面向数据可靠传输的高译码率带反馈的LT码
2022-02-15刘潇潇郭馨泽田家政
刘潇潇,郭馨泽,田家政,谢 鲲+
(1.湖南大学 信息科学与工程学院,湖南 长沙 410082;2.国网湖南综合能源服务有限公司 大数据中心,湖南 长沙 410000;3.长沙电力职业技术学院 经济管理系,湖南 长沙 410000)
0 引 言
近年来,由于网络、移动通信等技术的飞速发展,网络数据呈现出井喷式的增长,这无疑对网络的服务能力和服务质量造成了极大挑战[1,2]。数据包在不稳定网络传输时,一些数据包可能出现丢失。提高传输的可靠性成为无线传输的研究热点。与直接传输原始数据不同,利用纠删码的传输机制能够提高传输可靠性[3]。
在纠删编码中编码率定义为R=k/n,其中k为源码个数,n为编码个数。现有的纠删码按照是否需要预先估计编码率,可以分为有码率和无码率两类。在传统的有码率编码方案中[4],需要通过信道信息确定编码率。而在动态变化的无线传输信道下,信道传输特征容易发生突变,这就迫使发送者考虑最坏情况,大大降低了网络的传输效率。
与传统有码率编码方案不同,喷泉码最大的特点就是码率无关性。喷泉码主要可分为两类:LT码和Raptor码。与Raptor相比,LT码编译码复杂度低,且实现起来更加简单。然而,传统的LT码的译码方案[5],需要通过迭代查找度为1的编码来实现译码。当找不到度为1的编码时,译码停止,剩下的编码无法译码。
为了提高LT码的译码率,本文提出一种LT码译码方案,该方案通过迭代选取多个编码来产生度为1的数据包,实现译码。而且,以新的译码方案为基础,设计对应的反馈机制,使其能够以小的代价,在不稳定的网络环境中更加效率可靠地传输数据。实验结果表明,与现有译码方案相比,本文译码方案可以提高译码率35%。
1 LT码原理和相关工作
LT码属于无码率纠删码,纠删码的实现机制如图1所示,发送端要向接收端发送一组源码 {s1,s2,s3,s4,s5}。 首先发送端的编码器对这组源码进行异或操作,并获得数量略大于源码数量的编码分组 {t1,t2,t3,t4,t5,t6,t7}, 并将这些编码持续发送到接收端。由于网络传输状态不稳定等原因,某些编码在传输的过程中丢失。而接收端在接收到一定数量的编码后,译码器会对这些接收到的编码进行译码。虽然传输中丢失部分编码,但是接收到的编码中含有全部的源码数据,通过译码最终仍能获得全部的源码。因此,基于纠删码的数据传输能够提高数据传输的可靠性。

