基于上下文学习的轻量级自动抠图算法
2022-02-15王文韵黄根春王先培
王文韵,黄根春,田 猛,王先培
(武汉大学 电子信息学院,湖北 武汉 430072)
0 引 言
自然图像抠图是指精确估计前景对象不透明度,并将前景对象和背景对象分离的问题,其有广泛的应用[1]。传统的抠图算法主要通过传播、采样或两者的结合来实现。该类方法很大程度将颜色作为区别特征,导致对于前景和背景颜色分布重叠的情况分割性能较差。近年来,基于深度学习的自然图像抠图算法逐渐取得了主导地位。Cho等[2]将两种传统抠图方法(Closed-form算法及KNN算法)的结果和归一化RGB图像作为输入,通过端到端神经网络的学习来预测一个新的Alpha图。这种方法虽然利用了深度学习,但输入部分依赖于传统方法的结果,因此很容易遇到与以往抠图方法相同的问题。为了避免受到以往方法的影响,Xu等[3]提出了一种两阶段的网络,包括编解码阶段和细化阶段。该方法无需依赖于其它方法的结果,仅以原始图像和相应的三分图作为输入便可预测Alpha图。同时Xu等还提出了抠图领域第一个大规模的数据集。由于该数据集的可用性,基于深度学习的抠图方法得到了广泛的探索。Lutz等[4]进一步改进了文献[3]中的解码器结构,提出了一种生成对抗网络。Yu等[5]针对高分辨率图像进行了基于深度学习的自动抠图的研究。上述方法虽已取得较好的分割结果,但仍然存在一些不足。一是深层网络易丢失部分低级语义信息,而低级特征对于保留Alpha图的详细纹理信息至关重要[6]。二是深层网络普遍模型参量庞大,无法很好平衡精度和运行时间,而目前大部分嵌入式设备的算力很难支撑深度卷积神经网络模型的实时运行[7]。
针对上述问题,本文提出一种轻量级的自然图像抠图算法。该算法以U-Net框架为基线结构,改进的MobileNetV2为编码器,结合上下文特征聚合模块捕获多尺度的上下文信息,有效保证模型的输出精度。同时将深度可分离卷积应用到上下文特征聚合模块和解码器模块,大幅降低了模型参量。
1 网络结构与原理
本文提出的模型使用定制的U-Net架构来实现自然图像抠图,系统框架如图1所示。本文采用RGB图像和相应的三分图作为网络输入,其沿通道维度连接,形成一个4通道输入。网络首先通过编码器部分将输入图像编码为特征映射,然后使用上下文特征聚合模块融合多尺度的上下文信息,最后将增强后的特征映射解码恢复对象边界信息,得到预测的Alpha图。

图1 网络模型
1.1 基线结构
本文采用U-Net网络作为基本结构框架,该网络由Ronneberger等提出。U-Net网络近年来在语义分割领域取得了广泛的成功,如Shelhamer等[8]进行全卷积网络的语义分割,Liu等[9]用于图像修复以及Fan等[10]基于改进的U型网络进行高分辨率遥感图像分割。U-Net网络主要有两个显著特点。一是U型对称结构,左侧为编码器,右侧为解码器。编码器通过连续的卷积层和最大池化层对输入数据进行降维和特征提取,解码器则通过上采样层对提取的特征层进行升维和特征放大。二是跳跃连接结构,U-Net网络的每个卷积层得到的特征图都会连接到对应的上采样层,从而在后续的解码过程中可以有效利用每层特征信息。对于抠图问题,低层特征信息的保留对于恢复Alpha图中详细的纹理信息有着至关重要的作用。因此,本文设计解码器在上采样块之前组合编码器功能,避免在编码器特征上发生更多的卷积,而该卷积应该提供较低级别的特征。
