基于自注意力对抗的深度子空间聚类
2022-02-17吴浩杨谢胜利杨其宇
尹 明 吴浩杨 谢胜利 杨其宇
聚类作为无监督学习的技术[1],是许多领域中常用的统计数据分析技术,如图像分割、人脸识别、文本分析等.给定一组数据,聚类算法旨在将数据分成若干簇,同一簇内的数据具有相似特征,而不同簇的数据具有较大差异的特征,通常衡量数据相似性可采用某种距离函数,如欧氏距离、闵可夫斯基距离、信息熵等.目前较流行的聚类方法有k均值(k-means)聚类[2]、层次聚类[3]、谱聚类[4]等.然而现实生活中存在高维数据,单独使用以上方法聚类的效率极低,并且在数据存在噪声干扰时结果也不够鲁棒.
近年来各国学者发现,虽然高维数据的结构在整个数据空间很难聚类,但高维数据的内在结构通常小于实际维度,并且簇结构可能在某个子空间很容易被观测到[5].因此,为了聚类高维数据,子空间聚类(Subspace clustering,SC)[6]假定高维空间可分成若干个低维子空间,然后将这些低维子空间中提取的数据点分割成不同的簇[7].子空间聚类目前主要有4 大类:迭代法[8]、代数法[9]、统计法[10]、基于谱聚类的方法[11−16].其中基于谱聚类的子空间聚类一经提出就受到了广泛的关注,其基本思想是首先计算数据点间的相似性来构建相似度矩阵,然后再采用谱聚类算法[17]获得最终聚类结果.其中最成功的两种子空间聚类算法为:稀疏子空间聚类(Sparse subspace clustering,SSC)[11]通过ℓ0范数正则化迫使每个数据由用同一子空间的其他数据点尽可能稀疏地表示,再利用表示系数构建相似度矩阵,所得的相似度矩阵可捕捉到数据的局部结构;低秩子空间聚类(Low-rank representation,LRR)[12]通过核范数正则化来获得数据的最低秩表示,这样获得的相似度矩阵具有数据的全局结构信息.这两种算法都采用了数据“自表示”机制,有效地刻画出数据的子空间结构.
另一方面,随着神经网络的发展,自动编码器(Autoencoders,AEs)[18]成为流行的特征学习方法.其通过编码器将原始数据编码成一个低维的编码,然后再通过解码器把低维的编码重构回原始数据,这个低维的编码数据可近视作原始数据的低维表示.2006 年,Hinton 等对自动编码器进行改进提出深度自动编码器(Deep autoencoder,DAE)[19],相较于自动编码器,由于加深了网络深度的DAE可获得更鲁棒的数据表示.之后,Vincent 等提出了去噪自动编码器(Denoising autoencoders,DAEs)[20]通过在数据中加入噪声来进一步提高鲁棒性.为了去掉数据的冗余信息,获得稀疏的数据表示,Bengio 等提出稀疏自动编码器(Sparse autoecoders,SAE)[21].Masci 等将编码器和解码器的全连接层网络替换为卷积神经网络提出堆叠卷积自动编码器(Stacked convolutional autoencoders,CAE)[22]从而减少网络的参数量.基于自动编码器网络在特征学习上的优势,有研究者将其与聚类[23−24]算法相结合:例如,深度嵌入聚类(Deep embedded Clusterng,DEC)[25],同时进行深度学习与聚类算法(Simultaneous deep learning and clustering,DCN)[23],深度连续聚类(Deep continuous clustering,DCC)[24]以及Ren 等提出基于深度密度的图像聚类算法(Deep density-based image clustering,DDC)[26]和半监督深度嵌入聚类(Semi-supervised deep embedded clustering,SDEC)[27]等.
在数据表示学习时,我们可以加深网络深度学习更深层的表示[28],但通常来说网络并不是越深越好,由于AE 网络深度过长导致一些信息丢失,尤其是某个特定特征[29−30].为了解决这一问题,注意力模型(Attention model)[30]被提出来.其基本思想是模仿人类的注意力机制,即人类会根据内部经验、外部感觉从一个庞大的信息快速聚焦于局部信息.其计算可分为两步:首先对输入信息计算注意力分布,然后根据注意力分布计算输入信息的加权平均.采用了自注意力机制的网络相较于其他特征学习网络,会忽视无关的背景信息.目前注意力模型主要包括软注意力模型(Soft attention model)[30−31]、硬注意力模型(Hard attention model)[32]、自注意力模型(Self-attention model)[33]、局部注意力模型(Local attention model)和全局注意力模型(Global attention model)[34]等.
深度学习另一个突破的进展为2014 年Goodfellow 等提出生成对抗网络(Generative adversarial networks,GAN)[35],由一个生成网络与一个判别网络组成,通过让两个神经网络相互博弈的方式进行学习.首先,生成网络从潜在空间(Latent space)中随机采样作为输入,其输出结果需要尽量模仿训练集里的真实样本.而判别网络的输入则为真实样本或生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来.最终生成器生成的样本近似于真实样本.近些年有学者发现生成对抗模型也可以在聚类分析上起到作用,Chen 等提出的Info-GAN[36]在原本的输入增加一个新的潜在编码(Latent code),来控制生成结果,当这个编码为离散编码时,该算法具有聚类的作用.Mukherjee 等提出ClusterGAN[37],在Info-GAN 的基础上增加一个编码器来对生成器生成的图像再进行编码来对输入的潜在编码进行约束,从而获得更好的聚类性能.值得注意的是,Makhzani 在2016 年将自动编码器和生成对抗网络相结合的对抗自动编码器(Adversarial autoencoders,AAE)[38],该算法在半监督分类和无监督聚类均有效果.
尽管上述方法在某种程度上提升了聚类精度,但如何有效地挖掘数据内蕴的子空间结构,获得更鲁棒的数据表示仍待进一步研究.因此,本文拟提出一种基于自注意力对抗机制的深度子空间聚类方法.在包含“自表示”网络层的深度自动编码器网络中,我们引入自注意力机制以捕捉重要特征信息,而且利用对抗网络增强特征学习的鲁棒性.由此,学习到更鲁棒的数据子空间结构,获得更优的聚类结果.归纳而言,本文的主要贡献为:
1) 提出一种利用对抗机制提升子空间聚类的算法,使得编码器学习到的特征表示更具有鲁棒性;
2) 引入自注意力模型来解决聚类分析中特征学习的长距离依赖问题.
本文章节安排如下:第1 节描述了和基于自注意力对抗的子空间聚类相关的算法,第2 节描述基于自注意力对抗的子空间聚类的网络结构以及原理,第3 节通过在MNIST,Fashion-MNIST 等数据集实验并分析,第4 节总结全文,并提出进一步的研究方向.
1 相关工作
本文方法是在深度子空间聚类框架中引入自注意力模型和对抗训练机制的方法,因此,本节将围绕子空间聚类、自注意力模型和生成对抗网络进行简要介绍.
1.1 深度子空间聚类
给定一数据集X={x1,x2,···xn} ∈Rd×n,假设这组数据集属于N个线性子空间子空间维度分别为假设属于某线性子空间Si的样本足够多,且张成整个子空间Si,则Si中的任意一样本x均能表示为X中除去x的线性组合,即数据集的“自表示”特性[7],则有如下子空间学习模型:

C ∈Rn×n为输入数据X的自表示系数矩阵,其中Ci为第i个数据Xi由其他数据表示的系数向量.∥C∥p为正则化项,∥·∥p为任意矩阵范数,如稀疏子空间聚类的1-范数∥C∥1[11],低秩子空间聚类核范数∥C∥∗[12]和F-范数[39].然后使用谱聚类算法对由自表示系数矩阵构建的相似度矩阵聚类,获得最终聚类结果.
学者们发现基于自表示方法利用不同的正则化项可以处理受损数据,例如,包含噪声和异常值的数据,而且自表示系数矩阵呈现出块对角化的结构,这非常有利于后续的谱聚类[7]处理.因此,如何获得鲁棒的自表示系数矩阵是基于谱聚类的子空间聚类算法的关键问题.
然而,上述子空间模型学习到的自表示结构仅适用于线性子空间.另一方面,现实数据常常具有高维的非线性结构,传统子空间学习受到限制.可喜的是,深度自动编码器可将数据转换至一个潜在的低维子空间,捕获数据的非线性结构,从而获得数据的低维特征表示.因此与深度神经网络结合的子空间学习旨在低维特征上学习数据的自表示系数,如深度子空间聚类算法(Deep subspace clustering,DSC)[40].DSC 首先采用深度自动编码器学习原数据的低维特征表示,然后利用一个由全连接网络构成的自表示层来学习数据的相邻关系,该自表示层将神经元连接的权重视为同一子空间中数据样本之间的相似度.其目标函数表示如下:


图1 深度子空间聚类网络结构图Fig.1 The framework of Deep Subspace Clustering
1.2 生成对抗网络
生成对抗网络(GAN)通过生成网络和判别网络相互博弈以达到纳什均衡[35−41],用G表示为生成器,D为判别器,其训练目标函数为:

式中,E(·) 表示分布函数的期望值,pdata(x) 为真样本分布,pz(z) 定义低维噪声分布,log(·) 表示对数运算.V(D,G)为真、假样本的差异程度,表示当生成器固定时,使判别器最大化地判别出样本来自于真实数据还是生成的数据,表示当判别器固定时,期望生成器最小化真样本与假样本的差异.
在生成对抗模型中,首先由随机向量或噪声z通过生成器生成一个假样本G(z),然后判别器对真样本x和假样本G(z) 进行真假判断.当判别器D对真样本x甄别越严格,D(x) 值也越接近于1,此时logD(x)值也就越接近于0.其标准网络结构如图2所示,通常式(3)中判别器损失采用交叉熵损失函数,即通过交叉熵来判别两个分布的相似性.当目标函数收敛时,生成分布将拟合于真实分布.
由于生成对抗网络可以将一个生成样本分布拟合于真实分布,使得其不仅局限于样本生成,而且任何数据分布均可采用生成对抗网络来拟合,例如,对抗自动编码器(AAE)[38]将特征表示分布拟合于标准高斯分布,获得与变分自动编码器(Variational autoencoders,VAE)[42]相似的效果.
1.3 自注意力模型
目前大多数注意力模型嵌入于编−解码器(Encoder-decoder)框架.通常一个高维的数据通过编码输出一个低维的特征表示时,会损失大量的信息,注意力模型可以对不同的数据信息加权平均,因此含有注意力模型的编−解码器框架会编码出一个低维且信息损失较少的特征表示.注意力模型的数学表达如下:

其中,s(·) 为计算Q和KT的相似度函数,K=V=fe(·),Q=fd(·) .一般,注意力模型可以抽象为计算输出信息Q与输入信息⟨K,V⟩的关联性.
自注意力模型是注意力模型家族中最为广泛应用的一种.在该模型中K,V与普通注意力模型一样来自于输入信息,另一方面为了能直接捕捉到输入数据矩阵中任意两个向量的关联性,Q也源于输入信息.但注意力模型不局限于编−解码器框架,例如,自注意力生成对抗网络(Self-attention generative adversarial networks,SAGAN)[43]中将自注意力模型引入生成对抗网络,不仅解决卷积结构带来的感受野大小限制,也使得在生成图像时,每个局部区域的生成会与全局细节相协调.
2 基于自注意力对抗的深度子空间聚类算法
尽管现有DSC 算法在一定程度上改善了聚类性能,但其网络结构的感受野受到限制[43],即过大的通道数导致卷积运算难以捕捉数据不同局部间结构,而且所学习到的数据隐特征分布无法重构具有判别性的样本.因此,本节提出一种基于自注意力对抗机制的深度子空间聚类算法,在DSC 网络中引入自注意力模块,并约束数据特征分布近似于任意的先验概率.
2.1 网络模型与结构
基于自注意力对抗的深度子空间聚类网络框架如图4 所示,为了保证在特征学习过程中长距离依赖,我们在编码模块的最后一层卷积网络后添加一个自注意力模块.其中自注意力模块结构如图3 所示,对前一层网络的数据通过1×1 的卷积网络获得K,V,Q.将K转置与V相乘并经过softmax 归一化得到注意力映射,再与Q点积得到最终的自注意力特征映射.在判别网络中,倒数第二层卷积网络中输出的通道数为1 000,由于过大的通道数会导致卷积运算很难处理不同局部间的关系,因此我们在此处也增加一个自注意力模块.

