基于加权相似性的MCCNN训练集选择方法
2022-02-15范聪聪葛宝瑧范怡萍
范聪聪,葛宝瑧,范怡萍
(天津大学 精密仪器与光电子工程学院,天津 300072)
0 引 言
近年来,基于卷积神经网络[1]的立体匹配算法[2-4]越来越受到关注,其中,MCCNN网络(matching cost convolutioal neural network)[2]是用于立体匹配的典型方法。使用MCCNN网络必须利用训练集来训练模型中的参数,利用测试集来评估立体匹配性能,训练数据和测试数据需要满足独立同分布原理[5],即训练数据和测试数据分布要有一定的相似性,相似性越高,匹配结果越好。因此在MCCNN的实际应用中,需要根据待匹配图像的特点,合理选择训练数据集,以达到较好的匹配结果。在双目数据集的选择上,Su等[6]选择包含真实的背景纹理和变化的光照的数据集,Lee等[7]通过定性实验,选择不同的数据集共同训练,Mayer团队[8]选择对摄像机畸变进行建模的合成数据集。上述研究通过定性实验得到选择数据集的方法,但如何通过定量的标准为待匹配图像选择合适的训练集是一个值得研究的问题。
针对MCCNN立体匹配数据集定量选择的问题,本文提出了一种基于相关性比较、余弦相似性和结构相似性加权度量的选择方法,在网络训练前先使用这3个相似性标准的加权值衡量待匹配图像与目前公开训练集的相似性,以及训练集本身的相似性,选择相似性最高的对应数据集进行训练,最后实验结果表明,通过该相似性标准选择与待匹配图像相似性高的数据集训练MCCNN网络进行立体匹配,相比常用的BM(block matching)[9]、SSD(sum of squared differences)[10]、NCC(normalized cross correlation)[11]、BP(belief propagation)[12]等4种立体匹配方法得到的视差图更准确。