图1 纠删码原理
LT码分为编码和译码两部分,其中LT的编码过程如下:
(1)根据预定的度分布函数,随机选择一个di作为编码数据的度数;
(2)在k个源码中,随机选取di个源码;
(3)对所选的di个源码进行异或运算产生编码数据ti。
这里的度di是编码ti关联的源码的个数。如图2所示,编码器首先会使用预定的度函数策略随机产生一个度di,然后在源码中随机选取di个源码。在选到di个源码后,编码器对这di个源码进行异或运算,产生编码ti。
LT码的译码过程如下:
(1)在接收到的编码分组中找到一个度数为1的编码,恢复与之相连的唯一一个源码;
(2)将已经恢复的源码和与其相连的所有其它编码进行模二和(异或)运算,并将二分图中对应的边删除;
(3)重复步骤(1)、(2),直至当前编码分组中不存在度数为1的编码时,译码停止。

图3 LT码译码过程
如图3所示,首先在图3(a)中找到度为1的编码t2,恢复与之相连的唯一源码s2,并删除与编码t2关联的边,结果如图3(b)所示。将已经恢复的源码s2和与其相关联的所有其它编码t3和t4进行模二和运算,并将其对应的边删除,结果如图3(c)所示。继续在图3(c)中找到度为1的编码t4,重复上述操作,直至全部解出3个源码s1,s2,s3,结果如图3(f)所示。
一方面由于LT码的译码是基于度为1的编码进行译码的,因此译码代价会因R集合为空集概率的增加而增加(集合R指度为1的编码集合)。当没有度为1的码出现时,基于LT码的译码过程失败,接收端需要继续接收经过编码的源码,进而又加大了发送消息数目的代价。
度概率分布影响了LT码的编译码的性能,一方面,di的选取既要保证编码数据携带足够的源信息,选择较大的di使得更多的源码参与编码。另一方面,di过大会加重编码和译码的复杂性。为了提高LT码性能,在文献[6]中,Wang等尝试优化具有少量符号的LT代码的度分布的配置参数。在文献[7]中,Ebrahimzadeh等定义了一种全新的度数分布函数,并应用高斯消元法[8]进行译码。通过这种方式虽然减少了分组开销,但其译码复杂度却是二次方的。