基于近红外光谱技术的远安黄茶品质快速无损检测方法
2022-02-17王胜鹏郑鹏程桂安辉滕靖刘盼盼叶飞高士伟马梦君刘小英
王胜鹏,郑鹏程,桂安辉,滕靖,刘盼盼,叶飞,高士伟,马梦君,刘小英
1.湖北省农业科学院果树茶叶研究所,武汉 430064; 2.咸宁市农业科学院,咸宁 437100; 3.恩施花枝山生态农业股份有限公司,恩施 445000
黄茶是我国六大茶类之一,湖北则以远安黄茶历史最为悠久。茶鲜叶经摊放、杀青、闷黄和烘干后加工为远安黄茶,其具有外形卷曲紧结带钩、色泽金黄、香气清香持久、滋味醇厚回甘、汤色杏黄明亮和叶底嫩黄匀整等特点[1-2],深受消费者喜爱。因此,对远安黄茶品质开展评价就显得非常重要。通常应用感官审评方法对农作物品质开展评价[3-4],在茶叶研究领域已实现对绿茶[5]、红茶[6]和乌龙茶[7]等茶类的品质评价。传统感官评价方法虽然经典,但专业性较强,评审结果易受审评员嗜好差异等因素影响,主观性较强。化学检测方法通过测定内含成分含量来评价茶品质,结果较客观、准确,但测定前需先粉碎样品,且测定过程费时、费力,还需使用大量的化学试剂,可能会造成环境污染,不利于茶品质的快速检测[8]。因此,非常有必要建立一种快速无损、科学客观的远安黄茶品质评价方法。
近红外光谱(near infrared spectroscopy,NIRS)技术是一种绿色的分析技术[9],主要反映样品内部成分X—H化学键信息,通过建立某一化学成分含量的预测模型从而实现样品的快速、无损检测。NIRS技术目前已在农业、饲料和医药等[10-12]行业得到广泛应用。此外,NIRS技术还应用于对茶叶中茶多酚、游离氨基酸、含水量、咖啡碱等含量的快速预测和茶鲜叶质量的快速评估[13]以及茶品质的评价[14-15]等方面。
目前,有关黄茶的研究主要集中在黄茶适制品种的筛选[16]、闷黄过程中品质成分的变化[17]、闷黄和加工工艺的优化[18]以及黄茶生理保健功效[19]等方面,还较少有应用近红外光谱技术在远安黄茶品质成分分析方面开展研究的报道。本研究基于近红外光谱技术,分别结合偏最小二乘法、反向区间偏最小二乘法(backward interval partial least squares,Bi-PLS)、遗传算法(genetic algorithm,GA)和人工神经网络方法(artificial neural network,ANN)筛选最佳光谱预处理方法和提取特征光谱数据点,建立远安黄茶品质预测模型,并尝试解析光谱官能团信息,以期为远安黄茶品质的快速无损评价提供新的思路。
