标记,并不会使用任何身份标记.为了训练Cs和Ct,采用图像分类中最常用的交叉熵损失函数

2) 监督视角生成.以视角Si迁移到视角Tj为例,利用视角分类器可以估计生成图片属于目标域N个视角中的视角Tj的概率.接下来,对生成器进行约束,使得生成图片属于视角Tj类别的概率尽量接近1,属于其他N −1 个视角类别的概率尽量接近0.这个目标与分类任务类似,不同点只在于此时需要优化的参数是生成器,而视角分类器只用来估计生成图片属于各个视角类别的概率,参数是固定不变的.因此,也可以用以下交叉熵损失对生成器进行约束:

2.2.4 总目标函数
目标函数由4 部分组成,包括对抗损失(式(3)和式(4))、循环一致损失(式(5))、视角分类损失(式(7)和式(8))、身份保持损失(式(9)).除了前文已经介绍的前三种损失,还需要身份保持损失,用来保证迁移过程中身份信息不变,否则无法得到生成后图片的正确身份标注.我们使用文献[34]提出的基于前景掩模的身份保持损失函数.在多对多生成对抗网络中,该损失可以表示为

其中,M(·) 表示图片的前景掩模,实验中使用在COCO (Common objects in context)数据集[37]训练过的Mask R-CNN (Region convolutional neural network)[38]模型来提取行人的前景.∥·∥2表示L2 范数,“◦”表示逐像素乘法操作.式(9)表示生成前和生成后的图片前景应保持一致,即与前景保持一致.
鉴别器和视角分类器有很强的联系,鉴别器分辨输入图片是否属于某个域,视角分类器分辨输入图片属于该域的哪个视角,它们之间是粗粒度分类和细粒度分类的关系.于是,类似于多任务学习,我们令鉴别器和视角分类器共享一部分参数并让它们共同优化.
综合以上4 种损失函数,我们将总目标分为两部分.生成器的目标函数为

鉴别器和视角分类器的目标函数为

其中,λ1,λ2,λ3分别用于控制视角分类损失、身份保持损失和循环一致损失的相对重要性.
2.2.5 实现细节
在循环生成对抗网络的基础上,多对多生成对抗网络增加了两个视角分类器.所以多对多生成对抗网络一共由两个生成器、两个鉴别器和两个视角分类器组成.图3 是多对多生成对抗网络的框架图(图中只完整描述了源域迁移至目标域的全过程,省略了目标域迁移至源域的生成过程、循环一致损失和身份保持损失).图5 是网络结构示意图.网络结构图中长方体部分表示网络层、箭头上方是每一网络层的输出维度、M和N分别表示源域和目标域子视角类别数.图5 中展示的网络结构以源域为例,目标域的网络结构与此类似,唯一不同点是子视角类别数不同.