1 MCCNN立体匹配原理
MCCNN的基本原理是通过卷积神经网络分别提取左右图像块的特征,获得特征向量,再利用特征向量构造损失函数,进行网络训练。网络训练完成后,利用训练好的模型对输入图像对进行立体匹配时,整个流程如图1所示。
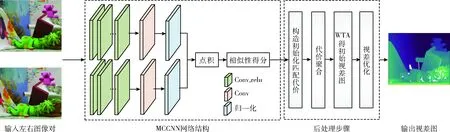
图1 MCCNN立体匹配流程
网络经过连续的卷积层提取输入左右图像对的特征,并在卷积层除最后一层外接ReLU激活函数, ReLU(x)=max(0,x) 式中x为提取的图像特征,将两个分支网络提取的特征图经过归一化和点积后,输出两个图像对的相似度,取相似度的负值作为初始化的匹配代价。然后通过基于交叉的代价聚合和半全局匹配算法后,利用“赢者通吃”策略(winner take all,WTA)找到使匹配代价最小的视差值作为该像素的视差值,从而生成初始的视差图,最后经过一致性检测、亚像素增强、中值滤波等进一步优化,生成最终的视差图。
2 目前主要的公开数据集
目前,常见用于训练的双目立体视觉数据集见表1,其中N代表自然数据集,S代表合成数据集。自然数据集是用相机等采集装置拍摄的真实场景的图片,合成数据集是使用三维建模软件渲染生成的虚拟场景的图片。自然数据集是Middlebury[13]、Kitti[14]、Eth3d[15]和Cityscapes[16]。合成数据集是Sintel[17]、Flyingthings3D、Mookaa和Dri-ving[18],下面对这些数据集进行简单的介绍。
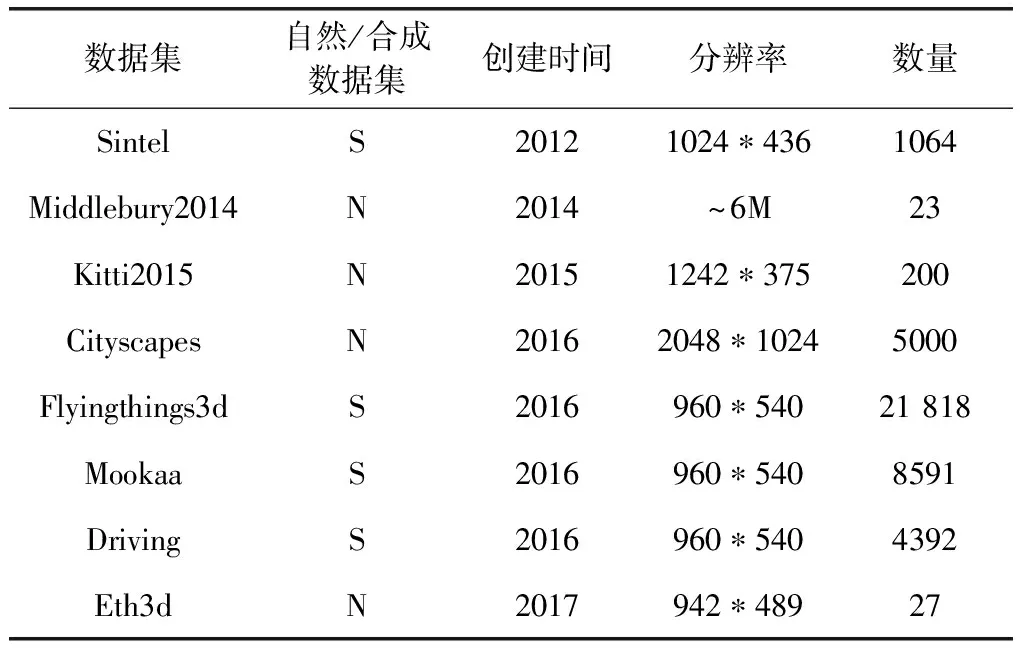
表1 双目立体视觉数据集基本特性