1 材料与方法
1.1 试验材料
采集湖北省宜昌市远安县嫘祖黄茶有限公司基地的标准一芽二叶安吉白茶鲜叶,经杀青、闷黄等工序加工,获得90个远安黄茶样品,样品加工时间为2016年4月至5月。依据样品不同品质,将样品按照4∶1比例分为建模样品(72个)和外部测试样品(18个)。72个建模样品用于建立预测模型,以品质分数为依据将样品按照2∶1比例划分为校正集(48个样品)和验证集(24个样品),其中验证集样品用于检验模型的稳健性。18个测试样品用于检验模型的实际预测效果。
1.2 方 法
1)感官审评。根据GB/T 23776―2018《茶叶感官审评方法》标准方法对远安黄茶品质进行评价。5位感官审评专家采用密码评审方式对样品品质进行打分,满分为100 分,品质越好,分数越高。以平均值作为该样品的最终品质得分。
2)近红外光谱采集。应用Antaris Ⅱ型傅里叶变换近红外光谱仪,采用漫反射方式扫描获得样品的近红外光谱,仪器光谱范围为4 000~10 000 cm-1,分辨率为8 cm-1,检测器为InGaAs。在扫描样品前,为使仪器达到最佳性能,保证状态稳定,通常先将仪器预热1 h后再扫描光谱,以镀金为光谱扫描背景。扫描时,将10 .0 g样品装入与仪器配套的旋转杯中,用压样器充分压实样品,保证光谱无法穿透样品,确保获得样品的全部光谱信息。每个样品重复装样3次扫描得到3条光谱,每条光谱扫描64次,取3条光谱的平均值作为该样品的最终光谱值。
3)光谱数据分析。应用TQ Analyst 9.4.45软件将每条近红外光谱转化为1 557对数据点保存于Excel表中,应用OPUS 7.0 软件和Matlab 2012a软件对光谱数据进行预处理和建立预测模型。光谱扫描过程中往往会包含一些与样品性质无关的因素带来的干扰,如样品的状态、光的散射及仪器响应等的影响,导致光谱基线漂移和产生噪声信息。为有效去除光谱中夹杂的大量噪声信息,提高光谱的信噪比,分别比较标准变量变换(standard normal variate,SNV)、多元散射校正(multiple scatter correction,MSC)、消除常数偏移量(eliminate constant offset,ECO)、矢量归一化(vector normalization,VN)、减去一条直线(subtract straight line,SSL)、一阶导数(first derivative,FD)和二阶导数(second derivative,SD)等光谱预处理方法的建模效果,得到最佳预处理方法。