在文献[9]中,Zhang和Lei分析了度选择的影响,并将两个度分布按一定比例组合在一起,通过优化波纹大小进一步调整度,从而获得一个新的度分布。在文献[10]中,作者提出了一种使用全部K个编码和K-1个编码异或产生的编码进行译码,但是译码率和传统的LT译码率相同。文献[11]中,作者提出通过两个度数相差1的两个编码,存在通过异或产生度为1的新的编码的方法,结果确实可以在一定程度上提高译码的效率。
虽然现有方法在提高编码和译码性能做了不少尝试。然而,当不存在一个包的度为1和两个编码异或产生度为1包时,现有方案无法译码,译码率低下。而且,现有的LT码通常不反馈,使得每次发送的码很大的概率是对译码没有帮助的码,这也进一步增加了发送消息数目的代价。本文针对上述问题,提出高译码率带反馈的LT码,从而提高译码率降低传输代价。
2 高译码率带反馈的LT码
针对LT码存在的译码率不高且发送消息数目代价大的问题,本文提出了一种高译码率带反馈的LT码(H-ACK-LT)。下面介绍H-ACK-LT的编码、译码和反馈3个过程。
2.1 H-ACK-LT编码
H-ACK-LT采用第1章LT码编码框架,实现无码率编码。因为度分布会影响译码的效率,因此选取合适的度函数至关重要。目前有许多关于度分布的函数,如基于MBRD度分布函数[12],理想孤波度分布和鲁棒孤波度分布[13]等。在理想的孤波分布函数中,为了能够保证产生的绝大多数数据包的度较低,度概率分布的设计如下

(1)
然而理想孤波分布在译码过程中发生没有度为1的编码的情况。而在一些更坏的情况下,可能一些源码sk根本没有参与编码,因此也无法通过译码获得。目前被广泛使用的鲁棒孤波度分布函数,它是基于理想孤波分布函数的改进,鲁棒孤波度分布函数的定义请参见文献[14]。
鲁棒孤波度分布函数引入了一个补充函数τ(d)
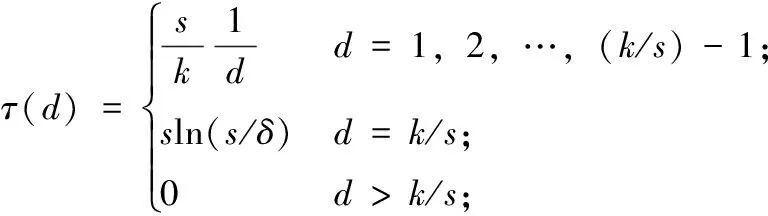
(2)
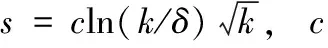
改进后的鲁棒孤波度分布函数μ(d) 如下
(3)
其中,Z是一个归一化参数,Z=∑dρ(d)+τ(d)。 当译码成功的概率至少为1-δ时,需要接收编码的个数为k′=kZ。
2.2 H-ACK-LT译码
