基于词典分类器的细粒度机构名识别
2022-02-15王路路吐尔根依布拉音姜丽婷艾山吾买尔
李 磊,王路路,吐尔根·依布拉音,姜丽婷,艾山·吾买尔
(新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046)
0 引 言
命名实体识别的主要方法有两种:基于统计的方法和深度学习方法。统计学方法依赖于特征的选取,对于语料库的依赖性较大,建立领域语料库又是一大难点[1]。而深度学习方法不需要特征工程,适用性强,因此,目前大多数采用深度学习方法实现命名实体识别。
随着深度学习的不断发展,基于神经网络的命名实体识别已在新闻领域呈现了很好的性能。但现有的命名实体识别数据集大多数只有3种实体类型,为了更好理解数据,研究者们提出了针对开放领域的细粒度命名实体识别。如盛剑等[2]采用LSTM-CNN-CRF完成中文细粒度命名实体识别,其F1值为0.8左右;Xu, Liang等[3]采用RoBERTa-wwm-large[4]模型对CLUENER20 20数据集实现细粒度命名实体识别,其F1值为0.8042。
在开放领域下人名、机构名、地名的研究十分必要,其中机构名所占比重较高,但由于机构名结构复杂、罕见词多且存在别名、缩略词(如“哈佛”与“哈佛大学”)、数据文本中存在英文实体等问题,因此识别精度不高,而且细粒度机构名识别在关系抽取、机器翻译等应用发挥重要作用。基于以上问题,本文提出了分阶段细粒度机构名识别的思想,首先采用Bert-BiLSTM-CRF模型对MSRA微软亚洲研究院开源数据集[5]进行粗粒度机构名识别;其次,建立机构名细粒度实体词典,采用最优深度学习分类器Bert-CNN训练机构名分类器;最后使用机构名分类器对识别出的粗粒度机构名进行细粒度分类。实验结果表明,细粒度命名实体识别的F1值达到0.8117,相较于词典匹配方法,分阶段实现细粒度命名实体识别是有效的。
1 相关研究
实体识别可以看作一种文本序列化标注问题,在标注语料上进行监督学习。而深度神经网络能够挖掘文本潜在的抽象信息,有助于提高实体识别的性能[6]。目前,中文命名实体识别的公开数据集有Boson数据集[7]、1998年人民日报标注数据集和MSRA微软亚洲研究院开源数据集[5]。英文公开的细粒度命名实体识别的数据集有ACE、FIGER、HYENA、OntoNotes、TypeNet、UFET等,而公开的中文数据集仅有CLUENER[3]和CFET[8]。
