基于神经网络的相似编程题目推荐
2022-02-15王小良夏传林
王小良,郑 巍,夏传林
(南昌航空大学 软件学院,江西 南昌 330063)
0 引 言
随着计算机技术的不断发展和普及,越来越多的人倾向于通过在线平台学习[1]。在这些在线教育编程平台中,推荐相似的编程题目供给学生练习就是一个很重要的任务[2-4]。一般来说,编程题目的内容包括题目知识点、题目文本信息以及题目源代码信息,如图1所示。相似的题目是指那些题目的难度相当,知识点相似和题目内容的语义表示相似[5]。例如,图2显示了3个编程题目,其中,图2(a)和图2(b)有着相同的目的,即评估学生对数组的掌握程度。如何从题目的内容中自动理解题目的语义是一个迫切需要解决的问题。目前已经有采用了文本相似度的方法[4]。但是,一些现有的解决方案可以综合利用异构数据[6,7]来准确理解题目的语义信息;有一些根据学生的学习偏好来推荐合适的资料[8]。不同的题目有着相似的知识点,但是有着不同的目的,这类不应该归类为同一种题目,但是有可能这类会被分类同一种相似的题目。
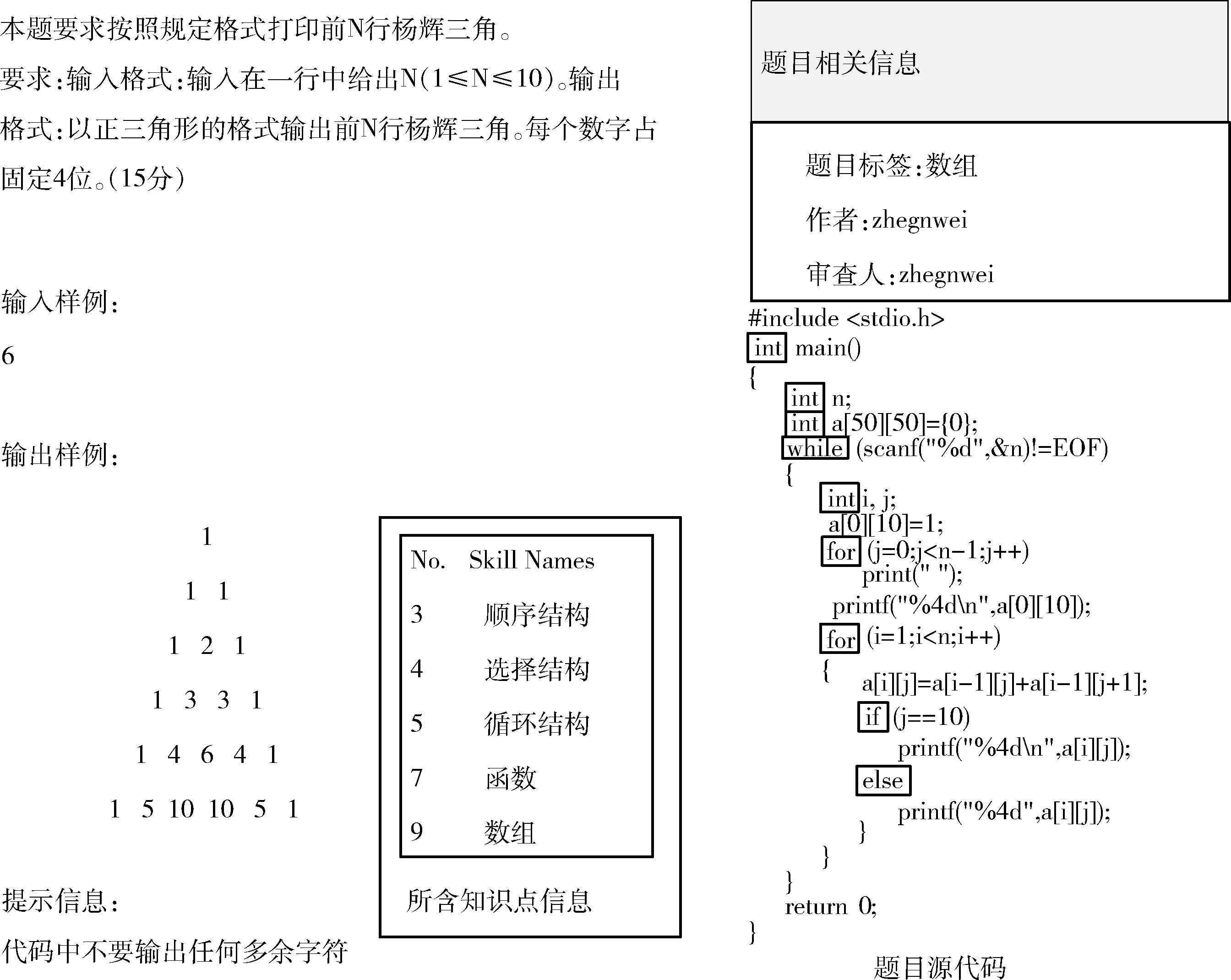
图1 编程题目包含的数据信息
总的来说,设计一个有效的推荐相似题目的解决方案仍然存在着许多挑战。首先,题目包含着多个异构数据,如何将这些异构数据表示题目的异构数据特征相关联,是一个亟待解决的问题。其次,找到一个合适的模型去准确度量题目知识点、题目代码和题目的文本信息是关键一步。最后,通过深入理解语义关系来衡量每组题目的相似部分也是很重要的。为了解决上述的挑战,在本文中,我们开发了一个基于异构数据的注意力的神经网络(HANN)框架,用于在大规模的在线编程平台中通过学习异构数据的统一语义表示来推荐相似的题目。根据在线编程平台上的真实数据显示,HANN框架推荐相似的题目的精确度较高。
1 相关工作
一般来说,相关工作可以分为以下3类,即推荐相似的题目的研究、异构数据的学习和对题目对建模的研究。
1.1 推荐相似题目的研究
在现有的文献中利用题目的概念来推荐相似的题目(RSE)。例如,向量空间模型(VSM),结合TF-IDF和余弦相似度来度量题目文本的相似度,这种方法是在线教育系统中比较常用的方法。Zheng L I等[5]开发了一种结合VSM和余弦相似函数的方法来对文本进行分类。然而,这些解决方案很少能综合利用异构的信息来精确理解和表示每个题目的语义。Pragya Dwivedi等[8]根据学生的学习偏好(学习风格、知识水平)来推荐合适的学习资料。