传统的译码方法当处理完度数为1的编码后,译码过程将无法继续,这使得传统译码的译码率通常不高。后来提出的一种基于二次译码的算法指出,在译码停止后剩下的未译码的编码数据中仍然具有可解性。因此,本算法尝试对剩余编码数据包进行译码,进一步提升译码率。
设 {s1,s2,…,sk} 为源码集合, {t1,t2,…,tn} 为编码集合,对应的编码矩阵A为0,1矩阵

(4)
其中,A∈k×n。
该矩阵的第j个列向量表示第j个编码是由哪些源码数据编码完成的。当列向量只有一个1时,表明这个编码是度数为1的编码,可以直接求解对应的源码。LT译码就是当收到一组编码数据(令收到的编码个数为k′),以及其对应的编码矩阵时,求解源码的过程。
安:当然了,我们刚才所讨论的一切,并不意味着一个功底不足、技术疏漏的普通人可以迅速通过这样的方法来演奏如此之难的作品。而是说,有相当技术的专业学生,在面对这样极具挑战的作品时,可通过这样的方法,达到事半功倍的效果。而且,这样的方法本身也需要极大的智慧!这不仅事关句法的选择、旋律的修饰,更是需要我们时刻思考发力的方法,以及对声音的考量。
在LT译码过程中,找到度为1的编码数据成为译码的关键。现有工作要么通过直接找度为1的编码或者找两个编码异或生成度为1的编码来进行译码,如果通过编码数据之间的异或运算无法产生度为1的编码时,则译码停止。我们发现,即使现有方法的译码过程停止时,仍然有机会获得度为1的编码,并进一步继续译码。如 {abcde,abc,bcd,ce} 表示4个由源码 {a,b,c,d,e} 编码后得到的编码,通过这4个编码进行异或运算得到新的编码:abcde⊗abc⊗bcd⊗ce→b。 新的编码b只包含一个源码,由于新的编码b的度数为1,译码过程可以继续进行。因此,我们提出新的LT译码算法如下:
(1)初始化i=1
(2)While(i≤k′)
1)选取编码矩阵的i列,将选取i列进行异或运算,如果i=1时,将选取的1列与0向量异或
2)如果能找到i列,使得异或结果为度为1列向量
则根据异或的结果恢复与此编码相连的唯一源码。将已经恢复的源码和与此源码相连的所有其它编码进行模二和运算,消除此源码在这些编码中的模二和分量,并更新编码矩阵,令i=1;
3)如果不能找到异或结果为度为1的列向量
i=i+1;

图4 编码和编码矩阵