早期的命名实体识别主要是基于规则的方法,主要依靠大量人工标注的规则,但是由于各种语言的结构不同,难以制定一套统一的使用规则。针对不同的领域,专家要书写不同的规则,存在代价很大,制定规则周期较长等问题[9]。传统的命名实体识别主要是基于统计的方法[2],例如支持向量机(SVM)[10]、隐马尔可夫模型(HMM)[11]、条件随机场(CRF)[12]等。条件随机场在分词和命名实体识别任务上效果较优,其标注框架特征灵活,全局最优;缺点在于收敛时间和训练时间较长[2];支持向量机的准确度较高,但是隐马尔可夫的训练速度更快。综上所述,统计学方法依赖于特征的选取,而且对于语料库的依赖性较大,但是建立领域语料库又是一大难点[2]。而深度学习方法不需要规则且灵活度高,因此,现在研究者大多采用深度学习的方法,该类方法也是现在命名实体识别的主流方法,它以端到端的方法从原始输入中自动获取识别和分类实体所需的表示[9]。主要有CNN、RNN、Bert等神经网络模型。
目前,基于英文数据集的细粒度命名实体识别主要有以下几个方法:①传统方法,Xiao Ling提出细粒度命名实体识别[13],该文使用112个标签和一个线性分类器进行多标签分类。这是细粒度命名实体识别的开端。Yosef等[14]提出使用多个二分类SVM进行实体识别,共有505个标签。②计算相关性方法,为了平衡细粒度标签之间的关系,Yogatama等[15]提出将输入的文本信息和标签信息全部映射到低维空间,可以用标签在低维空间的距离来衡量它们之间的关系,相关性越高,距离越近。③神经网络方法,Shimaoka等[16]提出了基于注意力机制的神经网络模型,该模型使用LSTM对实体上文编码,然后对实体的上下文采用注意力机制,充分提取输入句子的语义信息。Dogan等[17]提出用预训练模型ELMo和知识库Wikipedia实现实体识别。
在中文细粒度命名实体识别研究上,盛剑等[2]定义了12个领域下的46个细粒度标签,采用LSTM-CRF-CNN实现命名实体识别,然后对数据进行细粒度分类,开启了中文细粒度命名实体识别的研究,其中CNN有助于识别实体的边界,该方法采用静态的词向量和单向的LSTM,有一定的改进空间。Liang等[3]公开了中文数据集CLUENER2020,其包含10类细粒度标签,并采用RoBERTa-wwm-large预训练模型实现中文命名实体识别。
2 细粒度机构名识别研究