但是,没有针对题目信息来推荐。最近,另一个方向是尝试利用学生的表现数据,通过获得题目簇来测量类似的题目。然而,学生的相似表现并不能保证题目的相似。Qi Liu等[9]通过数学题目的图像和题目概念以多模态方式寻找相似的题目。多模态学习是处理多种模态的强大方法,例如声音和视频[10]、视频和文本[11]、或图像和文本[6,7]。
1.2 异构信息网络学习
异构信息网络[12]作为新兴的方向在推荐系统中可以自然地建模复杂的对象及其丰富的关系,其中对象的类型不同,对象之间的链接表示不同的关系。最近,Shi等[13]提出了加权异构信息网络的概念,设计了一种基于元路径的协同过滤模型,灵活地集成异构信息进行个性化推荐。在Shi等[14]和Zheng等[14-16]论文中,用户和物品的相似度都是通过不同语义的元路径下的基于路径的相似度度量来评价的,并提出了基于双正则化框架的矩阵因子分解来进行评价预测[17]。
在本文框架中,最重要的步骤之一就是以循环神经网络的方式整合异构的数据材料。结合文本内容和题目源代码,构造题目的异构信息网络。通过深度学习学习题目异构数据信息,从而达到寻找相似题目的目的。
1.3 相似成对建模
对成对的相似度分析有很多研究,例如句子对、图像对、视频句子对。通常,成对建模的方法是试图学习成对中两个实例之间的关系。如Xu等[11]设计了联合视频语言嵌入模型,把学习视频“与”匹配的关系用来描述视频句子对的关系。Mueller等[18]利用LSTM架构提取语义表示,对句子进行相似关系分析。Yin等[19]在CNN中加入了注意策略,从单词、短语到句子观点捕捉句子对的相关部分。但是,这些方法并不关注具有多个异构数据的实例的成对建模。因此,应该设计新的方法来测量题目对之间的关系。
2 具体框架
在本节中,首先给出推荐相似的编程题目(RSE)任务的正式定义。然后介绍了HANN框架的技术细节。最后,指定了一个成对损失函数来训练HANN。
2.1 问题定义
相似的题目之间有着共同的目的,这也与题目的语义相关,对于任意的两个题目Ea和Eb来说,本文用S(Ea,Eb) 评价两者之间的相似性。S(Ea,Eb) 的分数越高,这就说明Ea和Eb的相似度越高。在没有损失值得情况下,推荐相似的编程题目(RSE)可以表述为
F(E,R,Θ)→Rs
(1)
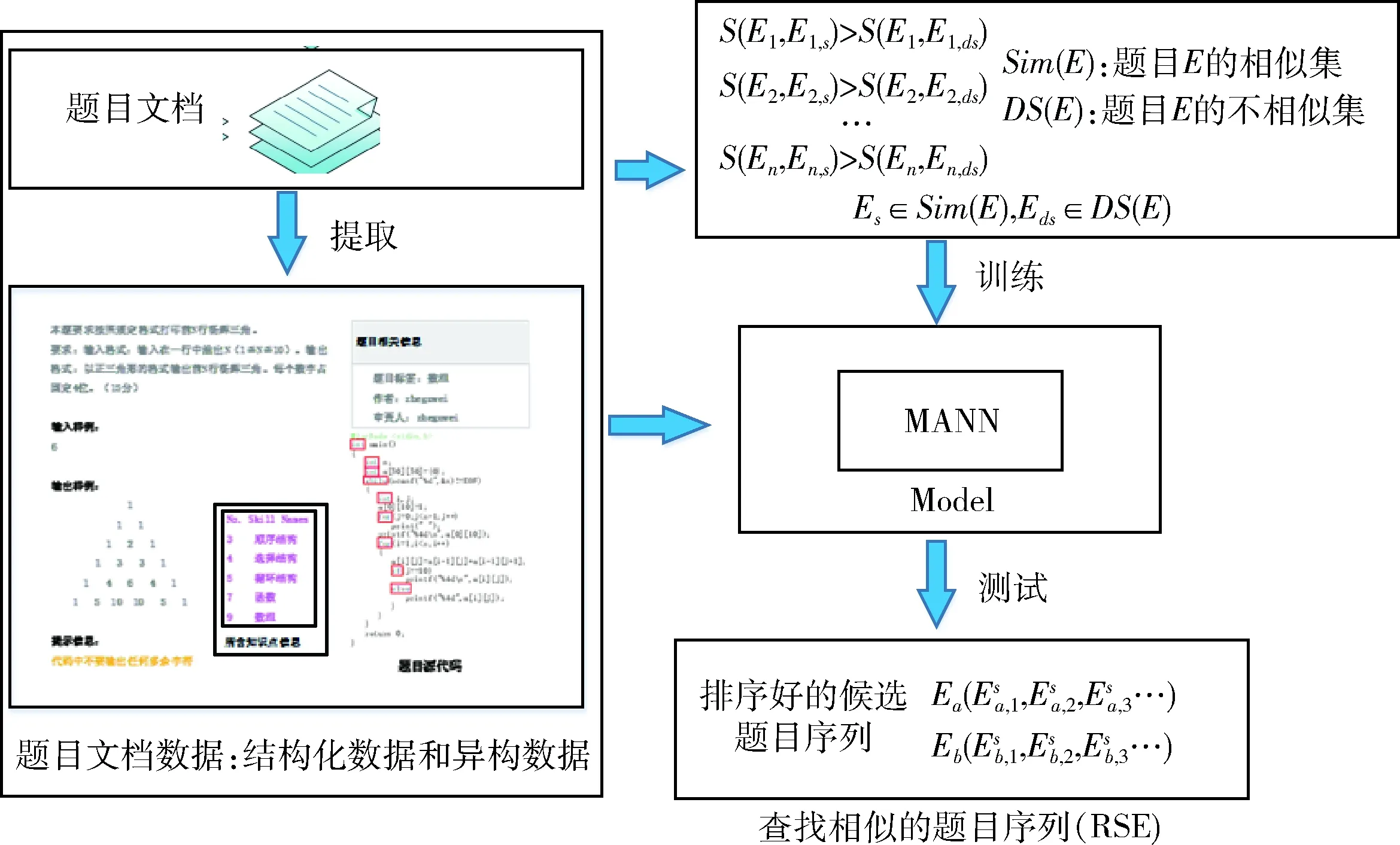
图3 具体的工作流程