如图4所示,图4(a)中给出源码与编码关系的二分图,其中黑色圆圈表示未恢复的源码,白色圆圈表示已恢复的源码,方块表示编码。图4(b)给出相应的编码矩阵,矩阵行表示源码,列表示编码。矩阵第i行第j列元素为1,表示第j列的编码是由第i行的源码生成的。若一列只有一个元素为1,表明该编码是度为1的编码。在图4(a)中发送端有一组源码: {a,b,c,d,e,f,g}。 首先编码器基于度分布策略对源码进行随机编码,得到一组编码: {abcdefg,abc,bcd,cef,f,abcdef}, 并将它们发送给接收端。在接收端,对接收到的这组编码进行译码。定义两个集合S和T,分别表示已恢复源码集合和待恢复编码集合。译码过程如下:
相应更新编码矩阵
(2)此时T中无法找到度为1的编码,传统的译码过程在这种情况下已经结束。而基于二次译码的译码方法可以通过两两异或产生新的度为1的编码。通过找到度数相差1的两个编码: {abcdeg,abcde}, 两者异或产生度为1的编码g,再对与g相关联的编码做异或:S={f,g},T={abc,bcd,ce,abcde}。
更新后的编码矩阵
(3)经过步骤(2),T中无法找到度为1的编码,同时也无法找到两个度数相差1的编码。此时,基于二次译码的方法由于无法产生度为1 的编码而终止译码。而能够处理更复杂组合的H-ACK-LT译码方法则可以继续译码。H-ACK-LT算法首先随机选择3个组合,尝试通过相互异或产生度为1的编码,然而最终无法通过异或产生度为1的编码。接下来尝试选择4个编码组合来产生度为1的编码,如下:abcde⊗abc=de,de⊗bcd=bce,bce⊗ce=b。 得到了度为1的编码b,对所有与b相关联的编码做异或:S={f,g,b},T={ac,cd,ce}。
更新后的编码矩阵为
(4)重复上述步骤,直至尝试所有组合仍无法通过异或产生度为1的编码,此时H-ACK-LT译码算法停止。
H-ACK-LT译码算法在进行译码时,先在编码中寻找度为1的编码,通过异或译码和此编码相连的编码。当没有度为1的编码数据包时,通过多组编码间的异或运算产生度为1的编码,通过异或译码和此编码相连的源码。重复上述步骤,直至译码成功或者无法再产生度为1的编码。通过上述译码过程,当传统译码和基于二次译码停止时,H-ACK-LT译码方法能够深度挖掘出度为1的编码。因此,相较于传统传统译码和基于二次译码方法,H-ACK-LT有更高的译码率。