图5 多对多生成对抗网络结构图Fig.5 Network structures of our M2M-GAN
1) 生成器结构.我们使用两个不同的生成器,分别用于从源域到目标域、从目标域到源域的迁移,两个生成器结构一致.与循环生成对抗网络类似,我们也采用经典的编码器−解码器(Encoder-decoder)模式搭建生成器.
生成器的输入为集成了源域视角和目标域视角信息的嵌入图(式(6)),嵌入图大小为(3+M+N)×128×128,M和N分别表示源域和目标域的视角数目.由于源域视角和目标域视角数目不固定,嵌入图的通道数不是一个确定的值.所以在对输入数据进行特征编码前,首先用一个有64 组滤波器的卷积层对嵌入图进行卷积操作,把通道数统一调整为64.
卷积后得到的特征图大小为 3×128×128,经过连续两次下采样操作得到 256×3×3 的特征图.每一次下采样操作会把特征图的宽和高变为原来的一半,通道数变为原来的两倍.下采样把图像从高维空间转换到潜在的低维空间,便于后续对特征进行处理.下采样可以通过卷积来实现.接下来,特征图输入到由6 个残差单元组成的瓶颈层.瓶颈层会对特征进行加工,筛选出能够用于构造目标图片的特征.最后,特征图经过连续两次上采样操作,得到256×3×3 的特征图.上采样和下采样是一一对应的,上采样把低维特征图重新变成高维图像,可以通过反卷积实现.为了使网络最终输出3 通道RGB 图片,网络最后一层是一个由3 组滤波器组成的卷积层,把图片通道数重新调整为3.
2) 鉴别器和视角分类器结构.鉴别器和视角分类器的学习目标有相似之处,前者判断输入图片是否服从某个域的整体分布,后者判断输入图片服从某个域的哪一个视角子分布,所以我们令鉴别器和视角分类器共享一部分参数.具体来说,鉴别器和视角分类器共享特征提取器,该特征提取器由6 个卷积层组成.输入图片经过共享的特征提取器,提取到对应的特征图,然后特征图流向两个分支,进行多任务学习.
其中一个分支是鉴别器,鉴别器需要对“真假”两个类别进行分类,是二分类问题.所以我们选择用1 组滤波器构成“真假”分类器,该滤波器用于计算图片属于真实分布的概率.
另一个分支是视角分类器,视角分类器需要对源域(或目标域)M个视角(或N个视角) 进行分类,是多分类问题.所以我们选择用M组(或N组)滤波器来构造多分类器.每个滤波器分别计算图片属于其中某个视角的概率,多组滤波器输出的是图片属于源域(或目标域)M个视角(或N个视角)的概率.
3) 训练方式.多对多生成对抗网络训练时,多视角组合是共同训练和优化的.同一数据集不同视角的图片包含相同的人群、相同的时间段和相似的背景,这种数据高相关性使得同时优化M ×N对视角组合的迁移并不需要M ×N倍训练时间(对比单独优化一对视角的训练时间).下面举个简单的例子进行说明.假设源域S有S1,S2两个视角,目标域T有T1,T2两个视角.有三种不同的训练方式:a)用S1,S2,T1,T2所有数据训练一个不区分视角的生成对抗网络(基本的迁移方法,不区分视角).b)单独使用一对视角组合数据训练一组生成对抗网络,即用(S1,T1)、(S1,T2)、(S2,T1)、(S2,T2)分别训练一组生成对抗网络(区分视角,单独优化).c)用S1,S2,T1,T2所有数据训练一个区分视角的生成对抗网络(本文提出的多对多迁移方法,区分视角,共同优化).由于不同视角数据分布相似,再加上新增的网络结构和损失函数对整体收敛速度影响不大,所以无论是用一对视角数据(如S1,T1)还是全部视角数据(即S1,S2,T1,T2),无论是训练普通的生成对抗网络还是多对多生成对抗网络,对于一组生成对抗网络的训练开销是相近的.因此方式1、方式2 和方式3 训练一组生成对抗网络需要的训练开销近似,但方式2 需要训练4 组生成对抗网络,因此训练开销大约是其他两种方式的4 倍.实验结果可以验证,多对多迁移不需要大量的训练开销.
多对多生成对抗网络的具体训练过程是:每次迭代都随机从源域和目标域分别选择Q张图片(Q等于训练批次大小的一半),每张图片有两个视角标记,分别是图片自身的视角标记以及随机生成的另一个域的视角标记.然后用这 2Q张图片交替训练鉴别器和生成器.训练鉴别器和视角分类器时,生成器的参数固定不变,用式(11)计算损失,并反向传播更新鉴别器和视角分类器的网络参数;训练生成器时,鉴别器和视角分类器的参数固定不变,用式(10)计算损失,并反向传播更新生成器的网络参数.
2.3 行人特征学习
多对多生成对抗网络训练完成后,我们就可以利用训练好的生成器把源域的图片变换到目标域,然后使用变换后的数据集训练行人再识别模型.因为经过迁移的图片可以使用迁移前的身份标记,这样就把无监督问题变成了有监督的行人再识别问题,然后可以采取任意一种有监督的行人再识别方法.特别地,在本文中我们采用最常见的基于分类损失的行人再识别框架,把每个行人看作一个类别,使用分类损失函数(交叉熵)训练