2.2 异构数据的注意力神经网络(HANN)
在本节中,本节将介绍HANN框架的技术细节。如图4 所示,HANN主要包括3个部分,即,题目的异构数据表示层(HERL)、注意力层(SA)和预测得分层(SL)。具体来说,HERL利用其结构化数据和异构数据,结合长短时记忆神经网络输出每个题目的统一语义表示。注意力机制通过语义表征在两个练习之间测量相似部分。预测得分层计算题目对的相似度得分,可用于对相似的题目集进行排序,以便为所有的题目找到其相似的题目信息。

图4 HANN框架的具体流程
2.2.1 HERL层
对于HERL的输入,首先提取题目文本特征,题目知识点转化为知识点矩阵(Q矩阵),并且将题目代码进行one-hot编码,提取代码特征。然后,设计了一个基于注意力的长短时记忆网络(attention-based LSTM),通过长短时记忆神经网络整合不同的题目数据来学习每个题目的统一语义表示。具体细节如图5所示。
(1)题目输入:对于HERL框架的输入是题目E的数据,例如文本 (ET)、 题目源代码 (EC) 和题目知识点矩阵 (EQ), 将(ET) 形式化为N对词序列ET=(w1,w2,…wN) 其中wi∈d0, 由一个d0训练的词嵌入初始化的Word2vec。对于题目代码,提取代码的关键词信息,然后进行one-hot编码,题目中E的代码可以用一个矩阵表示EC=(k1,k2,…kL)∈{0,1}L×Lall, 其中ki是一个one-hot向量,其维数等于题库中所有代码中的关键词的总个数,Lall为题目E中代码关键词的个数。题目的知识点将会表示为Q矩阵信息EQ=(q1,q2,…qL)∈{0,1}M×Nall。
(2)源代码嵌入(Embedding):因为代码的关键词的one-hot表示过于稀疏而无法训练,因此,本文利用一种嵌入(Embedding)操作将代码的关键词的信息的初始化向量转化为具有密集值的低维向量。形式上,对于代码的关键词ki, 转化为向量ui
ui=kiWu
(2)
其中,Wu∈Lall×d2是嵌入层的参数,ui∈d2为嵌入层的输出参数。从而,源代码关键词EC被转化为一个矩阵u=(u1,u2,…uL)∈L×d2
(3)基于注意力的LSTM在得到知识点和代码的特征表示后,通过整合输入题目E的所有的异构数据,即,文本表征、Q矩阵和代码表征。在每个题目中,文本的不同部分与不同的源代码和知识点相关联。因此,本文设计了基于注意力的LSTM结构,以神经网络的方式学习每个题目的表示,其中本文使用两种注意力策略,一种是文本-源代码(TCA)和文本-知识点(TQA),分别捕获文本-源代码(TCA)和文本-知识点(TQA)关联。细节如图6所示。