应用反向区间偏最小二乘法[20](backward interval partial least squares,Bi-PLS)筛选反映远安黄茶品质的特征光谱区间。在PLS基础上,Bi-PLS将全部光谱数据点等划分为20~24个光谱子区间,然后联合其中的2~4个光谱区间建立预测模型,当交互验证均方根误差(root mean square error of cross validation,RMSECV)最小时,此时得到的光谱区间即为筛选的最佳光谱区间。RMSECV计算公式如下:
(1)
式(1)中:n为校正集样品数;yi为样品i实测值;yi′为校正集样品i预测值。
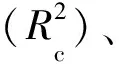
RMSEP计算公式如下:
(2)
式(2)中:n为验证集样品数;yi为样品i实测值;yi′为验证集样品i预测值。
2 结果与分析
2.1 远安黄茶感官品质分析
从表1可知,远安黄茶全部样品的感官品质分数为78.40~92.05,平均值为88.96,标准偏差为2.55;而以感官分数为分类依据,校正集样品感官分数范围为78.40~92.05,平均值为89.05,标准偏差为2.61;验证集样品感官评分范围为84.95~91.75,平均值为89.11,标准偏差为1.83。验证集样品品质分数处于校正集样品范围内,为建立一个稳健的预测模型提供了良好的前提条件。

表1 远安黄茶感官品质分数统计 Table 1 Statistics of sensory quality of Yuan’an yellow tea
2.2 光谱预处理方法筛选
从图1可以看出,不同品质远安黄茶近红外光谱整体变化趋势是一致的,随着黄茶品质的逐渐升高,光谱吸光度也逐渐增大,但在9 800~10 000 cm-1和4 000~4 200 cm-1这2个区间段存在较多的噪声信息。因此,在建模时应舍弃这2个波数区间。在6 900 cm-1和5 100 cm-1附近是游离水的—OH吸收峰,可能会影响品质模型的预测精度。此外,尝试应用多种预处理方法对样品光谱进行预处理,并用PLS方法建立品质分数预测模型,得出较佳的光谱预处理方法。