Middlebury数据集最早于2001年创建,均是在窒内通过控制不同的光照条件拍摄而得,示例如图2(a)所示,被广泛应用于计算机视觉领域,多用于算法的评估。Kitti数据集在2012年创建并在2015年进行了扩充,采用车载双目摄像头在街道行驶并拍摄真实道路场景,示例如图2(b)所示,是目前最常用的自动驾驶场景下的算法评测数据集。Cityscapes数据集是Cordts等在2016年创建的城市景观数据集,示例如图2(c)所示,和Kitti类似采用车载相机录制了50个不同城市大量多样的街道场景视频序列。Eth3d数据集是Thomas等使用单反相机及具有不同视场的同步多相机装置拍摄的图像对,示例如图2(d)所示,包括各种室内、室外场景的多视图和二视图高分辨图像对。
近年来合成数据集得到了较快发展,Butler等通过开源动画电影中的现有数据,在三维建模软件blender中进行渲染提供了一个合成数据集Sintel,示例如图2(e)所示,包含了一些逼真的场景,例如雾气和运动模糊。Mayer等同样利用开源的3D软件构建了SceneFlow数据集,其中包括3个子集,Flyingthings3d、Monkaa和Driving,示例如图2(f)~图2(h)所示,Flyingthings3d数据集采用随机导入网络模型并为模型附上纹理,之后将模型沿着3D轨迹飞行,最后进行渲染采集。Mookaa数据集是利用一段开源的动画电影,选取关键帧并进行随机的更改。Driving数据集采取导入逼真的汽车、路灯和树木模型并进行渲染采集。3个数据集共计34 799对图像,极大地解决了数据集不足的问题,是目前规模最大的双目数据集。

图2 数据集示例
3 基于加权相似性的数据集选择方法
3.1 图像的相似性度量标准
针对不同的图像特征指标和计算原理,可以分为基于概率[19-21]、几何特征[22-24]以及语义特征[25]的3类图像相似性度量方法。
基于概率的相似性度量方法是根据图像像素值的概率分布,对图像的直方图进行比较,几种常用的比较方法有:
(1)巴氏距离[19](Bhattacharyya distance)
(1)