其中,K是行人类别数,p(k) 是深度模型预测的样本属于第k类行人的概率.q(k) 表示真实的概率分布.当k为输入图片真实类别时,q(k) 值为1,否则q(k)为0.训练结束后,提取深度模型分类层前一层的网络层输出作为特征描述子,最后用欧氏距离度量查询图片和所有候选图片的相似性.
2.4 整体流程总结
为了便于理解,我们对整体流程总结如下:
步骤1.训练多对多生成对抗网络.使用源域的训练集和目标域的训练集训练一个多对多生成对抗网络,该步骤不使用任何行人身份标注.
步骤2.生成新数据集.多对多生成对抗网络训练完成后,对于源域的每一张图片,我们利用训练好的生成器都生成出目标域N个视角的新图片,新图片的身份标注使用对应的原始图片的身份标注.
步骤3.训练行人再识别模型.使用生成的数据集和对应的身份标注,以监督学习的方式训练一个行人再识别的深度神经网络.
3 实验结果与分析
为了验证本文提出的基于多对多生成对抗网络的迁移方法的有效性,我们设计了多个实验.
1) 设计了M2M-GAN 的可视化实验,定性分析M2M-GAN 是否能把源域各个视角的图片风格转换成目标域各个视角的图片风格.该实验的目的是验证M2M-GAN 是否能够模拟出目标域多视角分布的实际情况.
2) 将M2M-GAN 生成的图片用于行人再识别的效果.如果M2M-GAN 生成的图片能更好地体现目标域多个视角分布的特性,那么生成的图片就能够提高目标域内跨视角匹配的准确率.为了验证此观点,我们设置了两种跨域行人再识别基准实验作为对比,分别是:a)无迁移;b)不区分视角的迁移.把M2M-GAN 与这两种基准实验进行对比,可以验证我们提出的区分视角的迁移算法的有效性.
3) 设计了训练时间和模型参数量大小分析实验,对比了M2M-GAN 和两种迁移方式:a)经典的不区分视角的迁移模型;b)针对多种源域−目标域视角组合训练多组生成对抗网络的模型.与这两种方法对比,目的是验证第2.2 节提出的用多组生成对抗网络实现多视角迁移的不可行性和M2MGAN 的可实现性的观点.
4) 设计了消融实验,用来分析M2M-GAN 模型中的视角嵌入模块、视角分类模块和身份保持模块这3 个模块的作用.另外,该实验也能分析生成过程和鉴别过程中引入视角信息所起的作用.假如引入多视角信息有助于提高生成图片用于行人再识别的准确率,则可验证第2.1 节提出的“在迁移时引入视角信息是有利的”的观点.
5) 与其他无监督方法进行对比,从而验证我们方法的先进性.
3.1 实验数据集和算法性能评测指标
本文实验使用了3 个公开的大规模跨视角行人再识别基准数据集,包括Market1501[39]数据集、DukeMTMC-reID[40]数据集和MSMT17[34]数据集.
Market1501 数据集包含了6 个监控摄像头数据.数据集中有1 501 个行人共32 668 张图片.其中训练集包含751 个行人共12 936 张图片,测试集包含750 个行人共19 732 张图片,测试集中有3 368张图片被随机选为查询集,剩下的图片作为候选集.
DukeMTMC-reID 数据集包含了8 个监控摄像头数据.数据集中一共有1 812 人,其中408 人只有一个摄像机拍摄的图片.训练集包含702 个行人共16 522 张图片,测试集包含702 个行人.测试集中有2 228 张行人图片被选为查询图片,其余的17 661张图片(包括702 个作为测试的行人及408 个作为干扰的行人)作为候选集.
MSMT17 数据集是2018 年新发布的行人再识别数据集,它更符合实际应用场景.例如,数据集包含的摄像头数目更多,由15 个监控摄像头组成;数据集包含的行人数目更多,共4 101 人;拍摄时间和地点跨度更大,包含了室内室外四天内早中晚三个时段的数据,光照和背景变化更丰富.训练集中有1 041 个行人共32 621 张图片,测试集中有3 060人共93 820 张图片.其中测试集里有11 659 张图片被随机选为查询图片,其余82 616 张图片作为候选集.
本文采用常见的行人再识别评测指标,包括累积匹配曲线(Cumulative matching characteristics,CMC)和平均准确率均值(Mean average precision,mAP).CMC 表示前r个匹配结果中正确匹配的比例,r=1 表示首位匹配准确率.CMC 主要反映模型的准确率,mAP 则兼顾准确率和召回率.其中AP (Average precision)是某个类别所有返回结果的排列序号(Rank)倒数的加权平均值,mAP就是所有类别AP 值的平均值.
3.2 实验参数设置
我们使用Adam 优化器[41](β1=0.5,β2=0.999)训练M2M-GAN.训练数据为源域和目标域的训练集图片和对应的视角标记(摄像头编号),不使用任何行人类别标记.初始学习率设为0.0001,经历100 000 次迭代训练后学习率开始线性递减,直到第200 000次迭代时学习率递减为0.网络输入的图像尺寸重新调整为128×128 像素,批次大小设为16.式(10)和式(11)中有3 个超参数λ1,λ2,λ3,其中λ3控制循环一致损失的比重,本文参照文献[36]提供的设置,将其设为10.图6 显示了参数λ1和λ2对识别率的影响,可以看出当λ1取值为0.5~ 10.0,λ2取值为50~ 100 时,模型都能取得良好的识别率.特别地,当λ1和λ2取1 和100 时性能最好.因此,将λ1和λ2分别设为1 和100.