图1 远安黄茶样品近红外光谱Fig.1 Near infrared spectroscopy of Yuan’an yellow tea

2.3 Bi-PLS模型建立

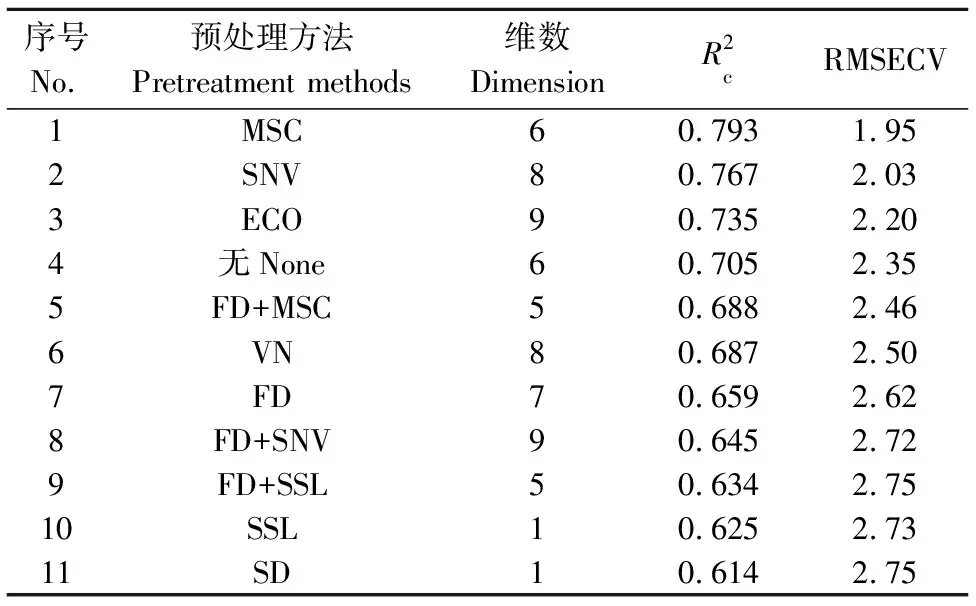
表2 不同光谱预处理方法的处理结果 Table 2 Comparison of spectral pretreatment methods
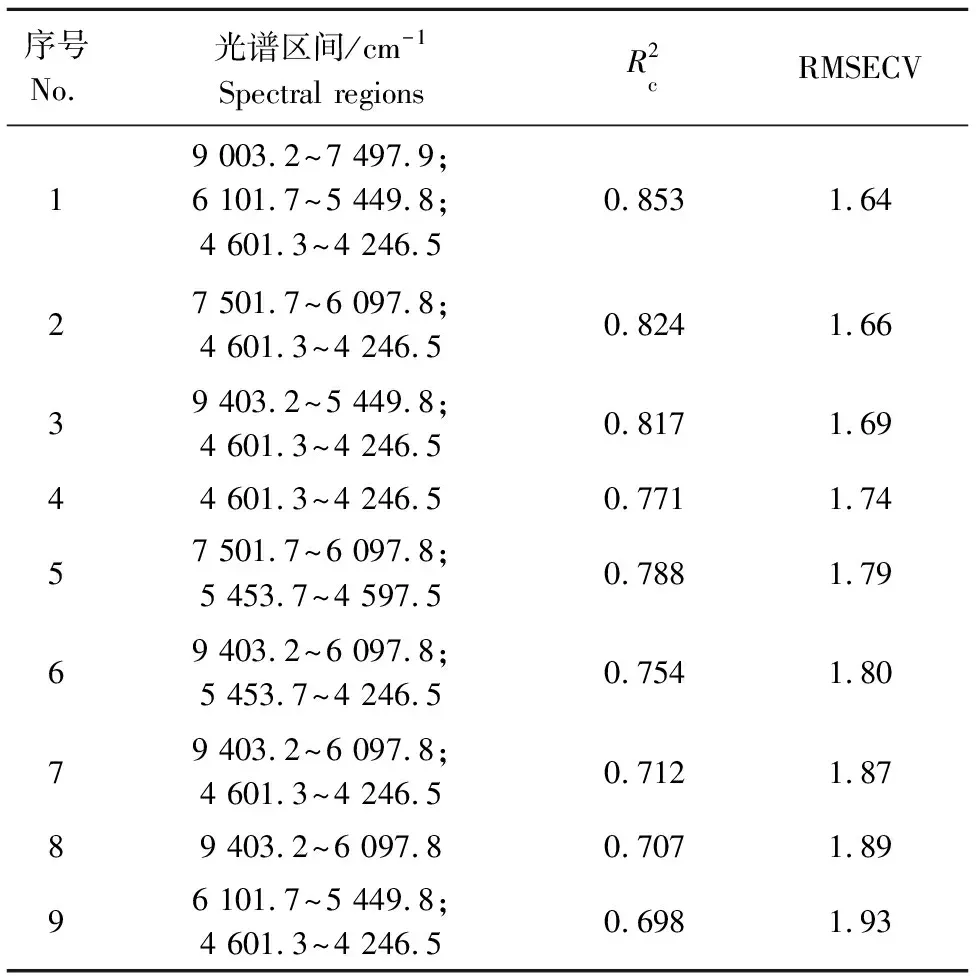
表3 远安黄茶品质Bi-PLS模型预测结果 Table 3 Results of Bi-PLS models for Yuan’an yellow tea
2.4 Bi-GA-PLS模型建立
虽然Bi-PLS方法可以筛选特征光谱区间,但在光谱区间中还会存在较多与品质无关的光谱数据点,因此,非常有必要进一步精准提取出与品质密切相关的光谱数据点。用遗传算法对9 003.2~7 497.9 cm-1、6 101.7~5 449.8 cm-1和4 601.3~4 246.5 cm-13个特征波段内的650个数据点进一步筛选。遗传迭代的参数设置为:初始群体48,交叉概率0.8,变异概率0.01,遗传迭代100次。通过观察遗传迭代后不同变量数的频率变化(图2)和与RMSECV的变化关系(图3) ,当RMSECV最小时,此时参与建模的变量即为反映远安黄茶品质的最佳NIRS数据点。
从图2和图3可以看出,应用GA优化特征光谱区间的650个波数点,每个数据点的使用频率代表其对建模的重要性程度,其中绝大多数数据点的使用频率小于5次,表明与品质无关的数据点较多。当最佳建模数据点为75个时,Bi-GA-PLS校正集模型RMSECV最小为1.521,此时筛选得到的数据点即为最佳的反映远安黄茶品质的NIRS数据点。75个光谱数据点的使用频率和与之对应的波数值见图4。从图4可以看出,光谱数据点最大使用频率为22次,最小使用频率为7次,使用频率大于或等于11的光谱数据点共14个,占全部最佳数据点的比例为18.67%。依据数据点的使用频率可以保证将最佳光谱数据点从大量的冗余信息中提取出来,有利于改善模型预测效果。在所有最佳光谱数据点中,最大光谱数据点为8 990.5 cm-1,最小光谱数据点为4 258.1 cm-1。其中,在9 003.2~7 497.9 cm-1波段中共有390个数据点,有40个数据点被提取为最佳数据点;在6 101.7~5 449.8 cm-1波段中共有168个数据点,有13个数据点被提取为最佳数据点;在4 601.3~4 246.5 cm-1波段中共有92个数据点,有22个数据点被提取为最佳数据点。