(2)相关性比较[20](Correlation)
(2)
(3)卡方比较[21](Chi-Square)
(3)
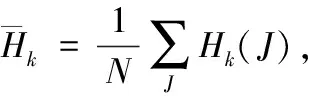
基于几何特征的相似性度量方法主要有距离相似度[22]、方向相似度[23]以及形状相似度[24]等指标。距离相似度指标主要是计算图形特征之间的距离,通过距离的大小衡量相似性程度,主要有欧氏距离、曼哈顿距离等,距离相似度计算比较简单往往需要和其它指标综合使用。方向相似度主要是计算图像之间的角度差,代表为余弦相似性,如式(4)所示,通过测量两张图片向量夹角的余弦值来度量它们之间的相似性大小。向量夹角越小,则余弦值越接近1,方向更加吻合,两张图片越相似
(4)
式中:xi、yi为要比较的两张图像在i位置处的像素灰度值,n为像素总数。形状相似度指标有面积比、重叠面积比、周长比、形状比率等,某一特征指标V(如面积、周长等)的相似度计算如式(5)所示,形状相似度指标范围为(0,1),当两张图像分布越相似时,形状相似度指标越接近于1
(5)
基于语义特征的相似性度量表现在图像的像素间存在着很强的相关性,这些相关性在视觉场景中携带着关于物体结构的重要信息。主要由结构相似性(structural simila-rity,SSIM)[25]来衡量,结构相似性用图像均值作为亮度的估计,标准差作为对比度的估计,协方差作为结构相似度的估计。给定两张图像x和y,其结构相似性可按照式(6)求出
(6)
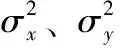
在进行相似度计算时一般会选取多个相似性指标进行综合计算。因此根据计算量和应用程度选取了基于概率的相关性比较、基于几何特征的余弦相似性比较和基于语义特征的结构相似性比较,这3种相似性度量标准的取值范围都为(0,1),且均为两张图像越相似时,值越近于1。用这3种相似性度量标准计算测试集与训练集的互相似性以及训练集本身的自相似性值。