图6 不同参数对识别率的影响Fig.6 Influence of different parameters on the matching rate
行人特征学习网络使用在ImageNet 上预训练过的ResNet50[42]网络参数(替换掉最后一层全连接层)作为模型的初始化参数,然后使用生成的数据集及对应的行人类别标记来微调.特征学习网络用随机梯度下降法(Stochastic gradient descent,SGD)优化器训练,最后一层全连接层的初始学习率设为0.1,其余层的初始学习率设为0.01,训练30 回合(Epochs)后学习率变为原来的1/10.网络输入的图像尺寸重新调整为256×128 像素,批次大小设为64.
3.3 不同数据集上的实验结果
我们在3 个数据集上进行实验.当使用某个数据集作为目标域时,其余两个数据集分别作为源域来评估该源域迁移到目标域的行人再识别的性能.
3.3.1 迁移到Market1501 数据集的实验结果
本节实验选择Market1501 数据集作为目标域,分别评估DukeMTMC-reID 和MSMT17 数据集迁移到Market1501 数据集的结果.
首先分析M2M-GAN 生成图片的视觉效果.图7(a)是Market1501 数据集6 个视角真实图片的例子,图7(b)是DukeMTMC-reID→Market1501的效果,图7(c)是MSMT17→Market1501 的效果.图7(b)或图7(c)最左列是源数据集的真实图片,右边几列是左边图片变换到目标数据集(Market1501 数据集)各个视角的生成图片,每一列代表一个视角.可以看出,生成图片在视觉上更接近于Market1501 数据集的风格,而身份信息(行人外观)也没有丢失.各个视角的生成图片之间的差异不显著,这是因为Market1501 数据集各个摄像头的地理位置相距很近,拍摄到的数据分布相差不够明显.第3.3.2 节和第3.3.3 节展示的另外两个数据集更贴近实际应用场景.
然后定量分析迁移的效果,即把迁移后的数据用于行人再识别任务.表1 是分别从DukeMTMCreID 数据集、MSMT17 数据集迁移到Market1501数据集的跨域迁移行人再识别结果.为了公平对比,所有实验使用相同的参数设置.表中“Pre-training”表示直接把从源域真实数据训练得到的模型用于目标域测试.“CycleGAN”和“M2M-GAN”都是先进行图像风格迁移,再用变换后的新数据集训练行人再识别模型.其中“CycleGAN”相当于文献[34]提出的PTGAN,迁移时忽略了不同视角的差异性.“M2M-GAN”是我们提出的基于多视角的非对称迁移方法.根据表1 的实验结果可知,“Pre-training”和“CycleGAN”这两种不使用迁移或只用对称迁移算法的效果较差.与“CycleGAN”相比,“M2MGAN”的rank1 提高了11.7%和11.8%,mAP 提高了8.1%和7.7%,这验证了“M2M-GAN”的有效性.