2.3 反馈机制
H-ACK-LT算法的译码机制很大程度上提升了译码率,但是一些情况下,译码过程因为无法继续产生度为1的编码而被迫终止,因而无法成功解出全部源码。因此,需要继续接收编码来重新启动译码。此时,重传的编码若是由那些已经译码的源码异或而成,则这些编码不仅无法帮助进一步的译码,反而会增加译码的复杂度和编码的冗余。随着译码的源码越来越多,这种情况的概率也会明显增加。
由于重传不同的编码对译码程度的影响不同,因此随机重传编码无法保证最大程度译码,甚至会增加译码复杂度和带来冗余。为了进一步最大程度译码剩余的编码,接收方可根据当前的译码情况,主动向发送方发送数据包请求。如图5所示,在LT码二分图中,未恢复的源码的度值越大,说明该源码参与的编码就越多。如果度数值大的源码已知,通过模二和运算就能消除此源码在这些编码中的模二和分量。最大可能地进一步产生度为1的编码数据,从而提高译码率。
图5 LT码二分图
因此,本文在所有的未恢复的源码中,选择度最大的源码作为重传编码,主动要求发送端发送该源码,从而提高译码率,降低传输延迟。当接收端收到新的度为1的编码时,将重新开启译码过程。
如图6所示,经过H-ACK-LT算法的一轮译码后,此时不存在度为1的编码,译码停止。此时需要重传一个仅由一个源码生成的编码来重启译码过程。而此时待恢复源码还有s1、s2和s3,度数分别为4,2和4。重传不同度数的源码,对后续译码过程的影响显然是不同的。如图6(a)所示,重传度数为2的源码s2生成的编码t5,最终只能恢复出源码s2。而如图6(b)、图6(c)所示,如果重传度为4的源码s1或s3生成的编码,经译码后则可被完全译码。因此每次重传最大度数源码生成的编码,能最大程度提升译码率。
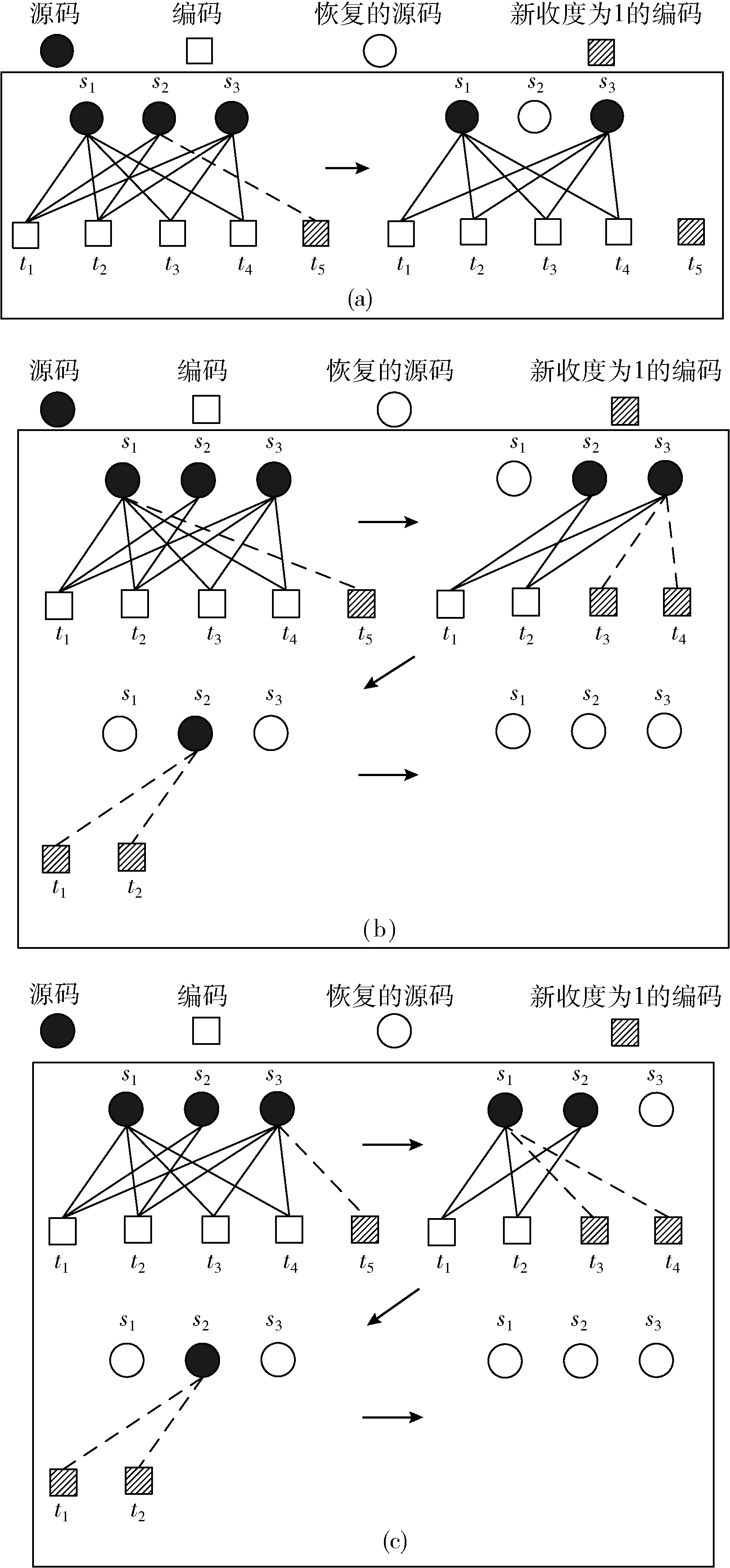
图6 反馈机制示例
带反馈机制的译码过程具体描述如下:
(1)当接收端译码器无法对剩下编码中异或产生新的度为1的包,接收端计算每个元数据si的度数,并向发送端发出度数最大的si需求指令;
(2)发送端收到接收端的需求指令,发送只包含si的编码;