互相似性以图3(a)、图3(b)所示为例,是指待匹配图像Kitti与训练集Middlebury图像数据分布的相似性;自相似性以图3(c)、图3(d)所示为例,是指训练集Middlebury内部不同图像数据之间的相似性。

图3 相似性示例
计算的方法主要有总分法[26]和加权法[27]。总分法将选取的各个相似度指标的和作为相似度值,而加权法考虑了不同指标对综合相似度值的不同影响,使用比较广泛,故采用加权法进行综合计算,一般加权法所采用的权重系数靠经验决定,主观性较大,因此在本文中采用实验的方法确定加权系数。
3.2 加权系数确定流程
加权系数确定流程如图4所示,整个过程描述如下。
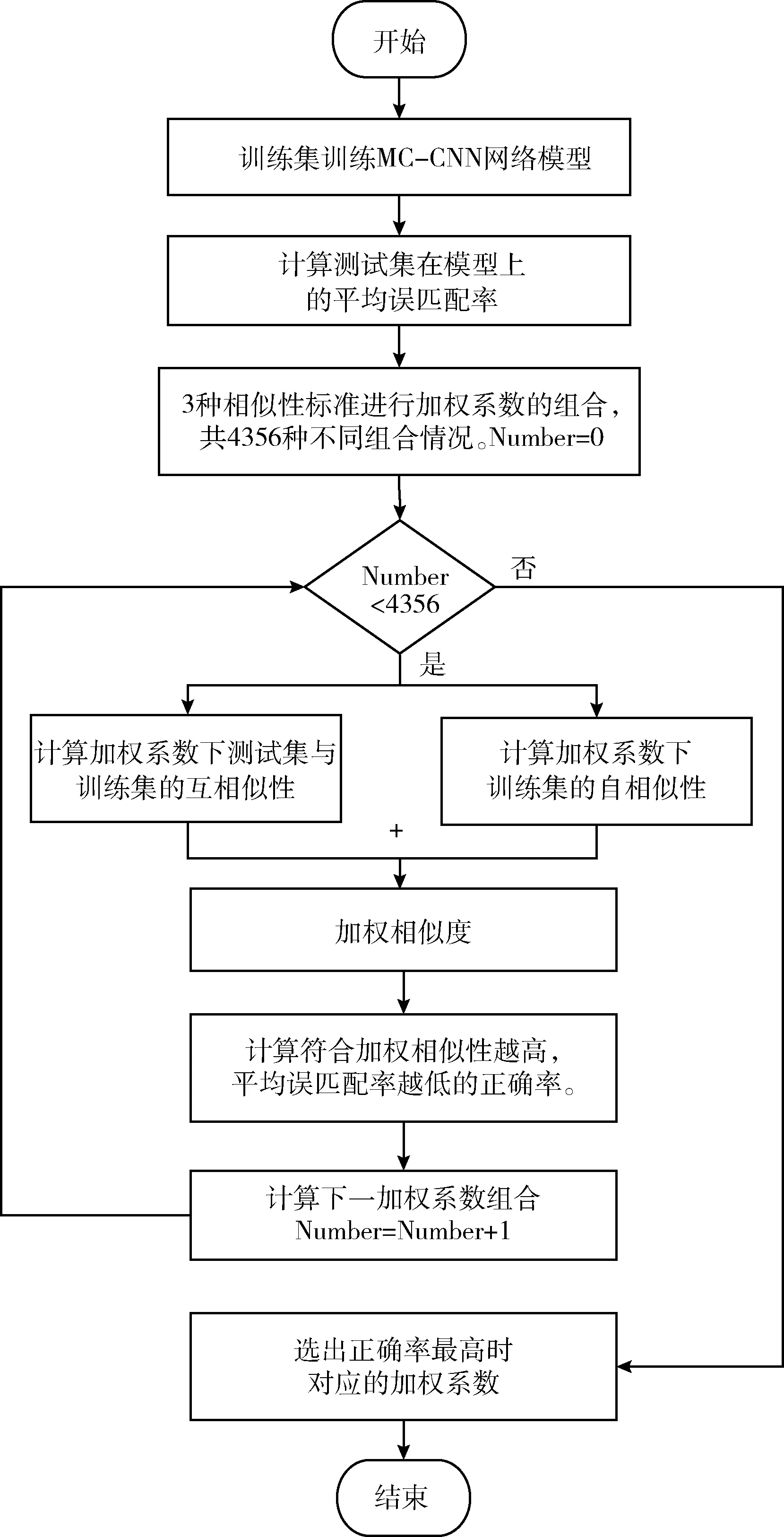
图4 加权系数确定流程
(1)先将第2节介绍的8种数据集依次在MC-CNN网络上训练得到8种网络模型,将测试数据依次在这8种模型上匹配得到视差图。视差图的评价标准采用平均误匹配率,误差容限阈值取3像素,即计算得到的视差图与视差真值相差大于3个像素时,认为是错误匹配点。这样得到在测试集上每种模型的平均误匹配率,结果见表2。
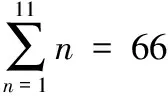
(3)按不同的加权系数分别计算出测试集与训练集的互相似性和训练集本身的自相似性值,并将两者的值相加,即加权相似性范围为(0,2)。
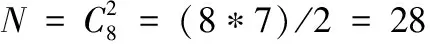
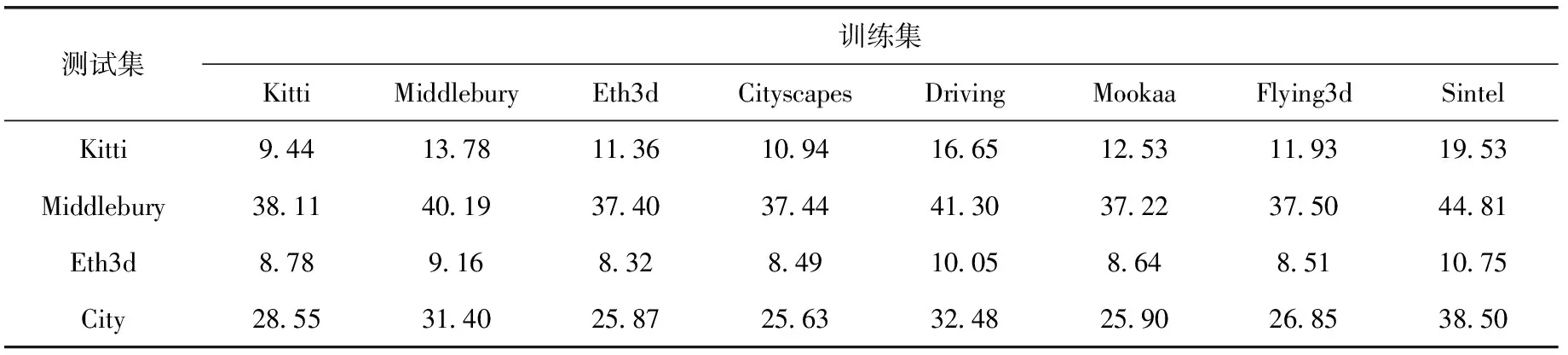
表2 各类数据集测试平均误匹配率/%
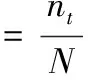
(7)
(5)计算下一加权系数组合下的正确率,直到计算完成全部4356种不同加权系数组合下的正确率。