1.2 轻量级编码器-解码器网络
本文将以U-Net框架为基础,保留其U型对称结构和跳跃连接结构,改进编码器-解码器结构,搭建一个适用于自然图像抠图的轻量级神经网络。
为了更好平衡精度和模型参量,本文选取MobilbeNetV2的主干网络作为编码器结构。MobileNetV2[11]网络是由google团队2018年提出的轻量级神经网络模型,该模型在大幅减少模型参数和运算量的同时保持了较高的准确率。MobileNetV2在保留了MobileNetV1[12]中的深度可分离卷积的基础上,提出了线性瓶颈的倒残差结构,进一步提高网络的表征能力。倒残差结构巧妙的反向利用了Resnet网络[13]提出的残差结构,如图2所示。通过倒残差结构,模型可以在高维度进行特征提取和低维度减少计算量上得到一个良好的平衡。值得注意的是,针对倒残差结构中最后的1×1卷积层,MobileNetV2采用线性激活函数替代ReLU激活函数。由于倒残差结构输出的是低维特征,线性激活函数较ReLU激活函数能够更好保留低维特征信息。因此,使用MobileNetV2网络既能够有效保留低级语义信息进而保证分割精度,又能降低模型的参数量。
具体地,本文采用的编码结构主要包含7个线性瓶颈的倒残差结构层和5个最大池化层。同时在最后一个倒残差结构层后添加了上下文特征聚合模块,以在多个尺度上对特征进行重新采样,从而准确高效预测任意尺度的区域。该模块将在后续的章节中详细阐述。
本文使用更简单的结构进行解码操作,同时将深度可分离卷积添加到解码模块中进一步减低模型参量。解码器部分由连续的最大值去池化层、卷积层以及和编码器的跳跃连接组成,进行上采样特征映射输出预测的Alpha图。其中跳跃结构能够通过融合低层特征信息捕获图像中的精细结构,进而提高输出精度。具体而言,解码器包含7个解码模块(如图3所示)和一个输出预测层。每个解码模块的卷积层后使用批处理标准化层(batch normalization,BN)和ReLU6激活函数,缓解训练过程中梯度消失的问题。

图3 解码模块
1.3 上下文特征聚合模块
本文提出了一种基于改进的空洞空间金字塔池化(astrous spatial pyramid pooling,ASPP)的上下文特征聚合模块,用于捕获多尺度的上下文信息。该模块能够与编解码网络结合,丰富网络中的编解码模块。
空洞卷积是空洞空间金字塔池化(ASPP)中的重要组成部分,其通过在权重之间插入零来对卷积滤波器进行上采样,如图4所示。相比普通的卷积,空洞卷积引入了一个称为扩张率(dilated rate)的超参数,该参数定义了卷积核处理数据时各值的间距。ASPP实质上是几个以不同的扩张率并行的空洞卷积。DeepLabV3[14]首次应用了ASPP捕获多个尺度上的上下文信息,经实验证实,该模型在分割基准上确实取得了一定的提升。