表1 不同风格迁移方法在Market1501 数据集上的识别率(%)Table 1 Matching rates of different style translation methods on the Market1501 dataset (%)
特别地,“CycleGAN”比“Pre-training”的效果有所降低.“Pre-training”没有使用迁移方法,“CycleGAN”使用了迁移方法,但是却比不使用迁移(“Pre-training”)效果还差,这说明并不是所有迁移算法都能获得效果提升.虽然迁移算法能把部分源域的知识迁移到目标域,但是迁移过程中可能会有信息损失.仔细观察真实图片和对应的生成图片(图7),会发现生成图片丢失了一些行人细节信息.例如,生成图片中行人的鞋子、背包、五官等纹理变得模糊.使用这些损失了部分细节信息的图片来训练,会降低模型学习行人判别性特征的能力.但另一方面,图片风格迁移又会提高模型对目标域的适应程度.所以风格迁移算法既有提升(减小数据集差异)也有损失(迁移过程中的信息丢失),提升大于损失的迁移算法才能比无迁移算法的效果好.

图7 其他数据集迁移到Market 数据集的可视化例子Fig.7 Visual examples of translations from other datasets to the Market1501 dataset
接下来是训练时间和模型参数量的对比.表2是不同方法在Market1501 数据集上的训练时间和模型参数量对比,源数据集为DukeMTMC-reID 数据集.行人特征学习网络是完全一样的,所以只需对比生成对抗网络这一阶段.表2 中“CycleGAN”、“M2M-GAN”的含义与前文解释一致.“M×NCycleGAN”是本文设置的基准实验,在“CycleGAN”基础上考虑了多视角问题,对每种源域−目标域视角组合都单独训练一组生成对抗网络.从表2可知,“M×NCycleGAN”和“M2M-GAN”都能提升准确率,说明非对称迁移的重要性,但两者训练开销相差较大,“M2M-GAN”开销更少.另外,“M2M-GAN”准确率略高于“M×NCycleGAN”,说明同时用多对视角组合数据训练比单独用各对视角组合数据训练更能利用不同视角数据之间的相关性,使得迁移效果更好.

表2 不同方法在Market1501 数据集上的训练时间和模型参数量Table 2 Training time and model parameters of different methods on the Market1501 dataset
为了验证不同模块的重要性,我们进行了消融实验.本文在循环生成对抗网络基础上添加了视角嵌入模块、视角分类模块和身份保持模块(身份保持模块参考文献[34]),我们分别验证这些模块的作用.表3 是在生成阶段使用不同的网络模块,最终得到的行人再识别准确率.源数据集是DukeMTMC-reID 数据集,目标数据集是Market1501 数据集.由于身份保持模块是基于图片风格迁移的跨域行人再识别这类算法的基本模块,所以我们在保留了身份保持模块的基础上再对视角嵌入、视角分类这两个模块进行分析.对比表3 的第1 行和第2 行,可以验证身份保持的重要性.对比表3 的第2~ 4行,可以发现单独使用视角嵌入模块或者视角分类模块都能提高准确率,但准确率提升不明显.对比表3 的第3~ 5 行,可以发现同时使用视角嵌入模块和视角分类模块可以获得更显著的性能提升.这是因为视角嵌入模块为生成器提供了辅助信息输入,视角分类模块为生成器提供了监督信号,两个模块配合使用才能取得理想的效果.另外,视角分类损失和身份保持损失的权重分析如图6 所示,当λ1取值为0.5~ 10.0,λ2取值为50~ 500 时,模型都能取得良好的识别率.

表3 不同模块在Market1501 数据集上的准确率分析(%)Table 3 Accuracy of different modules on the Market1501 dataset (%)
最后我们还与目前最先进的无监督行人再识别方法进行了对比.将对比的方法分成3 组,第1 组是基于手工特征和欧氏距离的方法;第2 组是基于聚类的无监督方法;第3 组是基于跨域迁移学习的方法.这些方法都没有用到目标域的标注信息,属于无监督学习范畴.由表4 可知,本文的方法在Market1501 数据集上的Rank1 达到63.1%,mAP达到30.9%,高于大多数算法,特别是高于其他基于生成对抗网络的方法.另外,TJ-AIDL[43]使用了行人属性信息,但我们的结果依然比该方法要好.虽然本文的方法低于ARN (Adaptation and reidentification network)[44],但是本文与ARN 是不同类型的算法.基于生成对抗网络的这类方法单独考虑迁移和行人再识别问题,生成的风格迁移图像可以直接输入到各种有监督行人再识别模型中,不需要调整行人再识别模型结构.所以基于生成多抗网络的跨域迁移方法具有很强的灵活性和发展前景.并且当图片生成技术或者有监督行人再识别技术有所提升时,基于生成对抗网络的跨域行人再识别性能也将得到进一步提高.因此,本文提出的方法虽然低于ARN,但在基于生成对抗网络的这一类方法中取得最好的效果,同样具有应用前景和研究价值.