在方法上,基于注意力的LSTM是传统LSTM架构的一个变体[20]。因为LSTM可以处理任何长序列,并学习跨输入序列的长范围依赖关系,本文使用基于LSTM的体系结构来学习任何长度的单词序列题目的表示。具体而言,本文LSTM网络的输入为序列x=(x1,x2,…xN) 每个题目的所有数据,将第t步输入步骤的隐藏状态ht更新为如下
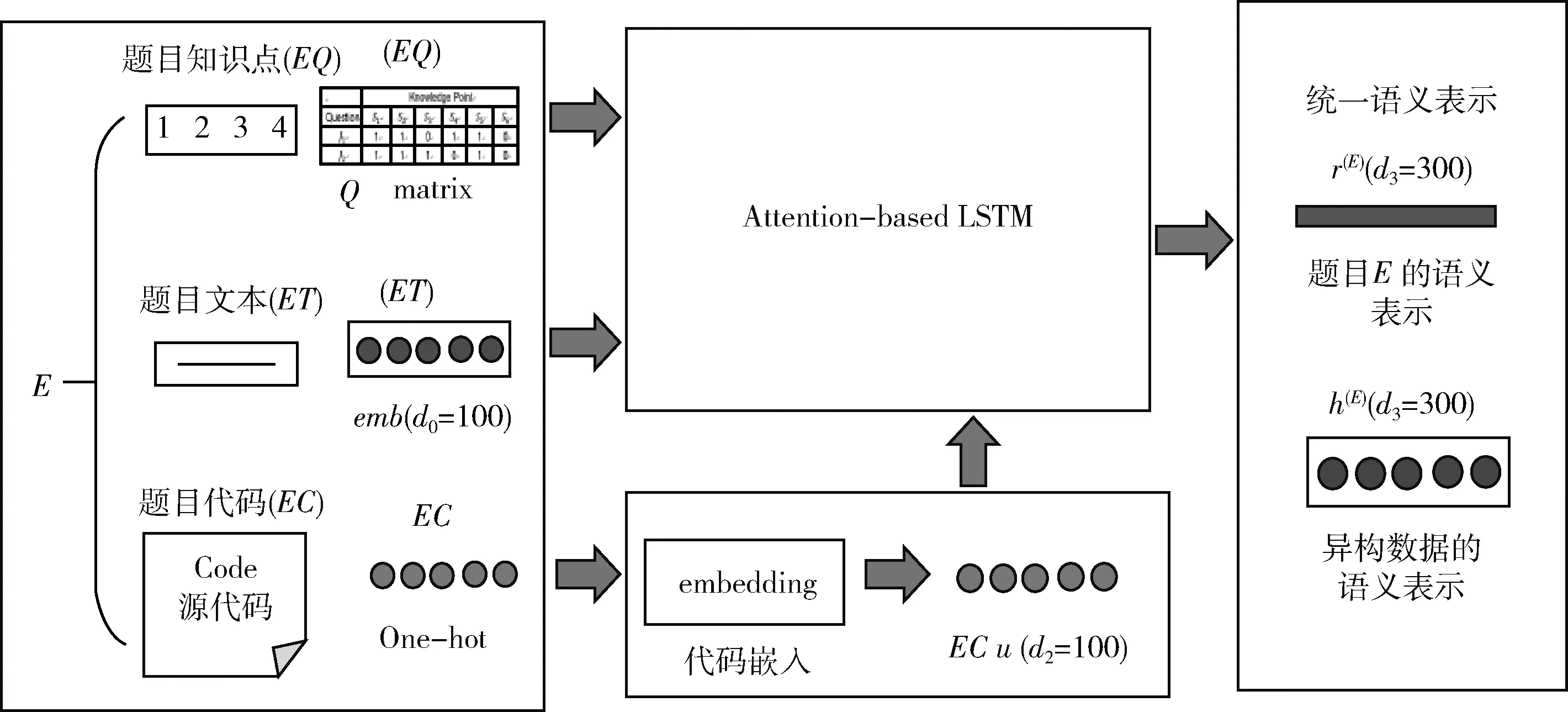
图5 题目的异构表示层(HERL)

图6 异构数据的语义表示
it=σ(WXixt+Whiht-1+bi),ft=σ(WXfxt+Whfht-1+bf),ot=σ(WXoxt+Whoht-1+bo),ct=ftct-1tanh(WXcxt+Whcht-1+bc),ht=ottanh(ct)
(3)
其中,i·、f·、c·、o·分别为LSTM的输入门、遗忘门、存储单元、输出门。W·和b·是学习过的权值矩阵和偏值。
显然,在每一个输入步骤中,xt是一个集文本、知识点和源代码于一起的多模态向量,即
(4)
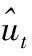

(5)
其中,Vac和Wac是TCA的学习参数,而在题目E中, (uj,wt,ht-1) 衡量的是第j步源代码关键词uj和wt之间的联系,αj表示的是经归一化后的φ(uj,wt,ht-1) 的注意力参数。
TQA的目标是捕捉文本-知识点的关联。与TCA类似,在TQA中,小波变换相关的知识点表示qt可以建模为式(5)的形式,其中可以简单地使用qj和学习过的TQA参数Vaq和Waq来代替uj、Vac和Wac。
通过基于注意力的LSTM,可以得到隐藏状态序列h=(h1,h2,…hN) 结合输入序列x。 此外,这个方法来自于LSTM应用于自然语言处理中[18],最后隐藏状态hN拥有题目E整体的语义信息的输入序列x, 所以采用hN的语义表示r(E), 即r(E)=hN。 另外第t步隐藏状态ht只保存序列的信息 (x1,x2,…xt)。 因此,进一步将h(E)=h表示为题目E异构数据的表示,从而得到E的统一语义表示 (r(E),h(E))。
2.2.2 注意力机制(SA)