因传统领域细粒度命名实体识别语料匮乏,本文提出基于实体词典分类器的细粒度机构名识别,该方法主要分为两个模块:粗粒度机构名识别模块、基于词典的细粒度机构名分类模块。
2.1 任务定义
细粒度机构名识别即给定文本,识别其中的机构名并预测可能的细粒度标签,见表1。

表1 细粒度机构名识别示例
本文提出了分阶段细粒度机构名识别的方法。首先,基于中文百科构建大规模的机构名实体词典,根据短文本分类的思想训练机构名分类器;对于待识别的文本,经过粗粒度机构名识别后,将识别的机构名作为机构名分类器的输入,以预测机构名的细粒度标签。
2.2 词典构建
建立机构名词典,首先从百度百科中爬取大量的词条,利用远程监督的方法筛选出词条标签中有标志性词,如“组织机构”、“俱乐部”、“协会”、“公司”的词条。
将筛选出的词条按照其语义特征,例如“某某公司”、“某某医院”、“某某学校”等,或者词条标签的内容,例如“公司”、“政党”等分配细粒度标签。
然而,在具体实现阶段,发现标注数据有许多错误:①词条标签中存在误导性标签,例如“巢湖风景名胜区”、“中华侏罗纪公园”等词条的标签中都有组织机构,但是显然这些实体不是机构名;②存在语义歧义词,如“5国集团”、“二十国集团”等显然不是公司,而是国际组织;③存在许多英文实体,如“NBC”、“tvb”等无法使用语义信息,针对这些问题,根据词条标签、词条摘要和语义对每个实体进行二次人工标注。
2.3 粗粒度机构名识别
粗粒度机构名识别通常被看作是序列标注问题,输入句子X=(x1,x2,…xi,…,xn), 其中xi表示i个字符。输出为标签序列y=(y1,y2,…,yi,…,yn), 其中yi∈{B,I,O} 是xi的标签, B,I,O分别表示机构名的首字,机构名的其它字和其它。本文提出利用Bert实现特征提取,结合BiLSTM和条件随机场(CRF)混合的机构名识别算法。模型如图1所示。
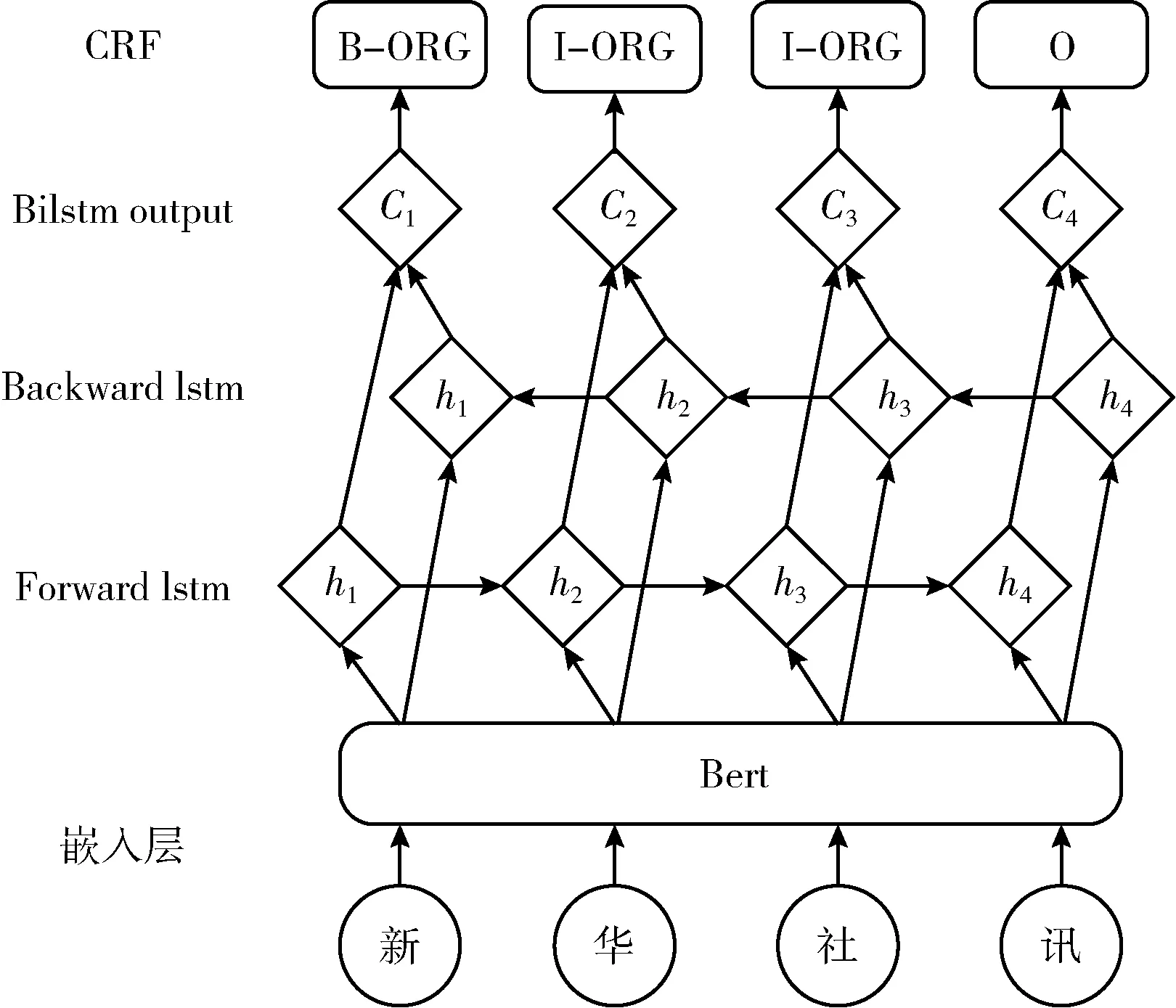
图1 Bert-BiLSTM-CRF基本结构
首先,将输入转换成向量形式,输入到BiLSTM[18]中。词向量的表示方式有one-hot、word2vec[19]等,但是one-hot将词之间的关系视为独立,导致向量稀疏问题。Word2vec虽然解决了这一问题,但是其窗口大小有限,且是静态,无法体现词的复杂特性。Bert[20]采用双向的Transformer结构,而Transformer模型的核心是注意力机制[21],可以学习输入序列的上下文信息、提取字级、词级和句子级特征,因此,本文考虑Bert提取词向量。