表4 不同无监督方法在Market1501 数据集上的识别率(%)(源数据集为DukeMTMC-reID 数据集)Table 4 Matching rates of different unsupervised methods on the Market1501 dataset (%) (The source dataset is the DukeMTMC-reID dataset)
3.3.2 迁移到DukeMTMC-reID 数据集的实验结果
本节实验选择DukeMTMC-reID 数据集作为目标域,所有图表的含义与第3.3.1 节实验完全相同.
图8 是M2M-GAN 生成图片的视觉效果,可以看出生成图片在视觉上更接近于DukeMTMCreID 数据集的风格,并且各个视角的生成图片之间有明显的差别,主要差别是图片的背景.迁移到DukeMTMC-reID 数据集不同视角的图片有不同的背景,这与DukeMTMC-reID 数据集实际的数据分布是相符的.

图8 其他数据集迁移到DukeMTMC-reID数据集的可视化例子Fig.8 Visual examples of translations from other datasets to the DukeMTMC-reID dataset
然后是定量分析迁移的效果.从表5 可以得出与Market 数据集实验类似的结论.与“Pre-training”和“CycleGAN”相比,“M2M-GAN”有效提高了行人再识别准确率.

表5 不同风格迁移方法在DukeMTMC-reID数据集上的识别率(%)Table 5 Matching rates of different style translation methods on the DukeMTMC-reID dataset (%)
接下来是训练时间和模型参数量的对比.由表6可知,“M2M-GAN”的准确率比“CycleGAN”和“M×NCycleGAN”高,而训练时间和网络参数量只略微高于“CycleGAN”,远低于“M×NCycleGAN”.再一次表明了“M2M-GAN”有效提升了识别准确率,同时不需要大量的训练开销.

表6 不同方法在DukeMTMC-reID 数据集上的训练时间和模型参数量Table 6 Training time and model parameters of different methods on the DukeMTMC-reID dataset
表7 是消融实验结果.与第3.3.1 节Market1501数据集上的消融实验结果类似,分别加入视角嵌入模块或者视角分类模块都能使行人再识别准确率略微提升.但是视角嵌入和视角分类两个模块同时使用,可以取得更显著的提升.这说明了本文方法的每个模块都是有效的,并且同时使用能够取得更好的效果.