如图4所示,对于每个编程题目对 (Ea,Eb) 统一的表示形式,即 (r(Ea),h(Ea)) 和 (r(Eb),h(Eb)), 通过HERL获得,注意力机制的目标是通过Ea和Eb的统一语义特征表示。如图2所示,虽然E1和E2是类似的题目,但是它们有不同的文本、源代码和知识点,这一证据表明,类似的题目可能由不同的数据材料组成。因此,在寻找相似的练习时,有必要捕捉两个练习中语义相似的部分。因此,本文设计了相似注意力机制来测量两个练习的相似部分,并学习它们的注意力表征。
在注意力机制方面,使用注意力矩阵A来度量输入题目对 (Ea,Eb) 的相似部分,方法是计算Ea和Eb各部分与h(Ea)和h(Eb)之间的余弦相似度。A∈NEa×NEb可以表示为
(6)

当我们悉心倾听一个人的幽幽诉说,当我们沉醉于慷慨激昂的演讲,当我们倾诉自己真实的心灵,当我们复述一个幽默的故事,当我们聚在一起夸夸其谈一个观点,当我们描述一个人的形象,当我们索要今天的晚报,当我们随意看到一个新颖的广告或标语,当我们醉心于时尚杂志的动听词汇,这些都离不开语文。
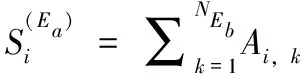
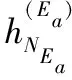
(7)
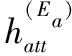
2.2.3 预测得分(SL)

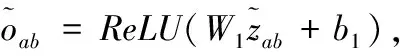
(8)
其中,W1、b1、W2、b2为网络参数。因此,该方法通过平衡异构信息,精确地测量了题目对的相似度得分。那些具有最大相似度得分的候选人将作为给定练习的相似练习返回。
2.3 HANN学习
在本节中,为了训练HANN指定了一个成对损失函数。在训练阶段,假设有一个子集的题目已经标记了几个相似的题目。对于题目E, 使用Sim(E) 来表示标记过的相似题目,并将未标记的题目视为不是相似的题目DS(E), 考虑到相似对 (E,Es) 的相似度得分要高于不相似对 (E,Eds), 其中Es∈Sim(E),Eds∈DS(E), 如图3所示,进一步构建成对损失函数为
L(Θ)=∑E,Es,Edsmax(0,μ-(S(E,Es)-S(E,Eds)))+λΘ||Θ||2
(9)
在上式中,S(..,..) 由式(8)计算;Θ为HANN的所有参数,λΘ为正则化的超参数;μ是一个边缘参数,迫使S(E,Es) 大于S(E,Eds)。 这样,可以通过使用Adam[22]直接最小化损失函数L(Θ) 来学习HANN。