然后,将Bert产生的向量通过双向LSTM[18]层。由于LSTM非常适合时序数据建模,如文本数据,可以更好捕捉双向的较长距离的依赖关系。但其无法编码反向信息,例如,“这件衣服脏的不行,需要清洗。”这里“不行”是“脏”的修饰词。因此,采用双向LSTM可以捕捉输入文本的双向语义依赖关系。
最后,将双向LSTM拼接的编码信息输入CRF[11,12],学习相邻实体标签之间的转移规则,约束输出的标签,调整不符合规范的标签序列。
在机构名识别的训练语料中,假设输入为
X=(x1,x2,…,xi,…,xn)
(1)
对应标签为
y=(y1,y2,…,yi,…,yn)
(2)
经过CRF层后预测的可能标签为
(3)
定义Pi∈R3为xi在 {B,I,O} 上的得分,则有
Pi=Wshi+bs
(4)

(5)
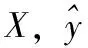
(6)
其中,Ys为输入X所有可能的标签序列集合。
(7)
2.4 基于词典的机构名分类器
已经有实验验证Bert-CNN在文本分类方面取得很好的性能(https://github.com/649453932/Bert-Chinese-Text-Classification-Pytorch),本文将机构名实体视为短文本,采用短文本分类的思想训练机构名分类器。首先利用Bert[20]充分提取输入实体的字级、词级和句级等特征,CNN[22]自动提取输入的n-gram特征,实现最优性能,而且由于实体分类属于短文本分类范畴,本文的max_len仅为32,CNN在短文本分类上性能优异,而LSTM[18]和DPCNN[23]主要在长文本上表现出优异性能。因此,本文采用Bert-CNN,基本结构如图2所示。
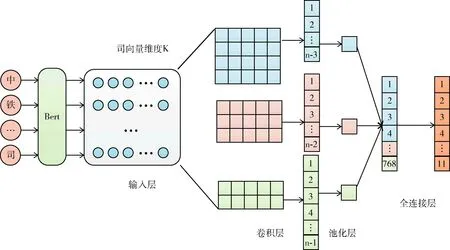
图2 Bert-CNN的基本结构
从图2中可以看出,为了捕捉输入真正意义的双向关系,本文采用Bert将输入的实体序列转换成向量,并将其作为CNN的输入。
CNN作为一个特征提取器,可以不断提取输入的特征,卷积操作和池化操作提取局部特征,全连接层可以提取整体特征。这样使得较远的输入之间也可以建立语义上的联系。使用大小分别为2×k, 3×k, 4×k的卷积核提取输入的某个局部特征,目的是尽可能不遗漏有用信息。卷积后得到256×3个一维特征向量。