表7 不同模块在DukeMTMC-reID 数据集上的准确率分析(%)Table 7 Accuracy of different modules on the DukeMTMC-reID dataset (%)
最后是与其他方法进行对比.由表8 可知,本文的方法在Market1501 数据集上的Rank1 达到54.4%,mAP 达到31.6%,超过了其他基于生成对抗网络的方法,仅低于ARN[44].
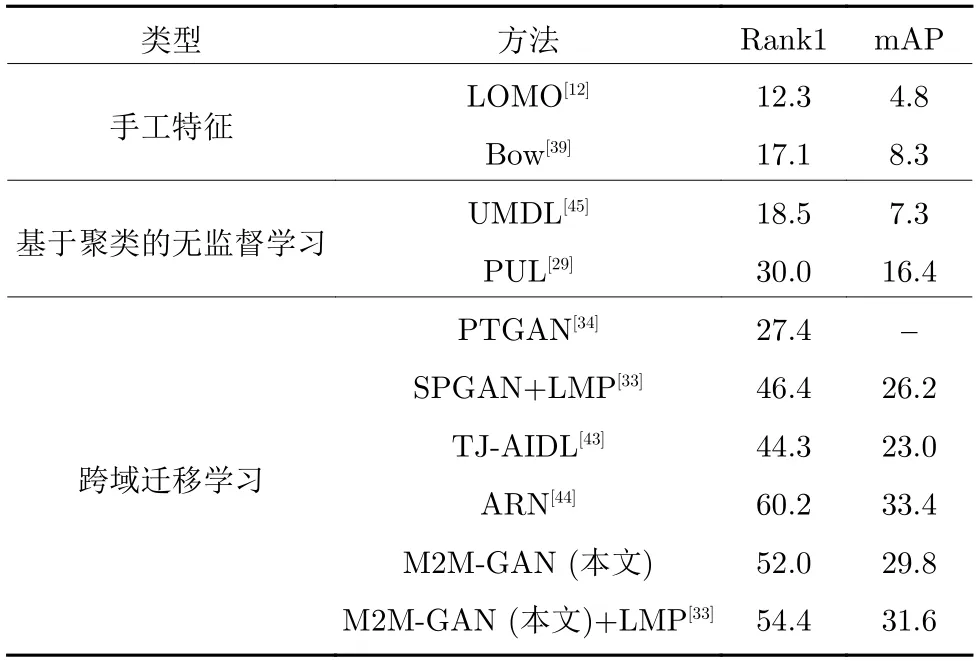
表8 不同无监督方法在DukeMTMC-reID 数据集上的识别率(%) (源数据集为Market1501 数据集)Table 8 Matching rates of different unsupervised methods on the DukeMTMC-reID dataset (%)(The source dataset is the Market1501 dataset)
3.3.3 迁移到MSMT17 数据集的实验结果
本节实验选择MSMT17 数据集作为目标域,所有图表的含义与第3.3.1 节实验完全相同.图9是其他两个数据集迁移到MSMT17 数据集的可视化例子.可以看出,生成的图片在保持身份信息不变的同时视觉上更接近于MSMT17 数据集的风格,并且各个视角的生成图片服从不同的分布.最明显的差别是光照不同,其次是背景信息不同,这与MSMT17 数据集的实际情况完全相符,也验证了多对多生成对抗网络能同时进行多个视角的迁移,而且迁移效果更好.

图9 其他数据集迁移到MSMT17 数据集的可视化例子Fig.9 Visual examples of translations from other datasets to the MSMT17 dataset
定量分析行人再识别的准确率也得出与前两个数据集类似的结果.由表9 可得,在MSMT17 数据集上,“M2M-GAN”比“CycleGAN”和“Pre-training”这两种方法的效果好很多.与“Pre-training”相比,“M2M-GAN”的Rank1 提升了17.7% 和16.6%.与“CycleGAN”相比,“M2M-GAN”的Rank1 提升了9.2%和12.1%.与前两个数据集相比,“M2M-GAN”在MSMT17 数据集的优势最明显,原因在于MSMT17 数据集摄像头数目多、摄像头数据分布差异大.这说明了我们提出的“M2M-GAN”比其他方法更能适用于复杂的现实场景.表10 与其他方法对比也体现“M2M-GAN”的良好效果.

表9 不同风格迁移方法在MSTM17数据集上的识别率(%)Table 9 Matching rates of different style translation methods on the MSTM17 dataset (%)

表10 不同无监督方法在MSMT17 上的识别率(%)(源数据集为Market1501 数据集)Table 10 Matching rates of different unsupervised methods on the MSMT17 dataset (%) (The source dataset is the Market1501 dataset)
4 结论
目前跨域迁移行人再识别的方法忽略了域内多个视角子分布的差异性,导致迁移效果不好.本文提出了基于多视角(摄像机)的非对称跨域迁移的新问题,并针对这一问题设计了多对多生成对抗网络(M2M-GAN).M2M-GAN 考虑了源域多个视角子分布的差异性和目标域多个视角子分布的差异性,并共同优化所有的源域−目标域视角组合.与现有不考虑视角差异的迁移方法相比,M2M-GAN 取到更高的识别准确率.在3 个大规模行人再识别基准数据集上,实验结果充分验证了本文提出的M2M-GAN 方法的有效性.未来的研究工作将考虑除视角以外的其他划分子域的方式,例如按照不同的光照或行人背景进行划分,这样能更好地刻画出一个域内的多个子分布的统计特性,进一步提高迁移的性能.