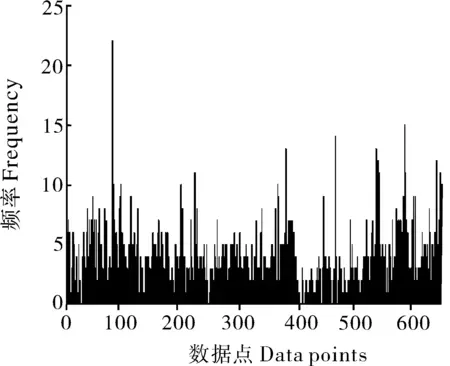
图2 光谱数据点频率变化Fig.2 Frequency variation of spectral data points

图3 RMSECV与建模最佳数据点关系Fig.3 Relationship between RMSECV and the best data points of model
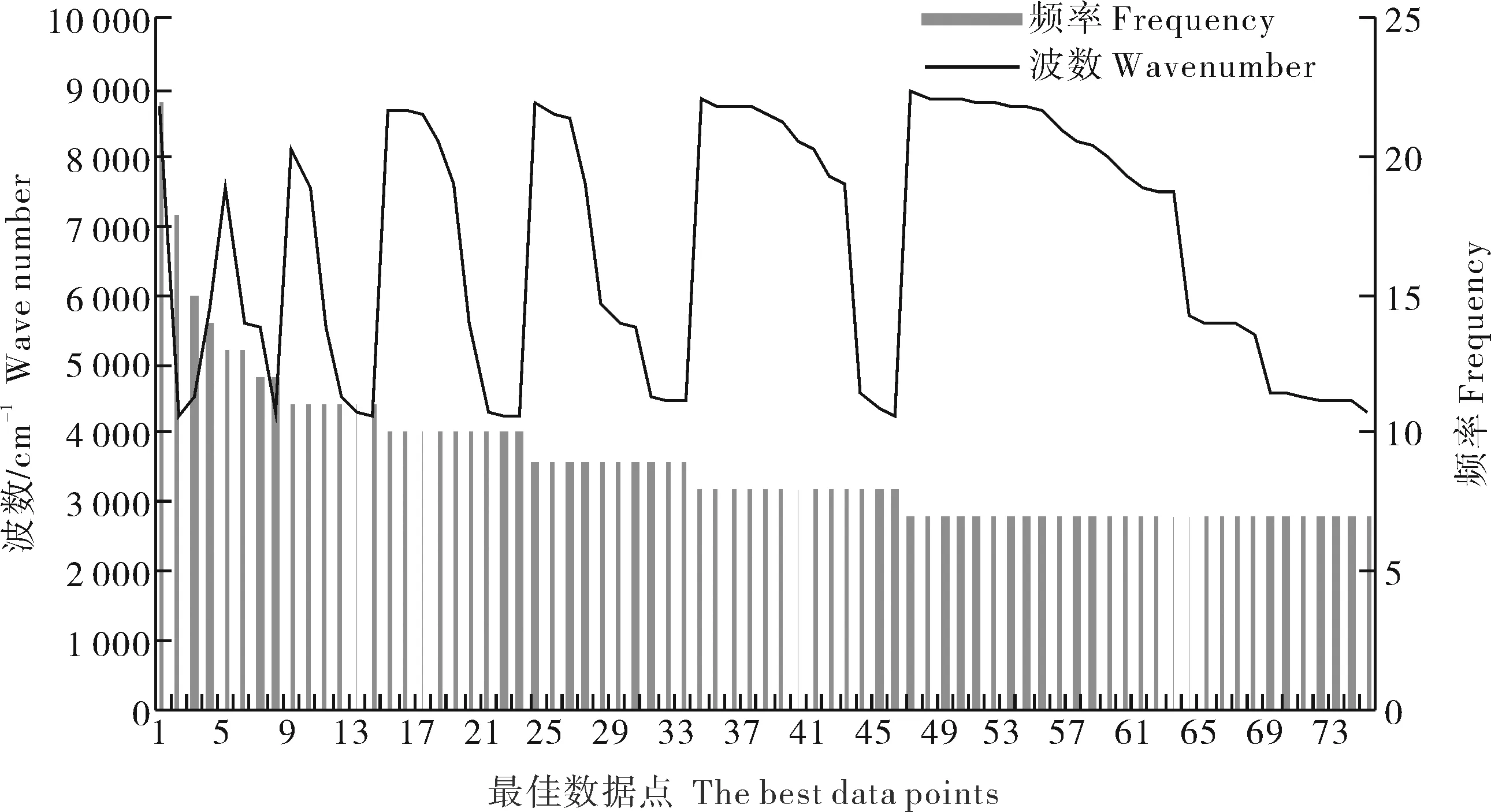
图4 最佳光谱数据点的频率与波数Fig.4 Frequencies and wavenumbers of the data points
2.5 Bi-GA-BP-ANN模型建立及模型优势比较
以遗传算法筛选的75个最佳光谱数据点为输入值,以远安黄茶品质为输出值,应用反向传播人工神经网络方法建立远安黄茶品质的近红外光谱Bi-GA-BP-ANN预测模型。在建立人工神经网络模型过程中,设置学习速率为0.1,传递函数为linear[-1,1],模型所得结果见表4。建立远安黄茶品质分数全波长PLS模型、Bi-PLS模型、Bi-GA-PLS模型、全波长GA-PLS模型和Bi-GA-ANN模型(表4),并分别用验证集样品和外部样品对上述5种模型的稳健性进行检验,比较不同方法间建立模型的优越性。


表4 5种模型预测结果优势比较 Table 4 Comparison of prediction results of five models
3 讨 论
3.1 特征光谱区间的筛选
每条样品NIRS都由1 557对数据点组成,数据量巨大,如果应用全部光谱数据建立模型,不仅造成建模时间较长,而且由于冗余信息的存在,致使模型欠稳健,不利于后期维护和使用。因此,非常有必要选取与样品密切相关的NIRS信息,而仅依靠去除样品中的噪声信息显然达不到目的,必须借助其他的数学方法从众多的信息中筛选出建模的特征光谱数据。应用Bi方法筛选出最能反映远安黄茶品质的子区间后建立PLS模型,经比较表2和表3的模型结果,应用Bi-PLS方法建立的远安黄茶品质NIRS模型,不仅建模的光谱数据少(占全部光谱数据的41.80%),而且模型的效果还得到了有效提升(RMSECV下降了15.83%)。