(6)选择正确率最高时对应的加权系数组合。
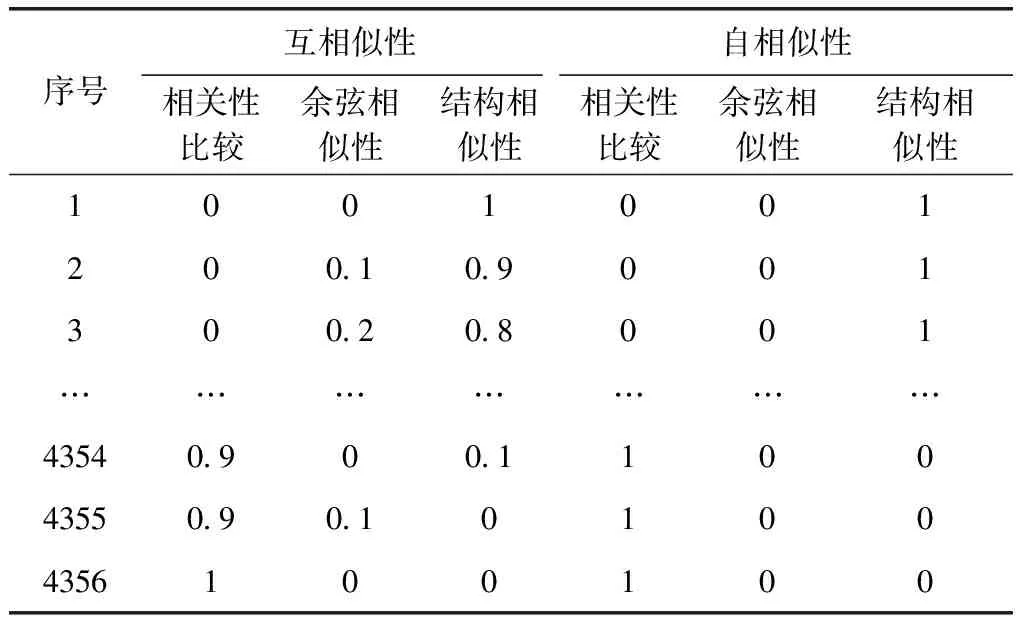
表3 加权系数组合情况
3.3 结果与分析
将表3中不同加权系数的组合情况与在不同情况下的正确率绘制散点图,如图5所示。同时还计算了当只考虑自相似性和只考虑互相似性时的正确率,绘制这两种情况下加权系数的组合与在不同组合下正确率的散点图,如图6、图7所示。
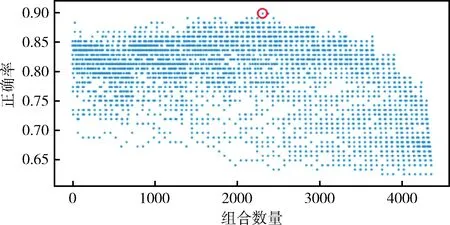
图5 综合互相似性和自相似性时的正确率
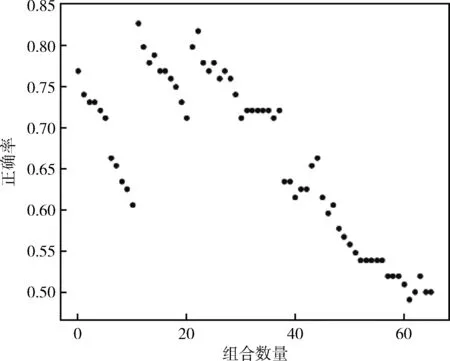
图6 只考虑自相似性时的正确率
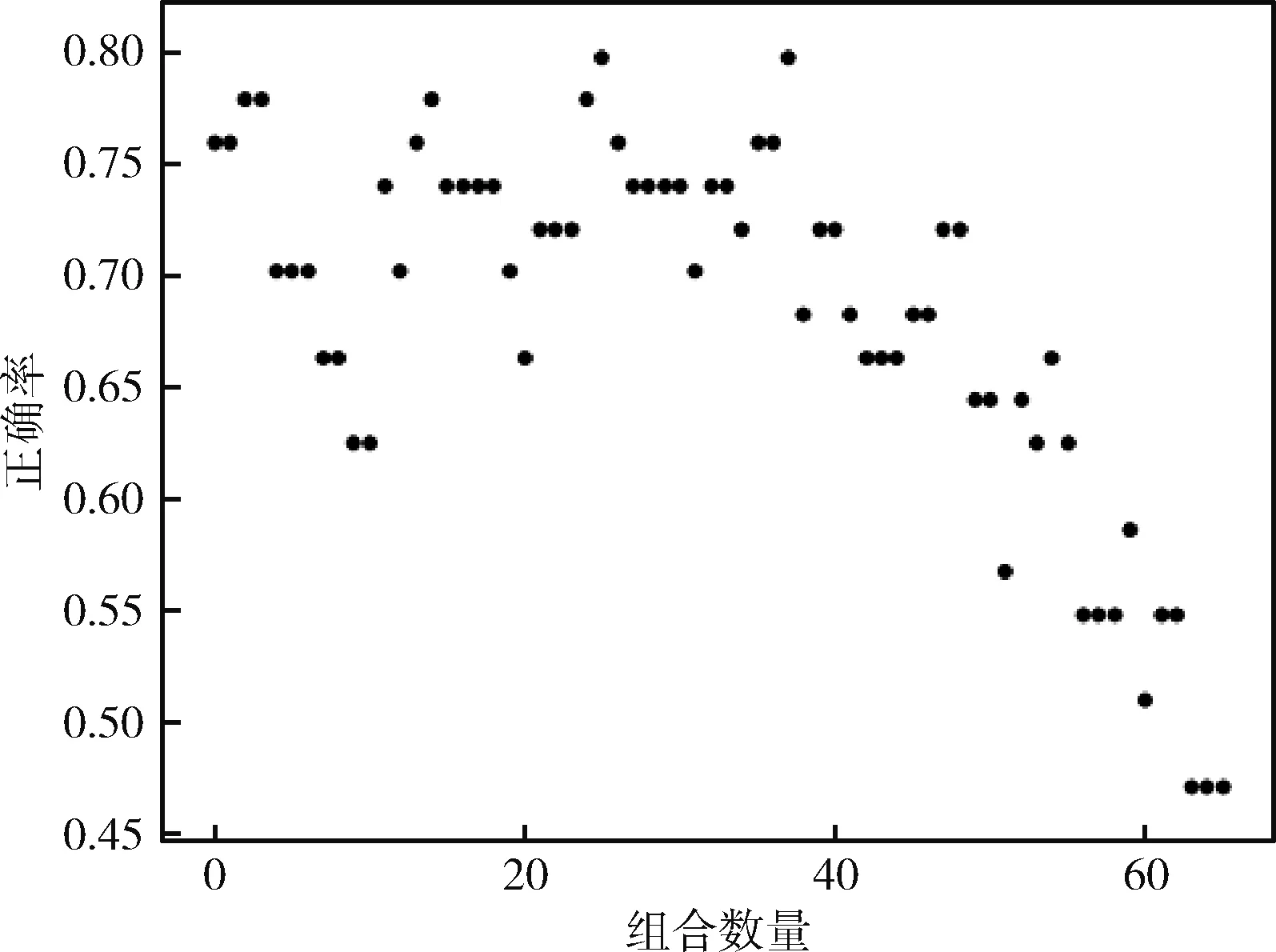
图7 只考虑互相似性时的正确率


表4 不同情况下符合相似性越高、 平均误匹配率越低的正确率/%
按得到的权重系数对测试集与训练集的互相似性和训练集本身的自相似性进行加权,加权结果见表5,为直观表达在这一权重系数下,相似性和平均误匹配率的关系,将表2和表5中的数据绘制散点图如图8所示,其中图8的横坐标为表5中测试集与训练集的加权相似性值,纵坐标为表2中测试集的平均误匹配率。由于在这一权重系数下,符合相似性越高,平均误匹配率率越低这一关系的正确率为90%,所以出现了少部分异常点,但整体上随着相似性的增加,平均误匹配率呈下降趋势,加权相似性最高时,匹配结果最好。

表5 测试集和训练集的加权相似度
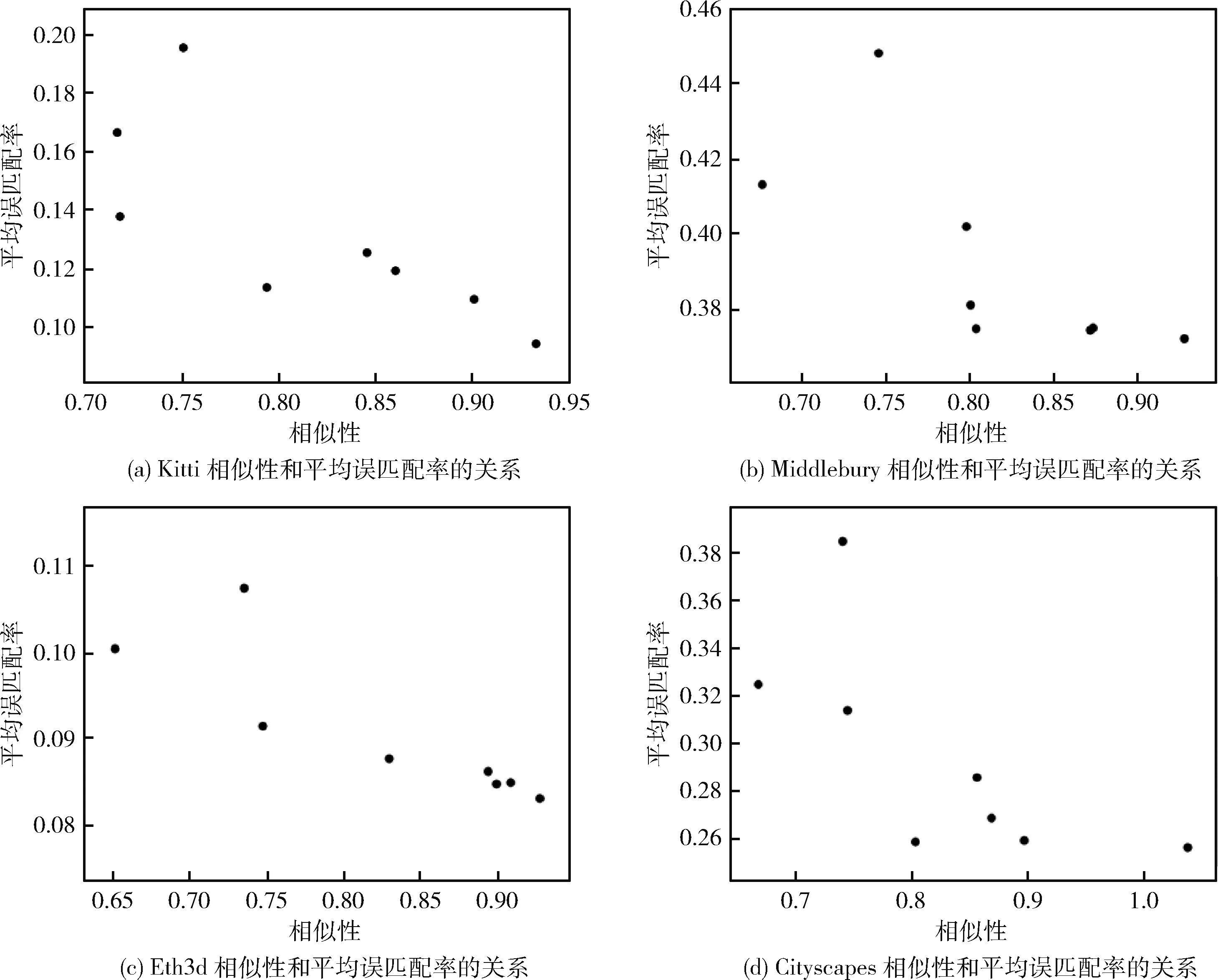
图8 相似性与匹配平均错误率的关系
4 实 验