图3 自注意力模块Fig.3 Self-attention module

图4 基于自注意力对抗的深度子空间聚类网络框架Fig.4 The framework of self-attention adversarial network based deep subspace clustering
在训练生成对抗网络时,由于判别器过于强大很容易导致输出梯度值为0,即梯度消失,导致没有足够的梯度信息去更新生成器.针对生成对抗网络的梯度消失问题,不少学者对其损失函数进行改进.Arjovsky 等认为式(3)交叉熵的选择无论是KL-散度还是JS-散度都有其局限,提出Wasserstein GAN (WGAN)[44]采用Earth-mover (EM)距离衡量两个分布距离,并去掉了对数 log 运算,其生成损失和判别损失函数分开表述如下:

但是,上式中每次更新判别器需要将梯度信息绝对值截断,不超过某个固定常数来保证判别器的稳定性.因此,WGAN-GP (Improved training of Wasserstein GANs)[45]将梯度截断作为一个梯度惩罚项加入式(7)中,但这需要满足Lipschitz 条件才能保证梯度惩罚起作用,而Lipschitz 条件又使得截断的梯度值趋向于设定的固定常数的负值边界或者正值边界.为解决这个问题,Wu 等采用Wasserstein 散度的概念,提出Wasserstein divergence for gans (WGAN-div)[46]摆脱了WGAN-GP 对Lipschitz 条件约束的依赖.
综合前人研究的GAN 及其变种,我们网络中生成对抗网络部分的损失函数[46]构造如下:

其中,Zg=fe(X) 为输入数据的特征表示.如图4所示,在生成对抗网络结构中,编码模块可以视为一个生成模块,用于生成特征表示.
因此从生成对抗网络的角度看,Zg为假样本,真样本Zr来自于一个先验分布的采样,该先验可以服从标准高斯分布、混合高斯分布等.将真假特征同时输入至判别器网络,通过博弈训练使得生成器生成的特征分布结构趋向于设定的先验分布的结构,导致解码器能够将采用自先验分布p(z) 的样本生成为观测数据,从而提高特征学习的鲁棒性,增加网络的抗干扰能力.
考虑引入了生成对抗网络,我们对式(2)改写如下:

相比于式(2),上式中的特征表示已经过生成对抗网络优化,具有先验分布的结构特性.
此外,除自注意力模块外,我们还增加了一个残差模块来加深网络的深度.由于残差模块是深度神经网络内部的一部分,网络的损失函数保持不变.引入残差模块后,自注意力模块的输出与残差模块的输出相加作为下一个神经网络单元的输入.其中残差模块为两个卷积核大小为3×3 的卷积网络,卷积步长为1.
2.2 网络训练
结合聚类和生成对抗机制,网络的总体损失函数为

在训练生成对抗网络时,通过生成损失和判别损失迭代训练来达成彼此互相更新.因此,首先最小化(8)的损失来获得特征表示,然后再通过最小化判别损失和生成损失优化特征表示,以epoch 作为一个训练次数,反复迭代训练三个损失函数达到稳定.综上所述,我们的网络训练步骤如下:λ2,λ3
输.入.数据集X,学习率η,以及超参数λ1,
步骤 1.依据式(8)求得特征表示Zg.
步骤 2.依据式(7) 判断Zg与Zr之间的相似性,并由式(6)优化Zg.
步骤 3.依据式(8)更新Zg.
步骤 4.重复步骤1~ 步骤 3,直到达到最大epoch 值为止.
输出.自表示系数C.
一旦完成网络训练,将学习到数据的相邻关系,最后利用谱聚类对C进行聚类,获得数据的聚类结果.
3 实验结果与分析
本实验是基于Python 编程语言进行仿真,操作系统为Ubuntu,主要软件架构为TensorFlow 1.0,配置CUDA 8.0 和cuDNN 5.1,使用4 块英伟达GPU GTX 1080Ti.
3.1 实验数据集与参数设置
为了验证所提算法的有效性,我们在5 个公开的数据集上进行了实验,两个手写数字数据集MNIST[47]和USPS,一个物品数据集COIL-20[48],一个人脸数据集Extended Yale B[49](下文统称YaleB)以及一个衣服数据集Fashion-MNIST (下文统称FMNIST).数据集的详细信息见表1 所示.

表1 数据集信息Table 1 Information of the datasets
针对5 个数据集,我们的实验参数如表2 所示.其中,λ1和λ2分别为对自表示项和正则化项贡献度的权重参数,为了方便调参,我们令λ1=1 .此外,在实验过程中,我们发现式(7)中的参数λ3对结果影响式微,可能是生成对抗网络中只要存在梯度惩罚便可使网络稳定.

表2 参数设置Table 2 Parameter setting
3.2 网络结构信息
实验中编码器网络结构为三层卷积网络,解码器和编码器的网络结构对称,Fashion-MNIST 编码器为一层卷积网络和三个残差模块,解码器也保持对称,COIL-20 仅用一层卷积网络,卷积网络具体参数如表3 所示.