筛选的特征光谱区间分别为9 003.2~7 497.9 cm-1、6 101.7~5 449.8 cm-1和4 601.3~4 246.5 cm-1。在3个子区间范围内,均没有包含水的—OH近红外光谱(6 900 cm-1和5 100 cm-1)信息,避免了H2O峰的高吸收对模型的影响。在已有研究中,与茶品质有关的内含成分主要为茶多酚、可溶性糖、咖啡碱、游离氨基酸和可溶性蛋白质等物质[24]。其中,茶多酚与茶苦涩味的形成有一定的关系,具有一定的收敛性;可溶性糖可增强茶汤的黏稠度,改善茶汤的滋味;咖啡碱与茶汤的苦味有关,游离氨基酸和可溶性蛋白质可提高茶汤的鲜味。上述这几类物质主要含有苯、酚羟基、—CHx、—C=O、—COOH和—NHx等官能团,在近红外光谱区间,6 000 cm-1附近是苯官能团的组合频信息区域,主要反映了茶多酚的光谱信息;5 555~5 882 cm-1是—CHx一级倍频信息区域,8 264~8 696 cm-1是—CHx二级倍频信息区域,4 545~4 500 cm-1和6 666~7 690 cm-1是—CHx组合频信息区域,主要反映了单糖等葡萄糖和咖啡碱等茶叶碱以及茶氨酸等游离氨基酸的光谱信息;4 760~4 445 cm-1是—C=O组合频信息区域,4 504 cm-1附近吸收峰是C—H伸缩振动和C=O伸缩振动的组合频信息区域,主要反映了咖啡碱以及单糖的光谱信息;4 630 cm-1和4 695 cm-1附近是C—H伸缩振动和C=O伸缩振动的组合频信息区域,4 525 cm-1附近是—NHx一级倍频信息区域,4 613~4 587 cm-1区域是N—H弯曲二级倍频与C=O伸缩振动的组合频信息区域,主要反映了游离氨基酸、蛋白质和咖啡碱等茶叶碱的光谱信息[25]。但是在光谱区间中,与酚羟基有关的信息较少,可能是由于黄茶在闷黄过程中茶多酚的酚羟基极易被氧化为醌类物质或形成酮类物质的原因。可见,应用Bi算法筛选出的建模光谱区间可以较为准确地反映与远安黄茶品质密切相关的内含成分,具有较好的代表性,但是还有较多的光谱区间并没有与远安黄茶品质相关的官能团信息或者含有的信息非常微弱,将会影响模型的预测效果。因此,尝试应用GA算法来精准筛选与远安黄茶品质更加密切的数据点。
3.2 GA精准提取特征光谱数据点