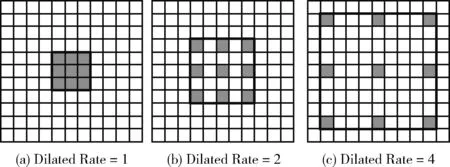
图4 空洞卷积
为了缓解网络主干的池化或跨步卷积操作造成对象边界详细信息丢失的问题,同时避免增加过多的模型参量,本文将深度可分离卷积添加至空洞空间金字塔池化结构并与编解码网络结合,具体的模块结构如图5所示。该模块能够明确地控制由深度卷积神经网络计算的特征分辨率,并通过调整扩张率以自适应修改滤波器的视场获取多尺度的信息。同时使用深度可分离卷积替代普通卷积可以在很大程度上控制模型参量的增加。
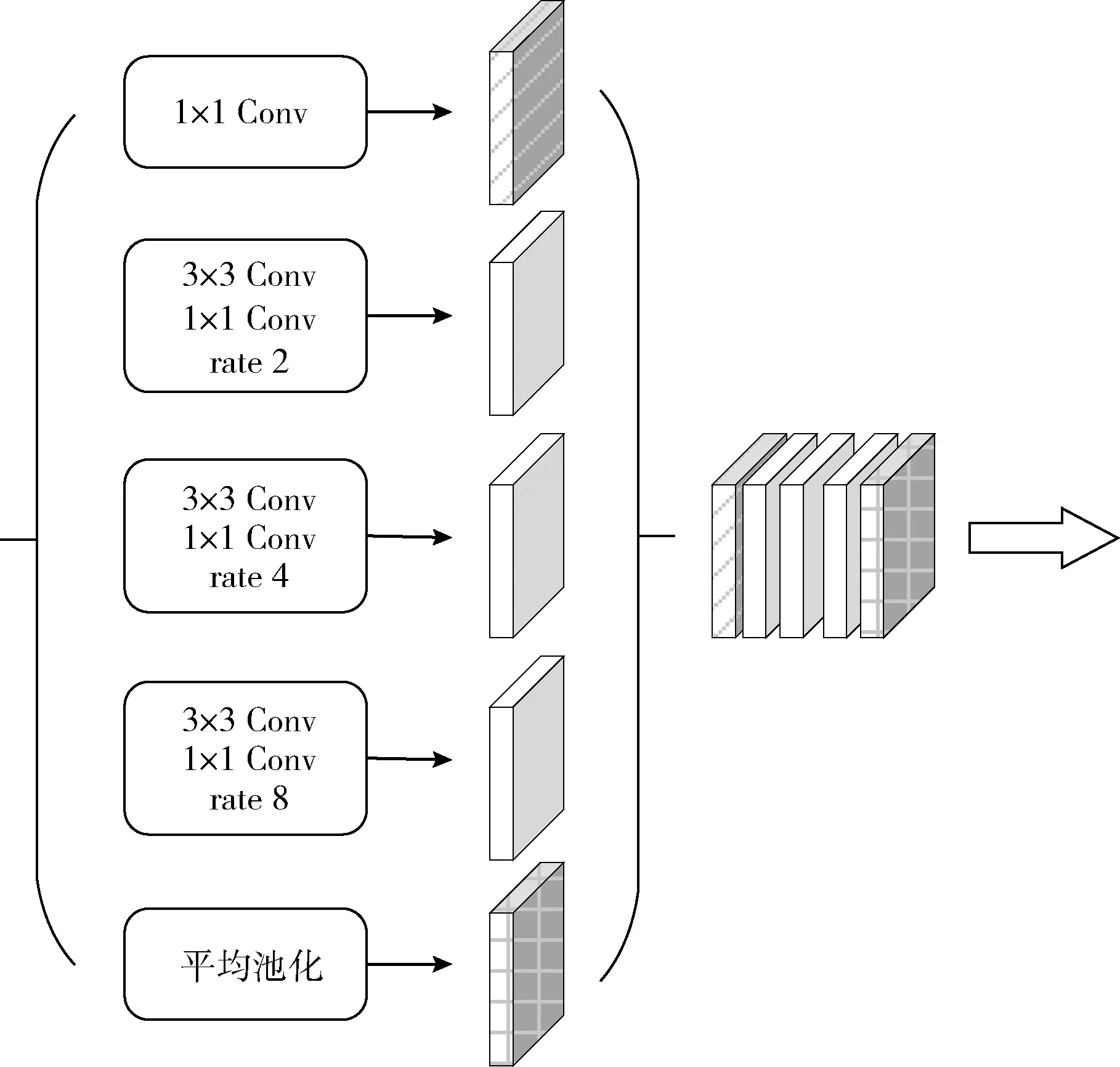
图5 上下文特征聚合模块
1.4 损失函数
本文提出的网络使用两个损失函数,分别为Alpha预测损失和合成损失。Alpha预测损失表示每个像素点处的真实Alpha值和预测Alpha值之间的绝对值差。合成损失则表示真实RGB颜色与预测RGB颜色之间的绝对差异,具体的计算公式如下[3]
(1)
(2)
式(1)中,αp表示阈值为0至1的预测层的输出;αg表示真实值;ε取10-6。式(2)中,c为RGB通道,cp为预测的Alpha合成的图像,cg为真实的Alpha合成的图像。总损失为上述两个损失的加权和,即Lo=ωlLα+(1-ωl)Lc。 在本文的实验中,ωl设置为0.5。
2 实验与分析
2.1 实验环境
本文在基于Pytorch的深度学习框架下进行训练和测试,接口语言为Python,操作系统为Ubuntu18.04,CPU为Intel i9-9900K,内存为32 GB,显卡配置为Quadro RTX 6000。
2.2 训练数据集
深度学习方法需要大量的数据才能很好地泛化。Alphamatting.com数据集(由Rhemann等提出)已经在加速抠图研究的发展方面取得了巨大的成功。然而,该数据集只有27张训练图像和8张测试图像,这远不足以训练神经网络。直到Xu等[3]发布了由431个独特的前景对象和对应的Alpha组成的新的抠图数据集。该数据集使训练深层抠图神经网络成为可能。然而,431张图片仍不足以很好训练深层网络,因此本文采用和Xu等相同的方法对数据集进行增强。对于每一张前景图像,随机从MS COCO数据集(由Lin等提出)中选取100张图像作为背景图像与前景图像进行合成,于是可得到包含43 100张图像的训练数据集。为进一步增强数据,本文采取随机旋转、剪裁等处理方法,使得网络具有更好的鲁棒性。
2.3 训练细节
网络编码器部分用MobileNetV2在Imagenet数据集(由Russakovsky等提出)上的预训练模型进行初始化,这种迁移学习的方式可以大大缩短训练的时间,同时提升模型的精度。由于本文修改了网络的第一层以适应4通道的输入,因此采用零初始化卷积层中的额外通道。所有解码器参数都用Xavier随机变量初始化。
在训练过程中,使用Adam来更新整个编码器-解码器网络,学习速率(Learning rate)设置为10-2,训练的批大小(batch size)设置为16,训练周期(epoch)为30。同时为了降低合成图像对预测结果造成的影响,训练中使用了Alpha预测损失和合成损失两种损失函数。