表3 网络结构参数Table 3 Network structure parameter
所有实验中判别器网络采用三层卷积网络,均为1×1 的卷积核,以便增加通道的信息交互,其通道数为[1 000,1 000,1].同时,我们将自注意力模块加在判别器网络的倒数第二层以增加1 000 个通道特征的长距离依赖.对于算法的预训练,大多数以自动编码器为架构的深度聚类算法均采用了自动编码器来进行预训练.但由于本文算法引入了生成对抗网络,为了避免判别器初始训练过于强大而干扰特征学习,因此我们使用对抗自动编码器(AAE)进行预训练.
所有实验采用Adam[50]优化,在激活函数的选择上,除YaleB 采用leaky relu 外,其他几个数据集均采用relu,式(8)学习率设置为0.0001,动量因子为0.9,式(6)和(7)学习率为0.0001,动量因子为0.9,batchsize 为表1 中对应的样本数量.
3.3 评价指标
为了评估我们算法的优越性,我们采用两个常用的度量方法:聚类精度(ACC) 和标准互信息(NMI)[51]来作为聚类的效果.

式(11) 中,I(·) 表示为互信息,即两个随机变量的相关程度,H(·) 为熵,A与B分别表示聚类的标签和正确标签,其中I(A,B)=H(A)+H(B)−H(A,B).
3.4 实验结果
在实验中,本文采用了与所提出算法相关的深度聚类方法进行实验结果对比,其中包括:Struct-AE[52]、DASC[53]、DCN、DSC 及DEC.实验结果如表4 所示,实验数据均为重复30 次的平均值,其中加粗数字表示最优值.因StructAE 与DASC 作者没有开源代码,其实验数据为引用自原论文.此外,由于其没有在FMNIST 和USPS 上进行实验,因此在这两个数据集上无实验数据对比.DSC 在数据集YaleB、COIL-20、MNIST 的实验结果引用其论文,而在FMNIST 和USPS 的实验结果为我们测试所得.DEC 与DCN 在YaleB 和COIL-20 上的实验结果为我们测试,其余引用原论文结果.其中DEC 在YaleB 的实验结果过于不合理,我们多次调节网络参数均无明显改变,因此DEC 在YaleB无测试结果,用“*”表示.
从表4 可看出,我们算法在ACC 和NMI 指标上均优于其他6 个深度聚类算法,通过DSC-L1、DSC-L2 和我们算法结果对比可看出经过自注意力生成对抗网络学习到的特征表示在聚类上可以获得更好的结果,例如,在MNIST 数据集上,我们的算法相比于次优DEC 的ACC 和NMI 分别提高了0.1110 和0.1281.DEC 在YaleB 上的结果与DCN在COIL-20 上结果欠佳是因为其没有自表示结构,没有很好地捕捉数据之间的关联性.DSC、DASC以及我们的算法均含有自表示结构,因此在部分数据上性能要优于DEC 和DCN.为了探讨我们生成对抗网络的稳定性,因此我们对MNIST 的训练损失可视化.如图5 所示,可看出生成损失和判别损失存在对称性,表明式(5)中的梯度惩罚项是的网络中生成器和判别器的相互博弈均衡,不存在一方过于强大的现象.此外,本文算法的网络训练损失曲线呈现逐渐下降的走势,且最终趋向平缓,表明在自表示系数学习过程中,网络稳定,损失函数收敛,并没有因生成对抗损失的引入导致存在不稳定现象.此外DSC 网络中相较于SAADSC 没有自注意力模块和对抗网络,我们选择了DSC-L2 的结果进行对比,可发现增加自注意力模块和对抗网络后,算法在聚类精度和标准互信息上均有所提高.