应用GA算法从9 003.2~7 497.9 cm-1、6 101.7~5 449.8 cm-1和4 601.3~4 246.5 cm-13个区间中精准提取了75个与远安黄茶品质密切相关的数据点(9 003.2~7 497.9 cm-1中40个,6 101.7~5 449.8 cm-1中13个,4 601.3~4 246.5 cm-1中22个),其中最能反映远安黄茶品质内含成分官能团信息的数据点为45个(按照以上顺序分为21、12、12个,所占比例分别为52.50%、92.31%、54.55%)。其中,9 003.2~7 497.9 cm-1区间提取的特征光谱数据点主要反映的是—CHx官能团的二级倍频和组合频信息,6 101.7~5 449.8 cm-1区间提取的特征光谱数据点主要反映的是—CHx官能团的一级倍频信息,4 601.3~4 246.5 cm-1区间提取的特征光谱数据点主要反映的是—C=O官能团组合频信息及—NHx官能团一级和二级倍频信息,以上这些官能团与茶叶中的单糖、咖啡碱、茶氨酸和游离蛋白质有关,这几种成分都与远安黄茶品质密切相关[26]。其余30个光谱数据点主要反映的是木质素、淀粉、纤维素等多糖的O—H伸缩和C—O伸缩的组合频信息、酰胺组合频信息以及脂肪烃类物质的C—H伸缩和C—C伸缩的组合频信息。由于远安黄茶在干燥提香时,会发生蛋白质热裂解而生成游离胺[1],而游离胺不稳定,会继续发生化学反应,生成糖胺类等。在评审远安黄茶品质时,用沸水冲泡黄茶并在浸泡过程中糖类物质以可溶解的单糖为主,但会有极少量的木质素、淀粉和纤维素等多糖物质溶解于茶汤中。上述物质虽然有助于提高茶汤的鲜味和甜味,但这些物质的含量极低,因此,它们的近红外光谱信息也就很微弱。这也是提取的75个特征光谱数据点中只有45个特征数据点可以较好地反映与黄茶品质有关的主要内含成分的官能团信息的原因。在今后研究中,进一步将茶叶中单糖、咖啡碱等理化成分与茶近红外光谱相结合,开展深层次茶品质评价研究。
本研究通过扫描获得了远安黄茶的近红外光谱,结合Bi-PLS算法和GA-PLS 算法分别筛选了建模的特征光谱区间和特征光谱数据点,实现了远安黄茶品质的快速、无损、准确预测。模型具有较高的稳健性,可以准确地预测外部未知样品的品质得分(R2=0.942,RMSEP=1.573)。但本研究在建立远安黄茶品质分数预测模型时,采用的样品均具有较好的品质,品质分数区间仅为78.40~92.05。因此,为使模型具有较佳的稳健性和较广的应用范围,除了在建模时筛选能反映样品的特征光谱信息外,还需扩大样品的品质分数区间,补充一些品质分数稍低的样品用于建立预测模型,将得到很好的实际应用效果。