采用1-max-pooling将产生的一维特征向量转化成一个值。对每个特征向量池化之后,将其结果拼接。拼接后的维度为768×1,将此特征向量通过激活函数为Linear的全连接层进行分类,最终输出实体在11个细粒度类别标签上的分数。为了防止过拟合,需要在池化层和全连接层之间加上dropout。
3 实 验
上文详细介绍了细粒度机构名识别框架,主要分为两个阶段,分别是粗粒度机构名识别和基于机构名词典的分类器。因此实验首先对这两个阶段的效果分别进行评估,并对其性能进行讨论分析,最后,验证基于词典分类器的细粒度机构名识别的效果。
3.1 数据集
3.1.1 机构名词典
本文对传统领域的机构名进一步进行了细粒度划分11种类别,分别是公司、教育科研机构、政府组织、军事组织、体育组织、社会团体、医疗机构、国际组织、媒体机构、政党及其它。本文采用随机将构建的词典分为训练集、验证集和测试集,实体数目见表2。
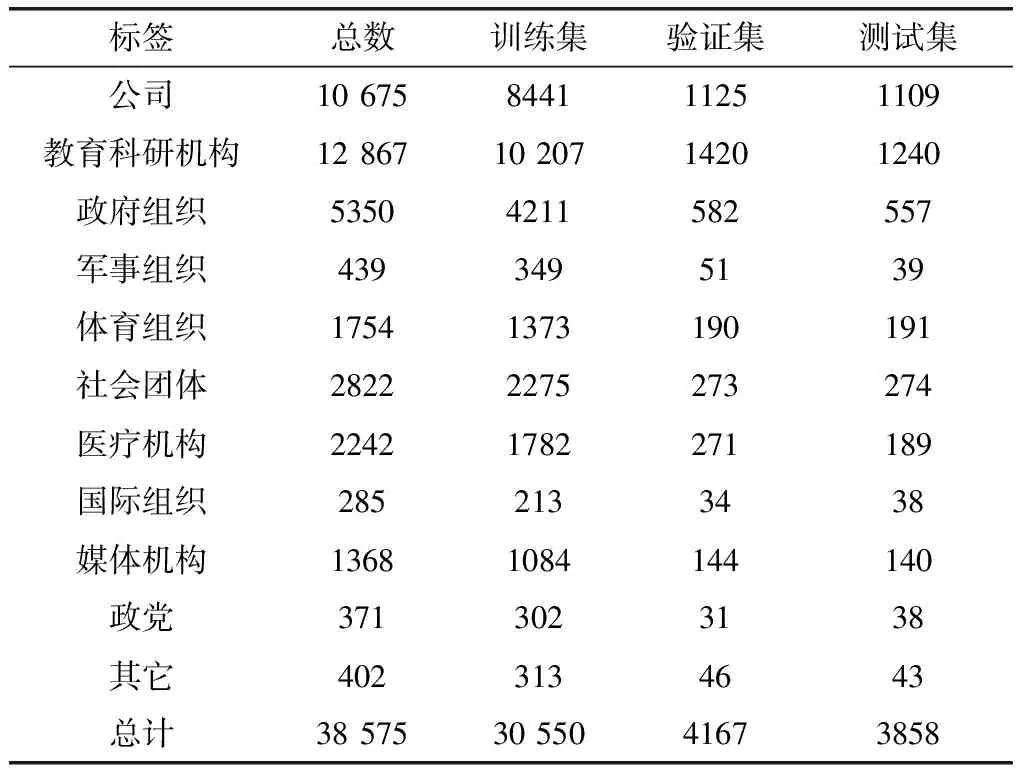
表2 细粒度实体词典数目
3.1.2 粗粒度机构名识别数据集
本文采用微软的中文标注数据MSRA。其中,句子数目及所含机构名实体数见表3。

表3 数据集句子数目及组织实体数目
3.1.3 细粒度机构名测试数据集
为了评估细粒度机构名的识别效果,本文根据机构名的细粒度标签对MSRA微软亚洲研究院开源数据集[5]的测试集进一步细粒度标注,以此作为整个方法的测试数据集。首先,利用词典匹配的方法为现有的机构名分配细粒度标签,进一步人工校对,查看是否存在误标、漏标现象,以确保数据集的可靠性。测试集中各细粒度机构名的数目见表4。

表4 测试集中各类别机构名的数目
3.2 实验结果
实验的最终结果取决于分类器和粗粒度机构名识别的效果,因此,需要对每个阶段进行实验。
3.2.1 粗粒度命名实体识别模型对比
为了验证Bert-BiLSTM-CRF[25]在粗粒度机构名识别的效果,选取若干模型与本文模型进行对比。
BiLSTM-CRF[12,18]:该模型是命名实体识别模块经典的方法之一。在输入词向量之后,BiLSTM获取输入序列的上下文表示,最后使用CRF层学习标签之间的转移规则。
Bert-CRF[12,20]:Bert具有广泛的通用性且在文本数据上表现出优异性能,因此,加入Bert验证其在命名实体识别上的性能。