2.4 评价指标
为了定量地评估抠图算法的性能,预测输出值需通过误差度量与真实值进行比较。本文实验评价指标使用抠图领域的4种通用衡量指标,分别是绝对误差和(sum of absolute differences, SAD)、均分误差(mean square error, MSE)、梯度误差(Gradient)和连通性误差(Connectivity)(2009年由Rhemann等提出)。绝对误差和(SAD)和均分误差(MSE)作为简单的评价指标能够为图像误差度量提供良好的基础,梯度误差(Gradient)和连通性误差(Connectivity)作为高级的视觉质量评价指标能够为抠图算法提供与人类视觉感知相近的比较结果,具体的计算公式如下
(3)
(4)
(5)
(6)
2.5 实验结果与分析
本文在两个数据集上评估了提出的算法。首先在Alphamatting.com数据集上进行了定性的评估,该数据集是现有的图像抠图的基准。其提供了8张测试图像,每张图像对应3种尺寸的三分图,分别为“用户”,“大”和“小”。由于Alphamatting.com数据集的规模较小,包含对象的大小和范围有限,本文进一步在Composition-1k测试数据集进行了定性和定量的评估。该数据集是抠图领域的第一个大规模测试数据集,包含1000张测试图像和50张独特的前景,具有更广泛的对象类型和背景场景。
2.5.1 Alphamatting.com数据集
Alphamatting.com测试数据集中包括具有不同透明度的各种对象:高透明度(网、塑料袋)、较高透明度(娃娃、巨魔)、中透明度(驴、大象)和低透明度(菠萝、植物),本文定性地将实验结果与其它6种最先进的抠图算法的实验结果进行了比较,如图6所示。对比算法分别为Closed-form算法(由Levin等提出)、Weighted color算法(由Shahrian等提出)、KNN算法(由Chen等提出)、Comprehensive Sampling算法(由Shahrian等提出)、Three-layer 算法[15](由Chao等提出)和DCNN算法[2](由Cho等提出),实验结果选取的三分图均为“大”尺寸。当前景与背景颜色相近时,传统算法通常性能较差,无法正确的将前景对象分割出来。如图6中第一个示例所示,传统算法无法精准分割娃娃头发与背景颜色相近部分,边界区域明显出现伪影。而本文提出的基于深度学习的方法明显表现更好,对于非常精细的结构(如头发),基于深度学习的方法也能较好完成分割工作。一个关键的原因是传统算法缺乏学习高级上下文信息并依赖于颜色相关的传播方法。其中,DCNN算法[2]虽然是基于深度学习的方法,但是由于其模型是在小的局部补丁上进行训练的,因此很难真正理解语义信息。此外由于本文提出的算法引用了更多的全局信息,因此当面对较大的未知区域时,该算法具有更好的鲁棒性。
2.5.2 Composition-1k测试数据集