由于每个标上标签的题目E的不同题目数量巨大,如果在训练过程的每次迭代中都使用它们,将花费大量的时间来训练HANN。因此,受工作[23,24]的启发,在每次迭代中只选取不同练习的一个数字(例如50)作为E的DS(E)。 具体来说,在本文的工作中,本文有两种抽样方法。
按照知识点随机抽样(Q-Random):在每次迭代中,对于每个给定的题目E, 从那些与E至少有一个共同知识点的题目中随机选择一些不同的题目。
3 实 验
在本节中,首先评估HANN在RSE任务上的表现与其它几个方法进行比较。然后,通过个案研究来形象化HANN的解释能力。
3.1 数据描述
本文的实验数据是从我们大学在线实验编程平台提供,专为本校大学生提供编程的平台。其中,我们的实验平台包含4354道真实的编程题目。我们的编程题目被分类成10个知识点信息。
3.2 实验参数配置
为了验证HANN算法的有效性,本文对数据集中标记的练习采用了5组交叉验证,其中5组中的1组用于构建测试集,其余的用于构建训练集。实验参数根据基于直观或经验达到最优解。
Word Embedding 预训练:使用维数d0=100的Word2vec工具[25],在数据集中对HERL的题目输入中使用的嵌入词进行训练。
HANN参数设置:本文将源代码关键词的嵌入表示的大小(d2)设为100,基于注意力的LSTM中隐藏状态的维数(d3)设为300,第一个全连接网络的输出大小设为200。
训练的详细细节。本文在HANN中使用标准偏差为0.1的截断正态分布初始化参数。在式(9)中将mini-batches 设置为64,μ=0.5和λΘ=0.00004。 式(9)用于训练HANN,除训练过的Word2vec中的参数外,可以在训练过程中调整HANN的参数。本文还使用概率为0.2的dropout来防止过度拟合,而使用梯度裁剪来避免梯度爆炸问题。
测试的详细细节。由于类似的练习通常有共同的知识点,因此对于给定的题目,必须选择至少有一个共同知识点的题目作为候选,以查找其相似的知识点。然而,这些题目的数量仍然非常大,并且将所有的题目都作为候选题目是不切实际的,因此,与训练过程类似,对于测试集中的每个给定练习,随机抽取至少有一个公共知识点的未标记题目,并将它们与标记的相似题目混合作为候选题目。当测量模型的性能时,多次重复这个过程并报告平均结果。
3.3 比较方法
为了验证HANN算法的有效性,本文将与几种方法进行了比较,包括HANN的一些变体、RSE任务的传统方法以及用于配对建模和异构数据学习的模型。