图5 MNIST 的网络训练损失Fig.5 The loss function of SAADSC during training on MNIST
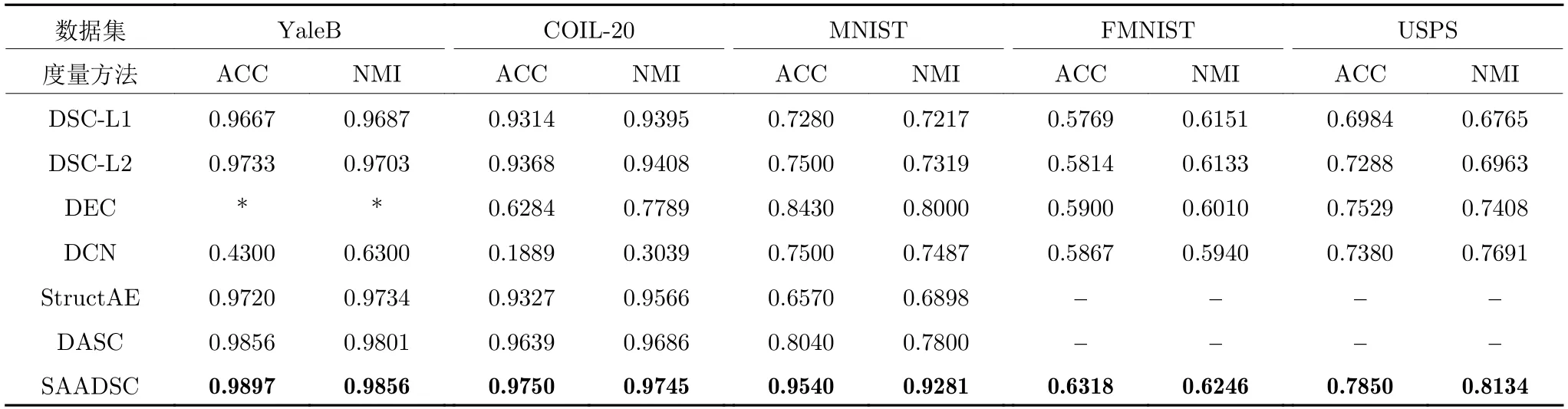
表4 5 个数据集的实验结果Table 4 Experimental results of five datasets
为了探讨不同先验分布对结果的影响,我们选择三种不同的分布在三个数据集上进行实验对比.如表5 所示,高斯分布取得最优的结果,这是因为当样本容量无限大的时候,数据的样本分布趋向于高斯分布.其次,高斯分布的熵值很大,当数据分布未知时选择熵值最大的模型效果会更好.

表5 不同先验分布的实验结果Table 5 Clustering results on different prior distributions
3.5 各模块作用分析 (Ablation study)
为了评估所提出网络中每个模块的作用,我们分别对其进行测试,Test1 表示去掉自注意力模块及残差模块后的网络;Test2 为去掉自表示层的网络,通过谱聚类算法对构成的邻接矩阵进行聚类;Test3 为排除自表示层后使用K-means对Zg聚类;Test4 排除了网络中残差模块.实验结果如表6 所示,我们可以看出残差模块对网络贡献力度最小,自表示层作用最大,其次是自注意力模块.由于自表示层构建数据之间的线性表示,通过自表示层获得的系数矩阵反映了类内数据的关联性和类间数据的不相关性.

表6 SAADSC 网络中不同模块的作用Table 6 Ablation study on SAADSC
3.6 鲁棒性实验
另外,为了测试我们的特征表示相比于深度子空间聚类算法是否更具有鲁棒性,针对COIL-20和USPS 数据集我们进行了噪声测试.具体而言,将对应百分比的像素点替换为随机的高斯噪声,采用算法DSC-L1、DSC-L2 和DASC 进行对比,因DASC 代码没开源,因此其在USPS 噪声实验中,无对比数据.且由于DASC 采取柱状图进行对比,因此表7 中COIL-20 的实验数据为对其论文柱状图的近似估计.其余均为测试结果.实验结果如表7和表8 所示.可看出,DSC-L1 和DSC-L2 随着噪声越大结果下降越明显,而DASC 和SAADSC 由于引入生成对抗网络使得算法具有抗干扰能力.相较于DASC,我们的网络的自注意力机制会在生成对抗学习过程中起到积极作用,从而提升了算法的抗干扰能力.

表7 含有噪声的COIL-20 聚类结果Table 7 Clustering results on the noisy COIL-20

表8 含有噪声的USPS 聚类结果Table 8 Clustering results on the noisy USPS
4 结论
针对现实数据结构复杂、如何获得更鲁棒的数据表示以便改善聚类性能问题,本文提出一种基于对抗训练的深度子空间聚类,利用对抗网络的博弈学习能力使得编码器网络学习到的特征表示服从预设定的先验分布特性,而且引入自注意力机制和残差网络模块,来增强特征学习的鲁棒性,从而提升聚类性能.实验结果表明,本文算法结在精确率(ACC)和标准互信息(NMI)等指标上都优于目前最好的方法.