为了对加权相似性度量方法的有效性进行验证,进行了二组实验。实验一,选择InStereo2K[28]数据集数据进行实验,如图9(a)、图9(b)所示的InStereo2K数据集中的两组图片作为待匹配数据,为其进行训练集的选择。实验二,以两组实际拍摄图像对作为待匹配数据进行实验。实拍图像是使用两台佳能5D MARKIII单反相机与两支佳能EF 600 mm f/4L IS USM镜头进行采图,将采集的图像对进行立体校正,如图9(c)、图9(d)所示为经过立体校正后的两组左右图像对。
4.1 视差图质量评价标准
视差图的质量是所提训练集选择方法性能的直接反映,评价标准采用比较不同数据集训练匹配得到的视差值与标准视差值相差大于3个像素的平均误匹配率,但由于实拍图像没有标准视差图,本文先由SGM[29]算法计算得到参考视差图,图9中图(a3)、图(b3)为InStereo2K两组图片的标准视差图,图(c3)、图(d3)为实拍图像经过SGM算法计算得到的参考视差图。
4.2 加权相似性与平均误匹配率分析
首先按3.3节得到的3个相似性标准的加权系数,计算图9(a)~图9(d)这4组图片数据与8种公开训练集的互相似性,以及各训练集的自相似性,加权相似性结果见表6,从表中可以看出,InStereo2K两组图片与Cityscapes数据集的加权相似性最高,实拍图像1与Flying-things3d数据集加权相似性最高,实拍图像2与Mookaa数据集加权相似性最高。
为实验图片选择加权相似度最高的数据集进行训练匹配,为了进行对比,同时选择相似性较低的数据集进行训练匹配,图9(a4)~图9(d4)分别表示对InStereo2k图片和实拍图像使用加权相似性较高的数据集训练匹配得到的视差图,图9(a5)~图9(d5)表示采用加权相似性较低的数据集训练匹配得到的视差图。在图中标注了与标准视差图相比得到的平均误匹配率,数值越低表示匹配结果越好。
从图9中看到,采用相似性较低的数据集得到的视差图相比标准视差图有很多错误匹配点,效果不是特别理想,而采用加权相似性较高的数据集得到的视差图更为平滑,也均比采用相似性较低的数据集训练得到视差图的平均误匹配率低。