(3)接收端译码器在接收到si编码后,重新启动H-ACK-LT译码算法。若全部译码成功,则停止译码。否则,重复(1)、(2)步骤,直至解出所有源码。
3 仿真实验
为了验证本文所提的H-ACK-LT性能,除了H-ACK-LT之外,本文还实现了文献[5]和文献[11]的译码方案来进行实验的比较,文献[5]和文献[11]的译码方案分别表示为Sta-LT和K-1-LT。Sta-LT在译码过程中,每次查找度为1的编码,若存在,则译码,若不存在,则停止。K-1-LT在译码过程中,首先查找度为1的编码,若存在,则译码,若不存在,则继续查找是否存在两两异或产生度为1的编码。若存在,则继续尝试使用通过两个编码异或运算产生的度为1的编码进行译码,若不能产生度为1的编码,则译码停止。H-ACK-LT算法首先查找度为1的编码,若存在,则译码,不存在则尝试利用两两异或产生度为1的编码进行译码。若不存在,则继续尝试使用3个、4个、5个……k′等运算产生的度为1的编码进行译码,若不能产生度为1的编码,则译码停止。这里的k′是所收到的全部编码数据包的个数。
因为现有工作Sta-LT和K-1-LT均不涉及反馈机制,为了进行公平比较,首先我们在没有反馈的情况下,考察3种算法的译码性能。为了进一步验证所提反馈机制对H-ACK-LT 的影响,我们将Sta-LT和K-1-LT加入本文的反馈机制,进行实验。下面列出实验结果。
3.1 无反馈编码实验
本文首先考察无反馈机制下的译码性能,采用k=15个源码进行编码实验。接收端接收到略大于源码个数的k′=(15+1) 个编码后,译码器分别用Sta-LT、K-1-LT和H-ACK-LT这3种算法进行译码。为使结果更具说服力,这样的过程重复实验100次,分别统计3种算法各自成功译码的次数。如图7所示,在100次译码中,Sta-LT成功译码9次,K-1-LT成功译码20次,而H-ACK-LT成功译码44次。结果表明,因为H-ACK-LT算法能够更加充分地挖掘潜在度为1的编码的能力,大大提高了获得度为1编码的概率,所以H-ACK-LT要显著优于前两种算法,其中H-ACK-LT相对于Sta-LT,译码成功率提高了近35%。

图7 100次编码实验中成功译码次数比较
在图8中进一步给出100次实验中,每次实验中15个源码中被成功译码的个数。为方便比较,图9列出比较3种算法译码成功个数的均值。