VSM:基于题目文本的TF-IDF和余弦相似度相结合的向量空间模型(VSM),是一种简单、有效、无监督的方法。它在许多教育系统中被广泛应用于RSE任务。
LSTM:LSTM用于学习基于文本的句子之间的语义相似度。
HANN-T:HANN-T是HANN的一种变体,仅使用题目的文本。
HANN-TCA:HANN-TCA是HANN的一种变体,仅使用编程的文本和源代码答案,并考虑文本-源代码与TCA的关联。
HANN-TQA:HANN-TQA是HANN的一种变体,仅使用题目文本和题目的知识点,并考虑文本-知识点与TQA的关联。
3.4 评价标准
要为给定的题目推荐相似的题目,将返回该题目中相似度得分最大的候选者。因此,本文采用3个广泛使用的top-n排序指标:精确度(Precision)、回收率(Recall)和F1测量标准,其中n表示从相似题目集中选择的题目的多少。所以本文在实验中设n=1、2、3、4、5。就这3个指标而言,规模越大越好。
3.5 实验结果
3.5.1 性能比较
为了调查HANN和其它方法在RSE任务上的表现,本文以知识点抽样的方式训练模型。正如在测试细节中所讨论的,本文设置m=50。构建测试集来计算3个度量的过程重复了20次,然后本文报告平均结果。
图7~图9显示了所有模型的性能结果。可以发现,本文提出的HANN是最好的结果。与SVM和LSTM相比,HANN的精确度、回收率和F1值明显有一个较大的提升。具体来说,首先,VSM表现不如其它的模型,因为VSM只关注题目的文本中常见的词语,而不能从语义上理解题目。其次,本文发现HANN-T,只基于文本语义的要低于HANN-TQA和HANN-TCA,这说明,影响题目相似度的重要特征有题目的源代码和题目的知识点信息。最后,HANN的表现最好,说明它结合文本、知识点和源代码这些异构数据处理的很好,这也说明TCA和TQA的有效性。
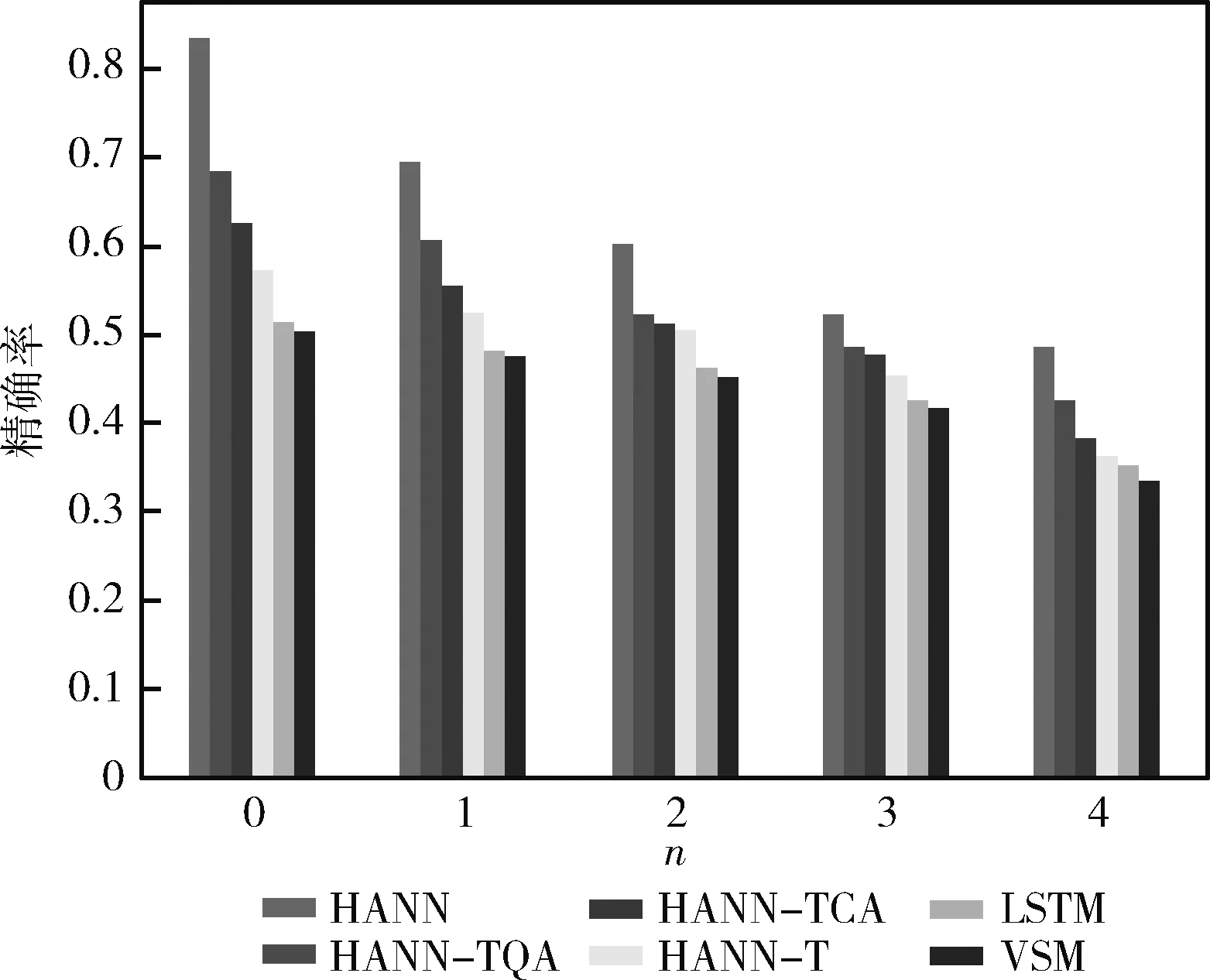
图7 RSE任务的精度比较
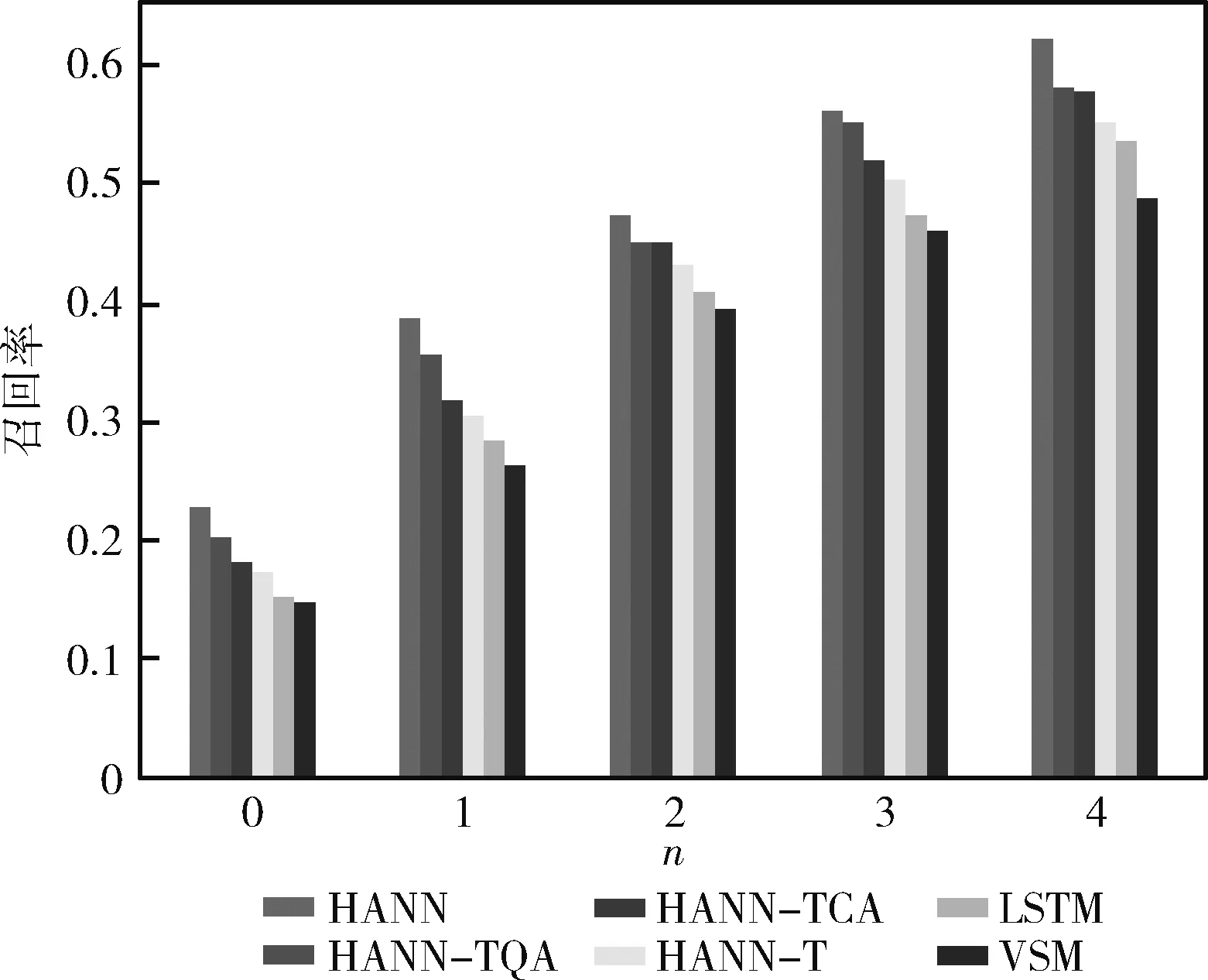
图8 RSE任务的回收率比较

图9 RSE任务的F1值比较
综上所述,这些证据表明题目知识点与题目源代码在题目中是重要的特征,对RSE任务是有用的。同时,这也意味着HANN可以通过将文本、知识点与题目源代码的关键词进行多模态整合,更有效地找到相似的题目,同时捕捉文本-知识点和文本-源代码的关系,并通过语义表征来测量两个题目之间的相似部分。