图9 视差图结果对比
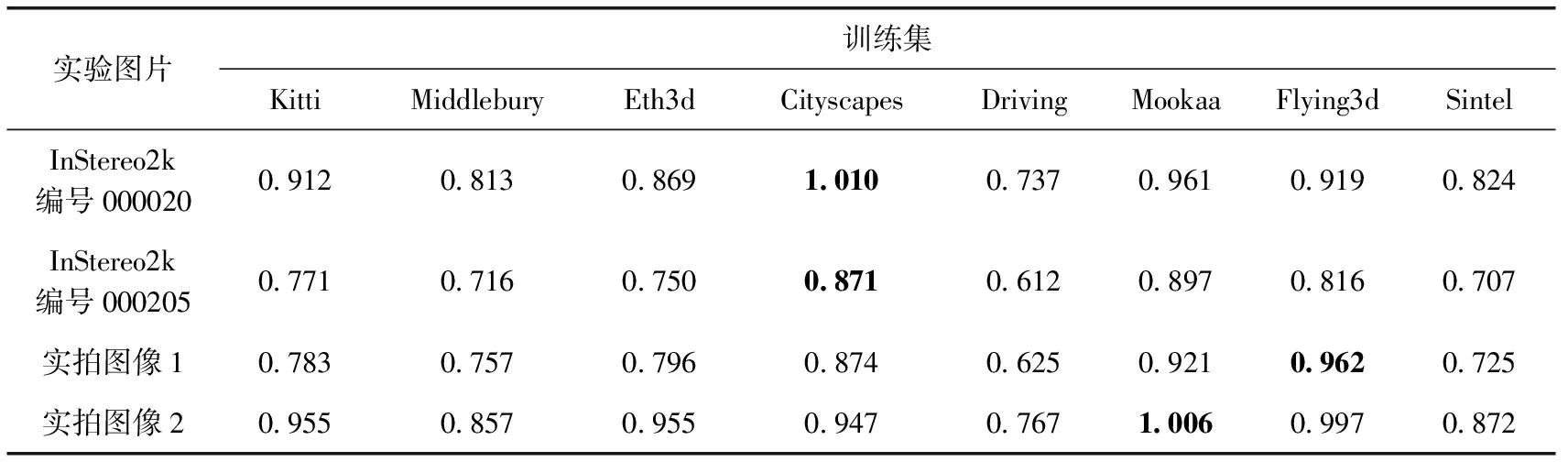
表6 实验图片与训练集的加权相似性
实验说明在本文选择的相似性标准的加权系数下,实验图片与训练集的加权相似性和平均误匹配率符合相似性越高,平均误匹配率越小这一关系,选择相似性较高的对应数据集训练可以提高视差图的准确率。
为了进一步评价所提方法的立体匹配效果,选择了BM(block matching)[9]、SSD(sum of squared differences)[10]、NCC(normalized cross correlation)[11]、BP(belief propagation)[12]这4种常用的匹配方法进行对比实验,实验在Windows 10系统上进行,使用处理器Intel(R) Core(TM) i7-8700,3.2 GHz,内存8 GB。使用Python语言+Opencv库,输入图像与图9的实验一样,实验结果见表7和表8,表7中给出了5种匹配方法对相同的4组输入图像的视差图平均误匹配率,表8为运行时间。从表7中可以看出,相比于其它对比方法,使用所提方法选择的数据集去训练MCCNN网络进行立体匹配,得到的视差图平均误匹配率低于其它对比方法。同时,从表8的运行时间来看,所提方法的运行时间比BM算法长,而比其它方法都短,因此,综合平均误匹配率和运行时间,特别是更多场合需要匹配精度高、误匹配率低,本文方法的平均误匹配率比BM算法低近一倍,因此,根据所提加权相似性选择训练集方法训练MCCNN网络进行立体匹配,其效果是显著的。
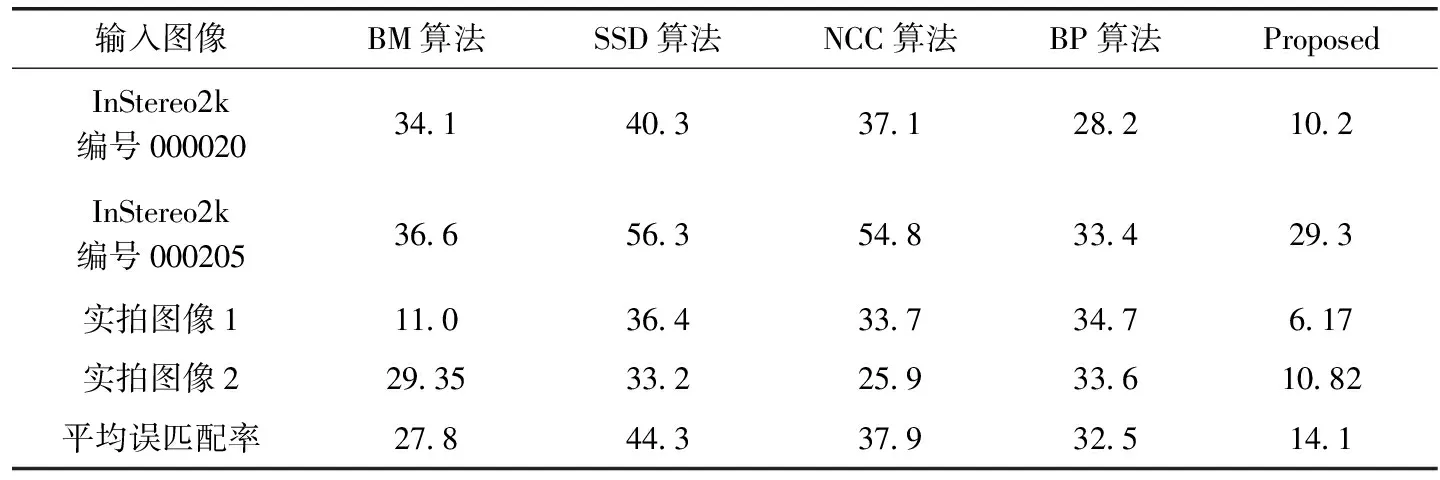
表7 不同算法的平均误匹配率/%
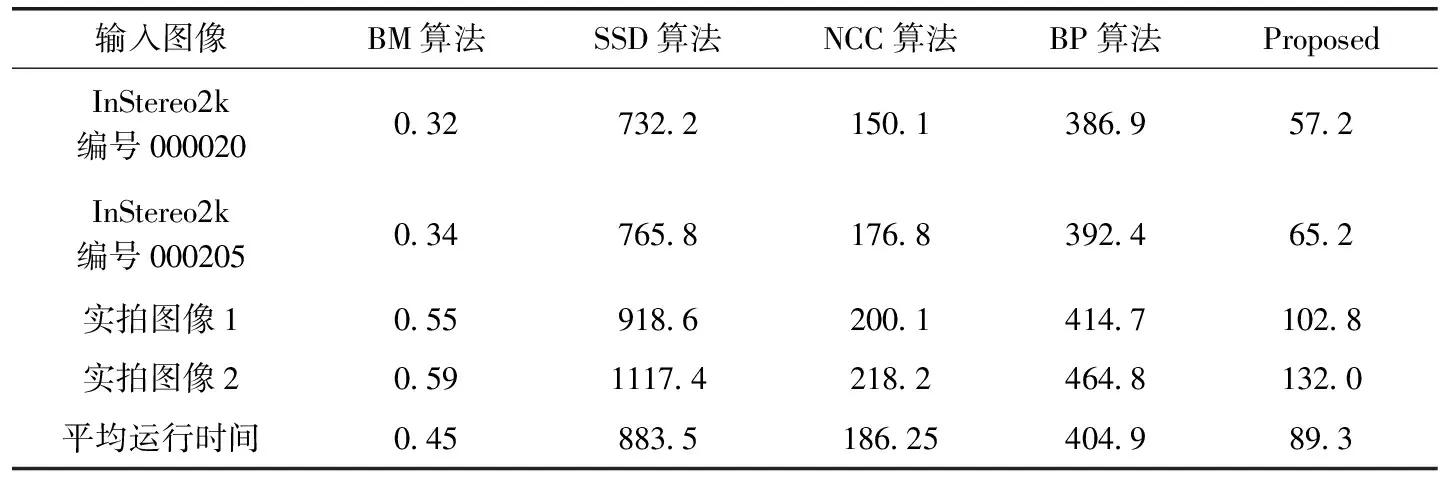
表8 不同算法的运行时间/s
5 结束语