Composition-1k测试数据集是由Xu等[3]提供,广泛用于抠图领域的评估数据集。为了进一步验证模型的有效性,本文分别定量定性的在该数据集上评估了提出的方法。与文献[3]中处理数据的方法相同,将作者提供的50个唯一的前景对象与Pascal VOC数据集(由Everingham等提出)中的1000个不同背景图像进行组合,生成了1000个不同的测试图像。
本文将提出的方法与其它8种主流的抠图算法进行了定量比较,分别是:Closed-form算法、KNN算法、Comprehensive Sampling算法、Three-layer算法[15]、DCNN算法[2]、Information-flow算法[16](由Aksoy等提出)、DIM算法[3](由Xu等提出)、AlphaGAN算法[4](由Lutz等提出)。对于所有对比算法,使用作者提供的源代码。本文方法的不同变体包括:a.编解码网络(基线结构)b.编解码网络(添加上下文特征聚合模块)。定量比较的结果见表1,评估指标使用上述介绍的4种通用衡量指标。由表1可见,本文提出的算法在4项评价指标的综合性能上优于以往的主流算法,梯度误差指标较DIM(deep image matting)算法提高了7.63%。对比基线网络结构,变体b在4项评价指标上均取得了一定的提升,SAD提高了3.24%,梯度误差提高了7.38%,充分了验证了本文提出的上下文特征聚合模块的有效性。本文列出的DIM算法的实验结果不包含后续优化模块,仅对比编码器-解码器主干网络的性能。
本文提出的网络使用MobileNetV2作为编码器结构,同时将深度可分离卷积应用至主干模块,大幅减少模型参量,具体模型参量见表2。由表2可知,本文算法模型参数量和浮点计算量均远小于对比算法,模型大小仅为2.50 M,较DIM算法降低了98.1%,浮点计算量较DIM算法降低了94.0%。

表1 Composition-1k测试数据集上的定量结果

表2 模型参数量对照
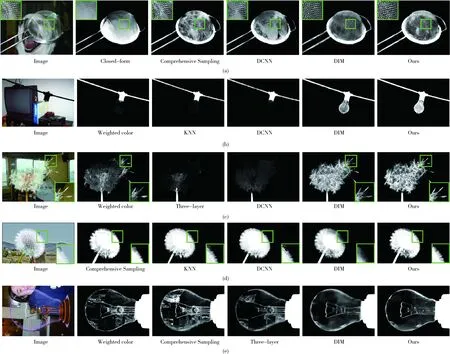
图7 Composition-1k测试数据集的实验结果
Composition-1k测试数据集上定性比较的实验结果如图7所示。由图中第二个示例可知,对于一些未知区域较大的图像,传统方法根本无法完成分割任务,而本文提出的方法能够利用U-Net网络的跳跃连接结构及上下文特征聚合模块捕获更多的全局信息从而较好完成前景对象的精确分割任务。本文算法在透明度较高(如网筛、灯泡及蒲公英等)的抠图任务中均取得了良好的视觉效果。这得益于该算法更多考虑了低级特征,这些特征有效保留了Alpha图的细节纹理特征。
3 结束语
针对目前嵌入式设备难以运行基于深度学习的自动抠图模型的问题,提出了一种基于编解码网络和上下文信息聚合模块的轻量级自然图像抠图模型,该模型的参数量较对比算法降低了98.1%。基于MobileNetV2的编码器能够对丰富的上下文信息进行编码,简单而有效的解码模块有效恢复对象边界信息,同时上下文特征聚合模块能够以任意分辨率提取编码器特征。在Alphamatting.com数据集和Composition-1k数据集上进行测试,实验结果表明本文提出的模型具有较为理想的抠图精度,验证了本文方法的有效性。