Bert-CNN-CRF[18,20,22]:CNN可以确定实体的边界,因此,加入CNN以验证其性能。
Bert-BiLSTM-CNN-CRF[22,25]:因CNN在句子建模方面效果突出,因此,将LSTM、CNN结合,验证是否有更有效果。实验结果见表5。

表5 命名实体识别模块实验结果
从表5中可知,Bert-BiLSTM-CRF在此数据集上的性能最好。总体来说,Bert和BiLSTM都会改进模型性能。但是若有Bert时,CNN的作用不大。
作为命名实体识别的经典模型,BiLSTM-CRF在此数据集上的F1值为0.8451。引入预训练Bert后,4种模型分别提高了0.0551、0.0555、0.0779、0.0651,这是因为Bert可以充分提取输入各种维度的特征, 从而使提取的词向量能够更好地表征不同语境中的句法与语义信息,进而增强模型泛化能力,因此性能更加优异。
与其它模型相比,Bert-BiLSTM-CRF的性能更好。Bert提取输入的各维度特征,学习其语义相关性,提升了输入的语义表示能力,BiLSTM对Bert产生的信息双向编码,通过记忆门、遗忘门,在一定程度上提升了有效信息的获取。
CNN可以学习输入的语义相关性,Bert也有这些作用。因为卷积核池化可能会丢失某些输入的局部信息,因此,加入CNN效果不好。
本文模型可以正确识别以下类型的机构名:①结构复杂,如“美国中国商会”等;②缩略词,如“联大”等;③英文实体,如“abb”等。很大程度解决了机构名识别存在的问题。
3.2.2 机构名词典模型对比
为了获取CNN模型的最佳参数,本文采用不同卷积核大小进行消融实验,结果见表6。

表6 模型的参数比较
从表6中可以看出,当卷积核大小为2、3、4时,模型效果最优。因此,本文采用卷积核大小分别为2、3、4的卷积核对输入进行特征提取。
为了验证Bert-CNN[19,22]在基于机构名词典的分类器上的效果,本模块分别用以下模型作为baseline进行比较。
CNN[22]:在文本分类任务上取得了很好的效果。以静态的词向量作为输入,若干卷积核对输入向量进行特征提取。
DPCNN[23]:与残差网络[24]相似,采用金字塔思想,以无监督词向量作为输入,堆叠几层卷积层和采样层,形成尺度缩放的金字塔,达到维度缩放的目的。
Bert[20]:Bert在很多自然语言处理任务上表现出优异的性能,包括文本分类任务。最终性能见表7。
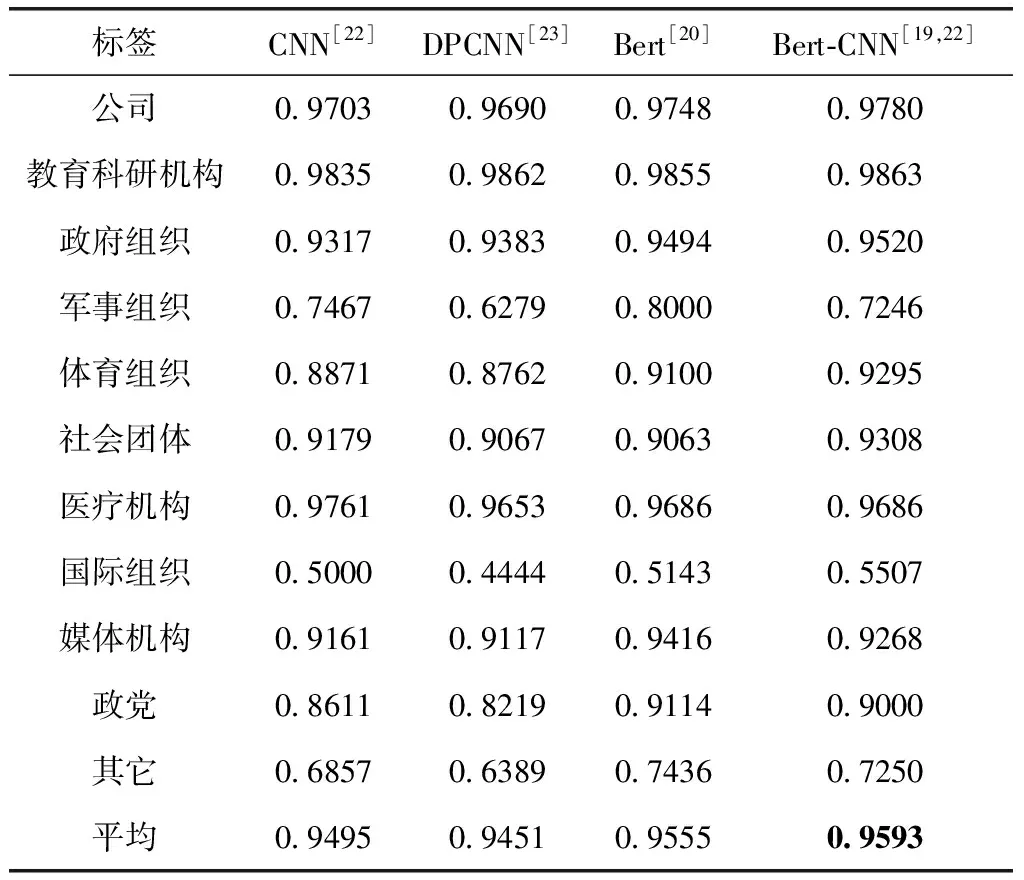