3.5.2 取样方式对训练的影响
如上文所述,本文有两种训练HANN的抽样方法,即随机采样(Random)和根据知识点随机采样(Q-Random)。接下来,使用相同的测试集来研究不同的采样方式对HANN有效性的影响。实验过程重复了20次,并给出了平均结果。
平均结果如图10~图12所示。从图中可以看出,接受知识点采样训练的题目比接受随机采样训练的题目表现更好。本文猜测可能的原因是,在训练HANN时,对于每一个给定的题目,其类似的题目非常不同于大多数样本不同的随机(随机抽样),而其类似的题目接近不同的知识点采样,所以HANN可以关注其类似题目对之间的细微差别和不同的知识点。因此,对于RSE任务,以知识点采样的方式训练的模型可以更加强大。
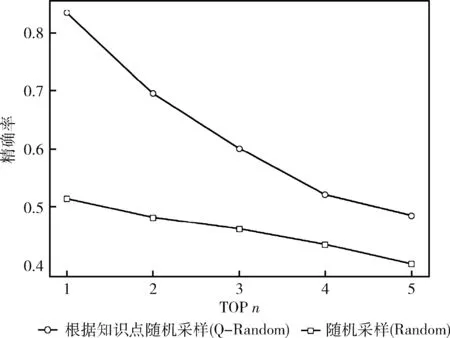
图10 不同采样方式对HANN的精确度的影响
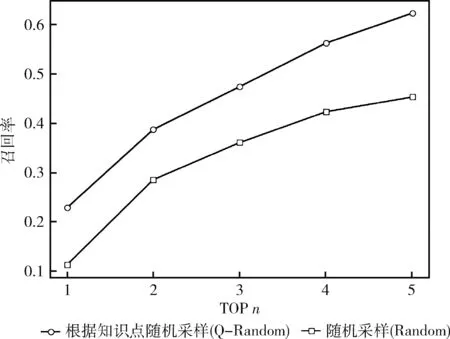
图11 不同采样方式对HANN的召回率的影响
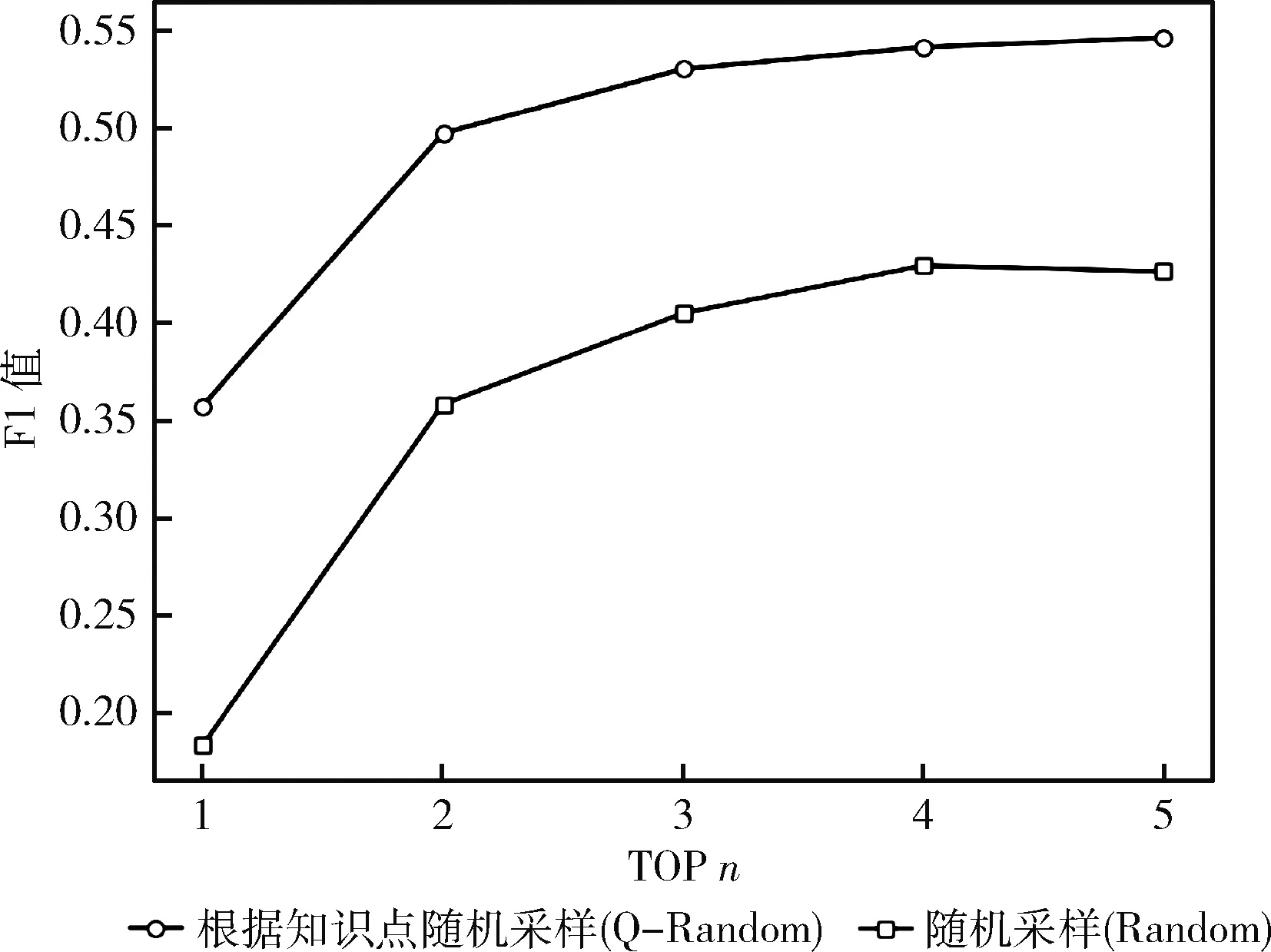
图12 不同采样方式对HANN的F1值的影响
综上所述,这些证据表明采用随机采用的方法没有根据知识点采用的效果好。因为根据知识点采样,对于输入的数据来说,就已经根据知识点分类好,根据学生对知识点的掌握情况,推荐更合适的相似题目也就更快。所以说接受知识点采样数据更好,更符合相似题目的查找。
4 结束语
在本文中,着重研究在线教育编程系统中推荐相似的题目(RSE)。为了对非均匀题目材料进行语义建模,提出了利用题目的文本、知识点和源代码作为题目的输入,然后利用基于异构数据的注意力神经网络框架进行建模。具体来说,首先生成题目知识点矩阵(Q矩阵),然后使用文本表征表示题目源代码信息。最后设计了一个基于注意的LSTM网络,结合异构数据信息学习每个题目的统一语义表示,其中提出了两种注意策略分别评估文本-知识点和文本-源代码关联。接下来,设计了相似注意来测量练习中相似的部分。最后,提出了一种成对训练策略来返回相似的训练。在大规模真实数据集上的实验结果清楚地验证了HANN的有效性和解释力。本研究结果表明了对于编程题目相似性的自动分类,题目的文本内容、题目相关知识点和题目的源代码信息对于判断题目对之间的相似性有着重要的因素。而本研究的不足点就是没有将题目对之间的难度信息作为判断题目对之间的相似性重要因素。我们下一步工作就是将题目难度信息代入HANN框架中。