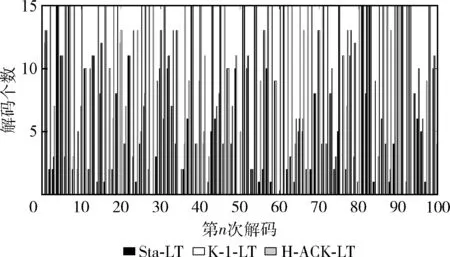
图8 成功译码个数比较
如图9所示,Sta-LT平均每次能够解出5.91个源码,K-1-LT平均每次能够解出7.81个源码,而H-ACK-LT平均每次能够解出11.68个源码。比较得出,在无反馈机制下H-ACK-LT每次解出源码的个数是最多的,解出源码个数大约是Sta-LT算法的两倍,是K-1-LT算法的1.5倍。上述结果表明,本文提出的H-ACK-LT译码算法可以大大提高译码的成功率。
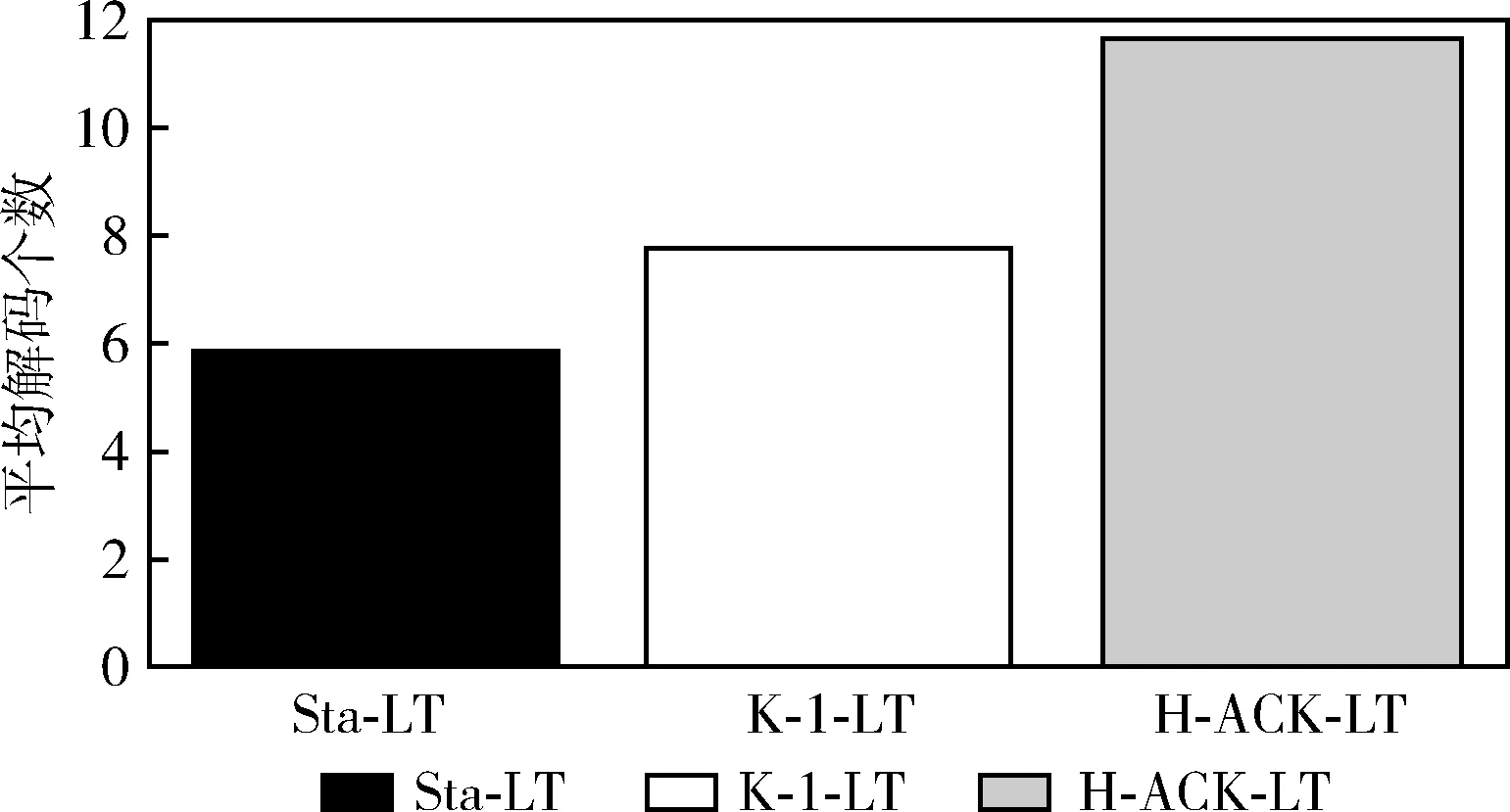
图9 平均成功译码个数
3.2 带反馈编码实验
本文接下考察反馈机制下的译码性能。同样的,首先使用编码器对k=15个源码进行编码实验。接收端接收到略大于源码个数的k′=(15+1) 个编码后,译码器分别用Sta-LT、K-1-LT和H-ACK-LT这3种算法进行译码。若仍有编码未被解出且算法无法找到度为1的编码而导致译码终止,则调用反馈机制继续进行译码,直到译码所有的编码。实验分别统计3种算法译码成功所需的反馈数据包的个数。3种算法每次译码成功所需调用反馈的次数如图10 所示。同样,为了方便比较,我们分别求出调用反馈次数的均值。
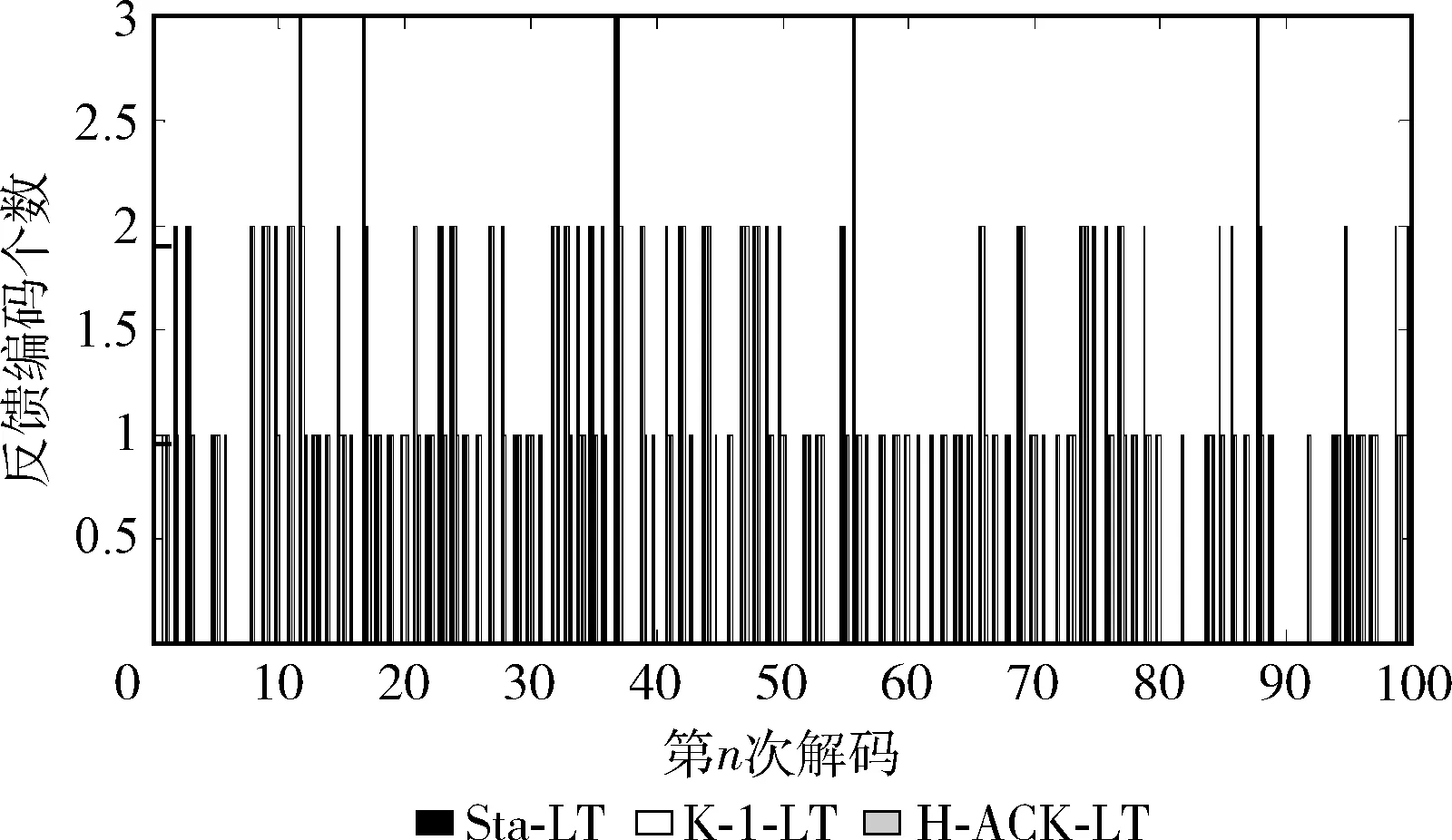
图10 反馈重传数据包个数比较
如图11所示,Sta-LT成功译码平均每次要反馈1.58次,K-1-LT算法成功译码平均每次要调用反馈1.18次,而H-ACK-LT成功译码平均每次要调用反馈0.74次,H-ACK-LT 所需反馈数据包最少,因此具有最小的传输和通信代价。
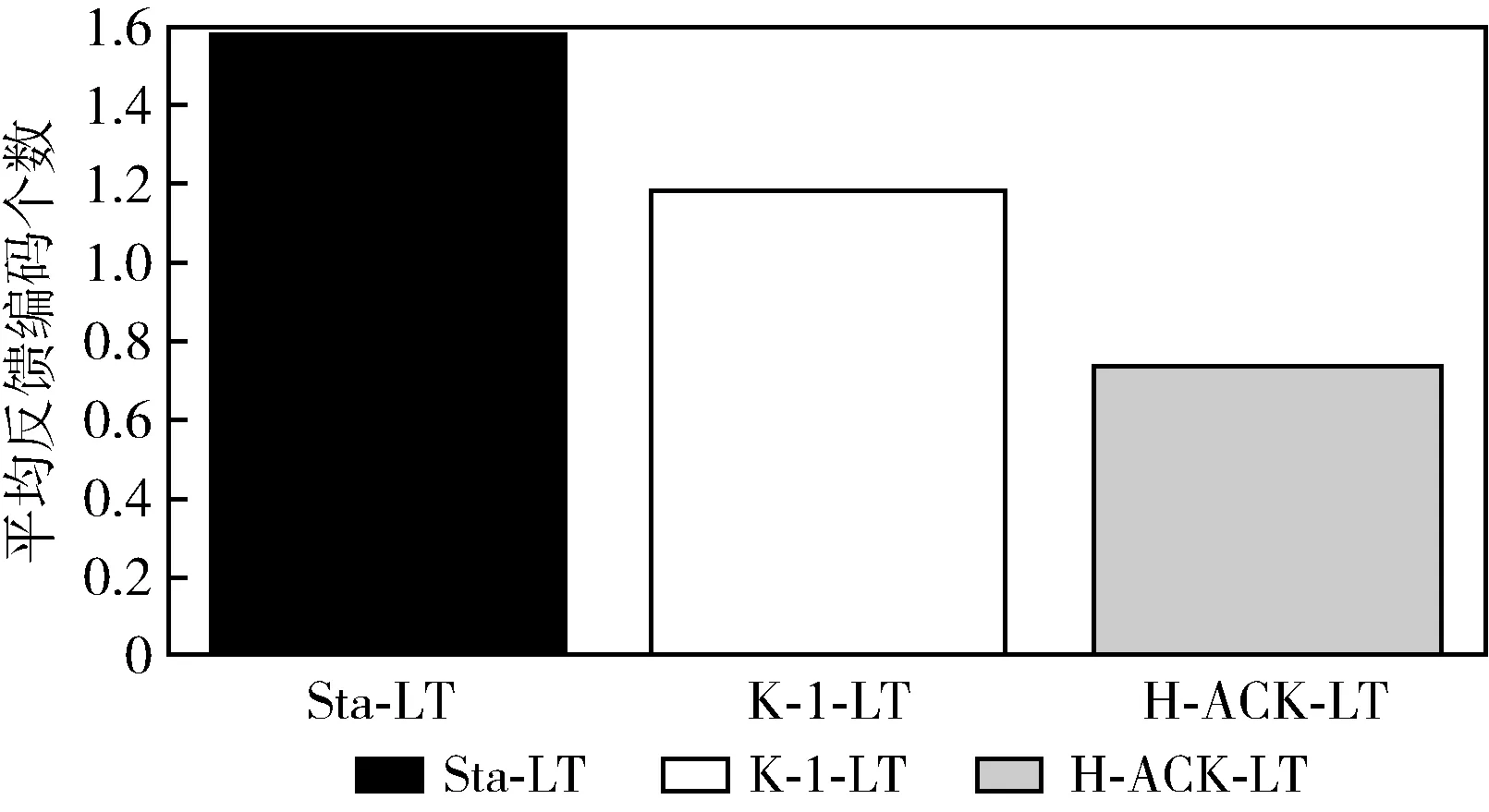
图11 平均反馈重传数据包个数
4 结束语
现有LT译码方法存在译码率不高的问题。本文提出的新的高译码率带反馈的LT码,利用多个编码之间相互异或制造新的译码条件,可以大大提高译码率。在此基础上,本文提出相应的反馈机制,在有反馈的情况下,不仅避免冗余编码的重传,而且重传的编码以极大的概率是那个能够帮助最快译码的编码。实验结果表明,与现有译码方案相比,本文译码方案可以提高译码率35%。