表7 分类器训练模块实验结果(F1)
根据实验结果,可以得出以下结论:
(1)模型的整体性能:DPCNN (2)分析每类机构名的分类效果,军事组织、国际组织和其它的效果均低于0.8,部分原因在于该类别的实体数目相对较少、实体名称不规律(例如:国际组织“CABI”等,军事组织“淮安独立团”等),还出现英文实体如“Sun Microsystems”、“P.A.WORKS”等,难以学习语义并进行分析。 3.2.3 细粒度分类效果对比 为了评估细粒度机构名识别的性能,本文提取测试集中粗粒度机构名,通过词典分类器为其分配对应的细粒度标签。 为了对比,本文选用词典匹配作为baseline。首先利用机构名词典对输入文本实现双向最大匹配,生成分词文本。其次利用词典对分词文本生成预测标签序列。细粒度机构名识别的对比终结果见表8。 表8 细粒度分类模块的实验结果 实验结果表明,相比于词典匹配,分阶段的机构名识别效果更好,原因在于词典匹配方法取决于词典的覆盖规模。相较于其它模型组合,当粗粒度命名实体识别模型为Bert-BiLSTM-CRF,分类器采用Bert-CNN训练时,细粒度机构名识别的性能最佳,F1值达到了0.8117,原因在于上游任务的准确率会影响下游任务,其次分类器也决定了细粒度标签分类的性能。 相较于其它模型,Bert-BiLSTM-CRF中Bert采用双向Transformer结构,Transformer的核心机制在于Multi-Head Attention,可以从不同于语义子空间捕获文本语义特征、BiLSTM考虑文本的时序信息获取文本的长距离依赖,CRF学习输出标签之间的规则并且约束BiLSTM输出的语义信息。分类器最好的模型是Bert-CNN,相较于Word2vec模型,Bert可以生成动态的文本表示,能够更加准确反映出词汇在当前语义环境下的表示。CNN通过不同大小的卷积核可以有效学习Bert生成的语义表示,通过其最大池化层又规避了过拟合情况的发生,所以取得了最好的分类效果。 本文构建了细粒度机构名词典,人工标注了不同领域的11类实体,共计38 575个,在此基础上分阶段完成细粒度机构名的识别。本文解决了机构名识别存在的问题,实验对比了不同文本表示下各个命名实体识别和分类模型取得的实验效果,为以后的进一步工作提供参考。在以后的工作中,我们将会把数据集扩展至人名、地名等传统领域,并且考虑引入更先进的深度学习模型展开细粒度命名实体识别研究。
4 结束语
